距离我真正写存储过程已经过去一周了。其实我是一个新手,看了《MySQL必知必会》之后就动手写了,算不得熟练,所以写此文也只是为了记录一下。
1. 存储过程
1.1 什么是存储过程?
一条或多条MySQL语句的组合,将其保存在数据库服务端以便复用,这就是存储过程。
1.2 为什么使用存储过程?
我遇到的场景是:开发过程中,后期给数据库追加字段,字段值来自同库其他表的字段值,几百条数据一条一条查出来再插进去太慢了,所以我选择用存储过程。
首先阿里规范是不让使用存储过程的,因为它:
- 调试困难。
- 可移植性差,特别是和代码比起来。
- 数据量大起来要分库分表、要扩展的时候就很无力了。
- 没有版本迭代……
这可能导致很多小伙伴学习MySQL语法的时候就直接跳过了视图、存储过程、游标、触发器等功能(说的就是我自己😂)。站在阿里从小公司到大型互联网企业的演变角度来看,它的规定绝对是有道理的。
但是我为什么还要使用呢?
- 开发库数据不重要,随便玩。
- 一个单库,数据量不大,没分库分表。
- 单纯想学习新东西和练手。
1.3 创建简单存储过程
下面是一个创建存储过程的简单样例:
CREATE PROCEDURE get_id()BEGINSELECT idFROM table_a;END;
- 在上例中,使用
create procedure创建了一个名为get_id的无参存储过程。 - 存储过程中具体要执行的MySQL语句写在begin和end之间,可以写多条。
- 每条语句依旧用英文分号“;”隔开,end后也要加分号。
1.4 分隔符和删除存储过程
你把上面给出的代码拿到navicat或者sqlyog中应该八成会报语法错误。没错,我故意的😜。并不是因为你的table_a不存在,而是因为分隔符“;”把语句拆开了,无法被正确解析。
这个时候要改变分隔符,语法就是delimiter //,除“\”符号外,任何字符都可以用作新的分隔符。
不管刚刚是否创建成功,我们都把刚刚创建的存储过程删除一遍重新建。删除语法如下:
-- 如果不存在会报错(不推荐用)drop procedure get_id;-- 如果不存在不会报错(推荐使用)drop procedure if exists get_id;
1.5 执行存储过程
现在重新创建,创建前后记得改变分隔符。表名和列名不存在虽然不会错,但是后面执行会报错,所以记得改你的表名和列名。
drop procedure if exists get_id;delimiter //create procedure get_id()beginselect idfrom table_a;end//delimiter ;
接下来使用call就可以直接使用这个存储过程了,call后跟存储过程名和括号,括号里面给存储过程需要的参数,如果没有参数可以省略。样例如下:
call get_id();
1.6 参数
考虑如下表:
CREATE TABLE `user` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键id',`username` varchar(32) NOT NULL COMMENT '用户名称',`age` int NOT NULL DEFAULT '10' COMMENT '年龄',PRIMARY KEY (`id`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户表';
引用《MySQL必知必会》的原文:
一般,存储过程并不显示结果,而是把结果返回给你指定的变量。 变量(variable):内存中一个特定的位置,用来临时存储数据。 变量名:所有MySQL变量都必须以@开始。
给出如下存储过程:
drop procedure if exists get_uname;delimiter //create procedure get_uname(in uid bigint,out uname varchar(32))beginselect idinto uidfrom `user`where username = uname;end//delimiter ;
该存储过程接收两个参数,传给存储过程的变量uid,从存储过程传出去的变量uname。
- MySQL支持的关键字:
- IN:传递给存储过程。
- OUT:从存储过程传出。
- INOUT:对存储过程传入和传出。
- 每个参数都必须指明类型:
- 就像给出的示例一样,uid除了要指明是in还是out外,还要给出列的数据类型。
- 通过into保存到变量中。
- 不允许用一个参数返回多行多列的记录集,只能使用多个参数返回多个列。
下面是使用该存储过程:
call get_uname(1, @uname);select @uname;
call调用该过程, 并把id=1对应的记录的username值保存到@uname变量中,然后select @uname显示查出的结果,如下图: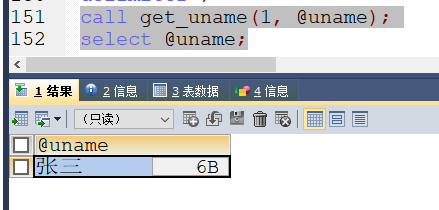
要获得多个列值,只需要都select出来就好了,变量之间用英文逗号分隔。
2. 游标
2.1 什么是游标?
书中原话:
游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。 不像多数DBMS,MySQL游标只能用于存储过程(和函数)。
感觉说了和没说一样,抓重点,MySQL游标是结果集且仅能用于存储过程。
2.2 使用游标步骤和注意点
在使用游标的步骤:
- 在能够使用游标前,必须声明(定义)它。这个过程实际上没有检索数据,只是定义要使用的select语句。
- 声明游标后,必须打开游标才能使用。这个过程才执行前面的select语句进行检索。
- 对于填有数据的游标,根据需要检索各行。
- 结束游标使用时,必须关闭游标。
有几个注意点:
- 声明游标后,可以根据需要频繁打开和关闭游标。
- 游标关闭后,必须重新打开才能使用它,但是不需要重新声明它。
- 如果你不明确关闭游标,MySQL会在达到END语句时自动关闭它。
2.3 创建游标
给出如下存储过程:
drop procedure if exists get_results;delimiter //create procedure get_results(out uname varchar(32),out uage int)-- (1)这里用来写注释comment 'comment 用来写注释'begin-- (2)定义局部变量declare uid bigint;declare local_uname varchar(32);declare local_uage int;-- (3)定义有默认值的局部变量declare done boolean default 0;declare rback boolean default 0;-- (4)定义游标declare results cursorforselect id, username, age from `user`;-- (5)定义继续处理句柄declare continue handler for sqlstate '02000' set done = 1;declare continue handler for sqlexception set rback = 1;-- (6)创建新表,用以返回结果集drop table if exists temp_table;create table if not exists temp_table(username varchar(32), age int);-- (7)打开游标open results;-- (8.1)定义重复处理部分label: repeat-- (9)获取游标数据并插入给三个局部变量fetch results into uid, local_uname, local_uage;-- (10.1)关闭自动提交并开启事务set autocommit = 0;start transaction;insert into temp_table(username, age)values(local_uname, local_uage);if (rback) thenrollback;leave label;elsecommit;end if;set autocommit = 1;-- (10.2)事务结束-- (11.1)if语句开始if (uid = 1) thenselect local_uname into uname;elseif (uid = 5) thenselect local_uage into uage;alter table temp_table change username new_username varchar(32);-- (11.2)if语句结束end if;-- (8.2)重复处理结束until done end repeat label;-- (12)关闭游标close results;end//delimiter ;
没有给出注释的地方都是前文讲过的了,接下来主要讲讲注释部分(序号对应):
- 给这个存储过程添加注释,就像建表时一样。使用
show procedure status like 'get_results';语句可以看到指定存储过程的详细信息。 - 定义局部变量。
- declare关键字可以定义局部变量、游标、句柄等。
- 定义三者的先后顺序是:局部变量 》游标 》句柄,不遵循会报错。
- 定义有默认值的局部变量。配合下面的句柄进行流程控制和事务控制。
- 定义游标。语法:
declare 游标名 cursor for select语句。不会立刻执行select语句。 - 定义句柄。这里定义了两个继续处理句柄,它是在条件出现时被执行的代码。
- 当
sqlstate '02000'出现时,就set done = 1。sqlstate '02000'是一个未找到条件,当repeat由于没有更多行供循环而不能继续时,出现这个条件。 - 当
sqlexception出现时,就set rback = 1。 SQLEXCEPTION:不以“00”、“01”或“02”开头的 SQLSTATE 值类的简写,出现异常时出现这个条件。 - 关于句柄给出官方文档链接:https://dev.mysql.com/doc/refman/8.0/en/declare-handler.html
- 当
- 创建新表,用以返回结果集。存储过程中可以创建表。
- 打开游标,会执行定义游标时的语句,得到结果集。
定义重复处理部分。语法规则:
[begin_label:] REPEAT statement_list UNTIL search_condition END REPEAT [end_label]- repeat语句中的语句列表会重复,直到search_condition表达式为真。因此, 一个REPEAT总是至少进入循环一次。 statement_list由一个或多个语句组成,每个语句以分号 ( ;) 语句分隔符结束。
- REPEAT官方文档地址:https://dev.mysql.com/doc/refman/8.0/en/repeat.html
- 开始标签后必跟冒号。
- 开始标签可以不给结束标签,但是如果结束标签存在,必与开始标签同名。
- 标签最长可达16个字符
- LABEL官方文档地址:https://dev.mysql.com/doc/refman/8.0/en/statement-labels.html
- 获取游标数据。使用fetch获取游标时,游标必须被open打开。
- 这里是事务。
- 关闭自动提交。
- 开启事务。
- 插入表,执行一组增删改操作。
- 执行成功提交事务,执行失败回滚事务。这里回滚时会退出循环标签。
- 开启自动提交。
- if语句。if语句支持elseif和else子句,前者使用then子句,后者不使用。这里都给出了样例。
- 关闭游标,推荐手动关闭释放资源,即使不关闭到END语句也会自动关闭。
2.4 使用游标
给出例子数据库数据如下: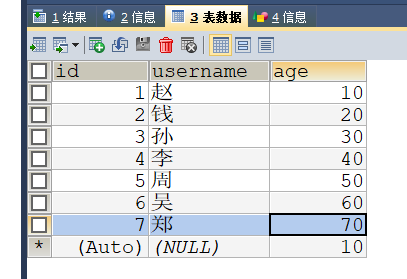
使用如下语句调用存储过程、获取参数值、查看临时表的数据。
-- 调用存储过程
call get_results(@uname, @uage);
-- 查看参数值
select @uname, @uage;
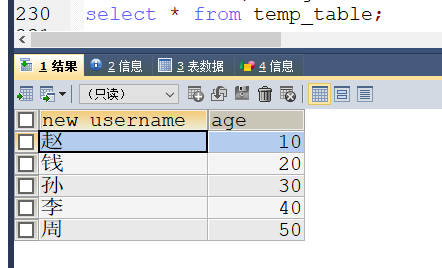
-- 查看临时表数据
select * from temp_table;
得到结果如下: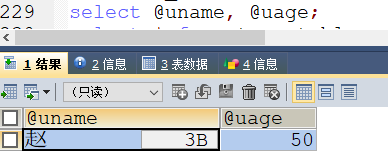
2.5 分析结果
- 调用存储过程之后再查看参数值,确实是拿到的
id=1的username和id=5的age值。 - 在
id=5时,我们改变了临时表的username字段名为new_username,接下来的id=6时的insert语句肯定出错,然后出现sqlexception,接着继续执行,但是会set rback = 1,(boolean值指定非零都为真,只有0被视为假),这时就会走回滚操作,然后退出标签,剩下的就不执行了。因此出现五条数据。 - 如果把存储过程中做如下修改,会出现7条数据,修改部分如下:
虽然是七条数据,但是结果却很诡异,参数的值还是和上面一样,但是临时表数据:if (rback) then rollback; -- leave label;这里做了修改 alter table temp_table change new_username username varchar(32); set rback = 0; -- 不管这里是否commit结果都很诡异 -- commit; else commit; end if;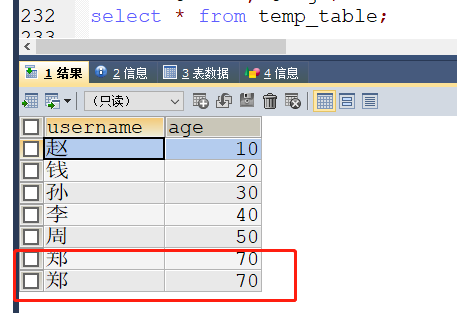
插入了两条id=7的数据,这是为什么呢?实际上是最后一条数据总是会被插入两次,可是书上给的例子写法也差不多,却不会插入两次最后一条数据,难道是mysql8.0.27版本的问题?
2.6 思考与讨论
如果是你来建立这个事务,你会选择把整个repeat部分都包起来做长事务呢?还是像我这样用短事务?为什么?
3. 使用心得
- 合理利用参数,避免联表查询操作。
- 先尝试分别写出多个单条sql,保证每条都正确。然后逐渐利用变量和参数代替,最后进行组装。
- 对于单个库下面的几张表有用,不同的库不能用存储过程。
- 日常开发写业务代码千万别用存储过程,真的没有可移植性和可扩展性。

若有收获,就点个赞吧
0 人点赞
