什么是Kylin?
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Apache Kylin™ 令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
- 定义数据集上的一个星形或雪花形模型
- 在定义的数据表上构建cube
- 使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果
Kylin 提供与多种数据可视化工具的整合能力,如 Tableau,PowerBI 等,令用户可以使用 BI 工具对 Hadoop 数据进行分析。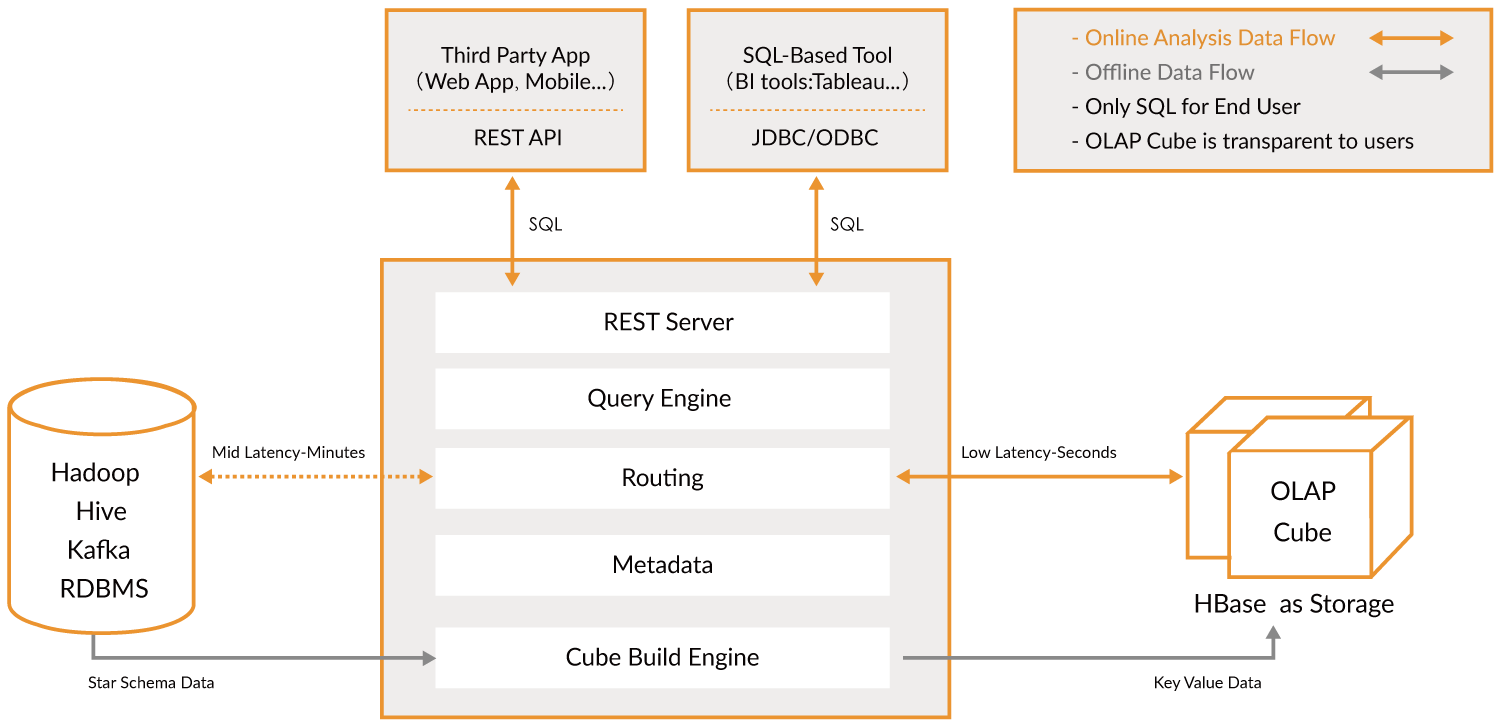
REST Server层:用户程序访问Kylin的入口。实现用户通过程序对Kylin进行访问,可实现Cube的创建、查询、获取元数据及权限配置等操作。
Query Engine层:用户在预计算生成Cube后,查询层可以快速响应用户的查询动作,并将结果返回给用户。
Routing层:路由层设计之初是为了在查询未预计算Cube的数据时可以转而直接查询Hive,但由于Cube查询仅几秒的时间就可以返回数据,而查询Hive表通常需要十几秒秒甚至几分钟到几十分钟,导致用户体验会变的极差。因此在后来Kylin默认配置关闭了此项功能。
Metadata层:Metadata层主要是Kylin的一些元数据,比如最重要的Cube信息等等。
Cube Build Engine层:Cube构建层主要负责数据的预计算并生成Cube,包括MR任务及其他java api等。
Kylin是依靠于Hadoop生态系统之上应用程序。它的数据来源为Hive表或Kafka流式数据以及其他关系型数据库中的数据。通过构建引擎,将预计算生成的Cube数据存到Hbase中,以供快速的查询响应。
Kylin在数据系统中的一般架构是什么样的?
Kylin解决什么类型问题?
Apache Kylin的设计初衷就是要解决千亿条、万亿条记录的秒级查询问题,其中的关键就是要打破查询时间随着数据量成线性增长的这个规律。Kylin的工作原理本质上是MOLAP(Multidimensional Online Analytical Processing)Cube,也就是多维立方体分析。这是数据分析中相当经典的理论,在传统数据分析与BI领域已经有了广泛的应用,例如MSTR,SAP BW等都使用了这种技术。这实际上走得是“预计算”的思路,是一种拿空间换时间的一种计算策略:尽量多地预先计算聚合结果,在查询时刻应尽量使用预算的结果得出查询结果,从而避免直接扫描可能无限增长的原始记录。
Kylin工作原理就是对数据模型做Cube预计算,并利用计算的结果加速查询,具体工作过程如下:
1)指定数据模型,定义维度和度量。
2)预计算Cube,计算所有Cuboid并保存为物化视图。
3)执行查询时,读取Cuboid,运算,产生查询结果。
由于Kylin的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算,并利用预计算的结果来执行查询,因此相比非预计算的查询技术,其速度一般要快一到两个数量级,并且这点在超大的数据集上优势更明显。当数据集达到千亿乃至万亿级别时,Kylin的速度甚至可以超越其他非预计算技术1000倍以上。
Kylin相对于其他MOLAP优化了什么?
Kylin 是基于 Hadoop 的 MOLAP (Multi-dimensional OLAP) 技术,核心技术是 OLAP Cube;与传统 MOLAP 技术不同,Kylin 运行在 Hadoop 这个功能强大、扩展性强的平台上,从而可以支持海量 (TB到PB) 的数据;它将预计算(通过 MapReduce 或 Spark 执行)好的多维 Cube 导入到 HBase 这个低延迟的分布式数据库中,从而可以实现亚秒级的查询响应;最近的 Kylin 4 开始使用 Spark + Parquet 来替换 HBase,从而进一步简化架构。在此基础上,Kylin还使用到一些技术来优化Cube构建和查询:
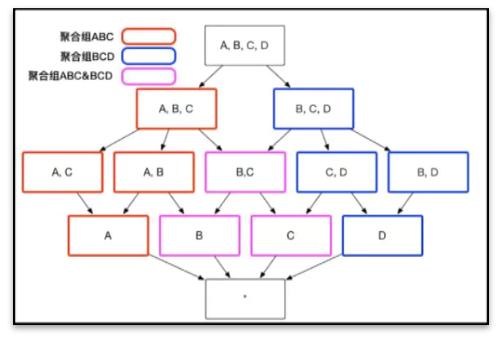
1. 维度剪枝
随着维度数目的增加,Cuboid 的数量会爆炸式地增长。为了缓解 Cube 的构建压力,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid,从而帮助解决Cube构建过程中可能发生的维度爆炸和扫描数据过多的问题。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierachy Dimension)和必要维度(Mandatory Dimension)等。
- 设置聚合组:通过聚合组进行剪枝,减少不必要的预计算组合;
- 设置联合维度:将经常成对出现的维度组合放在一起,减少不必要的预计算;
- 设置层级维度:将能通过其他维度计算出来的维度(例如年,月,日能通过日期计算出来)设置为衍生维度,减少不必要的预计算;
- 设置必要维度:将每次查询必带的维度作为必要维度,一个必要维度可减少一半的Cuboid。
- 设置维度表快照:放入内存现算,减少占用的存储空间;
- 字典编码:减少占用的存储空间;
- RowKey 编码,设置 shard by 列:通过减少数据扫描的行数,加速查询效率
2. 增量更新
由于Cube完整Publish是一个非常耗费计算资源的过程,而数据的增量有不可避免,Kylin设计了一套增量更新Cube的机制,来保证Cube的高效更新。
3. 计算下推
对于Cube计算不了的逻辑,Kylin还支持下推到源数据层(Hive)进行查询,满足一些特殊的查询需求。不过Hive一般交互查询性能不太好,默认是不开放的。

若有收获,就点个赞吧
0 人点赞
