概述
大数据分层(六层)体系


- 数据收集层
数据源特点:分布式、异构型、多样性、流式产生
因此大数据的收集系统应具备:扩展性、可靠性、安全性、低延迟
- 数据存储层
传统关系型数据库和文件系统(Linux文件系统)无法适应大数据场景,应具备:扩展性、容错性、存储模型
- 资源管理于服务协调层
多个应用部署在一个公共集群,共享集群资源,并对资源进行统一使用,同时采用轻量级隔离方案对各个应用进行隔离,由此带来好处:资源利用率高、运维成本低、数据共享
- 计算引擎层
批处理计算追求高吞吐率,典型应用搜索引擎构建索引;实时计算追求低延迟,典型应用广告系统及应用卡欺诈检测。
- 数据分析层
直接跟用户应用程序对接,为其提供易用的数据处理工具。
- 数据可视化层
直接面向用户展示结果的一层。
例如google大数据技术栈:
Hadoop和Spark开源大数据技术栈:
HBase:构建在HDFS之上的分布式数据库,Google BigTable的开源实现,运行储存结构化与半结构化的数据,支持列无限扩展以及数据随机查找与删除。
Kudu:分布式列式存储数据库,允许存储结构化数据,支持行无限扩展与数据随机查找与更新。
MapReduce:批处理计算引擎,允许用户通过简单API编写分布式程序。
Tez:基于MapReduce开发的通用DAG计算引擎,能够更加高效地实现复杂的数据处理逻辑,被应用在Hive、Pig等数据分析系统中。
Spark:通用的DAG计算引擎,提供基于RDD(Resilient Distributed Dataset)的数据抽象表示。
Impala/Presto:分别由Cloudera/Facebook开源的MPP(Massively Parallel Processing)系统,允许用户使用标准SQL处理存储在Hadoop中的数据,采用了并行数据库架构,内置了查询优化器,查询下推,代码生成等优化机制,使得大数据处理效率大大提高。
Storm/Spark Streaming:分布式流式实时计算引擎,允许用户通过简单的API完成实时应用程序的开发工作。
Hive/Pig/Spark SQL:在计算引擎之上构建的支持SQL或脚本语言的分析系统。Hive基于MapReduce/Tez实现的SQL引擎,Pig基于MapReduce/Tez实现的工作流引擎,SparkSQL基于Spark实现的SQL引擎。
Mahout/MLib:在计算引擎之上构建的机器学习库实现了常用的机器学习和数据挖掘算法。Mahout基于MapReduce实现,MLib基于Spark实现。
大数据架构:Lamda架构
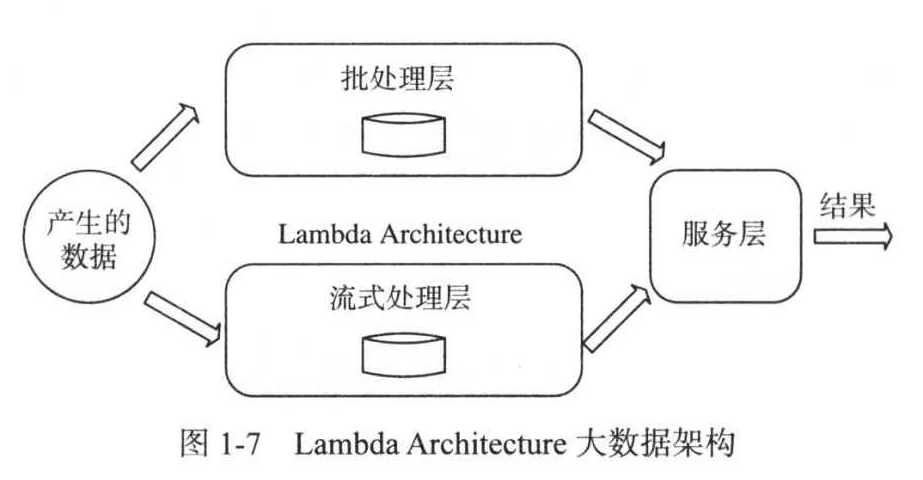
下图取自《从0学习大数据》
以推荐系统为例:
用户数据统一流入Kafka,之后按照不同时间粒度导入批处理和流式处理两个系统中。批处理层拥有所有历史数据(通常保存到HDFS/HBase),通常用以实现推荐模型,以当前数据(例如最近一小时数据)和历史数据为输入,通过特征工程、模型构建(迭代算法,使用MapReduce/Spark实现)及模型评估等计算环节后,最终获得最优的模型并将产生的推荐结果存储(比如Redis)起来,整个过程延迟较大,通常为分钟或小时级别。
为了解决推荐系统的冷启动问题(新用户推荐),引入流式处理层,实时采集用户行为数据,并基于这些数据通过简单的推荐算法(通常使用Storm/Spark Streaming实现)快速产生推荐结果并存储起来。
最后通过服务层,对外提供访问接口。
Hadoop和Spark版本
Hadoop发行版本
- Apache Hadoop:社区原生版本
- CDH(Cloudera Distributed Hadoop):Cloudera公司发行版,社区版所有源代码均开源,企业版闭源且收费
- HDP(HortonWorks Data Platform):HortonWorks公司发行版, 社区版所有源代码均开源,企业版闭源且收费
Spark发行版本:
- Apache Spark:社区原生版
- Databricks Spark:Databricks公司发行版,社区版所有源代码均开源
- Hadoop企业发行版:各大Hadoop企业发行版,比如CDH和HDP,均内置了对Spark的支持
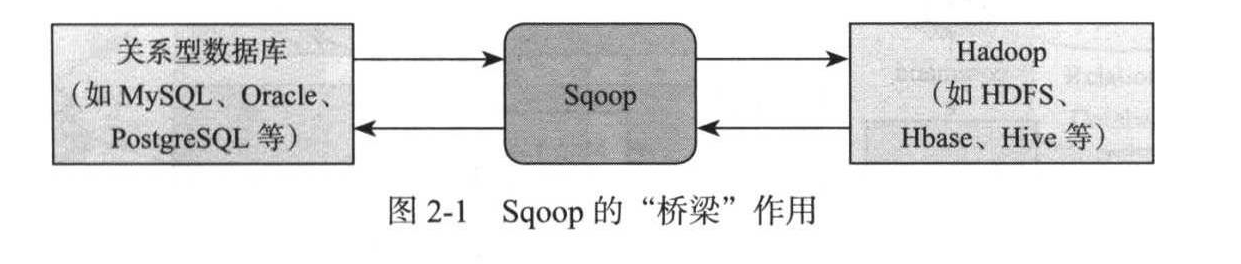
关系型数据收集
Sqoop
https://github.com/apache/sqoop
Sqoop设计动机
- 数据迁移
- 可视化分析结果
- 数据增量导入
sqoop的2个版本:1.4.x和1.99.x,分别称为sqoop1和sqoop2。
Sqoop2基本架构:
Sqoop Client:定义了用户使用Sqoop的方式,包括客户端CLI和浏览器2种方式,其中浏览器方式允许用户直接通过HTTP方式完成Sqoop的管理和数据导入导出。
Sqoop Server:根据用户创建的Sqoop Job生成一个MapReduce作业,提交到Hadoop集群中分布式执行。包括以下几个组件:
- Connector:关注数据解析和加载相关的功能,包括
- Partitioner:决定如何对源数据进行分片(SqoopSplit),以便启动Map Task并行处理;
- Extractor:将一个分片中的数据解析成一条条记录,并输出;
- Loader:读取Extractor输出的数据,并以特定格式写入目标数据源中;
- Metadata:Sqoop中的元信息,包括可用的Connector列表、用户创建的作业和Link等,被存储在数据仓库中,默认使用轻量级数据库Apache Derby
- RESTful和HTTP Server:与客户端对接,响应客户端发出的HTTP请求
Connector:访问某种数据源的组件,负责从数据源中读取数据,或将数据写入数据源;
Link:一个Connector实例;
Job:完成数据迁移功能的分布式作业,可从某个数据源(FROM link)中读取数据,并导入到另一种数据源(TO link);
查看Sqoop2提供的4种可用的Connector:
查看已创建的Link:
创建Link:create link -c
创建Job:create job -f
提交并监控Job:start job -jid
查看作业运行情况:status job -jid
数据增量收集CDC
CDC = Change Data Capture(即增量数据获取)
为实现CDC,可选方案有:
- 定时扫描整表:把变化的数据找出来,并发送给数据收集器(Sqoop增量收集本质上就是这种方案)
- 写双份数据:修改业务层代码,凡是数据更新操作,除了修改数据库表外,还需要将更新数据发送到数据收集器
- 利用触发器机制:触发器是一种特殊的存储过程,主要通过事件(增删改)进行触发而被执行,它在表中数据变化时自动强制执行。
但以上三种方案都存在劣势,于是基于事务或提交日志(binlog)解析的方案出现了,例如通过解析数据库更新日志,还原更新的数据,能够在不对业务层代码做任务修改的前提下,高效获取更新数据的Canal。
Canal实现原理:模拟主备复制原理,接收binlog,进而捕获更新数据。
https://github.com/alibaba/canal
争对多机房数据同步系统,ALIBABA基于Canal开发了Otter,定位是分布式数据库同步系统。
https://github.com/alibaba/otter

Otter的S、E、T、L阶段模型:
Select:数据源对接的阶段,为解决数据来源的差异性而引入
Extract、Transform、Load:类似于数据仓库的ETL模型,比如在跨机房同步场景中,Select和Extract一般部署在原机房,而Transform和Load部署在目标机房。

用户通过Manager配置跨机房同步任务,原机房(机房1)中数据由Canal获取后,经S、E两个阶段处理后,通过网络发送到目标机房(机房2),在目标机房中,经T、L两个阶段处理后,最终将数据写入新的数据库或消息队列等系统。
非关系型数据收集
Flume由Cloudera公司开源的一个分布式高可靠系统,能够对不同数据源的海量日志数据进行高效收集、聚合、移动、最后存储到一个中心化的数据存储系统中。
日志收集面临的问题:
- 数据源种类多,格式不同,产生日志的方式也不同(有些写到本地日志文件,有些通过HTTP发送到远端)
- 数据源是物理分布的,各种服务运行在不同的机器上
- 流式的,不间断产生
- 对可靠性有一定要求,例如银行用户转账日志希望可以做到不丢失,或者用户搜索日志希望可以做到只丢失可控的数量
Flume目前存在2个版本:Flume OG(Original Generation)和Flume NG(Next/New Generation),Flume OG对应Apache Flume 0.9.x及之前版本,已被各大Hadoop发行版抛弃;Flume NG对应Apache Flume 1.x版本,被主流Hadoop发行版采用。
Flume NG
基本架构
Flume的数据流是通过一些列Agent组件构成的。一个Agent可以从客户端或前一个Agent接收数据,经过过滤、路由等操作后,传递到下一个或多个Agent(完全分布式),直到抵达指定的目标系统。
流水线中传递的数据称为“Event”,每个头部和字节数组两部分组成,其中头部由一系列key/value对构成,可用于数据路由,字节数组封装了实际要传递的数据内容,通常使用Avro、Thrift、Protobuf等对象序列化而成。
Agent的内部组成:
- Source
接收Event的组件,通常从Client程序或上一个Agent接收数据,并写入一个或多个Channel。提供了默认的一些Source:
- Avro Source
- Thrift Source
- Exec Source 很少采用
- Spooling Directory Source:用于监控目标目录下的文件的变化,较多采用
- Kafka Source:从Kafka中读取某个topic的数据,写入Channel
- Syslog Source:可接收HTTP协议发来的数据,写入Channel
实际生产环境中,存在2种数据源,一种是文件,但考虑到前者无法保证数据完整性,后端实时性较差,通常会自己定制,taildir source便是一个非常优秀的解决方案,它能实时监控一个目录下文件的变化,实时读取新增数据,并记录断点,保证重启Agent后数据不丢失或被重复传输。另一种数据是网络数据,可采用Avro/Thrift source,并自己编写客户端程序传输数据给该source。
- Channel
缓存从source写入的Event,直到被Sink发送出去,默认提供以下几种:
- Memory Channel:内存队列中缓存,性能高,但是断电后数据丢失,内存不足时也会导致Agent崩溃
- File Channel:磁盘文件中缓存,但性能有所下降
- JDBC Channel:支持JDBC驱动,可将Event写入数据库中,该Channel适用于对故障恢复要求非常高的场景
- Kafka Channel:Kafka中缓存,由于Kafka的特性,提供了高容错性和扩展性,并为Sink重复读取Channel中数据提供了可能
- Sink
从Channel中读取数据,并发送给下一个Agent(的Source),默认提供以下几种:
- HDFS Sink
- HBase Sink
- Avro/Thrift Sink
- MorphlineSolrSink/ElasticSearchSink
- Kafka Sink
Flume使用事务性的方式保证Event传递的可靠性。Sink必须在Event被存入Channel后,或者已经被成功传递给下一个Agent后,才会把Event从Channel中删除。
Flume NG的高级组件
包括Interceptor、Channel Selector、Sink Processor
- Interceptor
允许用户修改或丢弃传输中的Event
- Channel Selector
允许Source选择一个或多个目标Channel,并将当前Event写入到这些Channel,默认提供以下几种:
- Replicating Channel Selector:将相同数据(Event)导入到多个系统,默认采用该Channel Selector
- Multiplexing Channel Selector:根据Event头部某个属性值,将Event写入对应的Channel
- Sink Processor
允许将多个Sink组装在一起形成一个逻辑实体(Sink Group),而Sink Processor则在Sink Group基础上提供负责均衡以及容错的功能(当一个Sink挂掉,另一个Sink接替),提供默认以下几种:
- Default Sink Processor:默认实现,最简单的 Source-》Channel-》Sink数据流,每个组件只有一个
- Failover Sink Processor:Sink Group中每个Sink被赋予一个优先级,Event优先由高的Sink发送,如果高优先级Sink挂了,由次高优先级Sink接替
- LoadBalancing Sink Processor:Event通过某种负责均衡机制,交给Sink Group中的所有Sink发送
分布式消息队列Kafka
Flume和Kafka区别:
- Kafka中存储数据是多副本的,能够做到数据不丢失;Flume提供Memory Channel和File Channel都做不到;
- Kafka数据可以暂存一段时间(默认7天)供消费者重复读取;Flume Sink发送数据成功后会立刻删除Event;
- Kafka的生产者和消费者需要用户使用API编写;Flume提供了大量Source和Sink实现,能够更容易地通过配置就完成数据收集工作;
Kafka设计架构
Kafka采用了不同于其他消息队列的push-push架构,而是采用了push-pull架构。好处以下两点:
- Consumer可根据自己的实际负载和需求获取数据,避免采用“push”方式给Consumer带来太大压力
- Consumer自己维护已读消息的offset而不是由Broker端维护,大大缓解了Broker的压力,使得它更加轻量级
Kafka各组件详解:
- Producer
每条消息表示为一个三元组
- Broker
一般有多个,组成一个分布式高容错的集群。Broker以topic为单位将消息分成不同的分区,每个分区可以有多个副本,通过冗余的方式实现容错。当partition存在多个副本时,其中一个是leader,对外提供读写,其余均为follower,不对外提供读写,只同步leader中数据,并在leader出问题时通过选举算法将其中某一个提升为leader。
- Consumer
主动从Broker拉取消息,每个Consumer各自维护最后一个已读消息的offset,并在下次请求从这个offset开始的消息。Kafka允许多个Consumer构成一个Consumer Group,共同读取同一个topic中的数据,提高数据读取效率。可自动为同一个Group中的Consumer分摊负载,从而实现消息的并发读取,并在某个Consumer发生故障时,自动将其处理的partition转移给同Group中的其他Consumer处理。
- ZK
所有Broker会向ZK注册,将自己的位置、健康状态、维护的topic、partition等信息写入ZK,以便于其他Consumer可以发现和获取这些数据
Kafka关键技术点
- 可控的可靠性级别
通过参数 request.required.acks 控制消息的确认应答方式,该参数可以控制可靠性,但是会和写性能有此消彼长的影响
0:无需对消息确认(可靠性最差,写性能最好)
1:需等到leader partition写成功后才会返回(折中方案)
-1:需等到所有partition写成功后才会返回(可靠性最好,但是写性能最差)
- 数据多副本
为每个topic中的数据存放多个副本,以达到容错的目的。采用了强一致的数据复制策略 。消息首先被写入leader分区,之后由leader分区负责把收到的消息同步给其他follower分区。
- 高效的持久化机制
将消息持久化到磁盘而不是内存,采用顺序写的方式写入磁盘,并结合基于offset的数据组织方式,能达到很高效的读速度和写速度。
- 数据传输优化:批处理和zero-copy技术
为了降低单条消息传输带来的网络开销,Kafka broker将多条消息封装在一起,一并发送给Consumer。通常情况下,一条存储在磁盘上的数据,从读取到发送出去要经过4次拷贝2次系统调用,以此为:内核态read buffer-》用户态应用程序buffer-》内核态socket buffer-》网卡NIC buffer,通过zero-copy技术优化后,数据只需要经过3次拷贝即可发送出去:内核态read buffer-》内核态socket buffer-》网卡NIC buffer,大大提高数据传输效率。
- 可控的消息传递语义
at most once(最多一次):消息发送给消费者后,立刻返回,不关系消费者是否成功收到
at least once(至少一次):消息发送给消费者后,需等待确认,如果没有收到,则会重发,这种语义能保证消息者收到消息,但可能会收到多次
exactly once(有且只有一次):消费者会且只会处理一次同一条消息,常用技术手段:
- 两段锁协议:分布式中常用的一致性协议
- 在支持幂等操作的前提下,使用at least once语义
Producer和Broker之间:目前支持 at most once 和 at least once,分别通过异步发送和同步发送实现。0.9.0版本,增加对 exactly once,采用的技术思路是在支持幂等操作的前提下,使用 at least once 语义。
Broker和Consumer之间:处理消息之前持久化offset则为at most once;成功处理消息之后再持久化offset则为at least once。
Kafka在大数据中的应用场景
- 流式计算框架的数据源

- 分布式日志收集系统中的Source或Sink

- Lambda架构中的Source:同时为批处理和流式处理2条流水线提供数据源,并将最终结果汇聚,呈现给用户。


若有收获,就点个赞吧
0 人点赞
