项目介绍
作为个人练手项目,从前端到后端都选择了开源框架,数据库使用图数据库Neo4j,然后因为Neo4j使用d3.js做可视化,前端使用d3.js也确定下来了。网上找了很多教程,都是用java做后端,可是我一直用的是python,python作为一门胶水语言,用在这里也不在话下吧,于是整个技术栈就确定了:
- 前端:d3.js v4 力导向图
- 网络框架:python-flask
- 数据调用接口:python-py2neo
- 数据库:Neo4j
源码在github(还在更新中),主体部分呈现效果如下图: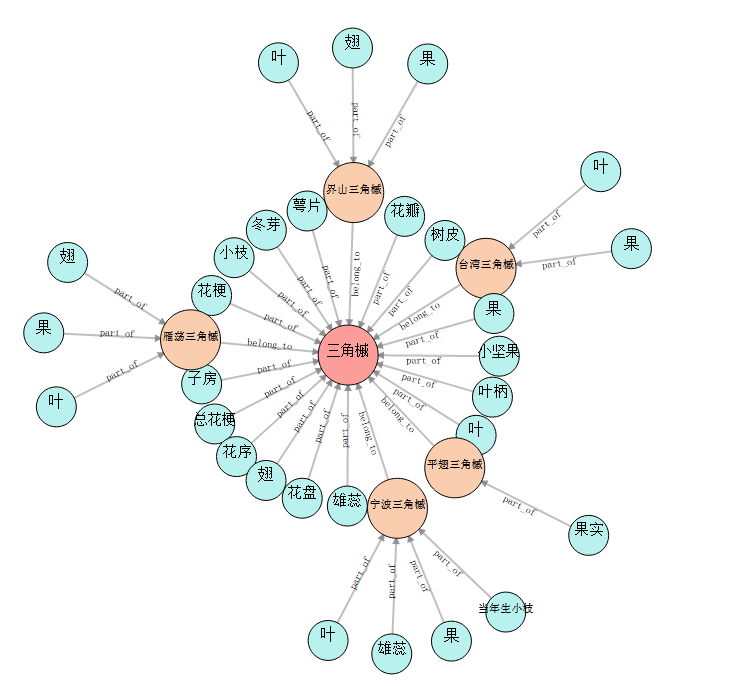
技术背景
- d3.js是一款用于数据可视化的Javascript库,优点是灵活,可以个性化定制,相应地学习起来也会困难一些;据说echart就容易上手得多,而且后者现在也可以做关系图。不过我还是喜欢定制度更高的选项,所以花了一个月学了d3.js,实现效果还是令人满意的。学习资料是《D3 4.X 数据可视化实战手册》,
- Flask是用 Python 编写的轻量级 Web 应用程序框架,教程看这里。之前也在Flask和Django之间犹豫过,最后看中了Flask的轻量,也就是灵活性高,而且据说“与非关系型数据库的结合远远优于Django”。实际使用过程中,发现如果仅需要实现可视化的话,一行
python -m http.server加一个index.html文件也够用了。 - py2neo是python中可以与Neo4j对接的库,我用的v4版本,上一篇更新就是py2neo v4使用笔记
- Neo4j是一款开源的图数据库,使用Cypher语言进行数据检索查询,我入门看的是《Graph_Databases_for_Beginners》,后来发现网上中文教程也很多,还有中文社区
另外还要说明一下,作为大龄才自学入门编程的野生码农,写的个人练手项目肯定是缺陷多多的,很多效果也没能完全实现,发在这里希望能有高手指点指点。
一.开发环境搭建
1. 最简单的方式——文本编辑器和浏览器
下载d3.js文件,我用的是4.x版本,现在已经更新到5了,从v3到v4改动是相当大的,v5应该没有步子跨这么大。然后将js文件和index.html文件放在一个文件夹,就可以用浏览器打开html文件来查看可视化效果了。
但是要从其他文件中加载数据的话,这种方式就不可行了,还是需要搭建自己的HTTP服务器。我们后面要用到json格式的数据文件,所以必须搭建服务器。
不用外部数据文件,直接在js代码中定义数据也是可以的,例如:
var links = [{source: 0, target: 2, rel:"belong_to"},{source: 0, target: 3, rel:"belong_to"},{source: 0, target: 4, rel:"belong_to"},{source: 1, target: 5, rel:"part_of"}];
2. python简易HTTP服务器
用python搭个服务器超级方便有没有,一行代码搞定,python2就用:
python -m SimpleHTTPServer 8888
python3就用:
python -m http.server 8888
8888是端口号,不写的话默认是8000。在项目文件夹下运行这行代码,然后浏览器就可以通过http://localhost:8888访问这个文件夹下的所有文件了
目前为止,这个简易服务器就够用了,可以直接进入第二部分,写前端页面了。
3. python-flask服务器
如果要实现更多功能,做一个完整网站,就可以用flask搭建服务器,我使用的文件目录结构如下,后面会再详细介绍:
├─config.py
├─server.py
├─static
│ ├─css
│ ├─data
│ └─js
└─templates
└─index.html
4. 基于NPM的开发环境
虽然我没有用过node.js和NPM,但是据说也很好用,写在这里备忘。
安装node.js之后,安装http-server模块:
npm install http-server -g
运行服务器,默认端口号是8080,也可以指定端口号:
http-server -p 8888
二.前端页面——D3.js力导向图
1.引用文件
部分引用上前面下载的d3.js文件,另外还有css文件
<script type="text/javascript" src="static/js/d3.js"></script><link rel="stylesheet" type="text/css" href="static/css/styles.css"/>
2.定义基本变量
然后在部分就可以开始写js代码了,将下面的js代码都放在<script type="text/javascript">``</script>之间,首先定义svg画布大小w、h,节点半径r,不同类型节点显示的颜色colors
var w = 1280,h = 800,r = 30,colors =d3.scaleOrdinal().domain(["species","subspecies","organ"]).range(["#FC9D9A","#F9CDAD","#B8F1ED"]);
定义colors时用到了d3.scaleOrdinal(),实际上是指定了一种映射关系,不同类型的节点(在这里是domain,理解为函数的定义域)对应于不同的颜色(range,函数的值域),后面我们会调用这种映射关系,给节点指定颜色。
d3里面还有很多种尺度函数,可以自动进行函数换算,例如将(20,200)范围的数值换算为(0,100)范围的图形宽度,这里不再详述。
3.定义相互作用力
接下来定义力导向图中最核心的部分——力,力导向图中的“粒子”(节点)模拟了物理世界中粒子在力的作用下的运动,只要定义好粒子间的相互作用力,粒子就会自己排布好,而不用费心去布局每个粒子放在画布的哪个地方,具体的原理和算法参见这篇博文。
var force = d3.forceSimulation().velocityDecay(0.2).alphaDecay(0).force("charge", d3.forceManyBody().strength(-200)) //负值表示设置为互斥力.force("x", d3.forceX(w / 2).strength(0.02)) //屏幕中心的引力.force("y", d3.forceY(h / 2).strength(0.02)) ;
其中,velocityDecay是速度衰减,数值范围是0-1,相当于摩擦力,值越大速度衰减越大,可理解为摩擦力越大;0对应无摩擦的环境,而1将冻结所有粒子(参考资料中,《D3 4.X 数据可视化实战手册》这本书中写反了);
alphaDecay,α衰变,借用粒子的放射性的概念,指力的模拟经过一定次数后会逐渐停止;数值范围也是0-1,如果设为1,经过300次迭代后,模拟就会停止;这里我们设为0,会一直进行模拟。
4.定义svg画布
定义svg画布相当于在浏览器中划定了一块坐标系,可以在里面画点、线、面,而且由于是矢量作图,放大也不会失真。
var svg = d3.select("body").append("svg").attr("width", w).attr("height", h);
5.绑定数据
d3.js有一套特殊的机制将数据绑定在DOM元素上,从而使数据得到可视化展示。这套机制就是“进入-更新-退出”(enter-updata-exit)模式 。
进入:当数据多于元素时,需要添加元素。例如我现在有一个数组,但还没有图形元素,可以用append操作添加元素。
更新:当数据=元素时,但数据发生了变化,更新元素上绑定的数据。
退出:当数据少于元素时,需要删除元素,常用remove操作,然后更新元素上绑定的数据。
具体的理解,可以看这篇博文。
这部分代码很长,又有点杂乱,我放上节点部分做例子。
var nodeElements = svg.selectAll("circle.node").data(nodes) //绑定节点数据,为json格式.enter().append("circle") //进入模式,添加circle元素.style("fill", function(d) { //调用函数,给不同类别的节点填充不同颜色return colors(d.label); //根据每个数据d的label值,调用前面的colors尺度,转换为对应的颜色}).style("stroke", "#000").call(d3.drag() //定义鼠标拖拽时的效果.on("start", dragStarted) //鼠标开始拖拽时,实现dragStarted,后面会定义这个函数.on("drag", dragged).on("end", dragEnded)).on("dblclick",releaseNode) //鼠标双击时,实现releaseNode
其中调用的一些函数如下:
//节点拖拽并固定,固定后节点变红色function dragStarted(d) {d.fx = boundX(d.x);d.fy = boundY(d.y);}function dragged(d) {d.fx = boundX(d3.event.x);d.fy = boundY(d3.event.y);}function dragEnded(d) {d.fx = boundX(d.x);d.fy = boundY(d.y);d3.select(this).style('fill',"#F00");}//双击解除节点固定,并恢复颜色function releaseNode(d) {d.fx = null;d.fy = null;d3.select(this).style('fill',colors(d.label));}//确保节点不会被拖拽到svg画布之外function boundX(x) {return x>(w-r)?(w-r):(x>r?x:r);}function boundY(y) {return y>(h-r)?(h-r):(y>r?y:r);}
最后不要忘了下面这个重要的函数,作用是计算每一帧的节点的坐标值,就像动画一样,实时更新节点在力的作用下,坐标的变化
force.on("tick", function(e) {
nodeElements.attr("cx", function(d) { return boundX(d.x); })
.attr("cy", function(d) { return boundY(d.y); });
});
三.服务器对Neo4j的数据调用
1.数据接口
上面可视化展现的json数据从哪里来呢?python里面有个py2neo库,可以实现对Neo4j的数据库操作,详细使用方法可以见我之前的文档,Py2neo v4 使用笔记
这里我们在flask的基础框架之外,新建一个cypher.py的文件,里面是Neo4jToJson类(参考了利用py2neo从Neo4j数据库获取数据),这个类实现了根据前端传回数据在Neo4j里面进行检索的方法。
from py2neo import Graph
import json
import re
import random
class Neo4jToJson(object):
#接受表单查询,返回Json格式查询结果#
def __init__(self):
#初始化数据#
# 与neo4j服务器建立连接
self.graph = Graph()
self.links = []
self.nodes = []
def post(self,select_name):
# select_name是前端传过来的查询名称
# 取出所有物种节点数据
nodes_data_all = self.graph.run("MATCH (n:species) RETURN n").data()
# node名存储
nodes_list = []
for node in nodes_data_all:
nodes_list.append(node['n']['中文名'])
# 根据前端的数据,判断搜索的关键字是否在nodes_list中存在,如果存在返回相应数据,否则返回随机数据
if select_name in nodes_list:
# 获取Neo4j中相关节点数据
nodes_data = self.graph.run("MATCH (n)--(b) where n.中文名 ='" + select_name + "' return n,b").data()
links_data = self.graph.run("MATCH (n)-[r]-(b) where n.中文名 ='" + select_name + "' return r").data()
else:
# 获取Neo4j中随机某个节点数据
random_index=random.randint(0, len(nodes_list)-1)
select_name=nodes_list[random_index]
print(select_name)
links_data = self.graph.run("MATCH (n)-[r]-(b) where n.中文名 ='" + select_name + "' return r").data()
nodes_data = self.graph.run("MATCH (n)--(b) where n.中文名 ='" + select_name + "' return n,b").data()
#整理节点数据
self.get_select_nodes(nodes_data)
#整理关系数据
self.get_links(links_data)
#关系数据中source、target的值转换为nodes中对应序号index
self.convert_index(self.links,self.nodes)
# 数据格式转换
neo4j_data = {'links': self.links, 'nodes': self.nodes}
neo4j_data_json = json.dumps(neo4j_data, ensure_ascii=False).replace(u'\xa0', u'')
# 数据存入json文件
with open("static/data/result.json","w") as f:
json.dump(neo4j_data,f)
def get_links(self, links_data):
#关系数据整理#
links_data_str = str(links_data)
links = []
i = 1
dict = {}
# 正则匹配
links_str = re.sub("[\!\%\[\]\,\。\{\}\-\:\'\(\)\>]", " ", links_data_str).split(' ')
for link in links_str:
if len(link) > 1:
if i == 1:
dict['source'] = link
elif i == 2:
dict['rel'] = link
elif i == 3:
dict['target'] = link
self.links.append(dict)
dict = {}
i = 0
i += 1
return self.links
def get_select_nodes(self, nodes_data):
#节点数据整理#
dict_node = {}
for node in nodes_data:
name = node['n']['中文名'] #cypher查询语句中的n节点
index = "_"+str(node['n'].identity) #node['n']是py2neo的Node对象,用node.identity可返回其id值,并在前面加上下划线
label = list(node['n'].labels)[0] #node.labels返回Node对象的所有标签,list()[0]返回其中第一个标签
properties = dict(node['n']) #dict(node)返回Node对象的所有属性
dict_node["id"] = index
dict_node["name"]=name
dict_node["label"]=label
dict_node["properties"]=properties
self.nodes.append(dict_node)
dict_node = {}
break
for node in nodes_data:
name = node['b']['中文名'] #cypher查询语句中的b节点
index = "_"+str(node['b'].identity)
label = list(node['b'].labels)[0]
properties = dict(node['b'])
dict_node["id"] = index
dict_node["name"]=name
dict_node["label"]=label
dict_node["properties"]=properties
self.nodes.append(dict_node)
dict_node = {}
def convert_index(self,links,nodes):
#将self.links中source和target的值(即node的id值)转换为nodes中对应node的index,使数据能用于d3.js力导向图#
id_to_index={} #存储键值对,键为id(n["id"]),值为index(i)
i=0
for n in nodes:
id_to_index[n["id"]]=i
i+=1
for link in links:
link["source"]=id_to_index[link["source"]]
link["target"]=id_to_index[link["target"]]
self.links=links
return self.links
我在参考资料(利用py2neo从Neo4j数据库获取数据)的基础上,做了几点改动:
1.如果查询字段在数据库中不存在,只返回随机某个节点及其关系数据,而不是返回全部数据;
2.用node[‘n’].identity获取了每个节点的id,这个id在Neo4j数据库中具有唯一性,links中source、target的值都使用这个id值;
3.增加了convert_index函数,将links中source、target的节点id值,替换成每个节点在nodes数组中的序号。这么做是因为,我用了d3.json()方法,将json数据自动展开为links和nodes,其中links的source、target值需要是nodes中对应的序号。(我想应该会有更简单的方法,暂时我就这么用着吧)
2.服务器调用数据
在Flask的主程序中,实例化上面的Neo4jToJson类,调用其中的post方法,将前端输入的字段传入,返回相应的查询结果
from cypher import Neo4jToJson
data_neo4j = Neo4jToJson()
name = form.name.data #这里form是扩展了FlaskForm的表单,可接受前端传入的数据
data_neo4j.post(name)
Flask中表单查询的功能我还没有实现好(总是要刷新浏览器之后才能显示新的数据),这部分代码就不放上来了。暂时还是先写到这里,有空再完善。
参考资料
《D3 4.X 数据可视化实战手册》朱启(Nick Zhu)著
《Data Visualization with Python and JavaScript》Kyran Dale
利用py2neo从Neo4j数据库获取数据
D3.js 力导向图(气泡+线条+箭头+文字)
Neo4j graph visualization using D3.js
Py2neo v4 使用笔记

若有收获,就点个赞吧
0 人点赞
