0.Python解释器
| 解释器 | 说明 |
|---|---|
| CPython | 官方,C语言开发,最广泛的Python解释器 |
| IPython | 一个交互式、功能增强的CPython |
| PyPy | Python语言写的Python解释器,JIT技术,动态编译Python代码 |
| Jython | Python的源代码编译成Java的字节码,跑在JVM上 |
| IronPython | 与Jython类似,运行在.Net平台上的解释器,Python代码被编译成.Net的字节码 |
| stackless | Python的增强版本解释器,不使用CPython的C的栈,采用微线程概念编程,并发 编程 |
语言类型
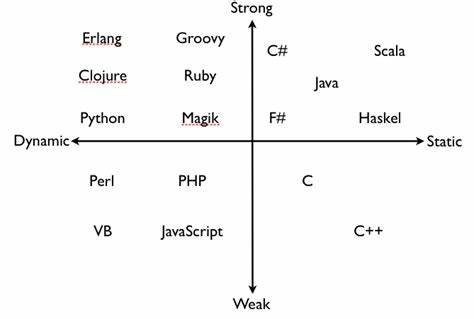
Python是动态语言、强类型语言。 静态语言
- 事先声明变量类型,之后变量的值可以改变,但值的类型不能再改变
- 编译时检查
动态语言
- 不用事先声明类型,随时可以赋值为其他类型
- 编程时不知道是什么类型,很难推断
强类型语言
- 不同类型之间操作,必须先强制类型转换为同一类型。print(‘a’+1)
弱类型语言
- 不同类型间可以操作,自动隐式转换,JavaScript中console.log(1+’a’)
但是要注意的是,强与弱只是一个相对概念,即使是强类型语言也支持隐式类型转换。
1.Python 变量 & 注释
内存中,变量默认一次只能指向一个值,当一个值没有任何变量指向的时候,内存会自动把改数据从内存释放掉,以节省内存空间。
:::success 变量 : 可以改变的量就是变量,实际上指代的是内存的一块空间 :::
1.1 变量的概念
变量:赋值后,可以改变值的标识符
rujia305 = "张三"rujia305 = "李四"rujia305 = "小明"print(rujia305)
1.2 变量的3种声明形式
# 1a = 100b = 101print(a)print(b)# 2a,b = 200,201# print(值1,值2,值3, ..... ) 一行打印所有变量print(a , b)# 3a = b = 300print(a, b)
1.3 变量的命名
标识符
- 一个名字,用来指代一个值
- 只能是字母、下划线和数字
- 只能以字母或下划线开头
- 不能是python的关键字,例如def、class就不能作为标识符
- Python是大小写敏感的
标识符约定: 不允许使用中文,也不建议使用拼音 不要使用歧义单词,例如class_ 在python中不要随便使用下划线开头的标识符
标识符本质: 每一个标识符对应一个具有数据结构的值,但是这个值不方便直接访问,程序员就可以通过其对应的标识符来访问数据,标识符就是一个指代。一句话,标识符是给程序员编程使用的。
"""变量的命名字母数字下划线,首字符不能为数字严格区分大小写,且不能使用关键字变量命名有意义,且不能使用中文哦"""# abc123 = 1# 123abdc error________1_ = 1# ___@@_ = 2 error# a__________ = 90# 1____ = 10 error# 严格区分大小写abc = 10ABC = 11print(abc) # 10print(ABC) # 11# 关键字 : 系统预设的相关属性和函数或者特殊意义的变量;# 引入 模块(文件)import keyword# 模块.属性 (文件.变量)print(keyword.kwlist)"""['False', 'None', 'True', 'and', 'as', 'assert','break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except','finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda','nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while','with', 'yield']"""# 系统预设的相关关键字不能被替换覆盖,不要使用改名字作为变量名;"""print = 100print(1)"""# 起名字要见名知意mycar = "特斯拉"youcar = "五菱宏光"asldkfjaskldjfklasdjfklasjdklfjasdkl = "宝马" # 不推荐# 中文命名变量不会报错的,但是严禁使用中文 = "小明"print(中文)n = "小明"print(n)"""(1) 字符编码:中文命名的变量容易乱码;utf-8(万国码): 一个中文占用3个字节,字母数字其他符号占用1个字节gbk (国标码) : 一个中文占用2个字节,字母数字其他符号占用1个字节(2) 占用空间:中文命名变量比英文命名变量占用更大的空间."""
1.4 变量的交换
a = 18b = 19# 通用写法tmp = aa = bb = tmpprint(a,b)# python特有a = 18b = 19a,b = b,aprint(a,b)
1.5 常量
- 一旦赋值就不能改变值的标识符
- python中无法定义常量
```python
(5) 常量 : 永远不变的量(约定俗成:把每个字母都变成大写)
BIRTHDAY = “1010” ID_CARD = 210205200010106688
<a name="HyqMK"></a>## 1.6 注释:::warning**注释: 就是对代码的解释 方便大家阅读python代码**:::```python1)注释的分类(2)注释的注意点(3)注释的排错性(1)注释的分类 : 1.单行注释 2.多行注释# 1.单行注释 以#号开头 ,右边的所有东西都被当做说明文字 ,程序不进行编译运行。print(‘hello world’)# 2.多行注释 三个单引号 或 三个双引号'''这是第一行这是第二行'''(2)注释的注意点如果外面使用三个单引号,里面使用三个双引号,反之亦然。(3)注释的排错性先注释一部分代码,然后执行另外一部分,看看是否报错,逐层缩小报错范围,找到最终错误点。# 注释: 就是对代码的解释,方便程序员阅读代码 , 被注释的代码不执行.# 1.注释的分类: 单行注释 , 多行注释# 单行注释# python2.x print "hello,world"# python3.x print("hello,world")# notepad: ctrl + q pycharm: ctrl + /# 快捷键 : ctrl + z 撤销 ctrl + y 反撤销# print("hello,world")# 多行注释 ''' """'''print("今天是python32期,python上课第一天")print("总体学员人数,40人左右")print("同学们上课积极踊跃,非常认真")print("在半年之后,都要找一份满意的工作")print("希望同学们养成吃苦耐劳的习惯,好好的学习python")print("在未来,可以靠python大放光彩")'''"""print("今天是python32期,python上课第一天")print("总体学员人数,40人左右")print("同学们上课积极踊跃,非常认真")print("在半年之后,都要找一份满意的工作")print("希望同学们养成吃苦耐劳的习惯,好好的学习python")print("在未来,可以靠python大放光彩")"""# 2.多行注释的注意点'''如果里面嵌套的是三个单引号,外层使用三个双引号如果里面嵌套的是三个双引号,外层使用三个单引号单双引号要岔开''''''print("今天是python32期,python上课第一天")print("总体学员人数,40人左右")print("同学们上课积极踊跃,非常认真")print("在半年之后,都要找一份满意的工作")"""print("希望同学们养成吃苦耐劳的习惯,好好的学习python")"""print("在未来,可以靠python大放光彩")'''"""print("今天是python32期,python上课第一天")print("总体学员人数,40人左右")print("同学们上课积极踊跃,非常认真")print("在半年之后,都要找一份满意的工作")'''print("希望同学们养成吃苦耐劳的习惯,好好的学习python")'''print("在未来,可以靠python大放光彩")"""# 3.注释具有一定的排错性"""先用注释包裹一份部分代码,查看是否报错如果ok,缩小注释范围,再去一行一行进行排查,直到找到错误为止,以此类推...""""""print("今天是python32期,python上课第一天")print("总体学员人数,40人左右")print("同学们上课积极踊跃,非常认真")"""print("在半年之后,都要找一份满意的工作")print("希望同学们养成吃苦耐劳的习惯,好好的学习python")print("在未来,可以靠python大放光彩")# 其他语言的注释形式(了解)"""# shell注释/* */ 多行注释// 单行注释<!-- --> html/xml 注释"""
2.Python 6大数据类型
# ### 数据类型分类:(1)Number 数字类型 (int float bool complex)(2)str 字符串类型(3)list 列表类型(4)tuple 元组类型(5)set 集合类型(6)dict 字典类型# ### Number数字类型分类:int : 整数类型 ( 正整数 0 负整数 )float: 浮点数类型 ( 1普通小数 2科学计数法表示的小数 例:a = 3e-5 #3e-05 )bool: 布尔值类型 ( 真True 和 假False )complex: 复数类型 ( 声明复数的2种方法 ) (复数用作于科学计算中,表示高精度的数据,科学家会使用)# ### 容器类型分类:五个str "nihao"list [1,2,3]tuple (6,7,8)set {'a',1,2}dict {'a':1,'b':2}
2.0 数据的由来及介绍
:::success
数据类型的由来
0,1 控制电脑
:::
为什么会有多种数据类型 为了可以适应更多的使用场景,将数据划分为多种类型,每种类型都有着各自的特点和使用场景,帮助计算机高效的处理与展示数据
2.1 Number数字类型 (int float bool complex)
int 整型 (正整型 0 负整型)
数字
- 整数int
- Python3开始不再区分long、int,long被重命名为int,所以只有int类型了
- 进制表示:
- 十进制10
- 十六进制0x10
- 八进制0o10
- 二进制0b10
- bool类型,有2个值True、False
- 浮点数float
- 1.2、3.1415、-0.12,1.46e9等价于科学计数法1.46*10
- 本质上使用了C语言的double类型
- 复数complex
- 1+2j或1+2J
intvar = 100print(intvar)# type 获取值得类型res = type(intvar)print(res)# id 获取值得地址res = id(intvar)print(res)# 二进制整型intvar = 0b110print(intvar)print( type(intvar) )print( id(intvar) )# 八进制整型intvar = 0o127print(intvar)print(type(intvar))print(id(intvar))# 十六进制intvar = 0xffintvar = 0XFFprint(intvar)print(type(intvar))print(id(intvar))"""二进制 1 + 1 = `10八进制 7 + 1 = 10十六进制 f + 1 = 10"""
float 浮点型(小数)
# 表达方式1floatvar = 3.6print(floatvar , type(floatvar))# 表达方式2 科学计数法floatvar = 5.7e5 # 小数点右移5floatvar = 5.7e-2 # 小数点左移2print(floatvar , type(floatvar))
bool 布尔型 (True 真的, False 假的)
False等价 False等价布尔值,相当于bool(value)
- 空容器
- 空集合set
- 空字典dict
- 空列表list
- 空元组tuple
- 空字符串
- None
- 0
boolvar = Trueboolvar = Falseprint(boolvar , type(boolvar))
complex 复数类型
"""3 + 4j实数+虚数实数: 3虚数: 4jj : 如果有一个数他的平方等于-1,那么这个数就是j , 科学家认为有,表达一个高精度的类型"""# 表达方式1complexvar = 3 + 4jcomplexvar = -3jprint(complexvar , type(complexvar))# 表达方法2"""complex(实数,虚数) => 复数"""res = complex(3,4)print(res , type(res))
2.2 字符串类型 str
字符串
- 使用 ‘ “ 单双引号包裹的信息就是字符串
- ‘’’和””” 单双三引号,可以跨行、可以在其中自由的使用单双引号
- 字符串中可以包含任意字符:如字母,数字,符号,且没有先后顺序
- r前缀:在字符串前面加上r或者R前缀,表示该字符串不做特殊的处理
- f前缀:3.6版本开始,新增f前缀,格式化字符串
字符串拼接
str(1) + ',' + 'b' # 都转换成字符串拼接到一起"{}-{}".format(1, 'a') # {}就是填的空,有2个,就使用2个值填充# 在3.6后,可以使用插值a = 100;b = 'abc'f'{a}-{b}' # 一定要使用f前缀,在大括号中使用变量名
# ### 字符串类型 str"""用引号引起来的就是字符串,单引号,双引号,三引号# 转义字符 \ + 字符(1) 可以将无意义的字符变得有意义(2) 可以将有意义的字符变得无意义\n : 换行\r\n : 换行\t : 缩进(水平制表符)\r : 将\r后面的字符串拉到了当前行的行首"""# 1.单引号的字符串strvar = '生活不止眼前的苟且'print(strvar , type(strvar) )# 2.双引号的字符串strvar = "还有诗和远方的田野"print(strvar , type(strvar))# 可以将无意义的字符变得有意义strvar = "还有诗和\n远方的田野"strvar = "还有诗和\r\n远方的田野"strvar = "还有诗和\t远方的田野"strvar = "还有诗和\r远方的田野"strvar = "还有诗和\n远方的\r田野"# 可以将有意义的字符变得无意义strvar = "还有诗和\"远\"方的田野"print(strvar)strvar = "还有诗和\"远\"方的田野"# 3.三引号的字符串 (可以支持跨行效果)strvar = '''生活就像"醉"酒表面上说'不'要身体却很诚实'''print(strvar)# 4.元字符串 r"字符串" 原型化输出字符串strvar = "D:\nython32_python\tay02"strvar = r"D:\nython32_python\tay02"print(strvar)# 5.字符串的格式化"""%d 整型占位符%f 浮点型占位符%s 字符串占位符语法形式:"字符串" % (值1,值2)"""# %d 整型占位符strvar = "王同佩昨天买了%d风油精,洗澡" % (2)print(strvar)# %2d 占两位 (不够两位拿空格来补位) 原字符串具右strvar = "王同佩昨天买了%2d风油精,洗澡" % (2)print(strvar)# %-2d 占两位 (不够两位拿空格来补位) 原字符串具左strvar = "王同佩昨天买了%-2d风油精,洗澡" % (2)print(strvar)# %f 浮点型占位符strvar = "赵世超一个月开%f工资" % (9.9)print(strvar)# %.2f 保留小数点后面两位小数 (存在四舍五入的情况,默认保留六位小数)strvar = "赵世超一个月开%.2f工资" % (9.178)print(strvar)# %s 字符串占位符strvar = "%s最喜欢在电影院尿尿" % ("赵万里")print(strvar)# 综合案例strvar = "%s在水里%s被发现了,罚款%.2f元,并且做了%d俯卧撑." % ("孟凡伟","拉屎",500.129,50000)print(strvar)# 如果搞不清楚用什么占位符,可以无脑使用%sstrvar = "%s在水里%s被发现了,罚款%s元,并且做了%s俯卧撑." % ("孟凡伟","拉屎",500.129,50000)print(strvar)
2.3 列表类型 list
# ### 列表类型 list"""特征: 可获取,可修改,有序"""# 1.定义一个空列表listvar = []print( listvar , type(listvar))# 定义普通列表listvar = [98,6.9,True,12-90j,"赵万里"]# 2.获取列表中的元素# 正向索引 0 1 2 3 4listvar = [98,6.9,True,12-90j,"赵万里"]# 逆向索引 -5 -4 -3 -2 -1res = listvar[2]res = listvar[-2]print(res)# 通用写法# len 获取容器类型数据中元素个数length = len(listvar)res = listvar[length-1]print(res)# 简写res = listvar[len(listvar)-1]print(res)# python逆向索引的特点,瞬间得到列表中最后一个元素print(listvar[-1])# 3.修改列表中的元素listvar = [98,6.9,True,12-90j,"赵万里"]listvar[3] = "大象"print(listvar)
2.4 元组类型 tuple
# ### 元组类型 tuple"""特征: 可获取,不可修改,有序"""# 定义一个元组tuplevar = ("梦好心","王伟","安晓东","孙坚")print(tuplevar , type(tuplevar))# 获取元组中的元素# 正向索引 0 1 2 3tuplevar = ("梦好心","王伟","安晓东","孙坚")# 逆向索引 -4 -3 -2 -1print(tuplevar[2])print(tuplevar[-1])# 修改元组中的元素 : 元组中的值不能修改# tuplevar[0] = "萌不好心" error# 注意点"""逗号才是区分是否是元组的标识符"""tuplevar = (8.9,)tuplevar = 8.1,print(tuplevar)print(type(tuplevar))# 定义空元组tuplevar = ()print(type(tuplevar))# ### 字符串类型"""特征: 可获取,不可修改,有序"""# 正向索引 0 1 2 3 4 5 6 7 8strvar = "看你,我就心跳加速"# 逆向索引 -9-8-7-6-5-4-3-2-1# 获取字符串中的元素print(strvar[3])print(strvar[-6])# 不能修改字符串中的元素# strvar[3] = "你" errorprint("<===============>")strvar = "" # 单纯定义一个字符串类型print(strvar)print(type(strvar))strvar = " " # 字符串中含有3个空格字符print(strvar[0])print(type(strvar))
2.5 字典&集合 (dict set)
# ### 1.set 集合类型 (交差并补)"""特点: 无序,自动去重"""# 1.集合无序setvar = {"巨石强森","史泰龙","施瓦辛格","王文"}print(setvar , type(setvar))# 获取集合中的元素 不可以# setvar[0] error# 修改集合中的元素 不可以# setvar[2] = 111 error# 2.集合自动去重setvar = {"巨石强森","史泰龙","施瓦辛格","王文","史泰龙","史泰龙","史泰龙"}print(setvar , type(setvar))# 3.定义一个空集合setvar = set()print(setvar , type(setvar))# ### 2.dict 字典类型"""键值对存储的数据,表面上有序,本质上无序dictvar = {键1:值1, 键2:值2 , ... }3.6版本之前,完全无序,3.6版本之后,存储的时候,保留了字典定义的字面顺序,在获取内存中数据时重新按照字面顺序做了排序,所以看起来有序,实际上存储时还是无序."""# 1.定义一个字典dictvar = {"top":"the shy","middle":"肉鸡","bottom":"jacklove" ,"jungle":"臭鞋","support":"吃饱饱_嘴里种水稻"}print(dictvar, type(dictvar))# 2.获取字典中的值res = dictvar["middle"]res = dictvar["jungle"]print(res)# 3.修改字典中的值dictvar["top"] = "the xboy"print(dictvar)# 4.定义空字典dictvar = {}print(dictvar, type(dictvar))# ### 3.set 和 dict 的注意点"""字典的键 和 集合的值 有数据类型上的要求:(允许的类型范围)不可变的类型: Number(int float complex bool) str tuple(不允许的类型)可变的类型 : list set dict哈希算法的提出目的是让数据尽量均匀的在内存当中分配,以减少哈希碰撞,提升存储分配的效率;哈希算法一定是无序的散列,所以集合 和 字典都是无序字典的 键有要求,值没要求字典的值可以任意换掉,但是键不可以."""# 允许的类型范围dictvar = {1:"abc",4.89:111,False:333,3+90j:666,"王文":"你好帅啊,我好喜欢哦,没毛病",(1,2,3,4,5,6):9999}print(dictvar)print(dictvar[(1,2,3,4,5,6)])# dictvar = {[1,2,3]:123} error# 允许的类型范围setvar = {1,"a",4.56,9+3j,False,(1,2,3)}# setvar = {1,"a",4.56,9+3j,False,(1,2,3),{"a","b"}} errorprint(setvar)# 总结:"""无论是变量缓存机制还是小数据池的驻留机制,都是为了节省内存空间,提升代码效率"""
2.6 自动类型转换
当2个不同类型的数据进行运算的时候,默认向更高精度转换数据类型精度从低到高: bool int float complex
2.7 强制类型转换
# -->Number部分int : 整型 浮点型 布尔类型 纯数字字符串float: 整型 浮点型 布尔类型 纯数字字符串complex: 整型 浮点型 布尔类型 纯数字字符串 (复数)bool: ( 容器类型数据 / Number类型数据 都可以 )
# -->容器类型部分str: ( 容器类型数据 / Number类型数据 都可以 )list: 字符串 列表 元组 集合 字典tuple: 字符串 列表 元组 集合 字典set: 字符串 列表 元组 集合 字典 (注意:相同的值,只会保留一份)dict: 使用 二级列表,二级元组,二级集合(里面的容器数据只能是元组)
2.8 字典和集合的注意点
# ###哈希算法#定义:把不可变的任意长度值计算成固定长度的唯一值,这个值可正可负,可大可小,但长度固定该算法叫哈希算法(散列算法),这个固定长度值叫哈希值(散列值)#特点:1.计算出来的值长度固定且该值唯一2.该字符串是密文,且加密过程不可逆#用哈希计算得到一个字符串的用意?例如:比对两个文件的内容是否一致?例如:比对输入的密码和数据库存储的密码是否一致#字典的键和集合中的值都是唯一值,不可重复:为了保证数据的唯一性,用哈希算法加密字典的键得到一个字符串。用哈希算法加密集合的值得到一个字符串。如果重复,他们都是后面的替换前面的。自动去重#版本:3.6版本之前都是 字典和集合都是无序的3.6版本之后,把字典的字面顺序记录下来,当从内存拿数据的时候,根据字面顺序重新排序,所以看起来像有序,但本质上无序可哈希数据:可哈希的数据 (不可变的数据):Number(int float bool complex) str tuple不可哈希的数据 (可变的数据): list set dict
2.9 空类型
:::success
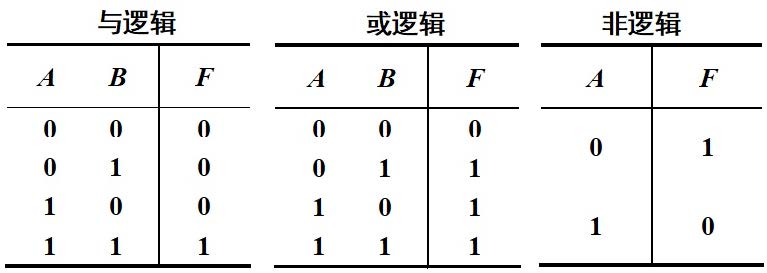
(1)算数运算符:
+、-、、/、//向下取整整除、%取模、*幂
注:在Python2中/和//都是整除。
(2)比较运算符:
==、!=、>、>=、<、<=
链式比较: 4 > 3 > 2
比较运算符,返回一个bool值
思考:1 == ‘1’ 吗? 1 > ‘1’ 吗?
注:<>:判断是否不等于;在python3里边已经废弃,仅在python2里边可用。
(3)赋值运算符:
a = min(3, 5)
+=、 -= 、=、/=、%=、//=、*= 等
x = y = z = 10
赋值语句先计算等式右边,然后再赋值给变量
(4)成员运算符: (针对于容器型数据)
in和not in,用来判断是否是容器的元素,返回布尔值
(5)身份运算符:
is 和 is not (检测两个数据在内存当中是否是同一个值)
(6)逻辑运算符:
与and、或or、非not
逻辑运算符也是短路运算符
and 如果前面的表达式等价为False,后面就没有必要计算了,这个逻辑表达式最终一定等价为False
1 and '2' and 0<br /> 0 and 'abc' and 1
or 如果前面的表达式等价为True,后面没有必要计算了,这个逻辑表达式最终一定等价为True
1 or False or None
- 特别注意,返回值。返回值不一定是bool型
- 把最频繁使用的,做最少计算就可以知道结果的条件放到前面,如果它能短路,将大大减少计算量
(7)位运算符:
&位与、|位或、^异或、<<左移、>>右移、~按位取反,包括符号位
:::
| python运算符 | 注意点 |
| —- | —- |
| 算数运算符 | % 取余 , //地板除 , ** 幂运算 |
| 比较运算符 | == 比较两个值是否相等 != 比较两个值是否不同 |
| 赋值运算符 | a += 1 => a = a+1 |
| 成员运算符 | in 或 not in 判断某个值是否包含在(或不在)一个容器类型数据当中 |
| 身份运算符 | is 和 is not 用来判断内存地址是否相同 |
| 逻辑运算符 | 优先级 () > not > and > or |
| 位运算符 | 优先级 (<<或 >> ) > & > ^ > | 5 << 1 结果:10 , 5 >> 1 结果:2 |
3.2 运算符优先级
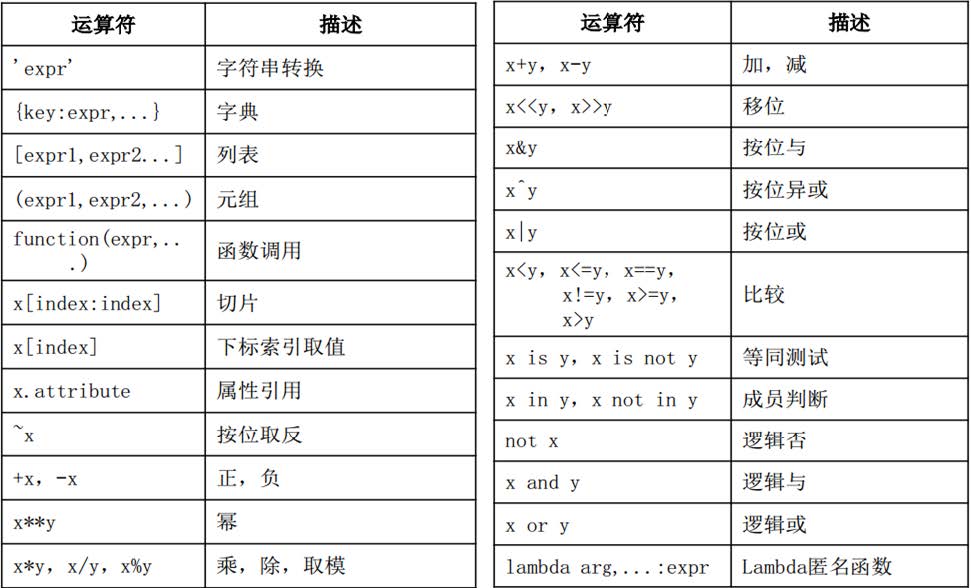
- 单目运算符 > 双目运算符
- 算数运算符 > 位运算符 > 比较运算符 > 逻辑运算符
- -3 + 2 > 5 and ‘a’ > ‘b’
搞不清楚就使用括号。长表达式,多用括号,易懂、易读。
3.3 表达式
- 由数字、符号、括号、变量等的组合。有算数表达式、逻辑表达式、赋值表达式、lambda表达式等等。
- Python中,赋值即定义。Python是动态语言,只有赋值才会创建一个变量,并决定了变量的类型和值。
- 如果一个变量已经定义,赋值相当于重新定义。
3.4 内建函数
| 内建函数 | 函数签名 | 说明 | | —- | —- | —- | | print | print(value, …, sep=’ ‘,
end=’\n’) | 将多个数据输出到控制台,默认使用空格分隔、
\n换行 | | input | input([prompt]) | 在控制台和用户交互,接收用户输入,并返回字
符串 | | int | int(value) | 将给定的值,转换成整数。int本质是类 | | str | str(value) | 将给定的值,转换成字符串。str本质是类 | | type | type(value) | 返回对象的类型。本质是元类 | | isinstance | isinstance(obj,
class_or_tuple) | 比较对象的类型,类型可以是obj的基类 | | len | len(str) | 返回字符串的长度 |
print(1,2,3,sep='\n', end='***')type(1) # 返回的是类型,不是字符串type('abc') # 返回的是类型,不是字符串type(int) # 返回type,意思是这个int类型由type构造出来type(str) # 返回type,也是类型type(type) # 也是typeprint(isinstance(1, int))print(isinstance(False, int)) # True
3.5 转义序列
- \ \t \r \n \’ \”
- 上面每一个转义字符只代表一个字符,例如\t 显示时占了4个字符位置,但是它是一个字符
前缀r,把里面的所有字符当普通字符对待,则转义字符就不转义了。
3.6 缩进
未使用C等语言的花括号,而是采用缩进的方式表示层次关系
-
3.7 续行
在行尾使用 \,注意\之后除了紧跟着换行之外不能有其他字符
- 如果使用各种括号,认为括号内是一个整体,其内部跨行不用 \
4.数据的在内存中的缓存机制
4.1 在同一文件(模块)里,变量存储的缓存机制 (仅对python3.6版本负责)
# -->Number 部分1.对于整型而言,-5~正无穷范围内的相同值 id一致2.对于浮点数而言,非负数范围内的相同值 id一致3.布尔值而言,值相同情况下,id一致4.复数在 实数+虚数 这样的结构中永不相同(只有虚数的情况例外)
# -->容器类型部分5.字符串 和 空元组 相同的情况下,地址相同6.列表,元组,字典,集合无论什么情况 id标识都不同 [空元组例外]
4.2 不同文件(模块)里,部分数据驻留小数据池中 (仅对python3.6版本负责 了解)
小数据池只针对:int,str,bool,空元祖(),None关键字 这些数据类型有效#(1)对于int而言python在内存中创建了-5 ~ 256 范围的整数,提前驻留在了内存的一块区域.如果是不同文件(模块)的两个变量,声明同一个值,在-5~256这个范围里,那么id一致.让两个变量的值都同时指向一个值的地址,节省空间。
#(2)对于str来说:1.字符串的长度为0或者1,默认驻留小数据池
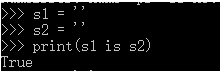
2.字符串的长度>1,且只含有大小写字母,数字,下划线时,默认驻留小数据池
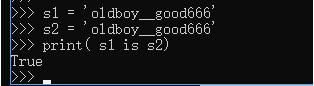
3.用*号得到的字符串,分两种情况。1)乘数等于1时: 无论什么字符串 * 1 , 都默认驻留小数据池2)乘数大于1时: 乘数大于1,仅包含数字,字母,下划线时会被缓存,但字符串长度不能大于20
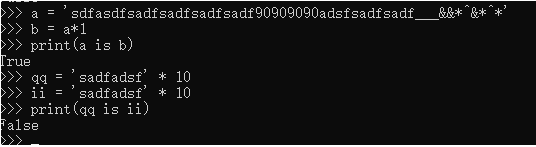
#(3)指定驻留# 从 sys模块 引入 intern 函数 让a,b两个变量指向同一个值from sys import interna = intern('大帅锅&*^^1234'*10)b = intern('大帅锅&*^^1234'*10)print(a is b)#可以指定任意字符串加入到小数据池中,无论声明多少个变量,只要此值相同,都指向同一个地址空间
4.3 缓存机制的意义
无论是变量缓存机制还是小数据池的驻留机制,都是为了节省内存空间,提升代码效率

若有收获,就点个赞吧
0 人点赞
