安装Navicat 15 for MySQL
Navicat 15 for MySQL可以让我们很方便的使用mysql数据库,但是他是收费的 我们要对他进行破解。
https://www.jb51.net/database/710931.html
下载之后按照网站的安装说明进行安装破解(很详细的)
目标 url=‘https://weixin.sogou.com/weixin?query=%E6%9D%AD%E5%B7%9E+%E5%85%BC%E8%81%8C&_sug_type_=&sut=6012&lkt=0%2C0%2C0&s_from=input&_sug_=n&type=2&sst0=1603156914034&page=1&ie=utf8&w=01019900&dr=1‘
使用的库
from selenium import webdriverimport reimport timeimport pymysql
创建五个变量在存储数据
from selenium import webdriverimport reimport timeimport pymysqla = []#储存<h3>b = []#存储连接c = []#存储标题d = []#存储上传时间e = [] #存储公众号标题
我的思路是将一个页面的所有标题,连接,公众号时间,公众号分别储存在一个列表里面,最后用for循环储存在数据库里面
函数
打开网站,网页
打开网站:
driver = webdriver.Firefox()#打开网页def _open_url(url):driver.get(url)return driver
找出
标签
找出
标签里面的代码将他们储存到a里面方便以后获得连接和标题
#找出网页对应的所有代码,我们可以发现我们所需要的连接和标题都在
标签里面
#找出网页对应的所有代码,我们可以发现我们所需要的连接和标题都在<h3>标签里面def _daima_url(driver):html=driver.page_sourcefor match in re.finditer(r'<h3>[\s\S]*?</h3>', html):a.append(match.group(0))return a
找链接
def _lianjie(a):b.clear()#开始抽取连接for i in a:match = re.findall(r'href="[\s\S]*?"', i)''' 这是我们用正则表达式抽取的其中一个连接href="/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS4UJUyG4CdQtlQ50A-U4nmqXKdZwBkox-lqXa8Fplpd9UMrPzlMkQDq4TCEtzURXCvi3H7xxSEkl-JXIku-Vr8hPysUpERqrov8akWylxUE-y9Dx_bXRFxgtI_PUHOXsw3gDvPu9Y18BUwUZluYyIj6f5F_7zfm6c022OAxAE8nigKdYty2vQnI1d42SewE1fQ5Qi7emTki5dk969PttsoUNGbbB75bUeA..&type=2&query=%E6%9D%AD%E5%B7%9E %E5%85%BC%E8%81%8C&token=1BE302BE33C778027277C142D7F5300D72D97F725FA12570"这是网站上的正确网页连接:https://weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS4UJUyG4CdQtlQ50A-U4nmqXKdZwBkox-lqXa8Fplpd9UMrPzlMkQDq4TCEtzURXCvi3H7xxSEkl-JXIku-Vr8hPysUpERqrov8akWylxUE-y9Dx_bXRFxgtI_PUHOXsw3gDvPu9Y18BUwUZluYyIj6f5F_7zfm6c022OAxAE8nigKdYty2vQnI1d42SewE1fQ5Qi7emTki5dk969PttsoUNGbbB75bUeA..&type=2&query=%E6%9D%AD%E5%B7%9E%20%E5%85%BC%E8%81%8C&token=1BE302BE33C778027277C142D7F5300D72D97F725FA12570可以看出对比正确的连接其中有 amp 与正确的连接不同所欲我们要在开头加个https://weixin.sogou.com 以及把href= 和amp用replace替换掉'''# 清除href=" str(match[0]) 解释 因为match变量是一个列表 无法进行下一个正则匹配 我们要吧里面内容全部换成str类型才能匹配下一个正则result = re.sub('href="', "", str(match[0]))#清除amp;result2 = re.sub("amp;", "", result)#现在我们将正确连接储存到b中b.append('https://weixin.sogou.com'+result2)return b
找标题
def _biaoti(a):c.clear()for i in a:result = re.findall(r"uigs=[\s\S]*?", i)'''这是正则匹配的结果uigs="article_title_4">【杭州兼职】180元/天,福利多多,西湖银泰果汁店招兼职啦!!我们要去掉结果中的1.uigs="article_title_0">2. 3.!--red_end-->'''#1.去除uigs=result1 = re.sub(r"uigs=[\S\s]*?>", "", str(result[0]))#2.去除result2 = re.sub("", "", result1)#3.去除!--red_end-->result3 = re.sub("", "", result2)#杭州兼职:10月30号杭州兼职发布 这是我们找到的标题结果 可以看到后面还有个 我们也给他去除掉 并将最后结果保存在result4中result4 = re.sub("", "", result3)#我们将正确的标题存储到c中c.append(result4)return c
找上传时间
#上传时间def _shangchuantime(driver):#可以根据元素看起来上传时间都保存在class=“s2”的标签中 我们用selenium中的CSS查找元素找出所有的class=“s2”的元素并用for循环保存每一个#element.get_attribute('outerHTML') 是网页的源代码elements = driver.find_elements_by_css_selector('.s2')for element in elements:#2020-10-31#这是其中的一条 我们用找标题的方法将2020-10-31找出来result = re.findall(r"[\S\s]*?<", element.get_attribute('outerHTML'))result1 = re.sub("", "", str(result[0]))result2 = re.sub("<", "", result1)d.append(result2)return d
找公众号
def _GZHtitle(driver):elements = driver.find_elements_by_css_selector('.account')'''新注册公众号'''#按照上述方法把标题找出来for element in elements:result0 = re.findall(r"uigs=[\S\s]*?<", element.get_attribute('outerHTML'))result1 = re.sub("</script>", "", str(result0[0]))result2 = re.sub(r"uigs=[\S\s]*?>", "", result1)result3 = re.sub("<", "", result2)e.append(result3)return e
**
保存数据
def chucun(driver):a = _daima_url(driver)b = _lianjie(a) #结束后所有连接保存在b中c = _biaoti(a) #结束后所有标题保存在c中d = _shangchuantime(driver) #结束后所有上传时间保存在d中e = _GZHtitle(driver) #结束后所有公众号标题保存在e中
执行
#因为我们要上传五页 所以要获取下一页的连接:def zhixing():url = 'https://weixin.sogou.com/weixin?query=杭州+兼职&sug_type=&sut=6012&lkt=0%2C0%2C0&s_from=input&sug=n&type=2&sst0=1603156914034&page=1&ie=utf8&w=01019900&dr=1'for k in range(5):driver = _open_url(url)chucun(driver)# 我们找到下一页的连接next_daima = driver.find_element_by_id("sogou_next")# 下一页连接的源代码next_url0 = re.search(r"href[\s\S]*?class", next_daima.get_attribute('outerHTML'))# 取出连接next_url1 = next_url0.group(0).replace('href="', "")next_url2 = 'https://weixin.sogou.com/weixin' + next_url1.replace('class', '')url = next_url2.replace('amp;', '')time.sleep(3)
#使用print检查数据有没有问题#执行完第八个函数之后 我们可以在后面打赢出来abcde里面的内容以及数据数有没有出错,方便存储到数据库中的内容不会出错if __name__ == "__main__":zhixing()print(a)print(b)print(c)print(d)print(e)print(len(a))print(len(b))print(len(c))print(len(d))print(len(e))
这是print打印的结果,可以看出数据没有问题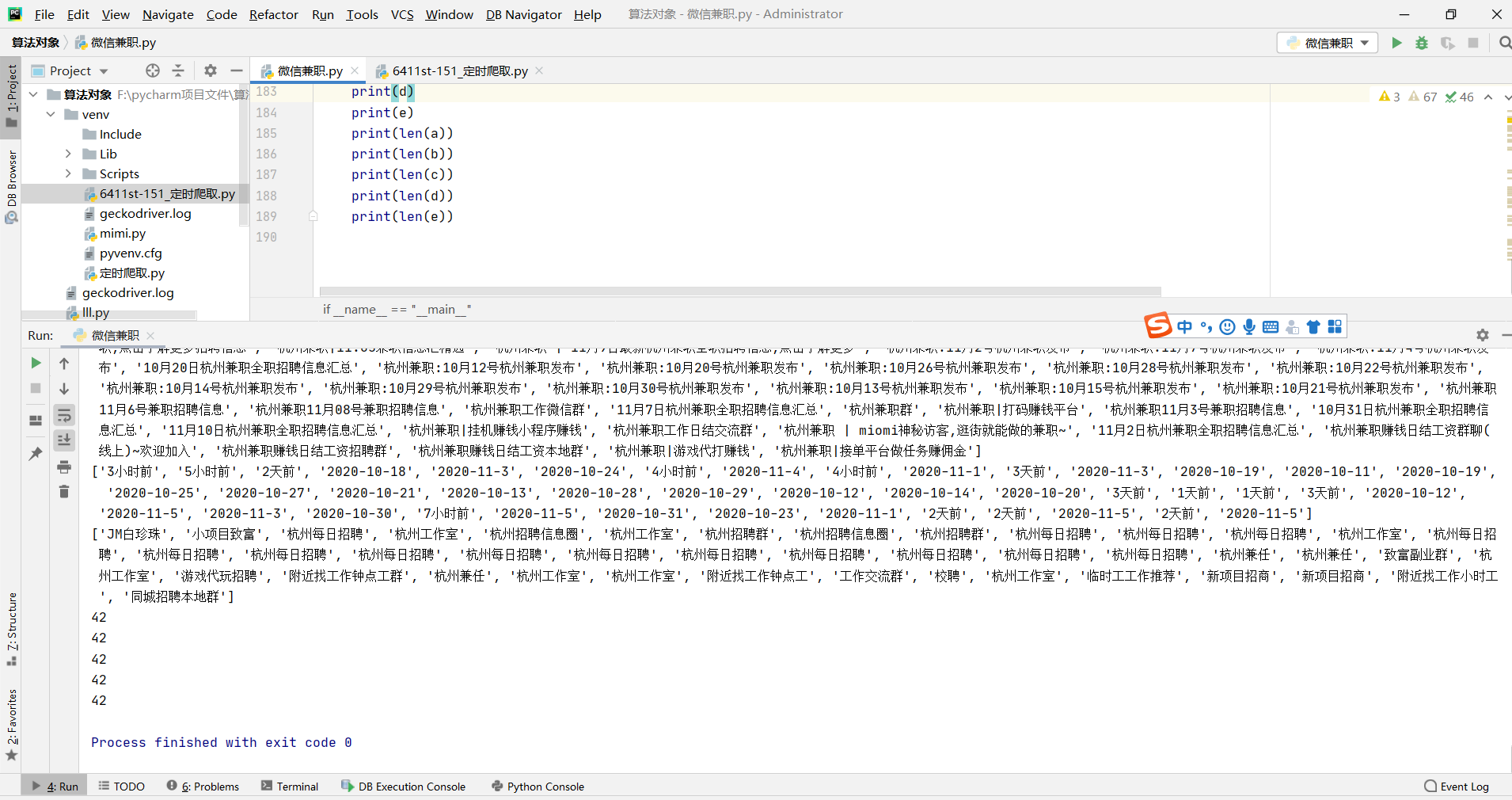
将数据上传到数据库中
#最后设置main 将数据储存到数据库中 :if __name__ == "__main__":zhixing()db = pymysql.connect(host='localhost', user='root', password='', port=3306, db='wx兼职')cursor = db.cursor()sql = 'INSERT INTO pachong(标题,连接,公众号,时间) values(%s,%s,%s,%s)' for i in range(len(a)):for i in range(len(a)):try:cursor.execute(sql, (c[i], b[i], d[i], e[i]))db.commit()except:db.rollback()
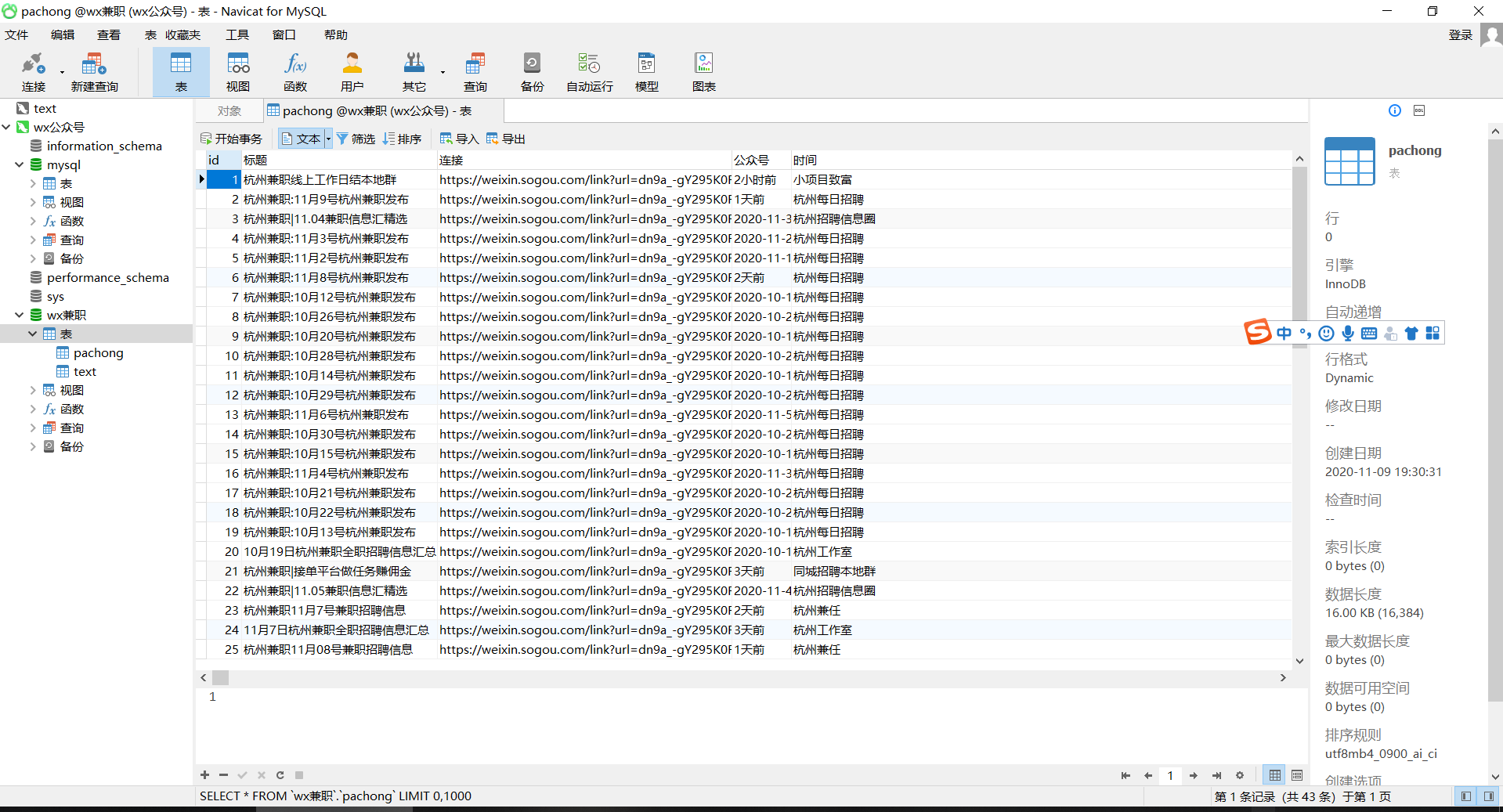
导出数据库
右键选中需要导出数据库,点击转存SQL文件 根据自己要求选结构和数据 或者结构。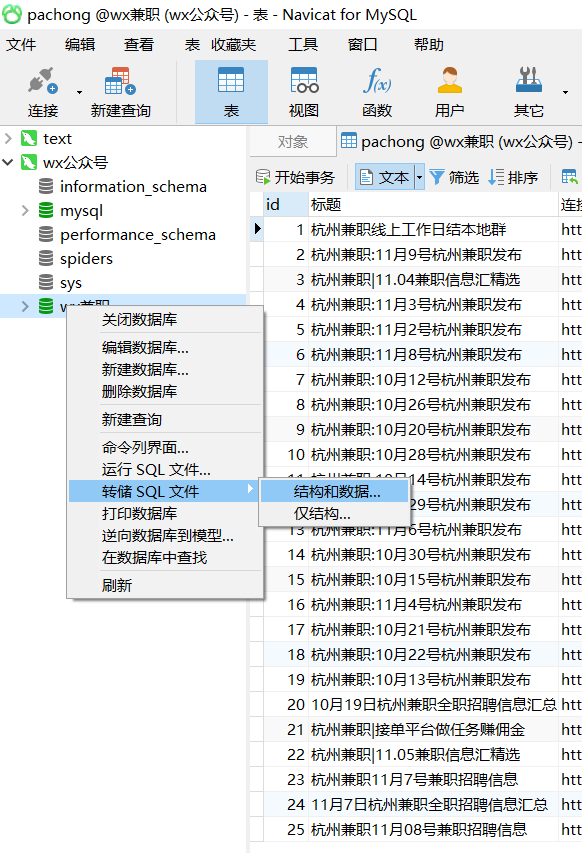
我们将它转存到桌面上,点击保存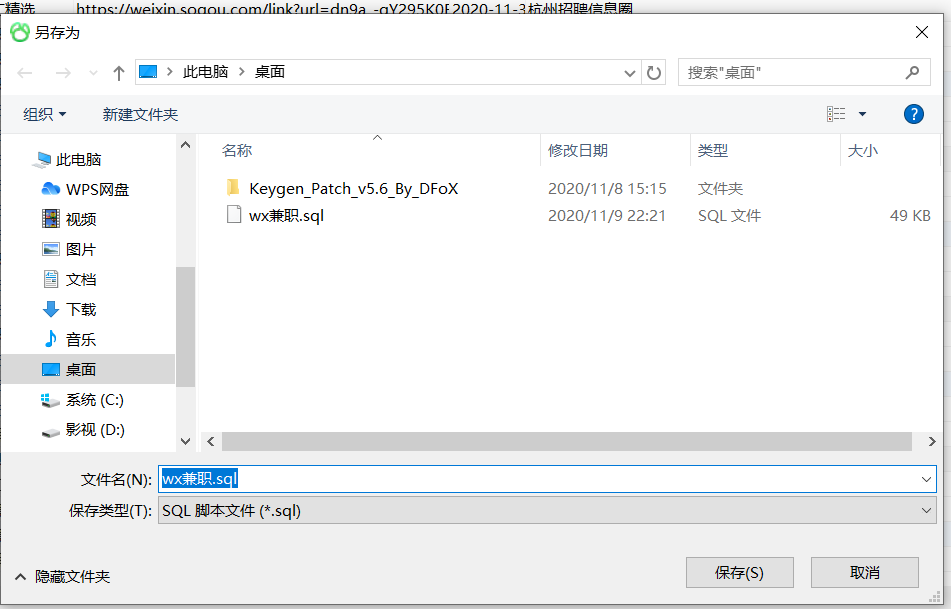
点击开始,结束后关闭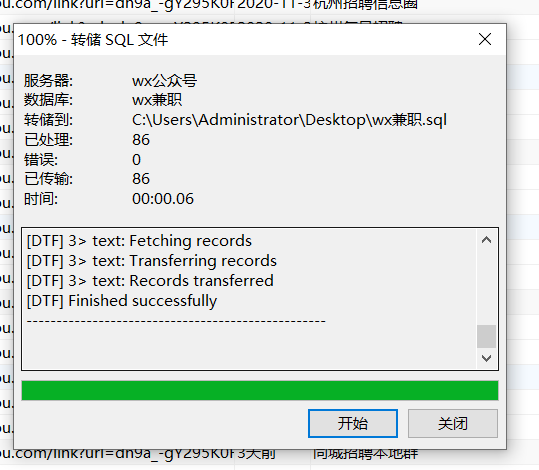
这样就在桌面上有个sql文件
导入数据库
我们新建一个数据库导入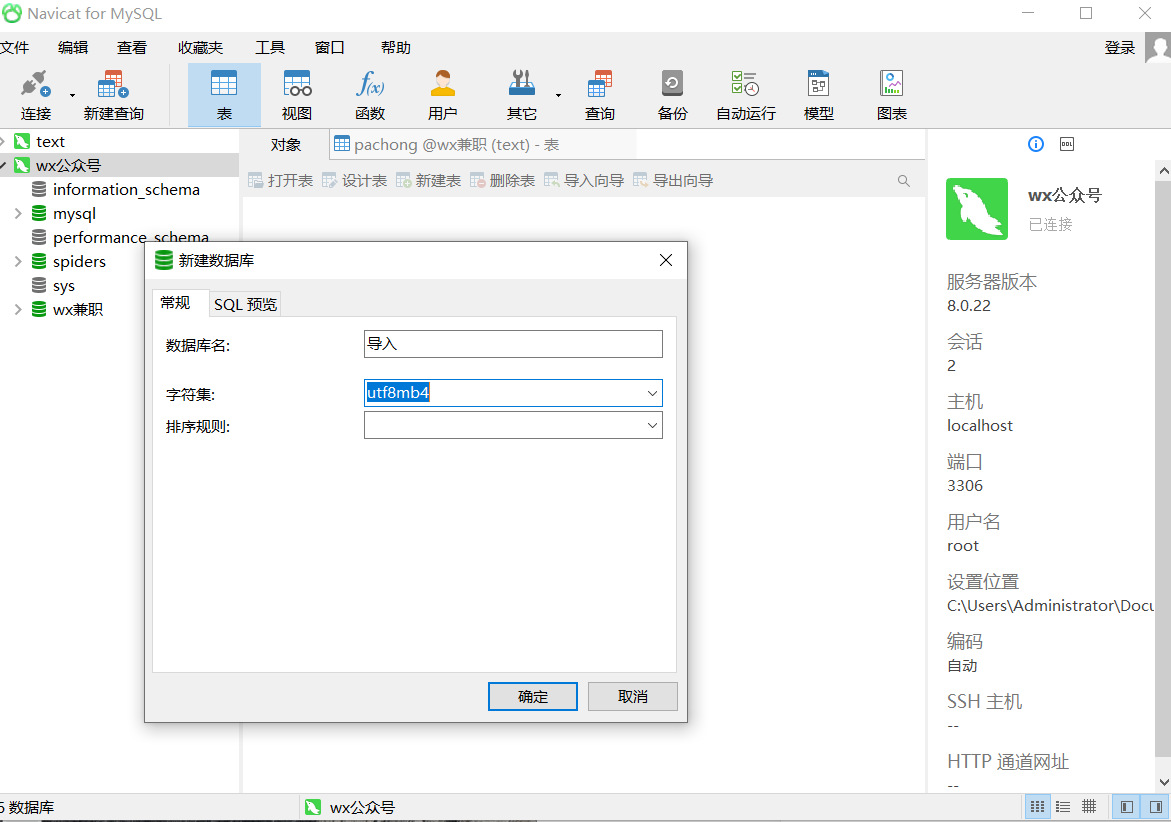
选中导入右键点击运行SQL文件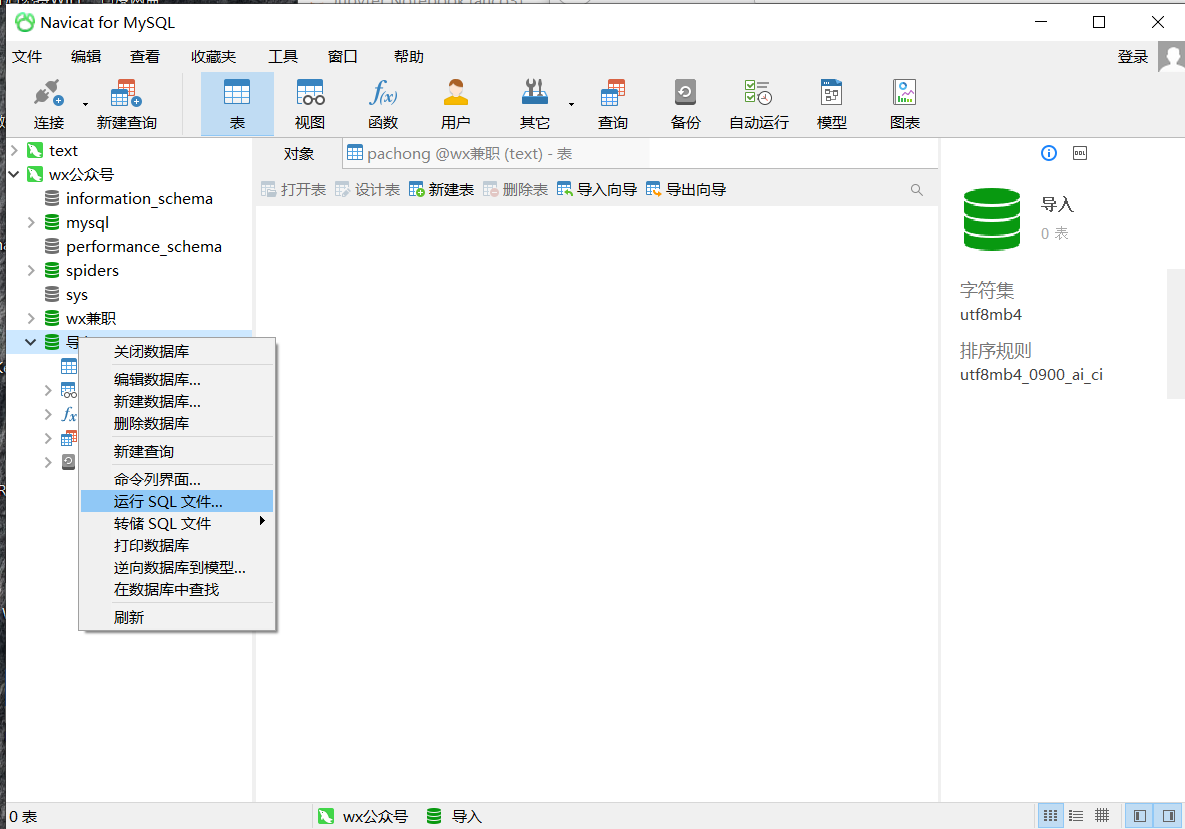
选中刚刚导出的文件,点击开始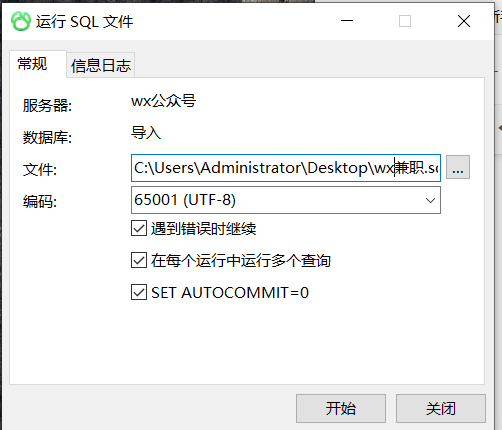
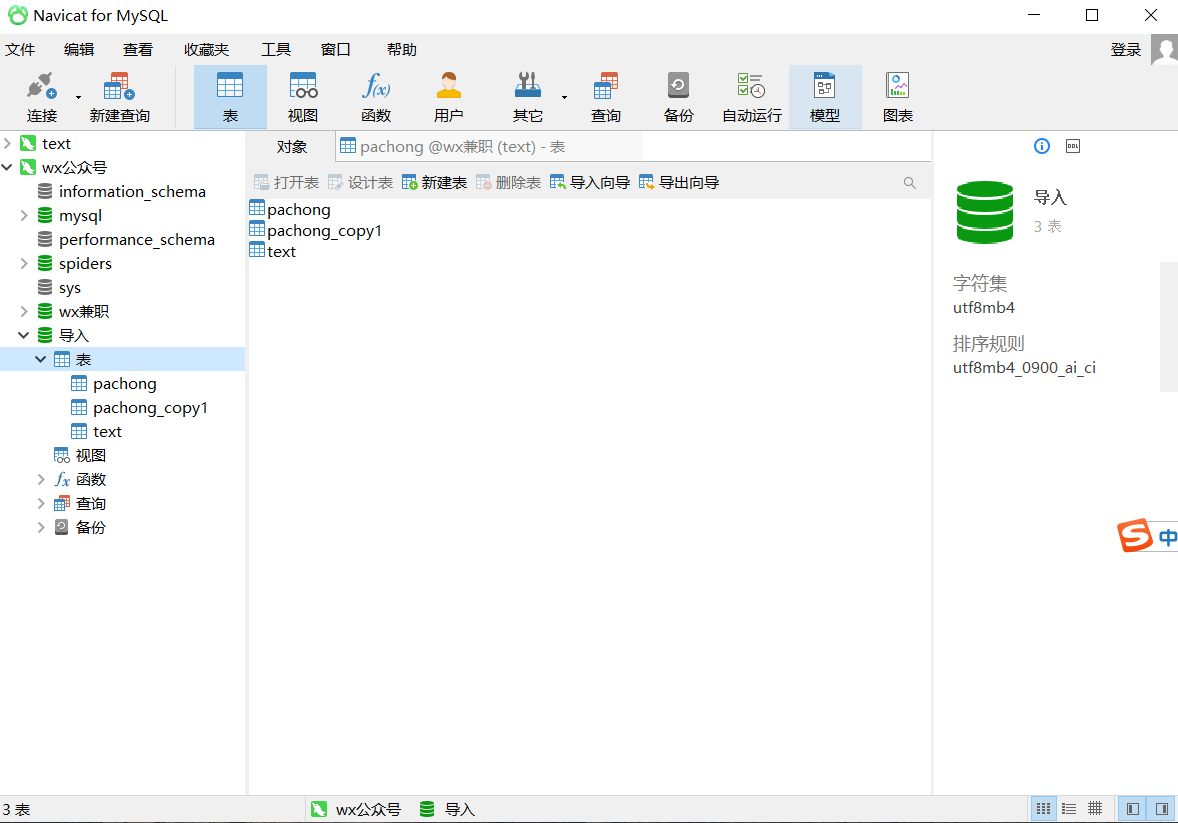
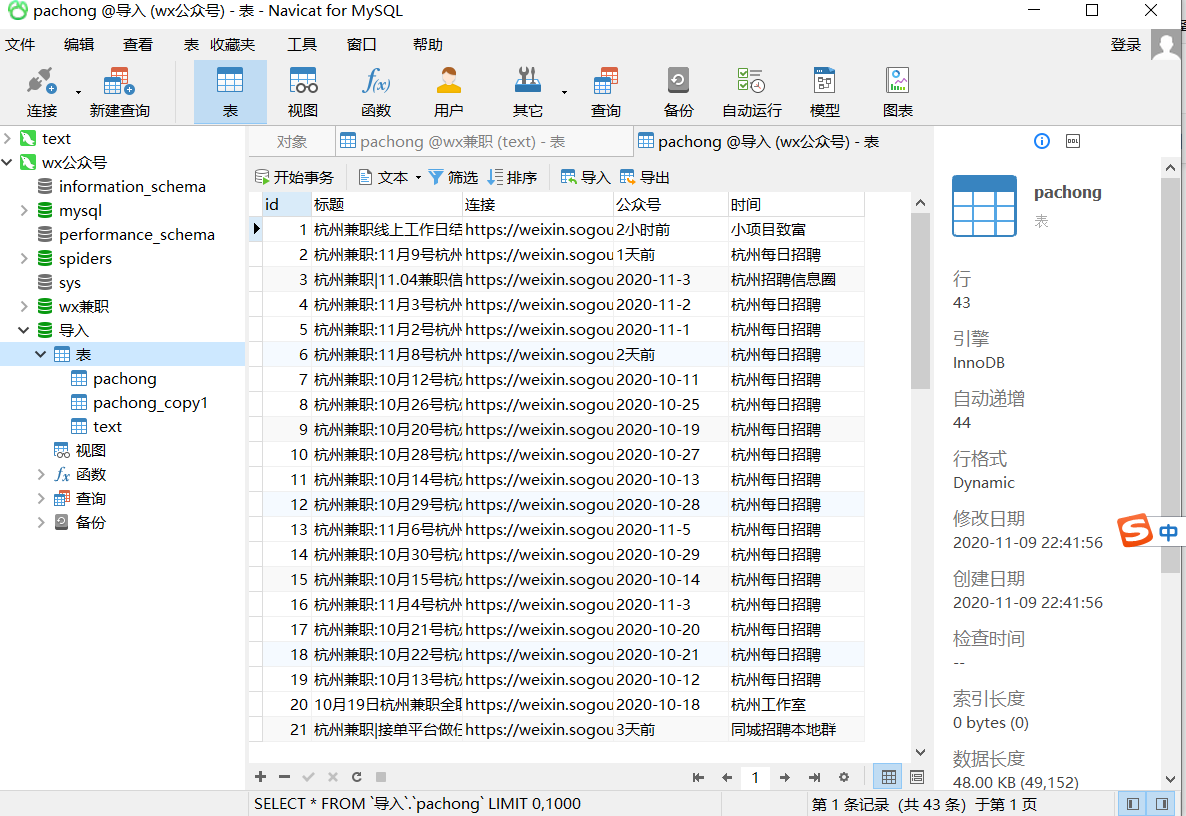
可以看到成功了
完整代码
#!/usr/bin/env python#encoding=utf-8from selenium import webdriverimport reimport timeimport pymysqla = []#储存<h3>b = []#存储连接c = []#存储标题d = []#存储上传时间e = [] #存储公众号标题driver = webdriver.Firefox()#打开网页def _open_url(url):driver.get(url)return driver#找出网页对应的所有代码,我们可以发现我们所需要的连接和标题都在<h3>标签里面def _daima_url(driver):html=driver.page_sourcefor match in re.finditer(r'<h3>[\s\S]*?</h3>', html):a.append(match.group(0))return adef _lianjie(a):b.clear()#开始抽取连接for i in a:match = re.findall(r'href="[\s\S]*?"', i)'''这是我们用正则表达式抽取的其中一个连接href="/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS4UJUyG4CdQtlQ50A-U4nmqXKdZwBkox-lqXa8Fplpd9UMrPzlMkQDq4TCEtzURXCvi3H7xxSEkl-JXIku-Vr8hPysUpERqrov8akWylxUE-y9Dx_bXRFxgtI_PUHOXsw3gDvPu9Y18BUwUZluYyIj6f5F_7zfm6c022OAxAE8nigKdYty2vQnI1d42SewE1fQ5Qi7emTki5dk969PttsoUNGbbB75bUeA..&type=2&query=%E6%9D%AD%E5%B7%9E %E5%85%BC%E8%81%8C&token=1BE302BE33C778027277C142D7F5300D72D97F725FA12570"这是网站上的正确网页连接:https://weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS4UJUyG4CdQtlQ50A-U4nmqXKdZwBkox-lqXa8Fplpd9UMrPzlMkQDq4TCEtzURXCvi3H7xxSEkl-JXIku-Vr8hPysUpERqrov8akWylxUE-y9Dx_bXRFxgtI_PUHOXsw3gDvPu9Y18BUwUZluYyIj6f5F_7zfm6c022OAxAE8nigKdYty2vQnI1d42SewE1fQ5Qi7emTki5dk969PttsoUNGbbB75bUeA..&type=2&query=%E6%9D%AD%E5%B7%9E%20%E5%85%BC%E8%81%8C&token=1BE302BE33C778027277C142D7F5300D72D97F725FA12570可以看出对比正确的连接其中有 amp 与正确的连接不同所欲我们要在开头加个https://weixin.sogou.com 以及把href= 和amp用replace替换掉'''# 清除href=" str(match[0]) 解释 因为match变量是一个列表 无法进行下一个正则匹配 我们要吧里面内容全部换成str类型才能匹配下一个正则result = re.sub('href="', "", str(match[0]))#清除amp;result2 = re.sub("amp;", "", result)#现在我们将正确连接储存到b中b.append('https://weixin.sogou.com'+result2)return bdef _biaoti(a):c.clear()for i in a:result = re.findall(r"uigs=[\s\S]*?</a>", i)'''这是正则匹配的结果uigs="article_title_4">【<em><!--red_beg-->杭州<!--red_end--></em><em><!--red_beg-->兼职<!--red_end--></em>】180元/天,福利多多,西湖银泰果汁店招<em><!--red_beg-->兼职<!--red_end--></em>啦!!</a>我们要去掉结果中的1.uigs="article_title_0">2. <em><!--red_beg-->3.!--red_end--></em>'''#1.去除uigs=result1 = re.sub(r"uigs=[\S\s]*?>", "", str(result[0]))#2.去除<em><!--red_beg-->result2 = re.sub("<em><!--red_beg-->", "", result1)#3.去除!--red_end--></em>result3 = re.sub("<!--red_end--></em>", "", result2)#杭州兼职:10月30号杭州兼职发布</a> 这是我们找到的标题结果 可以看到后面还有个</a> 我们也给他去除掉 并将最后结果保存在result4中result4 = re.sub("</a>", "", result3)#我们将正确的标题存储到c中c.append(result4)return c#上传时间def _shangchuantime(driver):#可以根据元素看起来上传时间都保存在class=“s2”的标签中 我们用selenium中的CSS查找元素找出所有的class=“s2”的元素并用for循环保存每一个#element.get_attribute('outerHTML') 是网页的源代码elements = driver.find_elements_by_css_selector('.s2')for element in elements:#<span class="s2"><script>document.write(timeConvert('1604116776'))</script>2020-10-31</span>#这是其中的一条 我们用找标题的方法将2020-10-31找出来result = re.findall(r"</script>[\S\s]*?<", element.get_attribute('outerHTML'))result1 = re.sub("</script>", "", str(result[0]))result2 = re.sub("<", "", result1)d.append(result2)return ddef _GZHtitle(driver):elements = driver.find_elements_by_css_selector('.account')'''<a class="account" target="_blank" id="sogou_vr_11002601_account_0"i="oIWsFtwbeMFIKOgK8nuArz_EksWM" href="/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6EzDJysI4ql5MPrOUp16838dGRMI7NnPqegdDsEEUfwxJfbo_1k2jXwwvDqyjOWdzlnYNyriFsra1h9rKze6a5FPJVhXd9I6T2oHKKEQvt75xK-LDdHU3y3rkjQPCoG-HYPFUO-m3Et7MbjmlZHQtxtzicJFaDsgndtFozGog2DMQ3inJVxe2HeO00efWrWmm&type=2&query=%E6%9D%AD%E5%B7%9E %E5%85%BC%E8%81%8C&token=29AB8EC921851BFD888D34D3115F268D888B7C9C5FA380A7"data-headimage="http://wx.qlogo.cn/mmhead/Q3auHgzwzM4CEQDjyTsWh9WvXTXYdSnzTUF4pdY9OnogEa9iccUzLibQ/0" data-isv="0"uigs="article_account_0">新注册公众号</a>'''#按照上述方法把标题找出来for element in elements:result0 = re.findall(r"uigs=[\S\s]*?<", element.get_attribute('outerHTML'))result1 = re.sub("</script>", "", str(result0[0]))result2 = re.sub(r"uigs=[\S\s]*?>", "", result1)result3 = re.sub("<", "", result2)e.append(result3)return edef chucun(driver):a = _daima_url(driver)b = _lianjie(a) #结束后所有连接在b中c = _biaoti(a) #结束后所有标题在c中d = _shangchuantime(driver) #结束后所有上传时间在d中e = _GZHtitle(driver) #结束后所有公众号标题在e中def zhixing():url = 'https://weixin.sogou.com/weixin?query=%E6%9D%AD%E5%B7%9E+%E5%85%BC%E8%81%8C&_sug_type_=&sut=6012&lkt=0%2C0%2C0&s_from=input&_sug_=n&type=2&sst0=1603156914034&page=1&ie=utf8&w=01019900&dr=1'for k in range(5):driver = _open_url(url)chucun(driver)# 我们找到下一页的连接next_daima = driver.find_element_by_id("sogou_next")# 下一页连接的源代码next_url0 = re.search(r"href[\s\S]*?class", next_daima.get_attribute('outerHTML'))# 取出连接next_url1 = next_url0.group(0).replace('href="', "")next_url2 = 'https://weixin.sogou.com/weixin' + next_url1.replace('class', '')url = next_url2.replace('amp;', '')time.sleep(3)if __name__ == "__main__":zhixing()db = pymysql.connect(host='localhost', user='root', password='', port=3306, db='wx兼职')cursor = db.cursor()sql = 'INSERT INTO pachong(标题,连接,公众号,时间) values(%s,%s,%s,%s)'for i in range(len(a)):try:cursor.execute(sql, (c[i], b[i], d[i], e[i]))db.commit()except:db.rollback()
py文件

若有收获,就点个赞吧
0 人点赞
