一、Overview
关于该学习哪个版本的问题
1、DL要了解框架
2、看文档
要求会:
1、线性代数+概率论
2、Python
吃什么的问题:
本教程-监督学习:有label 的
1、穷举
2、贪心
3、分治-快排
4、动态规划
DL 结构上是 NN,从目标上是 RL
Rules-based System:不咋地
Classic machine learning:手工特征,最终变成向量(张量Tensor)
Representing Learning:特征提取,
维度诅咒:每个Feature越多,对样本的需求就越多。
大数定律
我们想降维!
Manifold 流行:
Deep Learning(End2End):端到端的学习,原始特征(像素,语音······),额外的层,再到学习器(神经网络,Neural NetWork)
神经网络简史
Back Propagation 反向传播
核心:计算图
写深度神经网络较图简单一些。
流行的DL框架
Tensorflow(Kreas)、Theano
Caffe(Facebook)
Torch(和Caffe一起)
二、Linear Model
import numpy as npimport matplotlib.pyplot as pltx_data = [1.0,2.0,3.0]y_data = [2.0,4.0,6.0]# 前向传播def forward(x):return x * w #model 线性模型# 损失def loss(x,y):y_pred = forward(x)return (y_pred-y)*(y_pred-y)w_list = [] # 权重mse_list = [] # 均方误差for w in np.arange(0.0, 4.1, 0.1):print('w=',w)l_sum = 0for x_val, y_val in zip(x_data,y_data):y_pred_val = forward(x_val)loss_val = loss(x_val,y_val)l_sum += loss_valprint('\t',x_val,y_val,y_pred_val,loss_val)print('MSE=',l_sum/3)w_list.append(w) # 穷举的方式mse_list.append(l_sum/3)# 画图plt.plot(w_list,mse_list)plt.xlabel('w')plt.ylabel('loss')plt.show()
MSE 均方误差
Python zip() 函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
>>>a = [1,2,3]>>> b = [4,5,6]>>> c = [4,5,6,7,8]>>> zipped = zip(a,b) # 打包为元组的列表[(1, 4), (2, 5), (3, 6)]>>> zip(a,c) # 元素个数与最短的列表一致[(1, 4), (2, 5), (3, 6)]>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式[(1, 2, 3), (4, 5, 6)]
三、Gradient Descent
The best model:
最简单:Linear Model ——穷举法
Gradient:
Update:

α为学习率,取得比较小
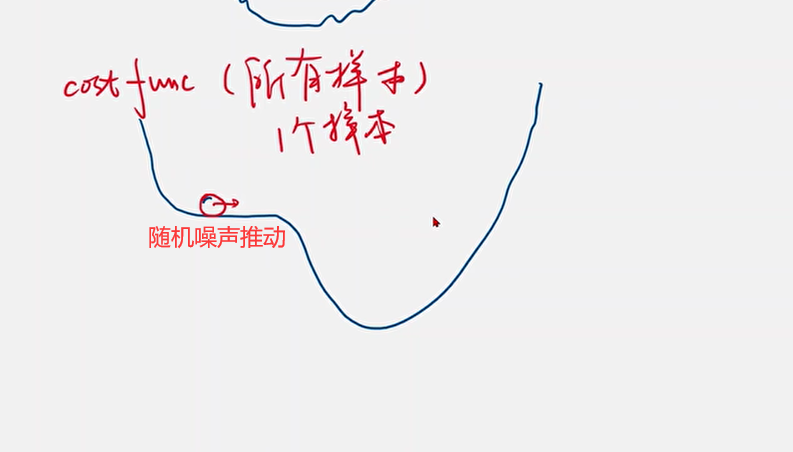
每一次都在往下降最快的方向,前进一步。——贪心算法,局部最优。
上图就是局部最优,也是梯度下降算法的结果。
那么问题来了,为什么还要在DL中使用梯度下降算法捏?
DNN中,并没有非常多的局部最优点,但存在特殊点——鞍点,即梯度为零的点。
DNN中解决最大的问题:
就是鞍点的问题
import numpy as npimport matplotlib.pyplot as pltx_data = [1.0,2.0,3.0]y_data = [2.0,4.0,6.0]w = 1# 前向传播def forward(x):return x * w #model 线性模型# 损失——MSE均方误差def loss(xs,ys):loss = 0for x,y in zip(xs,ys):y_pred_val = forward(x)loss += (y_pred_val-y)**2return loss/len(xs)# 梯度下降def gradient(xs,ys):grad = 0for x,y in zip(xs,ys):y_pred = forward(x)grad += 2*x*(y_pred-y)return grad/len(xs)print('Predict(before training)',4,forward(4))epoch_list = []loss_list = []# epoch 作循环用for epoch in range(100):loss_val = loss(x_data,y_data)grad_val = gradient(x_data,y_data) # 计算出梯度w -= 0.01 * grad_val # 0.01为学习率print('Epoch',epoch,'w= ',w,'loss',loss_val)epoch_list.append(epoch)loss_list.append(loss_val)print('Predict(after training)',4,forward(4))# 画图plt.plot(epoch_list,loss_list)plt.xlabel('loss')plt.ylabel('epoch')plt.show()

Batch

五、用Pytorch实现线性回归
前向传播求损失,后向传播求梯度,更新权重
1、准备数据集:后面会介绍
2、设计模型:用来计算y
3、计算损失和优化:使用pytorch的api
4、循环训练
5.1 准备数据
5.2 设计模型
numpy的广播机制:扩充,使两矩阵相同大小
重点目标:构造计算图
权重的大小:知道输入和输出的维度,就可以推出w。
loss必须是标量,所以对于loss的矩阵loss1,loss2,loss3求和。
将模型定义为类class:以后方便扩展,都要继承自torch.nn.Modle
初始化函数 init(self):
Linera对象:w权重 b偏置
它的行数表示的featur的数量,列数表示的是样本数量,相当于做个了转置!!!
目的是:把维度给她拼出来啊。
前向传播函数 forward(self,x):
y_pred = selft.linear(x)
在对象后面加括号,这是啥么意思呢?我们实现了一个可调用的对象。
(Modle帮你反向传播求梯度)
5.3 构造损失函数和优化器
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
SGD是一个类,lr:learning rate 学习率
学习率过大:loss函数直接越过全局最优点
学习率过小:loss函数的变化超慢的
5.4 训练过程
for epoch in range(100): # 循环100次
y_pred = model(x_data)
loss = criterion(y_pred, y_data) # 此处loss是一个对象
print(epoch,loss)
optimizer.zero_grad() # 梯度归零
loss.backward() # 进行反向传播
optimizer.step() # 更新
5.5 打印和测试预测效果
print(‘w = ‘,model.linear.weight.item())
print(‘b = ‘,model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print(‘y_pred = ‘,y_test.data)
不光要观察训练集,也要观察测试集。
import torchx_data = torch.Tensor([[1.0], [2.0], [3.0]]) # 输入数据y_data = torch.Tensor([[2.0], [4.0], [6.0]]) # 输出数据class LinearModel(torch.nn.Module):def __init__(self):super(LinearModel, self).__init__() # 调用父类的初始化函数self.linear = torch.nn.Linear(1, 1)def forward(self, x):y_pred = self.linear(x)return y_predmodel = LinearModel() # 实例化线性模型类criterion = torch.nn.MSELoss(size_average=False) # 均方差optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 随机的梯度下降# epoch 时期for epoch in range(100): # 循环100次y_pred = model(x_data)loss = criterion(y_pred, y_data) # 此处loss是一个对象print(epoch, loss)optimizer.zero_grad() # 梯度归零loss.backward() # 进行反向传播optimizer.step() # 更新print('w = ', model.linear.weight.item())print('b = ', model.linear.bias.item())x_test = torch.Tensor([[4.0]])y_test = model(x_test)print('y_pred = ', y_test.data)
六、逻辑回归
logistic regression
分类问题:输出的是属于每一个分类的概率,0.4或者0.6的时候,不确定
要计算的是P(y=1)和P(y=0)的概率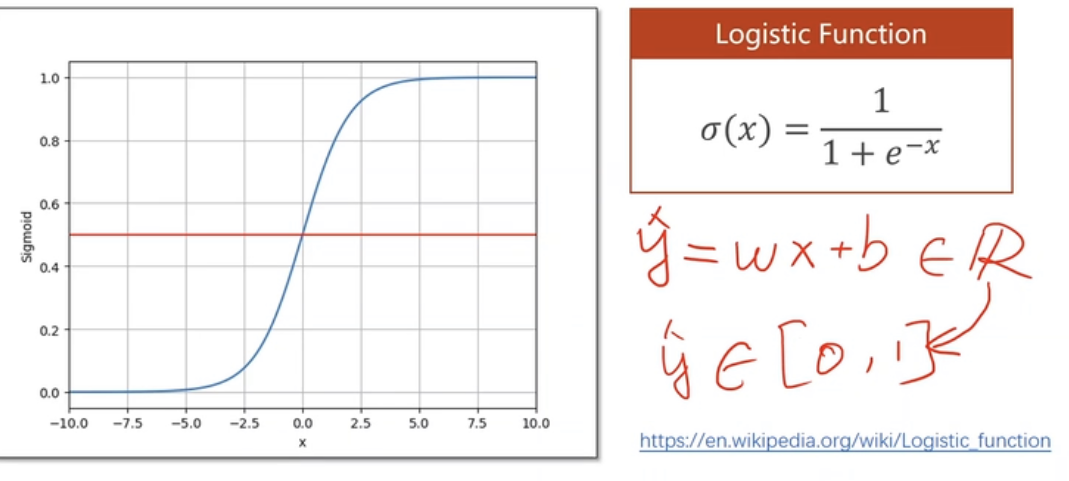
下面的y是逻辑回归方程(sigmoid 函数中最出名)的x。
图像是上图的形状,但为啥是这样的函数呢?
先别急,还有其他的sigmoid函数:
1、增函数 2、饱和函数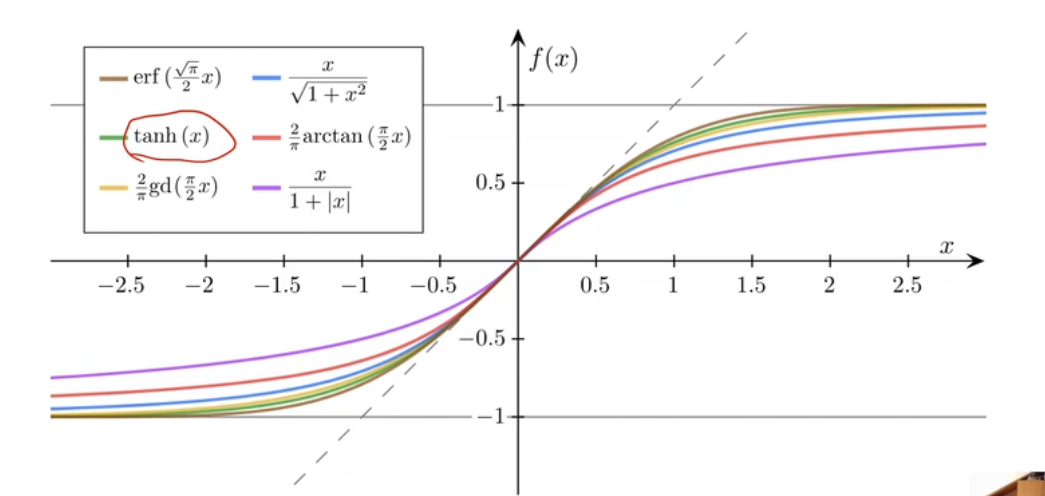
MINIST 手写数字的数据集
线性回归:
torchvision:pytorch提供的工具包,提供相应的数据集。
十、卷积神经网络
Convolusion Neural Network

若有收获,就点个赞吧
0 人点赞
