一、概述
1、Yarn介绍
资源调度平台,(管理集群资源,给任务合理分配)
(RM)ResourceManager 管理所有集群资源(内存、CPU。。。)
(NM)NodeManager 管理单个节点资源
(AM)ApplicationManager 管理单个任务
Contalner 容器
运行在YARN上的计算框架 (还有别的)
离线计算框架:MapReduce
DAG计算框架:Tez
流式计算框架:Storm
内存计算框架:Spark
2、Yarn优缺点
优点
- 解决了单点故障问题,由于每一个任务由一个AppMaster进行调度,且可进行AppMaster出错重试,从而使单点故障影响到多个任务进行问题不存在。
- 解决了单点压力过大问题,每一个任务由一个AppMaster进行调度,而每一个AppMaster都是由集群中资源较为充足的结点进行启动,调度任务,起到一个负载均衡的作用。
- 完成了资源管理和任务调度的解耦,Yarn只负责对集群资源的管理,各个计算框架只要继承了AppMaster,就可以共同使用Yarn资源管理,更加充分地利用集群资源。
3、Yarn角色
(RM)ResourceManager
1)处理客户端请求
2)监控NodeManager
3)启动或监控ApplicationManager
4)资源的分配与调度
(NM)NodeManager
1)管理单个节点资源
处理来自ResourceManager的请求
3)处理来自ApplicationManager的命令
(AM)ApplicationManager
1)为应用程序申请资源并分配给内部的任务
2)任务的监控与容错
Contalner
Contalner是YARN中的资源抽象,它封装了某个节点的多维度资源,如内存、CPU、磁盘、网络等
4、调度器和调度算法
Apache Hadoop-1.x默认调度器是FIFO;
Apache hadoop-2.7.2之后默认调度器是容量调度器Capacity Scheduler,也称计算能力调度器;
Apache hadoop-3.2.2默认调度器是公平调度器Fair Scheduler。
1、FIFO
FIFO调度器(First In First Out): 单队列,根据提交作业的先后顺序,先到先得。
优点: 简单易懂;
缺点: 不支持多队列,生产环境很少使用。
2、容量调度器
Capacity Scheduler是Yahoo开发的多用户调度器。
- 容量调度器特点

多队列 :每个队列可配置一定的资源量,每个队列内部采用FIFO调度策略;
容量保证:管理员可为每个队列设置资源最低保证和资源使用上线;
灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列;
多租户:
a. 支持多用户共享集群和多应用程序同时运行;
b. 为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源进行限定。
3、公平调度器
Fair Scheduler是Facebook开发的多用户调度器。
- 公平调度器特点

与容量调度器相同点:
多队列 :每个队列可配置一定的资源量,每个队列内部采用FIFO调度策略;
容量保证:管理员可为每个队列设置资源最低保证和资源使用上线;
灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列;
多租户:
a. 支持多用户共享集群和多应用程序同时运行;
b. 为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源进行限定。
4、容量调度器和公平调度器区别
核心调度策略不同
容量调度器: 优先选择资源利用率低的队列;
公平调度器:优先选择对资源缺额比例大的。
二、部署安装
1、下载安装包
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz
2、解压
mv hadoop-3.3.2.tar.gz /home/hadoop/tar -zxvf hadoop-3.3.2.tar.gzchown hadoop:hadoop -R hadoop-3.3.2*ll -rt | grep hadoop
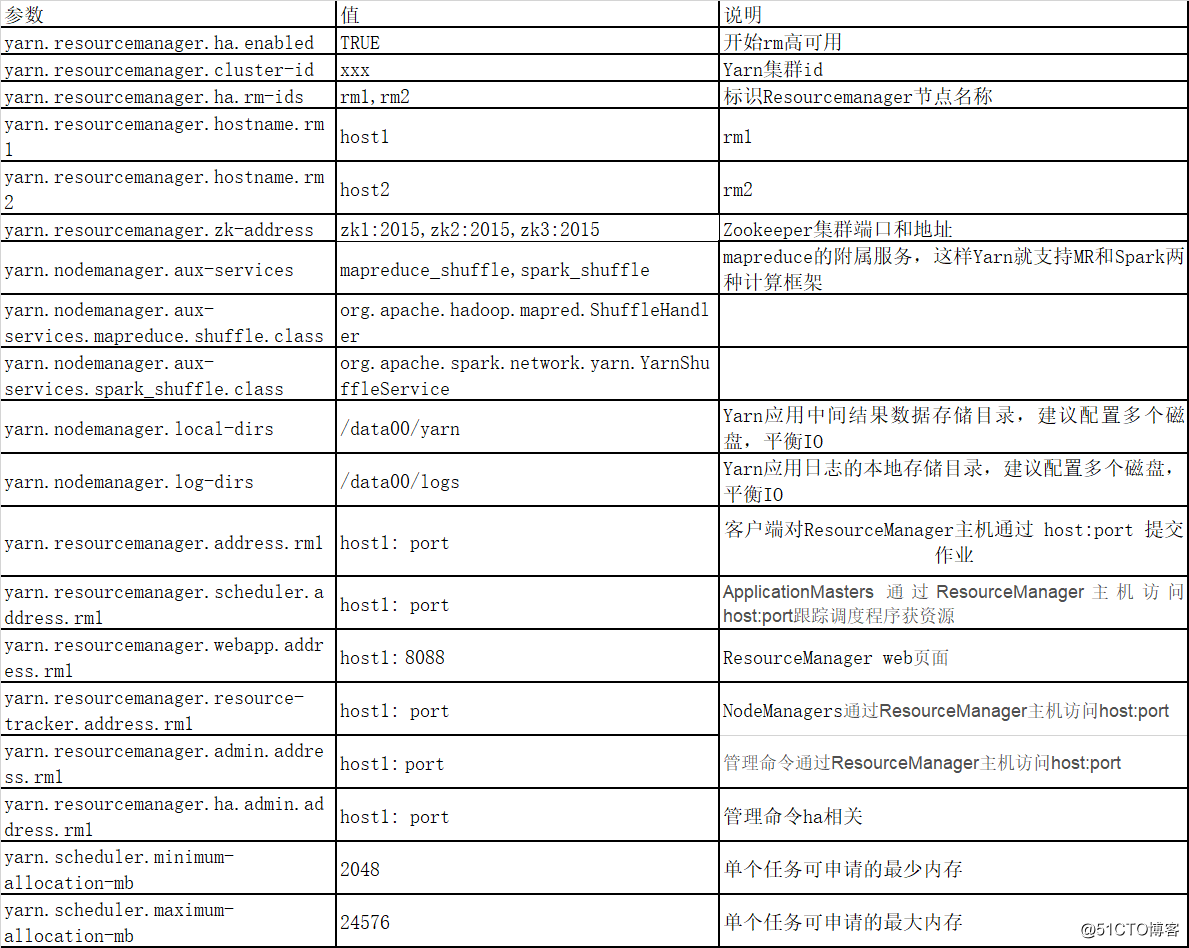
3、修改yarn-site.xml 文件
cd hadoop-3.3.2vim ./etc/hadoop/yarn-site.xml
<configuration><-- 允许跨域访问的来源,如果有多个,用逗号(,)分隔 --><property><name>hadoop.http.cross-origin.allowed-origins</name><value>*</value></property><-- RM所在的主机 --><property><name>yarn.resourcemanager.hostname</name><value>griffin</value></property><-- 以逗号分割的服务列表 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle,spark2_shuffle,timeline_collector</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><-- 存储容器日志的地方 --><property><name>yarn.nodemanager.log-dirs</name><value>/tmp/logs</value></property><-- 是否启用日志聚合。yarn.nodemanager.remote-app-log-dir确定日志存储位置--><property><name>yarn.log-aggregation-enable</name><value>true</value></property><-- 将日志聚合到的位置 HDFS路径 --><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/yarn-logs/logs</value></property><-- 远程日志目录前缀 --><property><name>yarn.nodemanager.remote-app-log-dir-suffix</name><value>logs</value></property><-- 在删除聚合日志之前保留多长时间。 --><property><name>yarn.log-aggregation.retain-seconds</name><value>360000</value></property><-- 日志聚合服务器的URL --><property><name>yarn.log.server.url</name><value>http://griffin:19888/jobhistory/logs</value></property><-- 服务器将绑定到的实际地址 , 0.0.0.0 使RM监听所有接口非常有用 --><property><name>yarn.resourcemanager.bind-host</name><value>0.0.0.0</value></property><-- RM web页面访问地址 --><property><name>yarn.resourcemanager.webapp.address</name><value>hdp101:8088</value></property><!-- for java 8 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><-- 是否将对容器强制实施虚拟内存限制。 --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property></configuration><-- 参考文档:https://blog.csdn.net/qq_35995514/article/details/120803426 -->
4、启动
su - hadoopcd sbin/./start-yarn.sh
./stop-yarn.sh
5、jps查看和ps查看
jps | grep 'ResourceManager\|NodeManager'ps -elf | grep 'ResourceManager\|NodeManager'

三、使用自带模板测试
cd hadoop-2.6.5/bin./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /sanguo /sanguoput

四、命令行操作Yarn
1、列出所有Application
yarn application -list
2、根据Application状态过滤:(ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)
yarn application -list -appStates All
3、kill掉Application
yarn application -kill application_1650620359034_0013
4、yarn logs 查看日志
yarn logs -applicationId application_1650620359034_0013
yarn logs -applicationId <ApplicationId> -containerId <ContainerId>
5、yarn applicationattempt 查看尝试运行任务
yarn applicationattempt -list application_1650620359034_0013
6、yarn node 查看节点状态
yarn node -list -all
7、yarn rmadmin更新配置
加载队列配置
yarn rmadmin -refreshQueues
8、yarn queue 查看队列
yarn queue -status default

五、Yarn的tool接口
六、Yarn工作流程

YARN在处理任务时,经历了以下几个步骤:
客户端向YARN提交一个作业(Application)。
作业提交后,RM根据从NM收集的资源信息,在有足够资源的节点分配一个容器,并与对应的NM进行通信,要求它在该容器中启动AM。
AM创建成功后向RM中的ASM注册自己,表示自己可以去管理一个作业(job)。
AM注册成功后,会对作业需要处理的数据进行切分,然后向RM申请资源,RM会根据给定的调度策略提供给请求的资源AM。
AM申请到资源成功后,会与集群中的NM通信,要求它启动任务。
NM接收到AM的要求后,根据作业提供的信息,启动对应的任务。
启动后的每个任务会定时向AM提供自己的状态信息和执行的进度。
作业运行完成后AM会向ASM注销和关闭自己。
七、作业提交流程

若有收获,就点个赞吧
0 人点赞
