需从3个维度来考虑
Kafka如何保证高可用
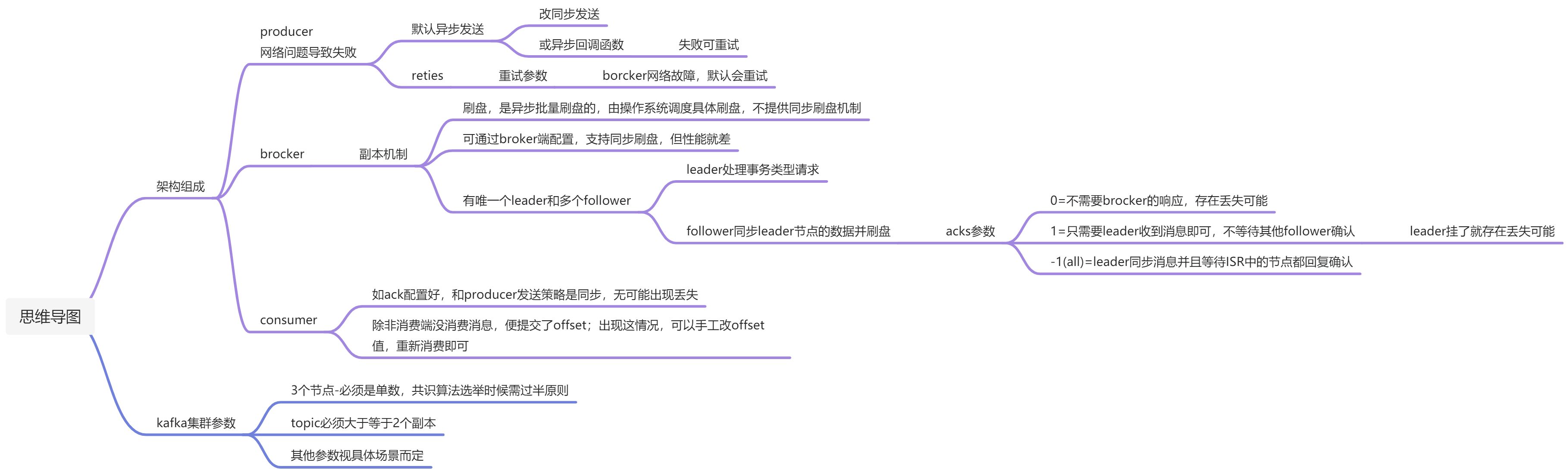
备份机制-副本机制
ISR机制
「ISR 副本集合」
这里的保持同步不是指与Leader数据保持完全一致,只需在replica.lag.time.max.ms时间内与Leader保持有效连接
各Partition的Leader负责维护ISR列表并将ISR的变更同步至ZooKeeper,被移出ISR的Follower会继续向Leader发FetchRequest请求,试图再次跟上Leader重新进入ISR
ISR中所有副本都跟上了Leader,通常只有ISR里的成员才可能被选为Leader
「Unclean领导者选举」
故障恢复机制
「Kafka从0.8版本开始引入了一套Leader选举及失败恢复机制」
首先需要在集群所有Broker中选出一个Controller,负责各Partition的Leader选举以及Replica的重新分配
- 当出现Leader故障后,Controller会将Leader/Follower的变动通知到需为此作出响应的Broker。
Kafka使用ZooKeeper存储Broker、Topic等状态数据,Kafka集群中的Controller和Broker会在ZooKeeper指定节点上注册Watcher(事件监听器),以便在特定事件触发时,由ZooKeeper将事件通知到对应Broker
Broker
「当Broker发生故障后,由Controller负责选举受影响Partition的新Leader并通知到相关Broker」
当Broker出现故障与ZooKeeper断开连接后,该Broker在ZooKeeper对应的znode会自动被删除,ZooKeeper会触发Controller注册在该节点的Watcher;
Controller
集群中的Controller也会出现故障,因此Kafka让所有Broker都在ZooKeeper的Controller节点上注册一个Watcher
Controller发生故障时对应的Controller临时节点会自动删除,此时注册在其上的Watcher会被触发,所有活着的Broker都会去竞选成为新的Controller(即创建新的Controller节点,由ZooKeeper保证只会有一个创建成功)
竞选成功者即为新的Controller
https://blog.csdn.net/u010365819/article/details/118600867 https://www.jianshu.com/p/c094820be837

若有收获,就点个赞吧
0 人点赞
