InnoDB索引实现
虽然 InnoDB 也使用 B+ 树作为索引结构,但具体实现方式却与 MyISAM 截然不同。
1.在 InnoDB 中,每一张表其实就是多个 B+ 树,即一个主键索引树和多个非主键索引树。 2.执行查询的效率,使用主键索引 > 使用非主键索引 > 不使用索引。 3.如果不使用索引进行查询,则从主索引 B+ 树的叶子节点进行遍历
第一个重大区别是 InnoDB 的数据文件本身就是索引文件。
在 InnoDB 中,表数据文件本身就是按 B+ 树组织的一个索引结构,这棵树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
另外,第二个与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。
对于聚簇索引存储来说,行数据和主键 B+ 树存储在一起,辅助索引只存储辅助键和主键,主键和非主键 B+ 树几乎是两种类型的树。
对于非聚簇索引存储来说,主键 B+ 树在叶子节点存储指向真正数据行的指针,而非主键。
为了更形象说明这两种索引的区别,我们假想一个表如下图存储了 4 行数据。其中 Id 作为主索引,Name 作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。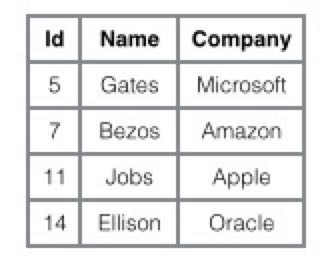
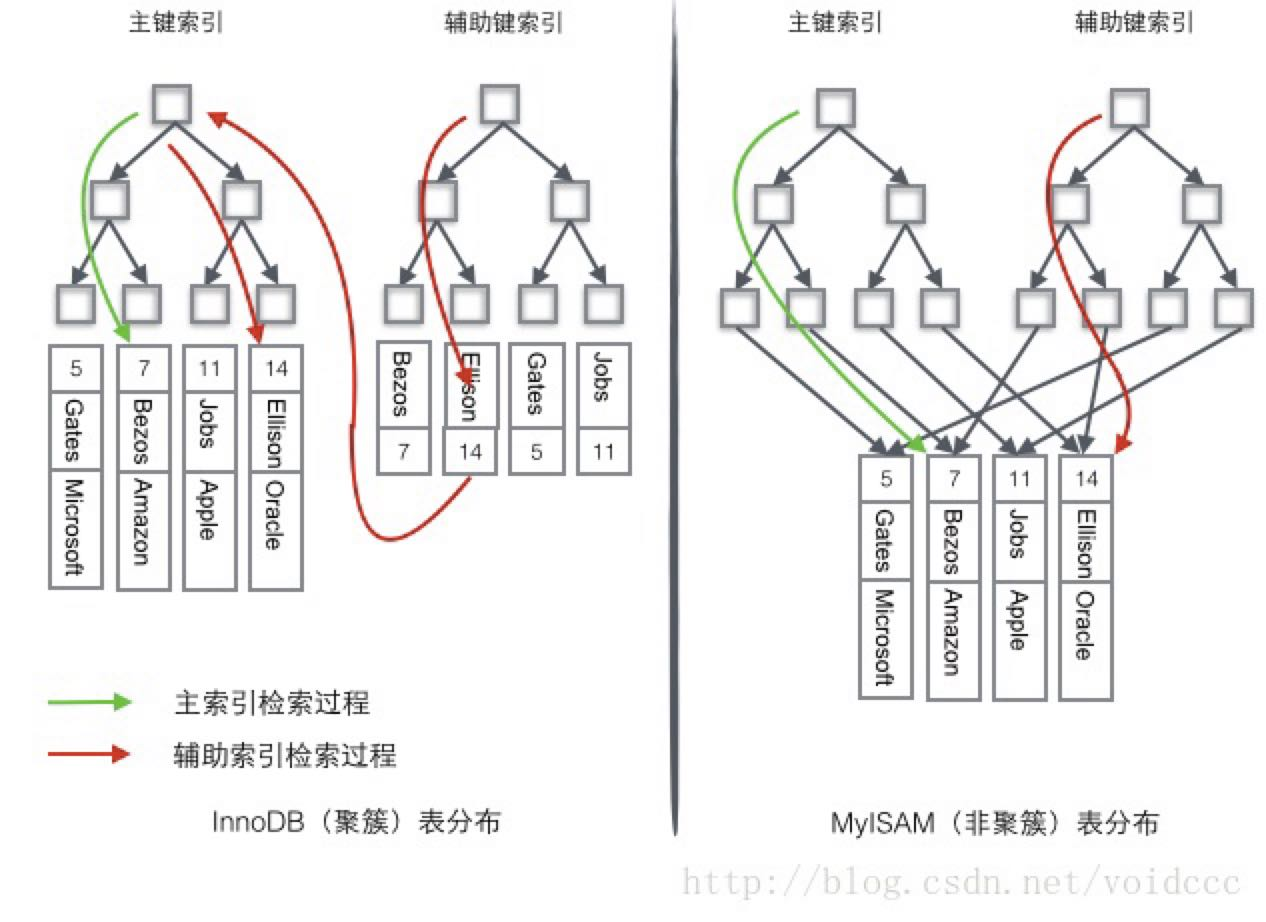
对于聚簇索引,若使用主键索引进行查询,where id = 14 这样的条件查找主键,则按照 B+ 树的检索算法即可查找到对应的叶节点,之后获得行数据。
若使用辅助索引进行查询,对 Name 列进行条件搜索,则需要两个步骤:
1、第一步在辅助索引 B+ 树中检索 Name,到达其叶子节点获取对应的主键。2、第二步根据主键在主索引 B+ 树种再执行一次 B+ 树检索操作,最终到达叶子节点即可获取整行数据。这个过程称为回表。
关于 InnoDB 的表结构:1.在 InnoDB 中,每一张表其实就是多个 B+ 树,即一个主键索引树和多个非主键索引树。 2.执行查询的效率,使用主键索引 > 使用非主键索引 > 不使用索引。 3.如果不使用索引进行查询,则从主索引 B+ 树的叶子节点进行遍历。
聚簇索引的优势在哪?
1、由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键 Id 来组织数据,获得数据更快。
2、辅助索引使用主键作为指针而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作。
使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是 InnoDB 在移动行时无须更新辅助索引中的这个指针。
也就是说行的位置会随着数据库里数据的修改而发生变化,使用聚簇索引就可以保证不管这个主键 B+ 树的节点如何变化,辅助索引树都不受影响。
引题:
执行一条 select * from T where k between 3 and 5 执行几次搜索操作。
建表
create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT ‘’,
index k(k))
engine=InnoDB;
insert into T values(100,1, ‘aa’),(200,2,’bb’),(300,3,’cc’),(500,5,’ee’),(600,6,’ff’),(700,7,’gg’)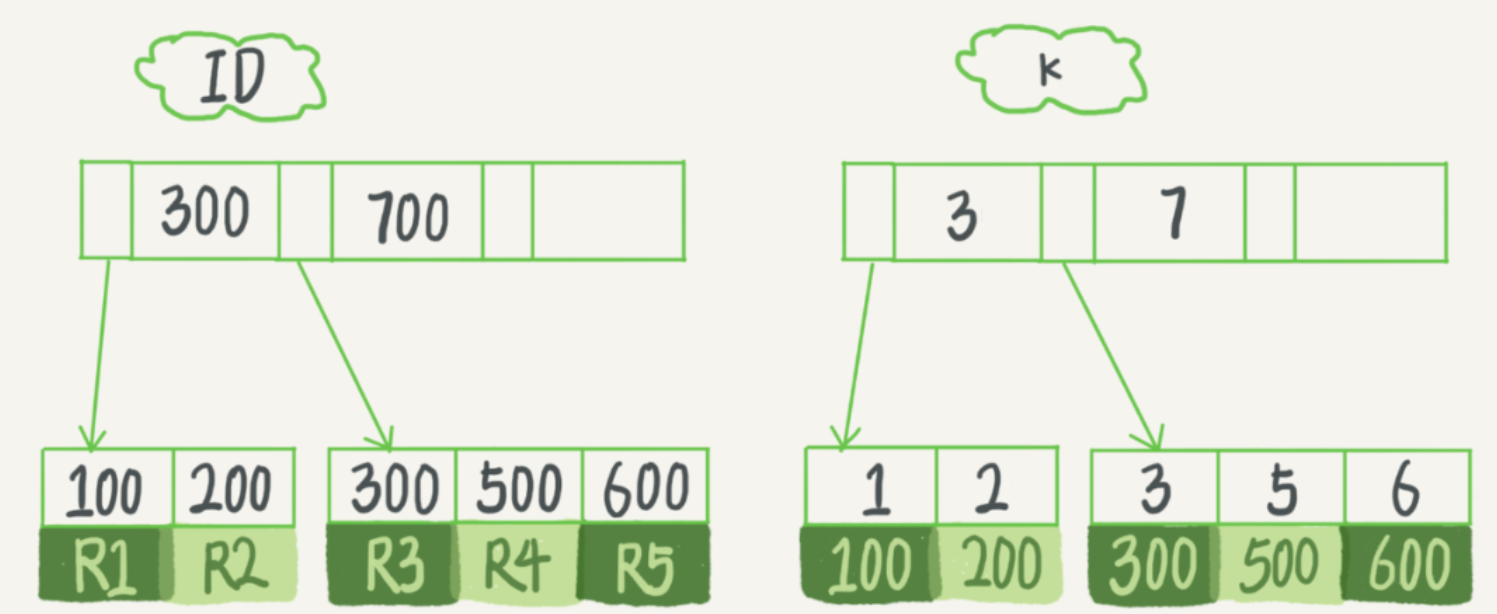
根据前面所学的知识,这条语句的执行流程为:
- 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500;
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值 k=6,不满足条件,循环结束
如何避免回表呢?
覆盖索引
在刚刚的列子中,我们可以看到,在 k 中的索引中 是有 ID 的值的。
如果我们只需要查询 ID select ID from T where k between 3 and 5 这条语句就可以很大的优化性能,因为她只需要在 k 的索引中查询并返回信息就可以了。
覆盖索引是一种非常强大的工具,能大大提高查询性能,只需要读取索引而不用读取数据有以下一些优点:
1、索引条目通常远小于数据行大小,只需要读取索引,则 MySQL 会极大地减少数据访问量。
2、因为索引是按照列值顺序存储的,所以对于 IO 密集的范围查找会比随机从磁盘读取每一行数据的 IO 少很多。
3、覆盖索引对 InnoDB 表特别有用。因为 InnoDB 的辅助索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询;
联合索引/最左匹配原则
即 索引中包含 两个及以上字段 。
它规定了 MySQL 从左到右地使用索引字段,对字段的顺序有一定要求。
另外,一个查询可以只使用索引中的一部分,更准确地说是最左侧部分(最左优先),这就是传说中的最左匹配原则。
即最左优先,如:
如果有一个 2 列的索引 (col1,col2),则相当于已经对 (col1)、(col1,col2) 上建立了索引;
如果有一个 3 列索引 (col1,col2,col3),则相当于已经对 (col1)、(col1,col2)、(col1,col2,col3) 上建立了索引;
但是 (col2,col3) 上并没有。
假定数据表有一个包含 2 列的联合索引(a, b),则索引的 B+ 树结构可能如下: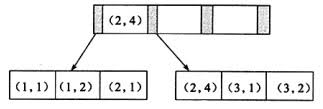
键值都是排序的,通过叶子节点可以逻辑上顺序的读出所有数据。
数据(1,1)(1,2)(2,1)(2,4)(3,1)(3,2)是按照(a,b)先比较 a 再比较 b 的顺序排列。
所以从全局看,a 是全局有序的,而 b 则不是。
基于上面的结构,对于以下查询显然是可以使用(a,b)这个联合索引的:
select from table where a=xxx and b=xxx ;
select from table where a=xxx;
但是对于下面的 sql 是不能使用这个联合索引的,因为叶子节点的 b 值,1,2,1,4,1,2 显然不是排序的。
select from table where b=xxx
*只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
注意
1、主键字段其实跟所有非主键索引建立了联合索引,只是说如果主键字段没有在联合索引中明确声明,只会在其他索引中处于最右边;
2、最左前缀匹配原则,MySQL 会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
比如 a = 1 and b = 2 and c > 3 and d = 4 如果建立 (a,b,c,d) 顺序的索引,d 是用不到索引的,如果建立 (a,b,d,c) 的索引,则都可以用到,(a,b,d 的顺序可以任意调整)是这样的么?。
3、= 和 in 的条件可以乱序
MySQL 的查询优化器会帮你优化成索引可以识别的形式。MySQL 查询优化器会判断纠正 SQL 语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。
为什么要使用联合索引?
1、 减少开销
“一个顶三个”。建一个联合索 引(col1,col2,col3),实际相当于建了 (col1),(col1,col2),(col1,col2,col3) 三个索引。
每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
2、 覆盖索引
对联合索引 (col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么 MySQL 可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机 IO 操作。
减少 io 操作,特别的随机 io 其实是 dba 主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
3、 效率高
索引列越多,通过索引筛选出的数据越少。
有 1000W 条数据的表,有如下sql: select col1,col2,col3 from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出 10% 的数据。
如果只有单值索引,那么通过该索引能筛选出 1000W10%=100w 条数据,然后再回表从 100w 条数据中找到符合 col2=2 and col3= 3 的数据,然后再排序,再分页;
如果是联合索引,通过索引筛选出 1000w_10% _10% 10%=1w,效率提升可想而知!
注:如果建立了索引(a,b) 而查询时不得不通过 b和a 单独查询,这时候不得不维护一个B的索引,这时候需要考虑空间原则了,a字段是比 b字段大的 ,那么在建立时就可以对B单独维护一个索引,反之,我们可以建立(b,a)联合索引,对 a 做一个单独索引
满足了最左前缀可以快速定位数据在索引中的位置,当不满足最左前缀原则的字段如何处理?
索引下推

若有收获,就点个赞吧
0 人点赞
