一、课堂主线:
- 语言—>形式语言—>形式语言的产生式—>编程语言—>编程语言的图灵完备性—>图灵完备的编程语言的一些常见分类方法—>对于一般命令式编程语言的整体结构—>由一般到特殊:如何重学JS
- JavaScript -> 程序文件是由字符组成的,先统一字符标准 —> 基于 ECMA-262.pdf开始学习词法,依次学习了InputElement中的whiteSpace(各种空格)、LineTerminator(换行符)、Comment(注释)以及Token中的Punctuator(符号)、Keywords(关键字)、IdentifierName(标识符)和几个基本的Literal(直接量)
二、语言:
- 自然语言(Natural Language)就是人类讲的语言,比如汉语、英语和法语。这类语言不是人为设计(虽然有人试图强加一些规则)而是自然进化的。自然语言存在不同程度的二义性。这种模糊、不确定的方式无法精确定义一门程序设计语言。
- 形式语言(Formal Language)是为了特定应用而人为设计的语言。例如数学家用的数字和运算符号、化学家用的分子式等。编程语言也是一种形式语言,是专门设计用来表达计算过程的形式语言。
三、形式语言及其表达:
如语言学中语言一样,形式语言一般有两个方面: 语法和语义。 专门研究语言的语法的数学和计算机科学分支叫做形式语言理论,它只研究语言的语法而不致力于它的语义。在形式语言理论中,形式语言是一个字母表上的某些有限长字符串的集合。一个形式语言可以包含无限多个字符串。
3.1 乔姆斯基体系
乔姆斯基体系是计算机科学中刻画形式文法表达能力的一个分类谱系,是由诺姆·乔姆斯基于1956年提出的。它包括四个层次:
- 0-型文法(无限制文法或短语结构文法)包括所有的文法。
- 等号左边不止一个
<a><b>::= "c"
- 等号左边不止一个
- 1-型文法(上下文相关文法)生成上下文相关语言。这种文法的产生式规则取如 αAβ -> αγβ 一样的形式。
"a"<b>"c"::="a""x""c"
- 2-型文法(上下文无关文法)生成上下文无关语言。这种文法的产生式规则取如 A -> γ 一样的形式。上下文无关语言为大多数程序设计语言的语法提供了理论基础。
- js, 大部分情况是上下文无关
- 3-型文法(正规文法)生成正则语言。正则语言通常用来定义检索模式或者程序设计语言中的词法结构。
正则语言类包含于上下文无关语言类,上下文无关语言类包含于上下文相关语言类,上下文相关语言类包含于递归可枚举语言类。这里的包含都是集合的真包含关系,也就是说:存在递归可枚举语言不属于上下文相关语言类,存在上下文相关语言不属于上下文无关语言类,存在上下文无关语言不属于正则语言类。
3.2 具体实现——巴科斯范式(BNF)
巴科斯范式(英语:Backus Normal Form,缩写为 BNF),又称为巴科斯-诺尔范式(英语:Backus-Naur Form,缩写同样为 BNF,也译为巴科斯-瑙尔范式、巴克斯-诺尔范式),是一种用于表示上下文无关文法的语言,上下文无关文法描述了一类形式语言。它是由约翰·巴科斯(John Backus)和彼得·诺尔(Peter Naur)首先引入的用来描述计算机语言语法的符号集。广泛地使用于程序设计语言、指令集、通信协议的语法表示中。大多数程序设计语言或者形式语义方面的教科书都采用巴科斯范式。在各种文献中还存在巴科斯范式的一些变体,如扩展巴科斯范式 EBNF 或扩充巴科斯范式 ABNF。
BNF规定是推导规则(产生式)的集合,写为:
符号 ::= <使用符号的表达式>
这里的 <符号> 是非终结符,而表达式由一个符号序列,或用指示选择的竖杠 '|' 分隔的多个符号序列构成,每个符号序列整体都是左端的符号的一种可能的替代。从未在左端出现的符号叫做终结符。
3.2.1 终结符和非终结符
- 终结符:终结符是一个形式语言的基本符号。就是说,它们能在一个形式语法的推到规则的输入或输出字符串存在,而且他们不能被分解为更小的单位。确切的说,一个语法的规则不能改变终结符。一个形式语法所推导的形式语言必须完全由终结符组成。
- 非终结符:非终结符是可以被取代的符号。一个形式文法中必须有一个起始符号,这个起始符号属于非终结符的集合。在上下文无关文法中,每个推到规则的左边只能有一个非终结符而不能有两个以上的非终结符或中介符。(并非所有的语言都可以被上下文无关文法产生)
3.2.2 BNF范式的语法
在BNF中,双引号中的字(“word”)代表着这些字符本身。而double_quote用来代表双引号。
在双引号外的字(有可能有下划线)代表着语法部分。
< > : 内包含的为必选项。[ ] : 内包含的为可选项。{ } : 内包含的为可重复0至无数次的项。| : 表示在其左右两边任选一项,相当于"OR"的意思。::= : 是“被定义为”的意思"..." : 术语符号[...] : 选项,最多出现一次{...} : 重复项,任意次数,包括 0 次(...) : 分组| : 并列选项,只能选一个
3.2.3 一个BNF范式的实践:
一个四则运算:
"a""b"<Program>: = ("a"+ | <Program> "b"+)+整数连加"+"<Number>: "0" | "1" ... "9"<Deciamal>: "0" | (("1" ~ "9") <Number>+)<Expression>: <Deciamal> ("+" <Deciamal>)+<Expression>: Deciamal | (<Expression> "+" <Deciamal>)四则运算<PrimaryExpression> = <DecimalNumber> |"(" <LogicalExpression> ")"<MultiplicativeExpression> = <PrimaryExpression> |<MultiplicativeExpression> "*" <PrimaryExpression>|<MultiplicativeExpression> "/" <PrimaryExpression><AdditiveExpression> = <MultiplicativeExpression> |<AdditiveExpression> "+" <MultiplicativeExpression>|<AdditiveExpression> "-" <MultiplicativeExpression>逻辑判断<LogicalExpression> = <AdditiveExpression> |<LogicalExpression> "||" <AdditiveExpression> |<LogicalExpression> "&&" <AdditiveExpression>
3.3 学习目标:
学习中遇到问题的时候,可以阅读ECMA-262.pdf 中关于词法、语法的权威定义。
四、系统的学习一门编程语言
4.1 图灵完备性
4.1.1 单带图灵机
图灵机(Turing Machine)是图灵在1936年发表的 “On Computable Numbers, with an Application to the Entscheidungsproblem”(《论可计算数及其在判定性问题上的应用》)中提出的数学模型。既然是数学模型,它就并非一个实体概念,而是架空的一个想法。在文章中图灵描述了它是什么,并且证明了,只要图灵机可以被实现,就可以用来解决任何可计算问题。
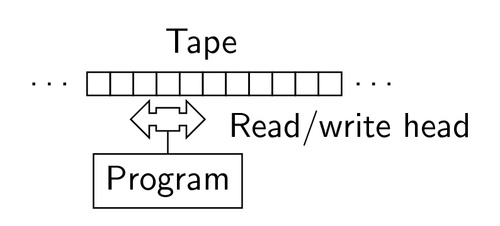
图灵机的结构包括以下几个部分:
- 一条无限长的纸带(tape),纸带被分成一个个相邻的格子(square),每个格子都可以写上至多一个字符(symbol)。
- 一个字符表(alphabet),即字符的集合,它包含纸带上可能出现的所有字符。其中包含一个特殊的空白字符(blank),意思是此格子没有任何字符。
- 一个读写头(head),可理解为指向其中一个格子的指针。它可以读取/擦除/写入当前格子的内容,此外也可以每次向左/右移动一个格子。
- 一个状态寄存器(state register),它追踪着每一步运算过程中,整个机器所处的状态(运行/终止)。当这个状态从运行变为终止,则运算结束,机器停机并交回控制权。如果你了解有限状态机,它便对应着有限状态机里的状态。
- 一个有限的指令集(instructions table),它记录着读写头在特定情况下应该执行的行为。可以想象读写头随身有一本操作指南,里面记录着很多条类似于“当你身处编号53的格子并看到其内容为0时,擦除,改写为1,并向右移一格。此外,令下一状态为运行。”这样的命令。其实某种意义上,这个指令集就对应着程序员所写下的程序了。
4.1.2 图灵机可以做什么?
在论文中,图灵所做的事是证明了,假设上述模型里所说的功能都能被以某种形式物理实现,那么任意可计算问题都可以被解决。 在计算机领域,或者说自动机领域,我们研究的一切问题都是计算问题(Computational Problem)。它泛指一切与计算相关的问题。 简而言之,对于一个问题,对于任意输入,只要人类可以保证算出结果(不管花多少时间),那么图灵机就可以保证算出结果(不管花多少时间)。
4.1.3 图灵完备
在可计算性理论里,如果一系列操作数据的规则(如指令集、编程语言、细胞自动机)可以用来模拟单带图灵机,那么它是图灵完备的。 虽然图灵机会受到储存能力的物理限制,图灵完全性通常指“具有无限存储能力的通用物理机器或编程语言”。
4.1.4 图灵完备的语言的常见实现方式
- 命令式 — 图灵机
- goto
- if while
声明式 — lambda
动态静态
- 动态:产品实际运行时,解释型,Runtime
- 静态:产品开发时,编译型,Compiletime
- 强类型弱类型
- 动态类型系统
- 静态类型系统
- 复合类型
- 强类型
- 弱类型
- 加入继承后

五、一般到特殊:重学JavaScript
5.1 最基础的组成——字符:Unicode
SourceCharacter ::any Unicode code point
5.1.1 相关概念
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
大概来说,Unicode 编码系统可分为编码方式和实现方式两个层次。
编码方式:
当前实际应用的统一码版本使用 16 位的编码空间。也就是每个字符占用 2 个字节。这样理论上一共最多可以表示 216(即 65536)个字符。基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这 16 位编码,而是保留了大量空间以作为特殊使用或将来扩展。 上述 16 位统一码字符构成基本多文种平面(Basic Multilingual Plane,简写 BMP。又称为“零号平面”、plane 0)。 基本多文种平面的字符的编码为 U+hhhh,其中每个 h 代表一个十六进制数字,与 UCS-2 编码完全相同。而其对应的 4 字节 UCS-4 编码后两个字节一致,前两个字节则所有位均为 0。 最新(但未实际广泛使用)的统一码版本定义了 16 个辅助平面,两者合起来至少需要占据 21 位的编码空间,比 3 字节略少。但事实上辅助平面字符仍然占用 4 字节编码空间,与 UCS-4 保持一致。在 Unicode 3.0 里使用“
U-”然后紧接着八个数字,而“U+”则必须随后紧接着四个数字。
实现方式:
Unicode 的实现方式不同于编码方式。一个字符的 Unicode 编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。Unicode 的实现方式称为 Unicode转换格式(Unicode Transformation Format,简称为 UTF)。 例如,如果一个仅包含基本 7 位 ASCII 字符的 Unicode 文件,如果每个字符都使用 2 字节的原 Unicode 编码传输,其第一字节的 8 位始终为 0。这就造成了比较大的浪费。对于这种情况,可以使用 UTF-8 编码,这是一种变长编码,它将基本 7 位 ASCII 字符仍用 7 位编码表示,占用一个字节(首位补 0)。而遇到与其他 Unicode 字符混合的情况,将按一定算法转换,每个字符使用 1-3 个字节编码,并利用首位为 0 或 1 进行识别。这样对以7位ASCII字符为主的西文文档就大幅节省了编码长度。类似的,对未来会出现的需要 4 个字节的辅助平面字符和其他 UCS-4 扩充字符,2 字节编码的 UTF-16 也需要通过一定的算法进行转换。
5.1.2 与通用字符集(USC)的关系
通用字符集(英语:Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。 历史上存在两个独立的尝试创立单一字符集的组织,即
- 国际标准化组织(ISO)于1984年创建的ISO/IEC
- 由Xerox、Apple等软件制造商于1988年组成的统一码联盟。
前者开发的ISO/IEC 10646项目,后者开发的统一码项目。因此最初制定了不同的标准。 统一码联盟公布的Unicode标准包含了ISO/IEC 10646-1实现级别3的基本多文种平面。在两个标准里,所有的字符都在相同的位置并且有相同的名字。
结论,对于一般用户使用者来说,可简单的理解为标准化组织和巨头软件公司之间在同一件事情上分别做了一个标准,后来相互兼容,但是叫两个不同的名字。大家都开心。
5.1.3 常用名词:
CJK:中日韩越统一表意文字(英语:CJKV Unified Ideographs),旧称中日韩统一表意文字(英语:CJKUnified Ideographs),也称统一汉字(英语:Unihan),目的是要把分别来自中文、日文、韩文、越文、壮文中,对于相同起源、本义相同、形状一样或稍异的表意文字,应赋予其在ISO 10646及统一码标准中有相同编码。此计划原本只包含中文、日文及韩文中所使用的汉字,是以旧称中日韩统一表意文字(CJK)。后来,此计划加入了越文的喃字,所以合称中日韩越统一表意文字(CJKV) 区域:
- 1993年5月,正式制订了最初的中日韩统一表意文字,位于U+4E00–U+9FFF 这个区域,共20,902 个字。一个月后,制订了统一码1.1 。
- 1999年,依据 ISO/IEC10646 的第17 个修正案(Amendment17)订定了扩充区 A ,于U+3400–U+4DFF 加入了6,582 个字。
- 2001年,依据 ISO/IEC10646-2,新增了扩充区B ,有 42,711 字。位于U+20000–U+2A6FF。但因在短时间内增加了大量的汉字,导致产生了许多重复的字形。
- 2005年,依据 ISO/IEC10646:2003 的第1 个修正案(Amendment1),基本多文种平面增加了 U+9FA6 到 U+9FBB 等 22 个汉字。
- 2009年,统一码 5.2 扩充区 C 增加了U+2A700-U+2B734 和U+9FC4~U+9FCB。
- 2010年,统一码 6.0 扩充区 D 增加了U+2B740-U+2B81F 。
- 2012年,1字增加 U+9FCC 。
因为有大量的增补区,所以单纯依靠判断是否在U+3400–U+9FFF 这个连续区域内验证是否为中文可能会有遗漏。更多的可以去查看Unicode字符平面映射或者Unicode Blocks。
5.1.4 最佳实践:
历史:ASCII
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte)。一个字节能表示的最大的整数就是255(2^8-1=255),而ASCII编码,占用0 - 127用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
最早的编码方案是ASCII,所以后来的各种编码方案都会兼容,为了避免各种编码问题带来的Bug,建议平时写代码的时候,使用ASCII码中的字符来编辑代码,需要使用ASCII之外的字符的时候,使用/u转义来完成。
5.2 Atom:InputElement
5.2.2 Whitespace 空格
可查阅 unicode space列表
- Tab:制表符(打字机时代:制表时隔开数字很方便)
- VT:纵向制表符
- FF: FormFeed
- SP: Space
- NBSP: NO-BREAK SPACE(和 SP 的区别在于不会断开、不会合并)
- …
5.2.2 LineTerminator 换行符
- LF: Line Feed
\n - CR: Carriage Return
\r - …
5.2.3 Comment 注释
- / ……/ 里面不能嵌套*/
5.2.4 Token 记号:一切有用的东西
- Punctuator: 符号 比如
> = < } - Keywords:比如
await、break… 不能用作变量名,但像 getter 里的get就是个例外- Future reserved Keywords:
eum
- Future reserved Keywords:
- IdentifierName:标识符,可以以字母、_ 或者 $ 开头,代码中用来标识变量、函数、或属性的字符序列
- 变量名:不能用 Keywords
- 属性:可以用 Keywords
- Literal: 直接量
- Number
- 存储 Uint8Array、Float64Array
- 各种进制的写法
- 二进制0b
- 八进制0o
- 十进制0x
- 实践
- 使用无穷小比较浮点是否相等:Math.abs(0.1 + 0.2 - 0.3) <= Number.EPSILON
- 如何快捷查看一个数字的二进制:(97).toString(2)
- String
- Character
- Code Point
- Number
可用 String.fromCharCode(num) '\t'.codePointAt() 进行打印,例如:"厉".codePointAt(0).toString(16)
- Encoding- unicode编码 - utf- utf-8 可变长度 (控制位的用处)- Grammar- `''`、`""`、``` `
- Boolean
- Null
- Undefind
参考资料:

若有收获,就点个赞吧
0 人点赞
