正则表达式
文本正则化(text normalization)
词汇切分(Word Tokenization)
N = token 数目
V = 词汇 = 类型集合
|V | = 词汇量
词切分(Word Segmentation)
用于像中文这类没有使用空格分隔词汇的语言。
Maximum Matching 算法
标准的基线切分算法,也称为贪心算法。
给定一个中文词汇表,和一个字符串
- 使用一个指向字符串开头的指针
- 在词汇表中查找匹配从指针指向的位置开头的字符串中,最长的词汇
- 将指针移到字符串中步骤 2 找到的那个词汇后面
- 重复步骤 2 ~ 4 直至字符串处理完毕
max_match(list, str):ptr = 0tokens = []while ptr < len(str):match = find_the_longest_match_in_list(list, str[ptr:])tokens.append(match)ptr += len(match)return tokens
词汇规范化和词干提取(Word Normalization and Stemming)
最小编辑距离(minimum edit distance)
一种解决字符串相似性问题的方法。
定义
两个字符串 X(长度为 M) 和 Y(长度为 N) 之间的最小编辑距离 D(M, N)是将一个字符串转换成另一个字符串所需的最小编辑操作(插入、删除、置换)次数。
算法
动态规划
D(i, j).val 表示 X[1..i] 和 Y[1..j] 的最小编辑距离,D(i, j).op 表示到达最小距离的操作
minimum_edit_distance(X, Y):M, N = len(X), len(Y)let D a two dimension array# 初始化for i = 1..M:D(i, 0).val = ifor j = 1..N:D(0, j).val = j# 自底而上for i = 1..M:for j = 1..N:D(i, j).val = D(i-1, j)+1D(i, j).op = 'D' # deleteif D(i, j) > D(i, j-1)+1:D(i, j).val = D(i, j-1)+1D(i, j).op = 'I' # insertif X[i] != Y[j]:if D(i, j) > D(i-1, j-1)+2:D(i, j).val = D(i-1, j-1)+2D(i, j).op = 'S' # substituteelif if D(i, j) > D(i-1, j-1):D(i, j).val = D(i-1, j-1)D(i, j).op = 'S' # substitutereturn D(M, N)
时间复杂度:O(nm)
空间复杂度:O(nm)
带权重最小编辑距离
D(i, j).val 表示 X[1..i] 和 Y[1..j] 的最小编辑距离,D(i, j).op 表示到达最小距离的操作;
del[X[i]] 表示删除 X[i] 的代价,ins[Y[j]] 表示增加 Y[j] 的代价,sub[X[i], Y[j]] 表示替换 X[i] 和 Y[j] 的代价;
minimum_edit_distance(X, Y):M, N = len(X), len(Y)let D a two dimension array# 初始化D(0, 0) = 0for i = 1..M:D(i, 0).val = D(i-1, 0) + del[X[i]]for j = 1..N:D(0, j).val = D(0, j-1) + ins[Y[j]]# 自底而上for i = 1..M:for j = 1..N:D(i, j).val = D(i-1, j)+del[X[i]]D(i, j).op = 'D' # deleteif D(i, j) > D(i, j-1)+1:D(i, j).val = D(i, j-1)+ins[Y[j]]D(i, j).op = 'I' # insertif D(i, j) > D(i-1, j-1)+sub[X[i], Y[j]]:D(i, j).val = D(i-1, j-1)+sub[X[i], Y[j]]D(i, j).op = 'S' # substitutereturn D(M, N)
Needleman-Wunsch 算法
一种全局比对算法,用于完整匹配两个序列。
needleman_wunsch(X, Y, d):M, N = len(X), len(Y)let D a two dimension array# 初始化D[0,0] = 0for i = 1..M:D[i, 0].val = -i * dfor j = 1..N:D[0, j].val = -j * d# 自底而上for i = 1..M:for j = 1..N:# max(delete, insert, match)# s[X[i], Y[j]] 表示 X[1..i] 和 Y[1..j] 这两个序列的相似性得分D[i, j] = max(D[i-1, j]-d, D[i, j-1]-d, D[i-1, j-1]+s[X[i], Y[j]])return D[M, N]
参考
Smith-Waterman 算法
一种进行局部序列对比(相对于全局比对)的算法,用于找出两个序列之间的相似区域。该算法是 Needleman-Wunsch 算法的一个变体。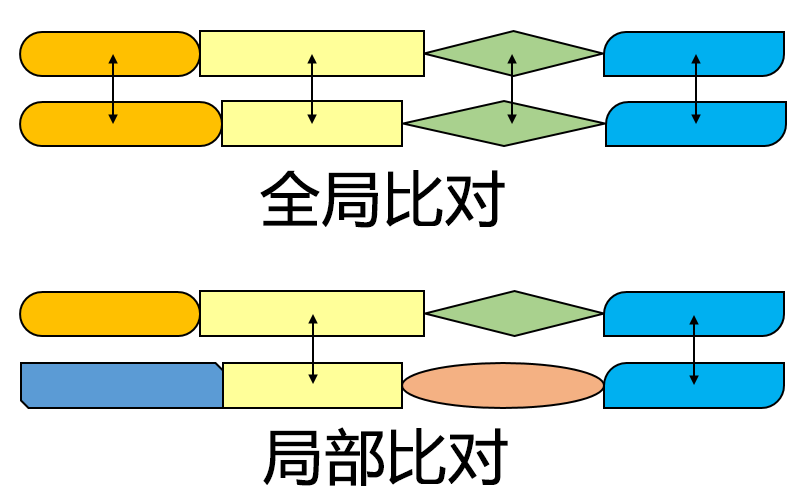
smith_waterman(X, Y):
M, N = len(X), len(Y)
let F a two dimension array
# 初始化
for i = 1..M:
F[i, 0].val = 0
for j = 1..N:
F[0, j].val = 0
# 自底而上
for i = 1..M:
for j = 1..N:
F[i, j] = max(F[i-1, j]-d, F[i, j-1]-d, F[i-1, j-1]+s[X[i], Y[j]], 0)
return F
最佳局部对比(best local alignment)

所有满足 scoring > t 的局部对比
for i = 1..M:
for j = 1..N:
if F[i, j] > t:
traceback(F, i, j)
参考
概率语言模型(Probabilistic Language Model)
概述
目标:计算一个句子或者一个单词序列的概率值
相关任务:在出现某个单词序列的情况下,出现某个单词的概率
计算上述概率值的模型称为一个语言模型(Language Model,LM)
应用
- 机器翻译
- 拼写纠正
- 语音识别
- 摘要
- QA,etc.
链式法则
条件概率

链式法则

将链式法则用于计算句子中的单词联合概率

马尔科夫假设(Markov Assumption)
马尔科夫假设(Markov Assumption):下一个词的出现仅依赖于它前面的一个或几个词。
即:
例如:
或者
N-Grams
一般来说,N-gram 模型是一个不足的语言模型,因为语言具有长距离依赖(long-distance dependencies)。
一元语言模型(Unigram model)
将单词序列的概率视为每个单词的概率的乘积(每个单词之间互相独立):
二元语言模型(bigram model)
每个单词的概率取决于它前面的单词的概率:
极大似然估计(Maximum Likelihood Estimate)

举个🌰
对于文本:
<s> I am Sam </s>
<s> Sam I am </s>
<s> I do not like green eggs and ham </s>
有:
实践问题
在 log 空间中进行( ):
):
- 避免向下溢出
- 加法通常比乘法快
参考
- SRILM
- Google N-Gram Release, August 2006
- Google Book N-grams
模型评估
外部评测(Extrinsic evaluation)
对比模型 A 和模型 B 的最佳评估:
- 将每个模型应用于一个任务(语音识别、MT 系统等)
- 获取每个模型的准确度
- 对比模型 A 和 B 的准确度
问题
耗时。
内部评测(Intrinsic evaluation):困惑度(perplexity)
最佳语言模型是最能预测一个未出现过的测试集的模型:

若有收获,就点个赞吧
0 人点赞
