1.概述
1.1定义:
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域
1.2.消息队列

1.3kafka基础架构

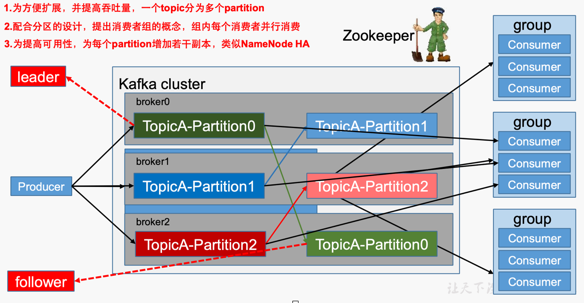
Partition的Leader选举机制:依赖于zookeeper
为何要获得半数以上的选票才能成为leader———————->为了防止选出leader(防脑裂)
1.3.1名词解释
| Producer :消息生产者,就是向kafka broker发消息的客户端 |
|---|
| Consumer :消息消费者,向kafka broker取消息的客户端 |
| Consumer Group (CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者 |
| Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic |
| Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic |
| Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列 |
| Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower |
| leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader |
| follower:每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的follower |
1.3.2架构示意图
1.4kafka的用途

2.kafka技术深入(工作流程及文件存储机制)
2.1工作流程图

2.2文件存储机制(Partition-log)
2.2.1架构说明

kafka消息基于topic分类,生产者消费者都是面向topic(topic是逻辑上的概念,而partition是物理上的概念
每个partition对应一个log文件,log文件中存储producer的生产数据
Producer生产的数据会不断追加到该log文件的末端,且每条数据都有自己的offset
2.2.2kafka文件图示

2.2.3Segment中index与log图示
概述:Segment的命名是以0开始,后续每个segment文件名为上一个全局partion的最大offset(偏移message数)
上图为Segment

Segment内部文件
例:(3,497)意味着在该Index中它处于第三个的位置,497意味着(position )这个消息的偏移量
Partition中如何通过offset查找message
查找segment file(二分查找法定位具体文件)
定位具体segment file后根据offset获取Index元数据,通过Index元数据查找log文件中的物理偏移地址
2.3kafka生产者
2.3.1分区策略

2.3.2数据可靠性保证
2.3.2.1 ack机制

2.3.2.2 isr

2.3.2.3 故障处理细节

2.3.3 Exactly Once语义

2.4 kafka消费者

2.5Kafka高效读写机制

2.6 zookeeper在kafka中的作用

3. Kafka API
3.1 Producer API
3.1.1 采取异步发送(两个线程)
main线程
- 封装ProducerRecord对象
- 拦截器(Interceptors)
- 序列化(Serializer)
- 分区(Partitioner)
线程共享变量RecordAccumulator
- 多个消息队列对应Topic的分区
- 累计批次或时间后进入Sender线程
Sender线程
Kafka Producer**发送消息流程
3.1.2 如何写Producer API

3.2 Consumer API

3.3 自定义维护offset
3.4 自定义Interceptor


若有收获,就点个赞吧
0 人点赞
