- 一、变量
- 3.简单四则运算
- 二、条件判断语法结构
- 三、流程 & 循环 语句
- 四、正则表达式
- 五、sed
- 三、sed使用方法介绍
- 六、awk
- date |awk ‘{print “Month: “$2 “\nYear: “$NF}’
- awk -F: ‘{print “username is: “ $1 “\t uid is: “$3}’ /etc/passwd
- awk -F: ‘{printf “%-15s %-10s %-15s\n”, $1,$2,$3}’ /etc/passwd
- awk -F: ‘{printf “|%15s| %10s| %15s|\n”, $1,$2,$3}’ /etc/passwd
- awk -F: ‘{printf “|%-15s| %-10s| %-15s|\n”, $1,$2,$3}’ /etc/passwd
- 6. awk算数运算
- awk ‘BEGIN{print 1+1}’
- awk ‘BEGIN{print 1**1}’
- awk ‘BEGIN{print 2**3}’
- awk ‘BEGIN{print 2/3}’
一、变量
1.变量的定义方式有哪些?
㈠ 基本方式
直接赋值给一个变量
[root@MissHou ~]# A=1234567[root@MissHou ~]# echo $A1234567[root@MissHou ~]# echo ${A:2:4} 表示从A变量中第3个字符开始截取,截取4个字符3456说明:$变量名 和 ${变量名}的异同相同点:都可以调用变量不同点:${变量名}可以只截取变量的一部分,而$变量名不可以
㈡ 命令执行结果赋值给变量
[root@MissHou ~]# B=`date +%F`[root@MissHou ~]# echo $B2019-04-16[root@MissHou ~]# C=$(uname -r)[root@MissHou ~]# echo $C2.6.32-696.el6.x86_64
㈢ 交互式定义变量(read)
目的:让用户自己给变量赋值,比较灵活。
语法:read [选项] 变量名
常见选项:
| 选项 | 释义 |
|---|---|
| -p | 定义提示用户的信息 |
| -n | 定义字符数(限制变量值的长度) |
| -s | 不显示(不显示用户输入的内容) |
| -t | 定义超时时间,默认单位为秒(限制用户输入变量值的超时时间) |
举例说明:
用法1:用户自己定义变量值[root@MissHou ~]# read nameharry[root@MissHou ~]# echo $nameharry[root@MissHou ~]# read -p "Input your name:" nameInput your name:tom[root@MissHou ~]# echo $nametom
用法2:变量值来自文件
[root@MissHou ~]# cat 1.txt10.1.1.1 255.255.255.0[root@MissHou ~]# read ip mask < 1.txt[root@MissHou ~]# echo $ip10.1.1.1[root@MissHou ~]# echo $mask255.255.255.0
㈣ 定义有类型的变量(declare)
目的: 给变量做一些限制,固定变量的类型,比如:整型、只读
用法:declare 选项 变量名=变量值
常用选项:
| 选项 | 释义 | 举例 |
|---|---|---|
| -i | 将变量看成整数 | declare -i A=123 |
| -r | 定义只读变量 | declare -r B=hello |
| -a | 定义普通数组;查看普通数组 | |
| -A | 定义关联数组;查看关联数组 | |
| -x | 将变量通过环境导出 | declare -x AAA=123456 等于 export AAA=123456 |
举例说明:
[root@MissHou ~]# declare -i A=123[root@MissHou ~]# echo $A123[root@MissHou ~]# A=hello[root@MissHou ~]# echo $A0[root@MissHou ~]# declare -r B=hello[root@MissHou ~]# echo $Bhello[root@MissHou ~]# B=world-bash: B: readonly variable[root@MissHou ~]# unset B-bash: unset: B: cannot unset: readonly variable
(五). 数组定义
㈠ 数组分类
- 普通数组:只能使用整数作为数组索引(元素的下标)
-
㈡ 普通数组定义
一次赋予一个值
数组名[索引下标]=值array[0]=v1array[1]=v2array[2]=v3array[3]=v4
一次赋予多个值
数组名=(值1 值2 值3 ...)array=(var1 var2 var3 var4)array1=(`cat /etc/passwd`) 将文件中每一行赋值给array1数组array2=(`ls /root`)array3=(harry amy jack "Miss Hou")array4=(1 2 3 4 "hello world" [10]=linux)
㈢ 数组的读取
${数组名[元素下标]}echo ${array[0]} 获取数组里第一个元素echo ${array[*]} 获取数组里的所有元素echo ${#array[*]} 获取数组里所有元素个数echo ${!array[@]} 获取数组元素的索引下标echo ${array[@]:1:2} 访问指定的元素;1代表从下标为1的元素开始获取;2代表获取后面几个元素查看普通数组信息:[root@MissHou ~]# declare -a
㈣ 关联数组定义
①首先声明关联数组
declare -A asso_array1declare -A asso_array1declare -A asso_array2declare -A asso_array3
② 数组赋值
一次赋一个值
数组名[索引or下标]=变量值# asso_array1[linux]=one# asso_array1[java]=two# asso_array1[php]=three
一次赋多个值
# asso_array2=([name1]=harry [name2]=jack [name3]=amy [name4]="Miss Hou")
查看关联数组
# declare -Adeclare -A asso_array1='([php]="three" [java]="two" [linux]="one" )'declare -A asso_array2='([name3]="amy" [name2]="jack" [name1]="harry" [name4]="Miss Hou" )'
获取关联数组值
# echo ${asso_array1[linux]}one# echo ${asso_array1[php]}three# echo ${asso_array1[*]}three two one# echo ${!asso_array1[*]}php java linux# echo ${#asso_array1[*]}3# echo ${#asso_array2[*]}4# echo ${!asso_array2[*]}name3 name2 name1 name4
其他定义方式
[root@MissHou shell05]# declare -A books[root@MissHou shell05]# let books[linux]++[root@MissHou shell05]# declare -A|grep booksdeclare -A books='([linux]="1" )'[root@MissHou shell05]# let books[linux]++[root@MissHou shell05]# declare -A|grep booksdeclare -A books='([linux]="2" )'
2. 变量的分类
㈠ 本地变量
本地变量:当前用户自定义的变量。当前进程中有效,其他进程及当前进程的子进程无效。 ps -auxf|grep bash 查看父子进程关系
㈡ 环境变量
环境变量:当前进程有效,并且能够被子进程调用。
全局变量:全局所有的用户和程序都能调用,且继承,新建的用户也默认能调用.
- 解读相关配置文件
| 文件名 | 说明 | 备注 | | —- | —- | —- | | $HOME/.bashrc | 当前用户的bash信息,用户登录时读取 | 定义别名、umask、函数等 | | $HOME/.bash_profile | 当前用户的环境变量,用户登录时读取 | | | $HOME/.bash_logout | 当前用户退出当前shell时最后读取 | 定义用户退出时执行的程序等 | | /etc/bashrc | 全局的bash信息,所有用户都生效 | | | /etc/profile | 全局环境变量信息 | 系统和所有用户都生效 | | $HOME/.bash_history | 用户的历史命令 | history -w 保存历史记录 history -c 清空历史记录 |
说明:以上文件修改后,都需要重新source让其生效或者退出重新登录。
用户登录系统读取相关文件的顺序
系统变量(内置bash中变量) : shell本身已经固定好了它的名字和作用. | 内置变量 | 含义 | | —- | —- | | $? | 上一条命令执行后返回的状态;状态值为0表示执行正常,非0表示执行异常或错误 | | $0 | 当前执行的程序或脚本名 | | $# | 脚本后面接的参数的个数 | | $* | 脚本后面所有参数,参数当成一个整体输出,每一个变量参数之间以空格隔开 | | $@ | 脚本后面所有参数,参数是独立的,也是全部输出 | | $1~$9 | 脚本后面的位置参数,$1表示第1个位置参数,依次类推 | | ${10}~${n} | 扩展位置参数,第10个位置变量必须用{}大括号括起来(2位数字以上扩起来) | | | 当前所在进程的进程号,如
echo| | $! | 后台运行的最后一个进程号 (当前终端) | | !$ | 调用最后一条命令历史中的参数 |进一步了解位置参数
$1~${n}#!/bin/bash#了解shell内置变量中的位置参数含义 这里\是转义作用意思是$0只是个字符串echo "\$0 = $0"echo "\$# = $#"echo "\$* = $*"echo "\$@ = $@"echo "\$1 = $1"echo "\$2 = $2"echo "\$3 = $3"echo "\$11 = ${11}"echo "\$12 = ${12}"
进一步了解$*和$@的区别
$*:表示将变量看成一个整体 $@:表示变量是独立的
#!/bin/bashfor i in "$@"doecho $idoneecho "======我是分割线======="for i in "$*"doecho $idone[root@MissHou ~]# bash 3.sh a b cabc======我是分割线=======a b c
3.简单四则运算
算术运算:默认情况下,shell就只能支持简单的整数运算
运算内容:加(+)、减(-)、乘(*)、除(/)、求余数(%)
1. 四则运算符号
| 表达式 | 举例 |
|---|---|
| $(( )) | echo $((1+1)) |
| $[ ] | echo $[10-5] |
| expr | expr 10 / 5 |
| let | n=1;let n+=1 等价于 let n=n+1 |
二、条件判断语法结构
1. 条件判断语法格式
- 格式1: test 条件表达式
- 格式2: [ 条件表达式 ]
- 格式3: [[ 条件表达式 ]] 支持正则 =~
特别说明:
1)[ 亲亲,我两边都有空格,不空打死你呦 ] :imp:
2)[[ 亲亲,我两边都有空格,不空打死你呦 ]]:imp:
3)更多判断,man test去查看,很多的参数都用来进行条件判断
2. 条件判断相关参数
㈠ 判断文件类型
| 判断参数 | 含义 |
|---|---|
| -e | 判断文件是否存在(任何类型文件) |
| -f | 判断文件是否存在并且是一个普通文件 |
| -d | 判断文件是否存在并且是一个目录 |
| -L | 判断文件是否存在并且是一个软连接文件 |
| -b | 判断文件是否存在并且是一个块设备文件 |
| -S | 判断文件是否存在并且是一个套接字文件 |
| -c | 判断文件是否存在并且是一个字符设备文件 |
| -p | 判断文件是否存在并且是一个命名管道文件 |
| -s | 判断文件是否存在并且是一个非空文件(有内容) |
举例说明:
test -e file 只要文件存在条件为真[ -d /shell01/dir1 ] 判断目录是否存在,存在条件为真[ ! -d /shell01/dir1 ] 判断目录是否存在,不存在条件为真[[ -f /shell01/1.sh ]] 判断文件是否存在,并且是一个普通的文件
㈡ 判断文件权限
| 判断参数 | 含义 |
|---|---|
| -r | 当前用户对其是否可读 |
| -w | 当前用户对其是否可写 |
| -x | 当前用户对其是否可执行 |
| -u | 是否有suid,高级权限冒险位 |
| -g | 是否sgid,高级权限强制位 |
| -k | 是否有t位,高级权限粘滞位 |
㈢ 判断文件新旧
说明:这里的新旧指的是文件的修改时间。
| 判断参数 | 含义 |
|---|---|
| file1 -nt file2 | 比较file1是否比file2新 |
| file1 -ot file2 | 比较file1是否比file2旧 |
| file1 -ef file2 | 比较是否为同一个文件,或者用于判断硬连接,是否指向同一个inode |
㈣ 判断整数
| 判断参数 | 含义 |
|---|---|
| -eq | 相等 |
| -ne | 不等 |
| -gt | 大于 |
| -lt | 小于 |
| -ge | 大于等于 |
| -le | 小于等于 |
㈤ 判断字符串
| 判断参数 | 含义 |
|---|---|
| -z | 判断是否为空字符串,字符串长度为0则成立 |
| -n | 判断是否为非空字符串,字符串长度不为0则成立 |
| string1 = string2 | 判断字符串是否相等 |
| string1 != string2 | 判断字符串是否相不等 |
㈥ 多重条件判断
| 判断符号 | 含义 | 举例 |
|---|---|---|
| -a 和 && | 逻辑与 | [ 1 -eq 1 -a 1 -ne 0 ] [ 1 -eq 1 ] && [ 1 -ne 0 ] |
| -o 和 || | 逻辑或 | [ 1 -eq 1 -o 1 -ne 1 ] |
特别说明:
&& 前面的表达式为真,才会执行后面的代码
|| 前面的表达式为假,才会执行后面的代码
; 只用于分割命令或表达式
① 举例说明
数值比较
[root@server ~]# [ $(id -u) -eq 0 ] && echo "the user is admin"[root@server ~]$ [ $(id -u) -ne 0 ] && echo "the user is not admin"[root@server ~]$ [ $(id -u) -eq 0 ] && echo "the user is admin" || echo "the user is not admin"[root@server ~]# uid=`id -u`[root@server ~]# test $uid -eq 0 && echo this is adminthis is admin[root@server ~]# [ $(id -u) -ne 0 ] || echo this is adminthis is admin[root@server ~]# [ $(id -u) -eq 0 ] && echo this is admin || echo this is not adminthis is admin[root@server ~]# su - stu1[stu1@server ~]$ [ $(id -u) -eq 0 ] && echo this is admin || echo this is not adminthis is not admin
类C风格的数值比较
``bash 注意:在(( ))中,=表示赋值;==表示判断 [root@server ~]# ((1==2));echo $? [root@server ~]# ((1<2));echo $? [root@server ~]# ((2>=1));echo $? [root@server ~]# ((2!=1));echo $? [root@server ~]# ((id -u`==0));echo $?
[root@server ~]# ((a=123));echo $a [root@server ~]# unset a [root@server ~]# ((a==123));echo $?
- 字符串比较```bash注意:双引号引起来,看作一个整体;= 和 == 在 [ 字符串 ] 比较中都表示判断[root@server ~]# a='hello world';b=world[root@server ~]# [ $a = $b ];echo $?[root@server ~]# [ "$a" = "$b" ];echo $?[root@server ~]# [ "$a" != "$b" ];echo $?[root@server ~]# [ "$a" !== "$b" ];echo $? 错误[root@server ~]# [ "$a" == "$b" ];echo $?[root@server ~]# test "$a" != "$b";echo $?test 表达式[ 表达式 ][[ 表达式 ]]思考:[ ] 和 [[ ]] 有什么区别?[root@server ~]# a=[root@server ~]# test -z $a;echo $?[root@server ~]# a=hello[root@server ~]# test -z $a;echo $?[root@server ~]# test -n $a;echo $?[root@server ~]# test -n "$a";echo $?# [ '' = $a ];echo $?-bash: [: : unary operator expected2# [[ '' = $a ]];echo $?0[root@server ~]# [ 1 -eq 0 -a 1 -ne 0 ];echo $?[root@server ~]# [ 1 -eq 0 && 1 -ne 0 ];echo $?[root@server ~]# [[ 1 -eq 0 && 1 -ne 0 ]];echo $?
② 逻辑运算符总结
- 符号;和&&和||都可以用来分割命令或者表达式
- 分号(;)完全不考虑前面的语句是否正确执行,都会执行;号后面的内容
&&符号,需要考虑&&前面的语句的正确性,前面语句正确执行才会执行&&后的内容;反之亦然||符号,需要考虑||前面的语句的非正确性,前面语句执行错误才会执行||后内容;反之亦然-
三、流程 & 循环 语句
1、流程控制
语法结构
if [ condition1 ];thencommand1if [ condition2 ];thencommand2fielseif [ condition3 ];thencommand3elif [ condition4 ];thencommand4elsecommand5fifi
应用案例
㈠ 判断两台主机是否ping通
需求:判断当前主机是否和远程主机是否ping通
① 思路 使用哪个命令实现
ping -c次数- 根据命令的执行结果状态来判断是否通
$? - 根据逻辑和语法结构来编写脚本(条件判断或者流程控制)
② 落地实现
#!/bin/env bash# 该脚本用于判断当前主机是否和远程指定主机互通# 交互式定义变量,让用户自己决定ping哪个主机read -p "请输入你要ping的主机的IP:" ip# 使用ping程序判断主机是否互通ping -c1 $ip &>/dev/nullif [ $? -eq 0 ];thenecho "当前主机和远程主机$ip是互通的"elseecho "当前主机和远程主机$ip不通的"fi逻辑运算符test $? -eq 0 && echo "当前主机和远程主机$ip是互通的" || echo "当前主机和远程主机$ip不通的"
㈡ 判断一个进程是否存在
需求:判断web服务器中httpd进程是否存在
① 思路
- 查看进程的相关命令 ps pgrep
- 根据命令的返回状态值来判断进程是否存在
- 根据逻辑用脚本语言实现
② 落地实现
#!/bin/env bash# 判断一个程序(httpd)的进程是否存在pgrep httpd &>/dev/nullif [ $? -ne 0 ];thenecho "当前httpd进程不存在"elseecho "当前httpd进程存在"fi或者test $? -eq 0 && echo "当前httpd进程存在" || echo "当前httpd进程不存在"
③ 补充命令
pgrep命令:以名称为依据从运行进程队列中查找进程,并显示查找到的进程id选项-o:仅显示找到的最小(起始)进程号;-n:仅显示找到的最大(结束)进程号;-l:显示进程名称;-P:指定父进程号;pgrep -p 4764 查看父进程下的子进程id-g:指定进程组;-t:指定开启进程的终端;-u:指定进程的有效用户ID。
㈢ 判断一个服务是否正常
需求:判断门户网站是否能够正常访问
① 思路
- 可以判断进程是否存在,用/etc/init.d/httpd status判断状态等方法
- 最好的方法是直接去访问一下,通过访问成功和失败的返回值来判断
- Linux环境,wget curl elinks -dump
② 落地实现
#!/bin/env bash# 判断门户网站是否能够正常提供服务#定义变量web_server=www.itcast.cn#访问网站 这里可以用curl 或者 elinkswget -P /shell/ $web_server &>/dev/null[ $? -eq 0 ] && echo "当前网站服务是ok" && rm -f /shell/index.* || echo "当前网站服务不ok,请立刻处理"
(四) 判断用户是否存在
需求1:输入一个用户,用脚本判断该用户是否存在
#!/bin/env bash2 read -p "请输入一个用户名:" user_name3 id $user_name &>/dev/null4 if [ $? -eq 0 ];then6 echo "该用户存在!"7 else8 echo "用户不存在!"9 fi#!/bin/bash# 判断 用户(id) 是否存在read -p "输入壹个用户:" idid $id &> /dev/nullif [ $? -eq 0 ];thenecho "该用户存在"elseecho "该用户不存在"fi#!/bin/env bashread -p "请输入你要查询的用户名:" usernamegrep -w $username /etc/passwd &>/dev/nullif [ $? -eq 0 ]thenecho "该用户已存在"elseecho "该用户不存在"fi#!/bin/bashread -p "请输入你要检查的用户名:" nameid $name &>/dev/nullif [ $? -eq 0 ]thenecho 用户"$name"已经存在elseecho 用户"$name"不存在fi#!/bin/env bash#判断用户是否存在read -p "请写出用户名" idid $idif [ $? -eq 0 ];thenecho "用户存在"elseecho "用户不存在"fi#!/bin/env bashread -p '请输入用户名:' usernameid $username &>/dev/null[ $? -eq 0 ] && echo '用户存在' || echo '不存在'
(五)判断当前主机的内核版本
需求3:判断当前内核主版本是否为2,且次版本是否大于等于6;如果都满足则输出当前内核版本
思路:1. 先查看内核的版本号 uname -r2. 先将内核的版本号保存到一个变量里,然后再根据需求截取出该变量的一部分:主版本和次版本3. 根据需求进步判断#!/bin/bashkernel=`uname -r`var1=`echo $kernel|cut -d. -f1`var2=`echo $kernel|cut -d. -f2`test $var1 -eq 2 -a $var2 -ge 6 && echo $kernel || echo "当前内核版本不符合要求"或者[ $var1 -eq 2 -a $var2 -ge 6 ] && echo $kernel || echo "当前内核版本不符合要求"或者[[ $var1 -eq 2 && $var2 -ge 6 ]] && echo $kernel || echo "当前内核版本不符合要求"或者#!/bin/bashkernel=`uname -r`test ${kernel:0:1} -eq 2 -a ${kernel:2:1} -ge 6 && echo $kernel || echo '不符合要求'其他命令参考:uname -r|grep ^2.[6-9] || echo '不符合要求'
2、循环
前置知识:如何生成随机数?
系统变量:RANDOM,默认会产生0~32767的随机整数
打印一个随机数echo $RANDOM查看系统上一次生成的随机数# set|grep RANDOMRANDOM=28325产生0~1之间的随机数echo $[$RANDOM%2]产生0~2之间的随机数echo $[$RANDOM%3]产生0~3之间的随机数echo $[$RANDOM%4]产生0~9内的随机数echo $[$RANDOM%10]产生0~100内的随机数echo $[$RANDOM%101]产生50-100之内的随机数echo $[$RANDOM%51+50]产生三位数的随机数echo $[$RANDOM%900+100]
for循环语法结构
- 基本语法格式
```bash
for variable in {list}
do
done 或者 for variable in a b c docommandcommand…
done 或者 直接遍历脚本参数 for var do echo $var donecommandcommand
或者 类C风格 for(( expr1;expr2;expr3 )) do command command … done for (( i=1;i<=5;i++)) do echo $i done
<a name="rhH63"></a>### 应用案例<a name="aTLS3"></a>#### 1.脚本同步系统时间① 具体需求1. 写一个脚本,30秒同步一次系统时间,时间同步服务器10.1.1.11. 如果同步失败,则进行邮件报警,每次失败都报警1. 如果同步成功,也进行邮件通知,但是成功100次才通知一次② 思路1. 每隔30s同步一次时间,该脚本是一个死循环 while 循环<br />1. 同步失败发送邮件 1) ntpdate 10.1.1.1 2) rdate -s 10.1.1.1<br />1. 同步成功100次发送邮件 定义变量保存成功次数<br />③ 落地实现```powershell#!/bin/env bash# 该脚本用于时间同步NTP=10.1.1.1count=0while truedontpdate $NTP &>/dev/nullif [ $? -ne 0 ];thenecho "system date failed" |mail -s "check system date" root@localhostelselet count++if [ $count -eq 100 ];thenecho "systemc date success" |mail -s "check system date" root@localhost && count=0fifisleep 30done#!/bin/bash#定义变量count=0ntp_server=10.1.1.1while truedordate -s $ntp-server &>/dev/nullif [ $? -ne 0 ];thenecho "system date failed" |mail -s 'check system date' root@localhostelselet count++if [ $[$count%100] -eq 0 ];thenecho "system date successfull" |mail -s 'check system date' root@localhost && count=0fifisleep 3done
2.批量创建用户(密码随机产生)
需求:批量创建5个用户,每个用户的密码为一个随机数
① 思路
- 循环5次创建用户
- 产生一个密码文件来保存用户的随机密码
- 从密码文件中取出随机密码赋值给用户
② 落地实现
#!/bin/bash#crate user and set passwd#产生一个保存用户名和密码的文件echo user0{1..5}:itcast$[$RANDOM%9000+1000]#@~|tr ' ' '\n'>> user_pass.file#循环创建5个用户for ((i=1;i<=5;i++))douser=`head -$i user_pass.file|tail -1|cut -d: -f1`pass=`head -$i user_pass.file|tail -1|cut -d: -f2`useradd $userecho $pass|passwd --stdin $userdone或者for i in `cat user_pass.file`douser=`echo $i|cut -d: -f1`pass=`echo $i|cut -d: -f2`useradd $userecho $pass|passwd --stdin $userdone#!/bin/bash#crate user and set passwd#产生一个保存用户名和密码的文件echo user0{1..3}:itcast$[$RANDOM%9000+1000]#@~|tr ' ' '\n'|tr ':' ' ' >> user_pass.file#循环创建5个用户while read user passdouseradd $userecho $pass|passwd --stdin $userdone < user_pass.filepwgen工具产生随机密码:[root@server shell04]# pwgen -cn1 12Meep5ob1aesa[root@server shell04]# echo user0{1..3}:$(pwgen -cn1 12)user01:Bahqu9haipho user02:Feiphoh7moo4 user03:eilahj5eth2R[root@server shell04]# echo user0{1..3}:$(pwgen -cn1 12)|tr ' ' '\n'user01:eiwaShuZo5hiuser02:eiDeih7aim9kuser03:aeBahwien8co
这里需要注意: for循环读取文件 是以 空格和换行符 作为分隔符 while循环管道读取文件 是以 仅换行符 **非常适合读取每一行 **但是while循环管道,只可以去读取循环外变量,对其赋值只能在循环内部使用,在外部对循环内的赋值获取不到;类似函数的字面量参数传递;
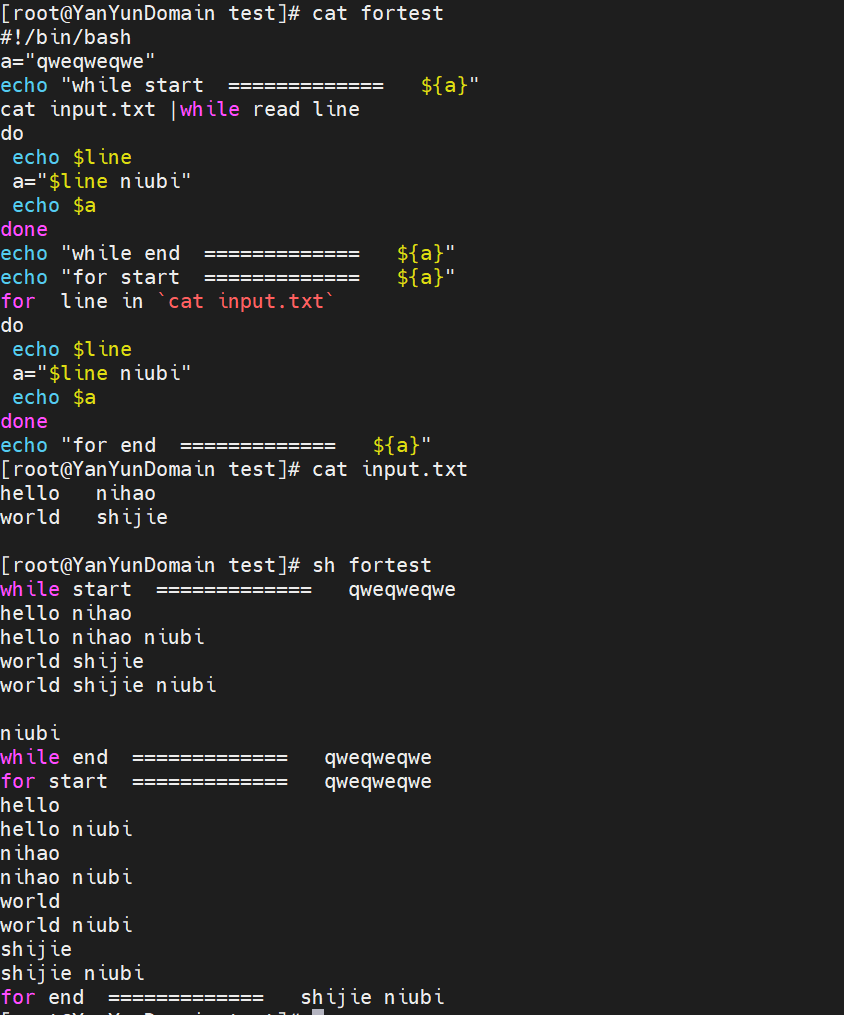
四、正则表达式
正则当中名词解释
- 元字符
指那些在正则表达式中具有特殊意义的专用字符,如:点(.) 星(*) 问号(?)等 -
第一类正则表达式
㈠ 正则中普通常用的元字符
| 元字符 | 功能 | 备注 | | —- | —- | —- | | . | 匹配除了换行符以外的任意单个字符 | | | | 前导字符出现0次或连续多次 | | | . | 任意长度字符 | ab.* | | ^ | 行首(以…开头) | ^root | | $ | 行尾(以…结尾) | bash$ | | ^$ | 空行 | | | [] | 匹配括号里任意单个字符或一组单个字符 | [abc] | | [^] | 匹配不包含括号里任一单个字符或一组单个字符 | [^abc] | | [1] | 匹配以括号里任意单个字符或一组单个字符开头 | [2] | | ^[^] | 匹配不以括号里任意单个字符或一组单个字符开头 | ^[^abc] |
示例文本
# cat 1.txtgglegoglegooglegoooglegooooooglegooooooogletaobao.comtaotaobaobao.comjingdong.comdingdingdongdong.com10.1.1.1Adfjd8789JHfdsdf/a87fdjfkdLKJK7kdjfd989KJK;bSKJjkksdjf878.cidufKJHJ6576,hello worldhelloworld yourself
㈡ 正则中其他常用元字符
| 元字符 | 功能 | 备注 |
|---|---|---|
| \< | 取单词的头 | |
| \> | 取单词的尾 | |
| \< \> | 精确匹配 | |
| \{n\} | 匹配前导字符连续出现n次 | |
| \{n,\} | 匹配前导字符至少出现n次 | |
| \{n,m\} | 匹配前导字符出现n次与m次之间 | |
| \( \) | 保存被匹配的字符 | |
| \d | 匹配数字(grep -P) | [0-9] |
| \w | 匹配字母数字下划线(grep -P) | [a-zA-Z0-9_] |
| \s | 匹配空格、制表符、换页符(grep -P) | [\t\r\n] |
举例说明:
需求:将10.1.1.1替换成10.1.1.2541)vim编辑器支持正则表达式# vim 1.txt:%s#\(10.1.1\).1#\1.254#g:%s/\(10.1.1\).1/\1.254/g2)sed支持正则表达式【后面学】# sed -n 's#\(10.1.1\).1#\1.254#p' 1.txt10.1.1.254说明:找出含有10.1.1的行,同时保留10.1.1并标记为标签1,之后可以使用\1来引用它。最多可以定义9个标签,从左边开始编号,最左边的是第一个。需求:将helloworld yourself 换成hellolilei myself# vim 1.txt:%s#\(hello\)world your\(self\)#\1lilei my\2#g# sed -n 's/\(hello\)world your\(self\)/\1lilei my\2/p' 1.txthellolilei myself# sed -n 's/helloworld yourself/hellolilei myself/p' 1.txthellolilei myself# sed -n 's/\(hello\)world your\(self\)/\1lilei my\2/p' 1.txthellolilei myselfPerl内置正则:\d 匹配数字 [0-9]\w 匹配字母数字下划线[a-zA-Z0-9_]\s 匹配空格、制表符、换页符[\t\r\n]# grep -P '\d' 1.txt# grep -P '\w' 2.txt# grep -P '\s' 3.txt
㈢ 扩展类正则常用元字符
注意:
- grep你要用我,必须加 -E 或者 让你兄弟
egrep来找我 - sed你要用我,必须加 -r
| 扩展元字符 | 功能 | 备注 | | —- | —- | —- | | + | 匹配一个或多个前导字符 | bo+ 匹配boo、 bo | | ? | 匹配零个或一个前导字符 | bo? 匹配b、 bo | | | | 或 | 匹配a或b | | () | 组字符(看成整体) | (my|your)self:表示匹配myself或匹配yourself | | {n} | 前导字符重复n次 | | | {n,} | 前导字符重复至少n次 | | | {n,m} | 前导字符重复n到m次 | |
举例说明:
# grep "root|ftp|adm" /etc/passwd# egrep "root|ftp|adm" /etc/passwd# grep -E "root|ftp|adm" /etc/passwd# grep -E 'o+gle' test.txt# grep -E 'o?gle' test.txt# egrep 'go{2,}' 1.txt# egrep '(my|your)self' 1.txt使用正则过滤出文件中的IP地址:# grep '[0-9]\{2\}\.[0-9]\{1\}\.[0-9]\{1\}\.[0-9]\{1\}' 1.txt10.1.1.1# grep '[0-9]{2}\.[0-9]{1}\.[0-9]{1}\.[0-9]{1}' 1.txt# grep -E '[0-9]{2}\.[0-9]{1}\.[0-9]{1}\.[0-9]{1}' 1.txt10.1.1.1# grep -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' 1.txt10.1.1.1# grep -E '([0-9]{1,3}\.){3}[0-9]{1,3}' 1.txt10.1.1.1
第二类正则
| 表达式 | 功能 | 示例 |
|---|---|---|
| [:alnum:] | 字母与数字字符 | [[:alnum:]]+ |
| [:alpha:] | 字母字符(包括大小写字母) | [[:alpha:]]{4} |
| [:blank:] | 空格与制表符 | [[:blank:]]* |
| [:digit:] | 数字 | [[:digit:]]? |
| [:lower:] | 小写字母 | [[:lower:]]{4,} |
| [:upper:] | 大写字母 | [[:upper:]]+ |
| [:punct:] | 标点符号 | [[:punct:]] |
| [:space:] | 包括换行符,回车等在内的所有空白 | [[:space:]]+ |
[root@server shell05]# grep -E '^[[:digit:]]+' 1.txt[root@server shell05]# grep -E '^[^[:digit:]]+' 1.txt[root@server shell05]# grep -E '[[:lower:]]{4,}' 1.txt
正则表达式总结
把握一个原则,让你轻松搞定可恶的正则符号:
- 我要找什么?
- 找数字 [0-9]
- 找字母 [a-zA-Z]
- 找标点符号 [[:punct:]]
- 我要如何找?看心情找
- 以什么为首 ^key
- 以什么结尾 key$
- 包含什么或不包含什么 [abc] ^[abc] [^abc] ^[^abc]
- 我要找多少呀?
| 元字符 | 功能 | 示例 |
|---|---|---|
| * | 前导字符出现0次或者连续多次 | ab* abbbb |
| . | 除了换行符以外,任意单个字符 | ab. ab8 abu |
| .* | 任意长度的字符 | ab.* adfdfdf |
| [] | 括号里的任意单个字符或一组单个字符 | [abc][0-9][a-z] |
| [^] | 不匹配括号里的任意单个字符或一组单个字符 | [^abc] |
| [3] | 匹配以括号里的任意单个字符开头 | [4] |
| ^[^] | 不匹配以括号里的任意单个字符开头 | |
| ^ | 行的开头 | ^root |
| $ | 行的结尾 | bash$ |
| ^$ | 空行 | |
| \{n\}和{n} | 前导字符连续出现n次 | [0-9]\{3\} |
| \{n,\}和{n,} | 前导字符至少出现n次 | [a-z]{4,} |
| \{n,m\}和{n,m} | 前导字符连续出现n-m次 | go{2,4} |
| \<\> | 精确匹配单词 | \ |
| \(\) | 保留匹配到的字符 | \(hello\) |
| + | 前导字符出现1次或者多次 | [0-9]+ |
| ? | 前导字符出现0次或者1次 | go? |
| | | 或 | ^root|^ftp |
| () | 组字符 | (hello|world)123 |
| \d | perl内置正则 | grep -P \d+ |
| \w | 匹配字母数字下划线 |
五、sed
1. sed用来做啥?
sed是Stream Editor(流编辑器)的缩写,简称流编辑器;用来处理文件的。
2. sed如何处理文件?
sed是一行一行读取文件内容并按照要求进行处理,把处理后的结果输出到屏幕。
- 首先sed读取文件中的一行内容,把其保存在一个临时缓存区中(也称为模式空间)
- 然后根据需求处理临时缓冲区中的行,完成后把该行发送到屏幕上
总结:
- 由于sed把每一行都存在临时缓冲区中,对这个副本进行编辑,所以不会直接修改原文件
- Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作,对文件进行过滤和转换操作
三、sed使用方法介绍
sed常见的语法格式有两种,一种叫命令行模式,另一种叫脚本模式。
1. 命令行格式
㈠ 语法格式
sed [options] ‘处理动作‘ 文件名
常用选项 | 选项 | 说明 | 备注 | | —- | —- | —- | | -e | 进行多项(多次)编辑 | | | -n | 取消默认输出 | 不自动打印模式空间 | | -r | 使用扩展正则表达式 | | | -i | 原地编辑(修改源文件) | | | -f | 指定sed脚本的文件名 | |
常见处理动作
丑话说在前面:以下所有的动作都要在单引号里,你敢出轨,回家跪搓衣板
| 动作 | 说明 | 备注 |
|---|---|---|
| ‘p’ | 打印 | |
| ‘i’ | 在指定行之前插入内容 | 类似vim里的大写O |
| ‘a’ | 在指定行之后插入内容 | 类似vim里的小写o |
| ‘c’ | 替换指定行所有内容 | |
| ‘d’ | 删除指定行 |
㈡ 举例说明
- 文件准备
# vim a.txtroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin298374837483172.16.0.25410.1.1.1
① 对文件进行增、删、改、查操作
语法:sed 选项 ‘定位+命令’ 需要处理的文件
1)打印文件内容
[root@server ~]# sed '' a.txt 对文件什么都不做[root@server ~]# sed -n 'p' a.txt 打印每一行,并取消默认输出[root@server ~]# sed -n '1p' a.txt 打印第1行[root@server ~]# sed -n '2p' a.txt 打印第2行[root@server ~]# sed -n '1,5p' a.txt 打印1到5行[root@server ~]# sed -n '$p' a.txt 打印最后1行
2)增加文件内容
i 地址定位的上面插入
a 下面插入
[root@server ~]# sed '$a99999' a.txt 文件最后一行下面增加内容[root@server ~]# sed 'a99999' a.txt 文件每行下面增加内容[root@server ~]# sed '5a99999' a.txt 文件第5行下面增加内容[root@server ~]# sed '$i99999' a.txt 文件最后一行上一行增加内容[root@server ~]# sed 'i99999' a.txt 文件每行上一行增加内容[root@server ~]# sed '6i99999' a.txt 文件第6行上一行增加内容[root@server ~]# sed '/^uucp/ihello' 以uucp开头行的上一行插入内容
3)修改文件内容
c 替换指定的整行内容
[root@server ~]# sed '5chello world' a.txt 替换文件第5行内容[root@server ~]# sed 'chello world' a.txt 替换文件所有内容[root@server ~]# sed '1,5chello world' a.txt 替换文件1到5号内容为hello world[root@server ~]# sed '/^user01/c888888' a.txt 替换以user01开头的行
4)删除文件内容
[root@server ~]# sed '1d' a.txt 删除文件第1行[root@server ~]# sed '1,5d' a.txt 删除文件1到5行[root@server ~]# sed '$d' a.txt 删除文件最后一行
② 对文件进行搜索替换操作
语法:sed 选项 ‘s/搜索的内容/替换的内容/动作’ 需要处理的文件 其中,s表示search搜索;斜杠/表示分隔符,可以自己定义;动作一般是打印p和全局替换g
[root@server ~]# sed -n 's/root/ROOT/p' 1.txt[root@server ~]# sed -n 's/root/ROOT/gp' 1.txt[root@server ~]# sed -n 's/^#//gp' 1.txt[root@server ~]# sed -n 's@/sbin/nologin@itcast@gp' a.txt[root@server ~]# sed -n 's/\/sbin\/nologin/itcast/gp' a.txt[root@server ~]# sed -n '10s#/sbin/nologin#itcast#p' a.txtuucp:x:10:14:uucp:/var/spool/uucp:itcast[root@server ~]# sed -n 's@/sbin/nologin@itcastheima@p' 2.txt注意:搜索替换中的分隔符可以自己指定[root@server ~]# sed -n '1,5s/^/#/p' a.txt 注释掉文件的1-5行内容#root:x:0:0:root:/root:/bin/bash#bin:x:1:1:bin:/bin:/sbin/nologin#daemon:x:2:2:daemon:/sbin:/sbin/nologin#adm:x:3:4:adm:/var/adm:/sbin/nologin#lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
③ 其他命令
| 命令 | 解释 | 备注 |
|---|---|---|
| r | 从另外文件中读取内容 | |
| w | 内容另存为 | |
| & | 保存查找串以便在替换串中引用 | 和\(\)相同 |
| = | 打印行号 | |
| ! | 对所选行以外的所有行应用命令,放到行数之后 | ‘1,5!’ |
| q | 退出 |
举例说明:
r 从文件中读取输入行w 将所选的行写入文件[root@server ~]# sed '3r /etc/hosts' 2.txt[root@server ~]# sed '$r /etc/hosts' 2.txt[root@server ~]# sed '/root/w a.txt' 2.txt[root@server ~]# sed '/[0-9]{4}/w a.txt' 2.txt[root@server ~]# sed -r '/([0-9]{1,3}\.){3}[0-9]{1,3}/w b.txt' 2.txt! 对所选行以外的所有行应用命令,放到行数之后[root@server ~]# sed -n '1!p' 1.txt[root@server ~]# sed -n '4p' 1.txt[root@server ~]# sed -n '4!p' 1.txt[root@server ~]# cat -n 1.txt[root@server ~]# sed -n '1,17p' 1.txt[root@server ~]# sed -n '1,17!p' 1.txt& 保存查找串以便在替换串中引用 \(\)[root@server ~]# sed -n '/root/p' a.txtroot:x:0:0:root:/root:/bin/bash[root@server ~]# sed -n 's/root/#&/p' a.txt#root:x:0:0:root:/root:/bin/bash# sed -n 's/^root/#&/p' passwd 注释掉以root开头的行# sed -n -r 's/^root|^stu/#&/p' /etc/passwd 注释掉以root开头或者以stu开头的行# sed -n '1,5s/^[a-z].*/#&/p' passwd 注释掉1~5行中以任意小写字母开头的行# sed -n '1,5s/^/#/p' /etc/passwd 注释1~5行或者sed -n '1,5s/^/#/p' passwd 以空开头的加上#sed -n '1,5s/^#//p' passwd 以#开头的替换成空[root@server ~]# sed -n '/^root/p' 1.txt[root@server ~]# sed -n 's/^root/#&/p' 1.txt[root@server ~]# sed -n 's/\(^root\)/#\1/p' 1.txt[root@server ~]# sed -nr '/^root|^stu/p' 1.txt[root@server ~]# sed -nr 's/^root|^stu/#&/p' 1.txt= 打印行号# sed -n '/bash$/=' passwd 打印以bash结尾的行的行号# sed -ne '/root/=' -ne '/root/p' passwd# sed -n '/nologin$/=;/nologin$/p' 1.txt# sed -ne '/nologin$/=' -ne '/nologin$/p' 1.txtq 退出# sed '5q' 1.txt# sed '/mail/q' 1.txt# sed -r '/^yunwei|^mail/q' 1.txt[root@server ~]# sed -n '/bash$/p;10q' 1.txtROOT:x:0:0:root:/root:/bin/bash综合运用:[root@server ~]# sed -n '1,5s/^/#&/p' 1.txt#root:x:0:0:root:/root:/bin/bash#bin:x:1:1:bin:/bin:/sbin/nologin#daemon:x:2:2:daemon:/sbin:/sbin/nologin#adm:x:3:4:adm:/var/adm:/sbin/nologin#lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin[root@server ~]# sed -n '1,5s/\(^\)/#\1/p' 1.txt#root:x:0:0:root:/root:/bin/bash#bin:x:1:1:bin:/bin:/sbin/nologin#daemon:x:2:2:daemon:/sbin:/sbin/nologin#adm:x:3:4:adm:/var/adm:/sbin/nologin#lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
④ 其他选项
-e 多项编辑-r 扩展正则-i 修改原文件[root@server ~]# sed -ne '/root/p' 1.txt -ne '/root/='root:x:0:0:root:/root:/bin/bash1[root@server ~]# sed -ne '/root/=' -ne '/root/p' 1.txt1root:x:0:0:root:/root:/bin/bash在1.txt文件中的第5行的前面插入“hello world”;在1.txt文件的第8行下面插入“哈哈哈哈”[root@server ~]# sed -e '5ihello world' -e '8a哈哈哈哈哈' 1.txt -e '5=;8='sed -n '1,5p' 1.txtsed -ne '1p' -ne '5p' 1.txtsed -ne '1p;5p' 1.txt过滤vsftpd.conf文件中以#开头和空行:[root@server ~]# grep -Ev '^#|^$' /etc/vsftpd/vsftpd.conf[root@server ~]# sed -e '/^#/d' -e '/^$/d' /etc/vsftpd/vsftpd.conf[root@server ~]# sed '/^#/d;/^$/d' /etc/vsftpd/vsftpd.conf[root@server ~]# sed -r '/^#|^$/d' /etc/vsftpd/vsftpd.conf过滤smb.conf文件中生效的行:# sed -e '/^#/d' -e '/^;/d' -e '/^$/d' -e '/^\t$/d' -e '/^\t#/d' smb.conf# sed -r '/^(#|$|;|\t#|\t$)/d' smb.conf# sed -e '/^#/d' -e '/^;/d' -e '/^$/d' -e '/^\t$/d' -e '/^\t#/' smb.conf[root@server ~]# grep '^[^a-z]' 1.txt[root@server ~]# sed -n '/^[^a-z]/p' 1.txt过滤出文件中的IP地址:[root@server ~]# grep -E '([0-9]{1,3}\.){3}[0-9]{1,3}' 1.txt192.168.0.254[root@server ~]# sed -nr '/([0-9]{1,3}\.){3}[0-9]{1,3}/p' 1.txt192.168.0.254[root@server ~]# grep -o -E '([0-9]{1,3}\.){3}[0-9]{1,3}' 2.txt10.1.1.110.1.1.255255.255.255.0[root@server ~]# sed -nr '/([0-9]{1,3}\.){3}[0-9]{1,3}/p' 2.txt10.1.1.110.1.1.255255.255.255.0过滤出ifcfg-eth0文件中的IP、子网掩码、广播地址[root@server shell06]# grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}' ifcfg-eth010.1.1.1255.255.255.010.1.1.254[root@server shell06]# sed -nr '/([0-9]{1,3}\.){3}[0-9]{1,3}/p' ifcfg-eth0|cut -d'=' -f210.1.1.1255.255.255.010.1.1.254[root@server shell06]# sed -nr '/([0-9]{1,3}\.){3}[0-9]{1,3}/p' ifcfg-eth0|sed -n 's/[A-Z=]//gp'10.1.1.1255.255.255.010.1.1.254[root@server shell06]# ifconfig eth0|sed -n '2p'|sed -n 's/[:a-Z]//gp'|sed -n 's/ /\n/gp'|sed '/^$/d'10.1.1.110.1.1.255255.255.255.0[root@server shell06]# ifconfig | sed -nr '/([0-9]{1,3}\.)[0-9]{1,3}/p' | head -1|sed -r 's/([a-z:]|[A-Z/t])//g'|sed 's/ /\n/g'|sed '/^$/d'[root@server shell06]# ifconfig eth0|sed -n '2p'|sed -n 's/.*addr:\(.*\) Bcast:\(.*\) Mask:\(.*\)/\1\n\2\n\3/p'10.1.1.110.1.1.255255.255.255.0-i 选项 直接修改原文件# sed -i 's/root/ROOT/;s/stu/STU/' 11.txt# sed -i '17{s/YUNWEI/yunwei/;s#/bin/bash#/sbin/nologin#}' 1.txt# sed -i '1,5s/^/#&/' a.txt注意:-ni 不要一起使用p命令 不要再使用-i时使用
⑤ sed结合正则使用
sed 选项 ‘sed命令或者正则表达式或者地址定位==’== 文件名
- 定址用于决定对哪些行进行编辑。地址的形式可以是数字、正则表达式、或二者的结合。
- 如果没有指定地址,sed将处理输入文件的所有行。 | 正则 | 说明 | 备注 | | —- | —- | —- | | /key/ | 查询包含关键字的行 | sed -n ‘/root/p’ 1.txt | | /key1/,/key2/ | 匹配包含两个关键字之间的行 | sed -n ‘/^adm/,/^mysql/p’ 1.txt | | /key/,x | 从匹配关键字的行开始到文件第x行之间的行(包含关键字所在行) | sed -n ‘/^ftp/,7p’ | | x,/key/ | 从文件的第x行开始到与关键字的匹配行之间的行 | | | x,y! | 不包含x到y行 | | | /key/! | 不包括关键字的行 | sed -n ‘/bash$/!p’ 1.txt |
2. 脚本格式
㈠ 用法
# sed -f scripts.sh file //使用脚本处理文件建议使用 ./sed.sh file脚本的第一行写上#!/bin/sed -f1,5ds/root/hello/g3i7775i888a999p
㈡ 注意事项
1) 脚本文件是一个sed的命令行清单。'commands'2) 在每行的末尾不能有任何空格、制表符(tab)或其它文本。3) 如果在一行中有多个命令,应该用分号分隔。4) 不需要且不可用引号保护命令5) #号开头的行为注释
㈢举例说明
# cat passwdstu3:x:509:512::/home/user3:/bin/bashstu4:x:510:513::/home/user4:/bin/bashstu5:x:511:514::/home/user5:/bin/bash# cat sed.sh#!/bin/sed -f2a\******************2,$s/stu/user/$a\we inster new lines/^[a-z].*/#&/[root@server ~]# cat 1.sed#!/bin/sed -f3a**********************$chelloworld1,3s/^/#&/[root@server ~]# sed -f 1.sed -i 11.txt[root@server ~]# cat 11.txt#root:x:0:0:root:/root:/bin/bash#bin:x:1:1:bin:/bin:/sbin/nologin#daemon:x:2:2:daemon:/sbin:/sbin/nologin**********************adm:x:3:4:adm:/var/adm:/sbin/nologinhelloworld
3. 总结
1、正则表达式必须以”/“前后规范间隔例如:sed '/root/d' file例如:sed '/^root/d' file2、如果匹配的是扩展正则表达式,需要使用-r选来扩展sedgrep -Esed -r+ ? () {n,m} | \d注意:在正则表达式中如果出现特殊字符(^$.*/[]),需要以前导 "\" 号做转义eg:sed '/\$foo/p' file3、逗号分隔符例如:sed '5,7d' file 删除5到7行例如:sed '/root/,/ftp/d' file删除第一个匹配字符串"root"到第一个匹配字符串"ftp"的所有行本行不找 循环执行4、组合方式例如:sed '1,/foo/d' file 删除第一行到第一个匹配字符串"foo"的所有行例如:sed '/foo/,+4d' file 删除从匹配字符串”foo“开始到其后四行为止的行例如:sed '/foo/,~3d' file 删除从匹配字符串”foo“开始删除到3的倍数行(文件中)例如:sed '1~5d' file 从第一行开始删每五行删除一行例如:sed -nr '/foo|bar/p' file 显示配置字符串"foo"或"bar"的行例如:sed -n '/foo/,/bar/p' file 显示匹配从foo到bar的行例如:sed '1~2d' file 删除奇数行例如:sed '0-2d' file 删除偶数行 sed '1~2!d' file5、特殊情况例如:sed '$d' file 删除最后一行例如:sed '1d' file 删除第一行6、其他:sed 's/.//' a.txt 删除每一行中的第一个字符sed 's/.//2' a.txt 删除每一行中的第二个字符sed 's/.//N' a.txt 从文件中第N行开始,删除每行中第N个字符(N>2)sed 's/.$//' a.txt 删除每一行中的最后一个字符[root@server ~]# cat 2.txt1 a2 b3 c4 d5 e6 f7 u8 k9 o[root@server ~]# sed '/c/,~2d' 2.txt1 a2 b5 e6 f7 u8 k9 o
六、awk
一、awk介绍
1. awk概述
- awk是一种编程语言,主要用于在linux/unix下对文本和数据进行处理,是linux/unix下的一个工具。数据可以来自标准输入、一个或多个文件,或其它命令的输出。
- awk的处理文本和数据的方式:逐行扫描文件,默认从第一行到最后一行,寻找匹配的特定模式的行,并在这些行上进行你想要的操作。
- awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,分别是Alfred Aho、Brian Kernighan、Peter Weinberger。
- gawk是awk的GNU版本,它提供了Bell实验室和GNU的一些扩展。
- 下面介绍的awk是以GNU的gawk为例的,在linux系统中已把awk链接到gawk,所以下面全部以awk进行介绍。
2. awk能干啥?
- awk用来处理文件和数据的,是类unix下的一个工具,也是一种编程语言
- 可以用来统计数据,比如网站的访问量,访问的IP量等等
- 支持条件判断,支持for和while循环
二、awk使用方式
1. 命令行模式使用
㈠ 语法结构
注意: 命令部分需要用单引号,如果是双引号会无效,并且输出awk 选项 '命令部分' 文件名特别说明:引用shell变量需用双引号引起
㈡ 常用选项介绍
- -F 定义字段分割符号,默认的分隔符是空格
-
㈢ ‘命名部分说明’
正则表达式,地址定位
'/root/{awk语句}' sed中: '/root/p''NR==1,NR==5{awk语句}' sed中: '1,5p''/^root/,/^ftp/{awk语句}' sed中:'/^root/,/^ftp/p'
{awk语句1;awk语句2;…}
'{print $0;print $1}' sed中:'p''NR==5{print $0}' sed中:'5p'注:awk命令语句间用分号间隔
BEGIN…END….
'BEGIN{awk语句};{处理中};END{awk语句}''BEGIN{awk语句};{处理中}''{处理中};END{awk语句}'
2. 脚本模式使用
㈠ 脚本编写
#!/bin/awk -f 定义魔法字符以下是awk引号里的命令清单,不要用引号保护命令,多个命令用分号间隔BEGIN{FS=":"}NR==1,NR==3{print $1"\t"$NF}...
㈡ 脚本执行
方法1:awk 选项 -f awk的脚本文件 要处理的文本文件awk -f awk.sh filenamesed -f sed.sh -i filename方法2:./awk的脚本文件(或者绝对路径) 要处理的文本文件./awk.sh filename./sed.sh filename
三、 awk内部相关变量
| 变量 | 变量说明 | 备注 | | —- | —- | —- | | $0 | 当前处理行的所有记录 | | | $1,$2,$3…$n | 文件中每行以间隔符号分割的不同字段 | awk -F: ‘{print $1,$3}’ | | NF | 当前记录的字段数(列数) | awk -F: ‘{print NF}’ | | $NF | 最后一列 | $(NF-1)表示倒数第二列 | | FNR/NR | 行号 | | | FS | 定义间隔符 | ‘BEGIN{FS=”:”};{print $1,$3}’ | | OFS | 定义输出字段分隔符,默认空格 | ‘BEGIN{OFS=”\t”};print $1,$3}’ | | RS | 输入记录分割符,默认换行 | ‘BEGIN{RS=”\t”};{print $0}’ | | ORS | 输出记录分割符,默认换行 | ‘BEGIN{ORS=”\n\n”};{print $1,$3}’ | | FILENAME | 当前输入的文件名 | |
1、常用内置变量举例
# awk -F: '{print $1,$(NF-1)}' 1.txt# awk -F: '{print $1,$(NF-1),$NF,NF}' 1.txt# awk '/root/{print $0}' 1.txt# awk '/root/' 1.txt# awk -F: '/root/{print $1,$NF}' 1.txtroot /bin/bash# awk -F: '/root/{print $0}' 1.txtroot:x:0:0:root:/root:/bin/bash# awk 'NR==1,NR==5' 1.txt# awk 'NR==1,NR==5{print $0}' 1.txt# awk 'NR==1,NR==5;/^root/{print $0}' 1.txtroot:x:0:0:root:/root:/bin/bashroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
2、内置变量分隔符举例
FS和OFS:# awk 'BEGIN{FS=":"};/^root/,/^lp/{print $1,$NF}' 1.txt# awk -F: 'BEGIN{OFS="\t\t"};/^root/,/^lp/{print $1,$NF}' 1.txtroot /bin/bashbin /sbin/nologindaemon /sbin/nologinadm /sbin/nologinlp /sbin/nologin# awk -F: 'BEGIN{OFS="@@@"};/^root/,/^lp/{print $1,$NF}' 1.txtroot@@@/bin/bashbin@@@/sbin/nologindaemon@@@/sbin/nologinadm@@@/sbin/nologinlp@@@/sbin/nologin[root@server shell07]#RS和ORS:修改源文件前2行增加制表符和内容:vim 1.txtroot:x:0:0:root:/root:/bin/bash hello worldbin:x:1:1:bin:/bin:/sbin/nologin test1 test2# awk 'BEGIN{RS="\t"};{print $0}' 1.txt# awk 'BEGIN{ORS="\t"};{print $0}' 1.txt
四、 awk工作原理
awk -F: '{print $1,$3}' /etc/passwd
- awk使用一行作为输入,并将这一行赋给内部变量$0,每一行也可称为一个记录,以换行符(RS)结束
- 每行被间隔符:(默认为空格或制表符)分解成字段(或域),每个字段存储在已编号的变量中,从$1开始
问:awk如何知道用空格来分隔字段的呢?
答:因为有一个内部变量FS来确定字段分隔符。初始时,FS赋为空格 - awk使用print函数打印字段,打印出来的字段会以空格分隔,因为$1,$3之间有一个逗号。逗号比较特殊,它映射为另一个内部变量,称为输出字段分隔符OFS,OFS默认为空格
- awk处理完一行后,将从文件中获取另一行,并将其存储在$0中,覆盖原来的内容,然后将新的字符串分隔成字段并进行处理。该过程将持续到所有行处理完毕
五、awk使用进阶
1. 格式化输出
```bash print函数 类似echo “hello world”print和printfdate |awk ‘{print “Month: “$2 “\nYear: “$NF}’
awk -F: ‘{print “username is: “ $1 “\t uid is: “$3}’ /etc/passwd
printf函数 类似echo -nawk -F: ‘{printf “%-15s %-10s %-15s\n”, $1,$2,$3}’ /etc/passwd
awk -F: ‘{printf “|%15s| %10s| %15s|\n”, $1,$2,$3}’ /etc/passwd
awk -F: ‘{printf “|%-15s| %-10s| %-15s|\n”, $1,$2,$3}’ /etc/passwd
awk ‘BEGIN{FS=”:”};{printf “%-15s %-15s %-15s\n”,$1,$6,$NF}’ a.txt %s 字符类型 strings %-20s %d 数值类型
占15字符
- 表示左对齐,默认是右对齐
printf默认不会在行尾自动换行,加\n
<a name="tmoi4"></a>### 2. awk变量定义```bash# awk -v NUM=3 -F: '{ print $NUM }' /etc/passwd# awk -v NUM=3 -F: '{ print NUM }' /etc/passwd# awk -v num=1 'BEGIN{print num}'1# awk -v num=1 'BEGIN{print $num}'注意:awk中调用定义的变量不需要加$
3. awk中BEGIN…END使用
①BEGIN:表示在程序开始前执行
②END :表示所有文件处理完后执行
③用法:'BEGIN{开始处理之前};{处理中};END{处理结束后}'㈠ 举例说明1
打印最后一列和倒数第二列(登录shell和家目录) ```bash awk -F: ‘BEGIN{ print “Login_shell\t\tLogin_home\n*“};{print $NF”\t\t”$(NF-1)};END{print “**“}’ 1.txt awk ‘BEGIN{ FS=”:”;print “Login_shell\tLogin_home\n*“};{print $NF”\t”$(NF-1)};END{print “**“}’ 1.txt Login_shell Login_home
/bin/bash /root /sbin/nologin /bin /sbin/nologin /sbin /sbin/nologin /var/adm /sbin/nologin /var/spool/lpd /bin/bash /home/redhat /bin/bash /home/user01 /sbin/nologin /var/named /bin/bash /home/u01 /bin/bash /home/YUNWEI
<a name="xVXka"></a>#### ㈡ 举例说明2**打印/etc/passwd里的用户名、家目录及登录shell**```bashu_name h_dir shell******************************************************awk -F: 'BEGIN{OFS="\t\t";print"u_name\t\th_dir\t\tshell\n***************************"};{printf "%-20s %-20s %-20s\n",$1,$(NF-1),$NF};END{print "****************************"}'# awk -F: 'BEGIN{print "u_name\t\th_dir\t\tshell" RS "*****************"} {printf "%-15s %-20s %-20s\n",$1,$(NF-1),$NF}END{print "***************************"}' /etc/passwd格式化输出:echo printecho -n printf{printf "%-15s %-20s %-20s\n",$1,$(NF-1),$NF}
4. awk和正则的综合运用
| 运算符 | 说明 |
|---|---|
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| ~ | 匹配 |
| !~ | 不匹配 |
| ! | 逻辑非 |
| && | 逻辑与 |
| || | 逻辑或 |
㈠ 举例说明
从第一行开始匹配到以lp开头行awk -F: 'NR==1,/^lp/{print $0 }' passwd从第一行到第5行awk -F: 'NR==1,NR==5{print $0 }' passwd从以lp开头的行匹配到第10行awk -F: '/^lp/,NR==10{print $0 }' passwd从以root开头的行匹配到以lp开头的行awk -F: '/^root/,/^lp/{print $0}' passwd打印以root开头或者以lp开头的行awk -F: '/^root/ || /^lp/{print $0}' passwdawk -F: '/^root/;/^lp/{print $0}' passwd显示5-10行awk -F':' 'NR>=5 && NR<=10 {print $0}' /etc/passwdawk -F: 'NR<10 && NR>5 {print $0}' passwd打印30-39行以bash结尾的内容:[root@MissHou shell06]# awk 'NR>=30 && NR<=39 && $0 ~ /bash$/{print $0}' passwdstu1:x:500:500::/home/stu1:/bin/bashyunwei:x:501:501::/home/yunwei:/bin/bashuser01:x:502:502::/home/user01:/bin/bashuser02:x:503:503::/home/user02:/bin/bashuser03:x:504:504::/home/user03:/bin/bash[root@MissHou shell06]# awk 'NR>=3 && NR<=8 && /bash$/' 1.txtstu7:x:1007:1007::/rhome/stu7:/bin/bashstu8:x:1008:1008::/rhome/stu8:/bin/bashstu9:x:1009:1009::/rhome/stu9:/bin/bash打印文件中1-5并且以root开头的行[root@MissHou shell06]# awk 'NR>=1 && NR<=5 && $0 ~ /^root/{print $0}' 1.txtroot:x:0:0:root:/root:/bin/bash[root@MissHou shell06]# awk 'NR>=1 && NR<=5 && $0 !~ /^root/{print $0}' 1.txtbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologin理解;号和||的含义:[root@MissHou shell06]# awk 'NR>=3 && NR<=8 || /bash$/' 1.txt[root@MissHou shell06]# awk 'NR>=3 && NR<=8;/bash$/' 1.txt打印IP地址# ifconfig eth0|awk 'NR>1 {print $2}'|awk -F':' 'NR<2 {print $2}'# ifconfig eth0|grep Bcast|awk -F':' '{print $2}'|awk '{print $1}'# ifconfig eth0|grep Bcast|awk '{print $2}'|awk -F: '{print $2}'# ifconfig eth0|awk NR==2|awk -F '[ :]+' '{print $4RS$6RS$8}'# ifconfig eth0|awk -F"[ :]+" '/inet addr:/{print $4}'
(二)练习
显示可以登录操作系统的用户所有信息 从第7列匹配以bash结尾,输出整行(当前行所有的列)
[root@MissHou ~] awk '/bash$/{print $0}' /etc/passwd[root@MissHou ~] awk '/bash$/{print $0}' /etc/passwd[root@MissHou ~] awk '/bash$/' /etc/passwd[root@MissHou ~] awk -F: '$7 ~ /bash/' /etc/passwd[root@MissHou ~] awk -F: '$NF ~ /bash/' /etc/passwd[root@MissHou ~] awk -F: '$0 ~ /bash/' /etc/passwd[root@MissHou ~] awk -F: '$0 ~ /\/bin\/bash/' /etc/passwd
显示可以登录系统的用户名
# awk -F: '$0 ~ /\/bin\/bash/{print $1}' /etc/passwd
打印出系统中普通用户的UID和用户名
500 stu1501 yunwei502 user01503 user02504 user03# awk -F: 'BEGIN{print "UID\tUSERNAME"} {if($3>=500 && $3 !=65534 ) {print $3"\t"$1} }' /etc/passwdUID USERNAME# awk -F: '{if($3 >= 500 && $3 != 65534) print $1,$3}' a.txtredhat 508user01 509u01 510YUNWEI 511
5. awk的脚本编程
㈠ 流程控制语句
if…elif…else结构
if [xxxx];thenxxxxelif [xxx];thenxxx....else...fiif...else if...else语句:格式:{ if(表达式1){语句;语句;...}else if(表达式2){语句;语句;...}else if(表达式3){语句;语句;...}else{语句;语句;...}}awk -F: '{ if($3==0) {print $1,":是管理员"} else if($3>=1 && $3<=499 || $3==65534 ) {print $1,":是系统用户"} else {print $1,":是普通用户"}}'awk -F: '{ if($3==0) {i++} else if($3>=1 && $3<=499 || $3==65534 ) {j++} else {k++}};END{print "管理员个数为:"i "\n系统用户个数为:"j"\n普通用户的个数为:"k }'# awk -F: '{if($3==0) {print $1,"is admin"} else if($3>=1 && $3<=499 || $3==65534) {print $1,"is sys users"} else {print $1,"is general user"} }' a.txtroot is adminbin is sys usersdaemon is sys usersadm is sys userslp is sys usersredhat is general useruser01 is general usernamed is sys usersu01 is general userYUNWEI is general userawk -F: '{ if($3==0) {print $1":管理员"} else if($3>=1 && $3<500 || $3==65534 ) {print $1":是系统用户"} else {print $1":是普通用户"}}' /etc/passwdawk -F: '{if($3==0) {i++} else if($3>=1 && $3<500 || $3==65534){j++} else {k++}};END{print "管理员个数为:" i RS "系统用户个数为:"j RS "普通用户的个数为:"k }' /etc/passwd管理员个数为:1系统用户个数为:28普通用户的个数为:27# awk -F: '{ if($3==0) {print $1":是管理员"} else if($3>=500 && $3!=65534) {print $1":是普通用户"} else {print $1":是系统用户"}}' passwdawk -F: '{if($3==0){i++} else if($3>=500){k++} else{j++}} END{print i; print k; print j}' /etc/passwdawk -F: '{if($3==0){i++} else if($3>999){k++} else{j++}} END{print "管理员个数: "i; print "普通用个数: "k; print "系统用户: "j}' /etc/passwd如果是普通用户打印默认shell,如果是系统用户打印用户名# awk -F: '{if($3>=1 && $3<500 || $3 == 65534) {print $1} else if($3>=500 && $3<=60000 ) {print $NF} }' /etc/passwd
㈡ 循环语句
① for循环
打印1~5for ((i=1;i<=5;i++));do echo $i;done# awk 'BEGIN { for(i=1;i<=5;i++) {print i} }'打印1~10中的奇数# for ((i=1;i<=10;i+=2));do echo $i;done|awk '{sum+=$0};END{print sum}'# awk 'BEGIN{ for(i=1;i<=10;i+=2) {print i} }'# awk 'BEGIN{ for(i=1;i<=10;i+=2) print i }'计算1-5的和# awk 'BEGIN{sum=0;for(i=1;i<=5;i++) sum+=i;print sum}'# awk 'BEGIN{for(i=1;i<=5;i++) (sum+=i);{print sum}}'# awk 'BEGIN{for(i=1;i<=5;i++) (sum+=i);print sum}'
② while循环
打印1-5# i=1;while (($i<=5));do echo $i;let i++;done# awk 'BEGIN { i=1;while(i<=5) {print i;i++} }'打印1~10中的奇数# awk 'BEGIN{i=1;while(i<=10) {print i;i+=2} }'计算1-5的和# awk 'BEGIN{i=1;sum=0;while(i<=5) {sum+=i;i++}; print sum }'# awk 'BEGIN {i=1;while(i<=5) {(sum+=i) i++};print sum }'
③ 嵌套循环
嵌套循环:#!/bin/bashfor ((y=1;y<=5;y++))dofor ((x=1;x<=$y;x++))doecho -n $xdoneechodoneawk 'BEGIN{ for(y=1;y<=5;y++) {for(x=1;x<=y;x++) {printf x} ;print } }'# awk 'BEGIN { for(y=1;y<=5;y++) { for(x=1;x<=y;x++) {printf x};print} }'112123123412345# awk 'BEGIN{ y=1;while(y<=5) { for(x=1;x<=y;x++) {printf x};y++;print}}'112123123412345尝试用三种方法打印99口诀表:#awk 'BEGIN{for(y=1;y<=9;y++) { for(x=1;x<=y;x++) {printf x"*"y"="x*y"\t"};print} }'#awk 'BEGIN{for(y=1;y<=9;y++) { for(x=1;x<=y;x++) printf x"*"y"="x*y"\t";print} }'#awk 'BEGIN{i=1;while(i<=9){for(j=1;j<=i;j++) {printf j"*"i"="j*i"\t"};print;i++ }}'#awk 'BEGIN{for(i=1;i<=9;i++){j=1;while(j<=i) {printf j"*"i"="i*j"\t";j++};print}}'循环的控制:break 条件满足的时候中断循环continue 条件满足的时候跳过循环# awk 'BEGIN{for(i=1;i<=5;i++) {if(i==3) break;print i} }'12# awk 'BEGIN{for(i=1;i<=5;i++){if(i==3) continue;print i}}'1245
6. awk算数运算
```
- / %(模) ^(幂2^3)
可以在模式中执行计算,awk都将按浮点数方式执行算术运算
awk ‘BEGIN{print 1+1}’
awk ‘BEGIN{print 1**1}’
awk ‘BEGIN{print 2**3}’
awk ‘BEGIN{print 2/3}’
<a name="WoolR"></a>## 六、awk统计案例<a name="V2xYm"></a>### 1、统计系统中各种类型的shell```bash# awk -F: '{ shells[$NF]++ };END{for (i in shells) {print i,shells[i]} }' /etc/passwdbooks[linux]++books[linux]=1shells[/bin/bash]++shells[/sbin/nologin]++/bin/bash 5/sbin/nologin 6shells[/bin/bash]++ ashells[/sbin/nologin]++ bshells[/sbin/shutdown]++ cbooks[linux]++books[php]++
2、统计网站访问状态
# ss -antp|grep 80|awk '{states[$1]++};END{for(i in states){print i,states[i]}}'TIME_WAIT 578ESTABLISHED 1LISTEN 1# ss -an |grep :80 |awk '{states[$2]++};END{for(i in states){print i,states[i]}}'LISTEN 1ESTAB 5TIME-WAIT 25# ss -an |grep :80 |awk '{states[$2]++};END{for(i in states){print i,states[i]}}' |sort -k2 -rnTIME-WAIT 18ESTAB 8LISTEN 1
3、统计访问网站的每个IP的数量
# netstat -ant |grep :80 |awk -F: '{ip_count[$8]++};END{for(i in ip_count){print i,ip_count[i]} }' |sort# ss -an |grep :80 |awk -F":" '!/LISTEN/{ip_count[$(NF-1)]++};END{for(i in ip_count){print i,ip_count[i]}}' |sort -k2 -rn |head
4、统计网站日志中PV量
名词解释:统计Apache/Nginx日志中某一天的PV量 <统计日志># grep '27/Jul/2017' mysqladmin.cc-access_log |wc -l14519统计Apache/Nginx日志中某一天不同IP的访问量 <统计日志># grep '27/Jul/2017' mysqladmin.cc-access_log |awk '{ips[$1]++};END{for(i in ips){print i,ips[i]} }' |sort -k2 -rn |head# grep '07/Aug/2017' access.log |awk '{ips[$1]++};END{for(i in ips){print i,ips[i]} }' |awk '$2>100' |sort -k2 -rn
网站浏览量(PV) 名词:PV=PageView (网站浏览量) 说明:指页面的浏览次数,用以衡量网站用户访问的网页数量。多次打开同一页面则浏览量累计。用户每打开一个页面便记录1次PV。
名词:VV = Visit View(访问次数) 说明:从访客来到您网站到最终关闭网站的所有页面离开,计为1次访问。若访客连续30分钟没有新开和刷新页面,或者访客关闭了浏览器,则被计算为本次访问结束。
独立访客(UV) 名词:UV= Unique Visitor(独立访客数) 说明:1天内相同的访客多次访问您的网站只计算1个UV。
独立IP(IP) 名词:IP=独立IP数 说明:指1天内使用不同IP地址的用户访问网站的数量。同一IP无论访问了几个页面,独立IP数均为1
- / %(模) ^(幂2^3)
可以在模式中执行计算,awk都将按浮点数方式执行算术运算
5、用sed或awk输出文件某些行
奇数偶数行打印
第一种方法: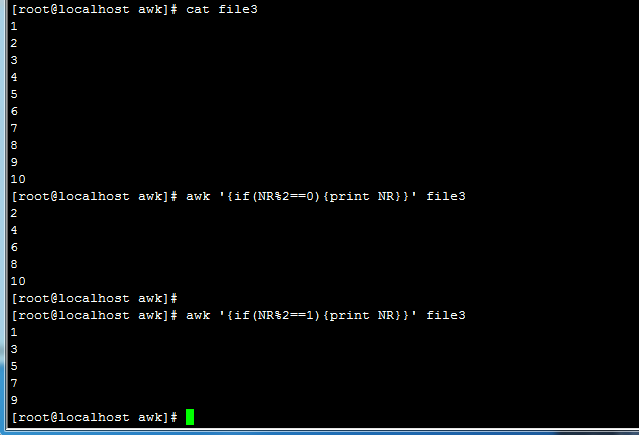
第二种方法: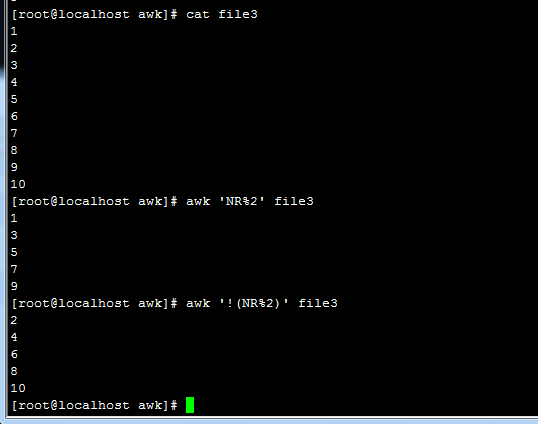
第三种方法: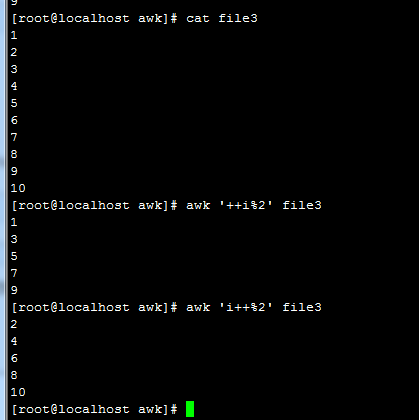
用sed又如何实现奇数行和偶数行的输出呢?
sed通常用-n -p选项结合来输出指定的行,sed有一个步长的设置,例如从第一行开始,每2行输出,则输出奇数行如下:
1. $ sed -n '1~2p' test1.txt2. 1 Jan3. 3 Mar4. 5 May5. 7 Jul6. 9 Sep7. 11 Nov
那么,从第二行开始,每2行输出,就是输出偶数行:
1. $ sed -n '2~2p' test1.txt2. 2 Feb3. 4 Apr4. 6 Jun5. 8 Aug6. 10 Oct7. 12 Dec
注意中间是个波浪号~
那么隔2行输出该怎么做呢?
1. $ awk 'NR%3==1' test1.txt2. 1 Jan3. 4 Apr4. 7 Jul5. 10 Oct
1. $ awk 'NR%3==2' test1.txt2. 2 Feb3. 5 May4. 8 Aug5. 11 Nov
1. $ sed -n '1~3p' test1.txt2. 1 Jan3. 4 Apr4. 7 Jul5. 10 Oct

若有收获,就点个赞吧
0 人点赞
