(一)——安装和测试
学习网络爬虫也是进行自然语言处理的前期准备工作,爬虫是获取大量语料的利器,自从学会使用网络爬虫之后,帮人爬了些网页数据,感觉自己胸前的红领巾又更鲜艳了一些
最开始用的是BeautifulSoup爬取静态网页,效果已经很让我惊艳了
后来遇到动态网站,又用了下Selenium,调用firefox爬取动态数据,也是成就感满满
然而听说爬虫框架Scrapy更高效(B格更高),于是决定今天开始学习一下
首先听说windows系统下Scrapy安装非常的复杂,我已经准备好又折腾一整天,不过有了Anaconda平台,这些都不是事,一行代码搞定:
conda intall scrapy
然后是测试:
scrapy startproject test #创建项目 cd test #进入项目目录 scrapy genspider baidu www.baidu.com #生成爬虫 scrapy crawl baidu #爬取百度
(二)——熟悉Xpath
开始Xpath之前先补充一下刚刚踩的一个小小坑
准备写这篇笔记之前打算在笔记本上也装上scrapy,结果用conda install安装好慢好慢好慢,一度以为是家里网络问题,查了下才发现添加下国内镜像源就可以了,输入以下代码即可:
conda config —add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config —set show_channel_urls yes conda config —add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ conda config —add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
好了,开始Xpath,Xpath就是用来在XML文档中查找目标元素的语言,HTML和XML一样,也是洋葱一样的一层一层包裹的结构,所以可以用Xpath很方便地在HTML文档中找到我们想要的元素
Xpath长这样:
//*[@id=”t1”]/tbody/tr/td/table/tbody/tr/td/table[1]/tbody/tr[2]/td[2]/table[1]/tbody/tr[2]/td[3]/b
就是一层一层地找下来,找到目标元素
很多浏览器都可以很方便地查看网页中某元素的Xpath,右键单击要查看的目标,选择“查看元素”,在显示的元素源代码中右键选择“复制Xpath”,上面一段长长的Xpath就是这么来的
不过实际使用中不建议直接用上面这样的Xpath,因为这个路径太长,还有很多按数字顺序选择的元素,万一网页结构稍有变化(比如弹出个广告框),这个结果就谬之千里了
比较稳妥的做法是用id来选择
嗯,Xpath的语法有很多很多,参见教程吧
接下来就是在scrapy中尝试一下Xpath的威力
在Anaconda端口输入
scrapy shell www.目标网页.com
居然又报错!(真是一台电脑一个环境,各种报错层出不穷啊)
错误信息:DLL load failed: 操作系统无法运行1%
解决方法:pip install -I cryptography
好啦,网页读取正常啦,接下来就用response.xpath(‘ ‘).extract()各种尝试吧
最后ctrl+d退出
(三)——创建项目
下面要正式开始创建项目了,其实在第一篇笔记的安装测试中,就已经创建了一个项目
这次我计划从一些期刊中爬取标题、摘要、关键词等内容,所以我创建了一个名为articles的项目:
anaconda端口中cd到准备存储项目的文件夹,输入scrapy startproject articles
发现文件夹中多了一个名为articles的文件夹,点开是这样的:
只用一行代码,项目就搭好了,接下来就要往文件夹里面一点一点填东西
这下理解了为什么scrapy叫爬虫框架,就是人家搭好了架子,按照模板填东西就好
(1)定义Item
打开文件夹中的items.py文件,按照给出的示例(name = scrapy.Field()),定义我准备爬取的字段,包括中英文标题、关键词、摘要等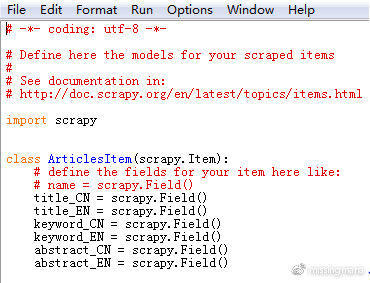
(2)编写爬虫
scrapy提供了不同的爬虫模板,用scrapy genspider -l查看,有basic、crawl、csvfeed、xmlfeed四种
先用basic模板试试,输入
scrapy genspider basic web
spiders文件夹中多了一个basic.py文件
打开编辑一下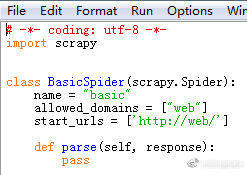
start_urls = [‘ ‘]里面填入要爬取的文章网页
def parse(self, response):里面填入网页中要获取的字段内容,这里Xpath就大派用场了
用Xpath获取网页中的目标元素
(3)运行爬虫
Anaconda端口输入
scrapy crawl basic
编辑好的basic.py爬虫就开始运行了,控制台输出了我要的标题、关键词、摘要等内容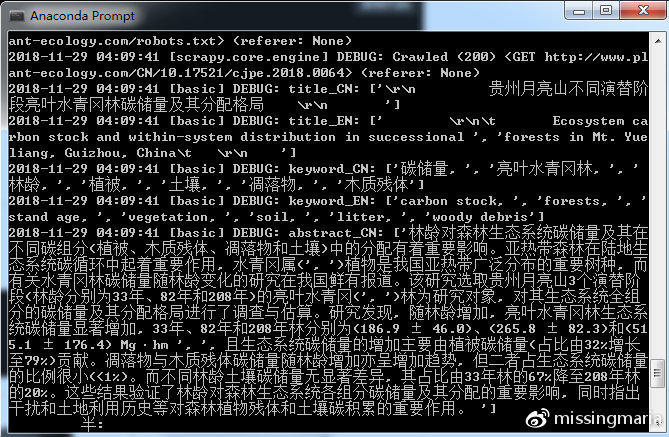
换一个文章网页也可以
scrapy parse —spider=basic http://另一篇文章的网站.com
(4)填充Item
目前为止,第一步定义的Item似乎还没有发挥作用,爬取的目标元素直接在控制台中输出了,看起来乱的很
不急,这就把结果导入到之前定义的Item中
还是编辑basic.py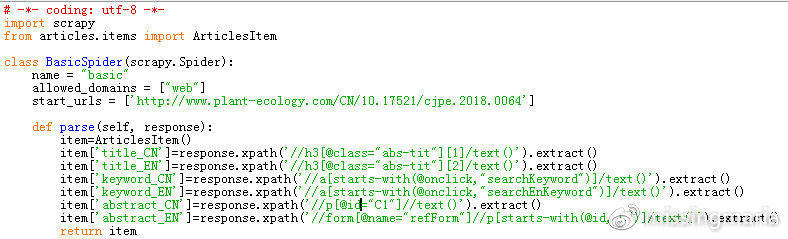
如上图,首先导入编写的ArcticlesItem:from articles.items import ArticlesItem
定义一个item实例:item=ArticlesItem()
给item的字段赋值,如:item[‘title_CN’]=response.xpath(‘//h3[@class=”abs-tit”][1]/text()’).extract()
最后不要忘记 return item
然后端口再运行:
scrapy crawl basic -o items.xml
结果直接导出到xml文件(json、jl、csv文件都可以,这里我选了xml)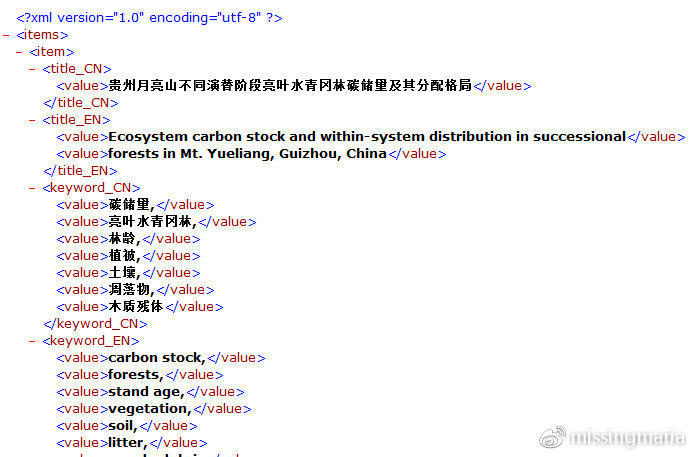
好了,大功告成,一个最最基础的爬虫就搭起来了,后面再接着完善
(四)——清洗Item
上一部分已经成功爬出了需要的字段,但是结果还不是很理想,比如还有一些恼人的逗号、不必要的分段等等
我以前的解决方式是导出来之后,另外用re模块进行文本处理
但是scrapy框架里面,这一步工作也为我们考虑到了,这就是ItemLoader,相当于一个中转站,爬下来的数据先不着急放到Item里面,而是在ItemLoader中先清洗一下,然后再导出到Item中
ItemLoader的具体用法见官方文档,还有一篇中文的博客文章也不错。
用ItemLoader可以自己构建处理器(Processor),将爬取的原始数据经过处理器处理后再导出到Item中。不过我目前只需要用到内置的一些处理器,一个是Join(),将获取的多个段落连接成一个;
还有一个是MapCompose(),()里面可以放入多个函数,数据由第一个函数处理完后,传递给第二个函数,以此类推。我只用了一个函数,MapCompose(lambda i:i.replace(‘,’,’’)),将多余的‘,’去掉。
好了,现在接着来修改basic.py文件:
首先导入需要的对象、函数:
from scrapy.loader import ItemLoader from scrapy.loader.processors import MapCompose,Join


(五)——爬取多个url
之前的笔记一直只是在拿一个网页做试验,但实际上我们需要对整个网站进行爬取
还是要对basic.py进行修改
最直接的方法就是在start_urls的列表里面添加网页地址
start_urls = [‘url1’,’url2’,’url3’]
很明显这不是一个理智的做法
还有一种方法是如果已经有了一个待爬取网页的列表,把它存在txt文档中,一行为一个网址,然后读取这个txt文件
start_urls = [i.strip() for i in open(‘list.txt’).readlines()]
这个方法看着B格也不是很高,不过有时候能应急,我在不会爬取动态网站的时候就用了这个方法,把网址索引页的表格整个复制粘贴到excel中,就这样弄到了整个网站的url列表(虽然B格不高,但是够快够轻松啊)
现在看看scrapy用的方法吧
先导入需要的函数 from scrapy.http import Request
起点设置成第一期的网页start_urls = [‘/the first volume/‘]
把原先的parse()函数更改为parse_item()
再写一个新的parse()函数,这个函数一方面调取下一期的url(next_selector),接着进行解析;另一方面调取本期文章的url(item_selector),填充item
最后端口运行scrapy crawl basic -o items.xml
喝几口茶,ok,全部爬完啦,一个10M的xml文件呈现在面前
好吧,真实场景是我又遇到了坑
1.Request()中必须加上dont_filter=True,否则什么都爬不到,原因不明(目标url和allowed_domains也并不冲突啊。。。。。。)
2.原本是用urlparse来解析抽取的相对路径,总是报错,最后只好用了个字符串替换解决了(还是原因不明)
3.scrapy还提供了一种B格更高的类LinkExtractor,上面的7行代码可以用2行解决,尝试了一下午,没有成功
目前就先到这里吧,接下来还准备再爬一些期刊,多多准备语料
scrapy还有更多更强大的功能,留着有空再慢慢研究

若有收获,就点个赞吧
0 人点赞
