1 开发模式
1.1前后端不分离
前端页面由后台服务提供,例如之前写的render、redirect返回html都是前后端不分离的项目
之前写的图书管理系统、学员管理系统、公司员工管理系统都是前后端不分离项目
1.2前后端分离
应用场景(需求):当一个公司既要开发一个网页端系统,又要开发一个手机app的时候,如果前后端不分离,需要后端服务写两套代码,而前后端分离的话可以只写一套代码用来提供数据,因为网页端和app都来自一个数据源,提高开发效率,降低成本。
前后端分离交互:
后端:返回json数据,不再写render和redirect,只写httpresponse
为前端提供url(api)
2 接口开发
2.1 以前版本
前端:
使用ajax或axios发送异步请求
后端:
url.py
urlpatterns = [path('list_dep/', list_dep),path('add_dep/', add_dep),path('del_dep/<int:dep_id>/', del_dep),path('edit_dep/<int:dep_id>/', edit_dep),]
views.py
def list_dep(request):return HttpRespose('')def add_dep(request):return HttpRespose('')def edit_dep(request, dep_id):return HttpRespose('')def del_dep(request, dep_id):return HttpRespose('')
缺点:url会随着表的增加极具增加,现在只有一个dep表 如果10张表就会有40个url
2.2 现在版本(让django程序遵循restful规范)
什么是restful规范:
是一套规则,用于前后端交互的约定,它规定了一些协议,以前增删改查需要四个接口,restful规范只需要一个接口,根据method不同,执行不同操作
restful规范还规定:数据在传输格式是json格式
建议url是:域名/api/版本号/接口地址
api接口不建议用动词
有条件的话,在url后面进行传递:域名/api/版本号/接口地址/?参数1&参数2
总结:
- 建议用https代替http,保证数据的安全
- url中添加api标识
- 在接口中体现版本
- 一般情况下对于api接口,用名词不用动词
- 如果有筛选条件的话,可以添加在url中
- 根据method不同执行不同操作
- 返回给用户状态码
- 返回值:
- GET
返回查询到的数据,列表套字典
- POST
返回新增数据
- PUT
返回更新数据
- Delete
返回空
- 操作异常时,返回错误信息
标准url:https://www.cnblogs.com/api/v1/userinfo/?page=1&category=2
还可以:https://api.cnblogs.com/v1/userinfo/?page=1&category=2(存在跨域问题)
基于FBV
urlpatterns = [path('dep/',dep)]
def dep(request):if request.method == "GET":return HttpResponse('查询')elif request.method == "POST":return HttpResponse('增加')elif request.method == "PUT":return HttpResponse('更新')elif request.method == "DELETE":return HttpResponse('删除')
基于CBV(推荐使用)—因为可以通过继承实现代码复用
urlpatterns = [path('dep/',DepView.as_view())]
class DepView(View):def get(self,request,*args,**kwargs):return HttpResponse('')def post(self,request,*args,**kwargs):return HttpResponse('')def put(self,request,*args,**kwargs):return HttpResponse('')def delete(self,request,*args,**kwargs):return HttpResponse('')
3 初识drf
drf是一个基于django开发的组件,本质是一个django的app
帮助我们在django的基础上快速搭建遵循restful规范的接口程序
功能:
- APIView
- 解析器:根据用户请求体格式不同进行数据解析,解析之后放在request.data中
- 序列化:serializers
- 渲染器:可以帮我们把json数据渲染到页面进行友好展示
3.1 drf使用
1.注册app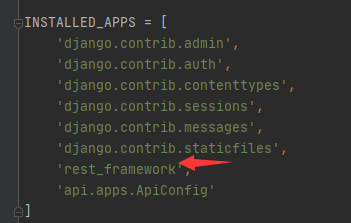
2.写路由 ```python urlpatterns = [ path(‘drf/info/‘, views.DrfInfoView.as_view()) ]
3.写视图```python#导入需要的类from rest_framework.views import APIViewfrom rest_framework.response import Responseclass DrfInfoView(APIView): # 继承APIView类"""咨询接口"""def get(self,request,*args,**kwargs):data = [{'id':1,'title':'刘学斌'},{'id':2,'title':'王淑贤'}]return Response(data) # 返回rest_framework.views的Response对象
界面如下: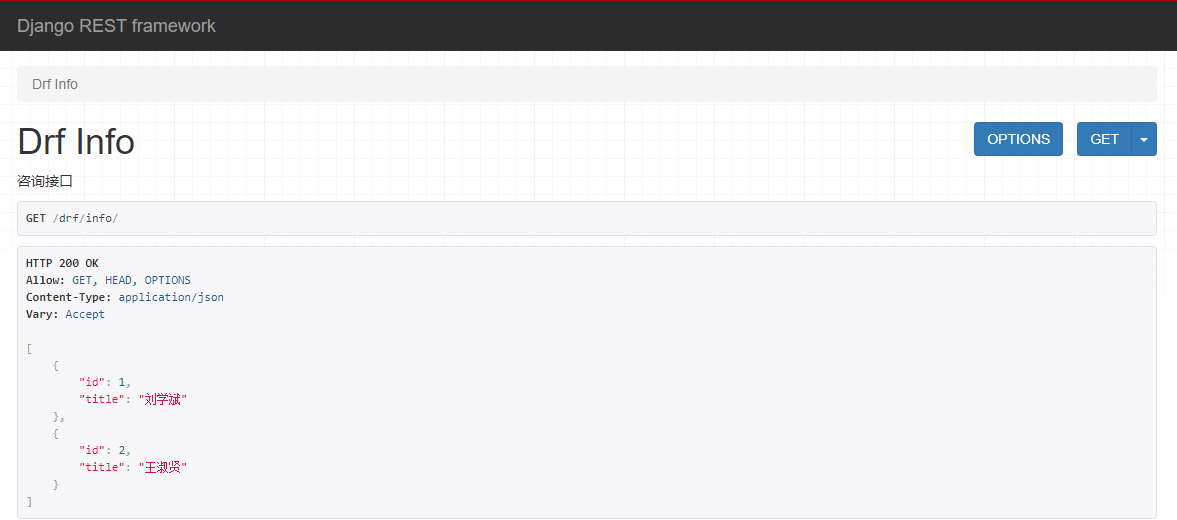
应用场景:前后端分离项目写接口时用到,用drf会很方便
4 小项目练习
4.1 创建程序并初始化数据库
1.修改相关配置
注册app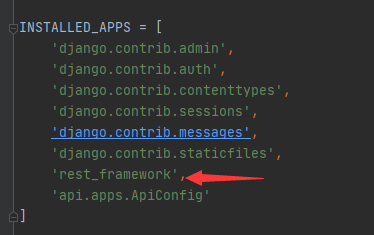
修改数据库迁移
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME':'数据库名','USER': 'root','PASSWORD': '362514','HOST': 'localhost','PORT': '3306',}}
修改init.py
import pymysqlpymysql.version_info = (1, 4, 13, "final", 0)pymysql.install_as_MySQLdb() # 使用pymysql代替mysqldb连接数据库
2.写model
from django.db import modelsclass Category(models.Model):"""分类表"""name = models.CharField(verbose_name='分类',max_length=32)class Tag(models.Model):"""标签表"""title = models.CharField(verbose_name='标签名', max_length=32)class Article(models.Model):"""文章表"""choices_status = ((1, '发布'),(2, '删除'))title = models.CharField(verbose_name='标题',max_length=32)summary = models.CharField(verbose_name='简介',max_length=255)content = models.TextField(verbose_name='文章内容')category = models.ForeignKey(to=Category,verbose_name='分类',on_delete=models.CASCADE)status = models.IntegerField(verbose_name='状态', choices=choices_status, default=1)tag = models.ManyToManyField(verbose_name='标签名', to=Tag)
3.写路由
from django.contrib import adminfrom django.urls import pathfrom huolala import viewsurlpatterns = [path('drf/category/', views.DrfCategoryView.as_view())]
4.写视图
from rest_framework.views import APIViewfrom rest_framework.response import Responseclass DrfCategoryView(APIView):pass
5.数据库迁移
4.2 接口开发
开发完毕之后告诉前端:
http://127.0.0.1:8000/drf/category/
因为在公司你不可能自己开发一个前端页面去做测试,也不可能让前端开发者去测试你的功能,因为你可能需要测试好几十遍,前端开发者不可能浪费时间给你测试,所以需要自己去测试
所以要用工具模拟浏览器发请求:postman
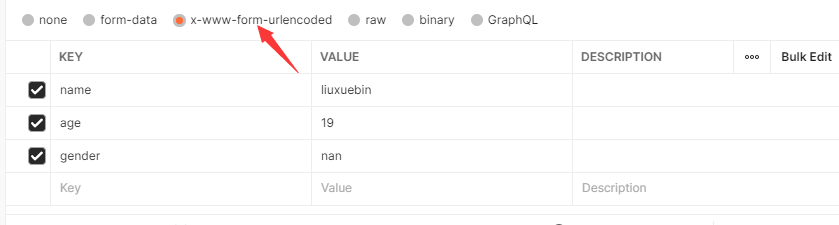
如果以上述格式发送请求体,后端拿到的原始数据是
request.body :b’name=liuxuebin&age=19&gender=nan’
request.POST :
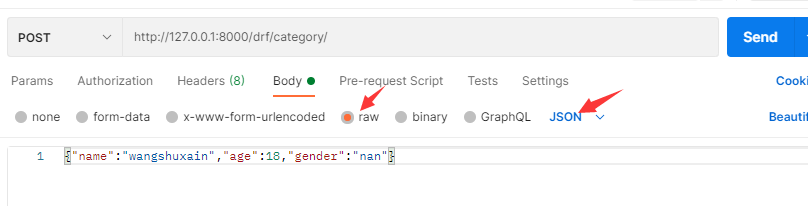
如果以上述原生JSON数据格式发送数据,后端拿到的是
request.body :b’{“name”:”wangshuxain”,”age”:18,”gender”:”nan”}’
request.POST :
现在大多数前端发的都是JSON格式数据
后端接收到的是字节类型数据,要转化成字典,首先要转化成字符串,然后用json.loads转化成字典
python中字节类型、字符串类型也就是json数据格式的字符串、字典 各自的样子:
b’{“name”:”wangshuxain”,”age”:18,”gender”:”nan”}’
{“name”:”wangshuxain”,”age”:18,”gender”:”nan”}
{‘name’: ‘wangshuxain’, ‘age’: 18, ‘gender’: ‘nan’}
但是request.data(drf提供的data属性)是字典类型,内部原理就是
s = reqeust.body.decode('utf-8')request.data = json.loads(s)
4.2.1 向分类列表增加一条记录
1.前端发请求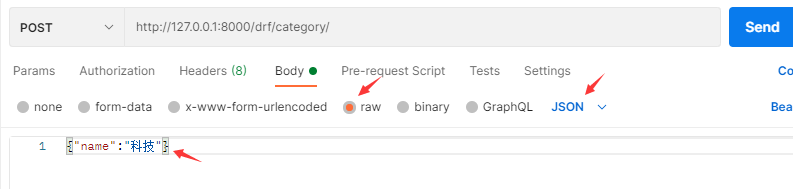
2.写视图
from rest_framework.views import APIViewfrom rest_framework.response import Responsefrom huolala import modelsimport jsonclass DrfCategoryView(APIView):"""对category表进行增删改查的接口"""def post(self,request,*args,**kwargs):"""增加一条分类记录:param request: 接受前端请求:param args: 接受前端参数:param kwargs: 接受前端参数:return:"""# request.data是字典类型{‘name’:'...'}models.Category.objects.create(**request.data)return Response('成功')
4.2.2 查询分类列表全部记录
def get(self,request,*args,**kwargs):"""获取所有文章分类列表:param request::param args::param kwargs::return:"""quertyset = models.Category.objects.all().values('id','name')return Response(quertyset)
因为Response内部要进行序列化,传递的是Category对象是不能被序列化的,所以用values转化成字典,再放入到Response中会序列化之后变成JSON对象(本质是字符串只不过是JSON数据格式)返回给前端
4.2.3 查询分类列表中的一条记录
1.修改url
urlpatterns = [path('drf/category/', views.DrfCategoryView.as_view()),path('drf/category/<int:id>/', views.DrfCategoryView.as_view())]
2.修改视图
def get(self,request,id=False,*args,**kwargs):"""获取 所有分类列表记录/单个记录:param request::param args::param kwargs::return:"""if not id:quertyset = models.Category.objects.all().values('id', 'name')return Response(quertyset)category_object = models.Category.objects.filter(id=id).first()data = model_to_dict(category_object) # Category对象直接转化成字典return Response(data)
4.2.4 删除和更新分类列表记录
def delete(self,request,id,*args,**kwargs):"""删除记录:param request::param id: 前台传来要删除的id:param args::param kwargs::return:"""models.Category.objects.filter(id=id).delete()return Response('删除成功')def put(self,request,id,*args,**kwargs):"""更新记录:param request::param id::param args::param kwargs::return:"""models.Category.objects.filter(id=id).update(**request.data)return Response('更新成功')
4.3 drf的序列化
引入serializers模块之后的增删改查
功能:
- 数据校验
- 序列化
4.3.1 单表的增删改查
serializer.py ```python from rest_framework import serializers from huolala import models
引入serializers模块之后对增删改查接口的改进
class NewCategorySerializers(serializers.ModelSerializer): “”” 对分类表进行序列化的类 “”” class Meta: model = models.Category
# 设置返回时,要显示的字段fields = ['id', 'name']
views.py```pythonfrom rest_framework.views import APIViewfrom rest_framework.response import Responseclass NewCategoryView(APIView):"""加入序列化之后改进的接口"""def get(self, request, id=False, *args, **kwargs):"""获取 所有分类列表记录/单个记录:param request::param args::param kwargs::return:"""if not id:queryset = models.Category.objects.all()# 把要序列化的queryset对象传给instance,对queryset中的category序列化成字典ser = NewCategorySerializers(instance=queryset, many=True)return Response(ser.data)category_object = models.Category.objects.filter(id=id).first()ser = NewCategorySerializers(instance=category_object, many=False)return Response(ser.data)def post(self,request,*args,**kwargs):ser = NewCategorySerializers(data=request.data)if ser.is_valid(): # 数据校验ser.save() # 增加数据return Response(ser.data) # 增加成功,返回增加的记录else:return Response(ser.errors) # 返回错误信息def put(self, request, id=False, *args, **kwargs):category_obj = models.Category.objects.filter(id=id).first()ser = NewCategorySerializers(instance=category_obj,data=request.data)if ser.is_valid():ser.save() # 修改成功return Response(ser.data)else:return Response(ser.errors)def delete(self,request,id=False,*args,**kwargs):models.Category.objects.filter(id=id).delete()return Response('删除成功')
小补充:
模板查找顺序:先找自己创建目录里的templates再去找INSTALLED_APPS里面注册的程序里面的templates
4.3.2 一对多的增删改查
serializer.py
class NewArticleSerializers(serializers.ModelSerializer):"""对文章表进行序列化的类"""# 把外键中name字段值显示的方法category = serializers.CharField(source='category.name')# model中choice属性显示名称的方法status = serializers.CharField(source='get_status_display')class Meta:model = models.Articlefields = ['id', 'title', 'content', 'category', 'status']
views.py
class NewArticleView(APIView):"""加入序列化之后的改进的接口"""def get(self, request, id=False, *args, **kwargs):if not id:queryset = models.Article.objects.all()ser = NewArticleSerializers(instance=queryset, many=True)return Response(ser.data)else:article_obj = models.Article.objects.filter(id=id).first()ser = NewArticleSerializers(instance=article_obj, many=False)return Response(ser.data)def post(self, request, *args, **kwargs):ser = NewArticleSerializers(data=request.data)if ser.is_valid():ser.save()return Response(ser.data)else:return Response(ser.errors)def put(self, request, id=False, *args, **kwargs):"""全部更新:提交全部字段:param request::param id::param args::param kwargs::return:"""article_obj = models.Article.objects.filter(id=id).first()ser = NewArticleSerializers(instance=article_obj, data=request.data)if ser.is_valid():ser.save()return Response(ser.data)else:return Response(ser.errors)def patch(self,request,id=False,*args,**kwargs):"""局部更新,提交部分字段:param request::param id::param args::param kwargs::return:"""article_obj = models.Article.objects.filter(id=id).first()ser = NewArticleSerializers(instance=article_obj, data=request.data, partial=True)if ser.is_valid():ser.save()return Response(ser.data)else:return Response(ser.errors)def delete(self,request,id=False,*args,**kwargs):models.Article.objects.filter(id=id).delete()return Response('删除成功')
4.3.3 多对多的增删改查
serilaizer.py
class NewTagSerializers(serializers.ModelSerializer):"""查询多对多表的序列化类"""category_name = serializers.CharField(source='category.name', required=False)tag_info = serializers.SerializerMethodField()class Meta:model = models.Articlefields = ['title', 'summary', 'category_name', 'tag_info']def get_tag_info(self,obj):return [row for row in obj.tag.all().values('id', 'title')]class FormNewTagSerializers(serializers.ModelSerializer):"""增加、更新多对多表记录的序列化类"""category_name = serializers.CharField(source='category.name', required=False)tag_info = serializers.SerializerMethodField()class Meta:model = models.Articlefields = "__all__"def get_tag_info(self,obj):# obj.tag相当于拿到article中每条记录对应的tag的id和tag的titlereturn [row for row in obj.tag.all().values('id', 'title')]
设定两个序列化器,因为展示数据和增加、更新数据字段是不一样的,展示数据可能只是一部分,而增加更新fields要设置成和模型类中属性相同,并且可能还要自己增加一些跨表属性
实际上对每个模型类序列化器不一定是只有一个,视情况而定
view.py
class NewTagView(APIView):"""多对多的增删改查"""def get(self, request, id=False, *args, **kwargs):if not id:queryset = models.Article.objects.all()ser = NewTagSerializers(instance=queryset, many=True)return Response(ser.data)else:article_obj = models.Article.objects.filter(id=id).first()ser = NewTagSerializers(instance=article_obj, many=False)return Response(ser.data)def post(self, request, *args, **kwargs):ser = FormNewTagSerializers(data=request.data)if ser.is_valid():ser.save()return Response(ser.data)else:return Response(ser.errors)def put(self, request, id=False, *args, **kwargs):article_obj = models.Article.objects.filter(id=id).first()ser = FormNewTagSerializers(instance=article_obj, data=request.data)if ser.is_valid():ser.save()return Response(ser.data)else:return Response(ser.errors)def patch(self, request, id=False, *args, **kwargs):article_obj = models.Article.objects.filter(id=id).first()ser = FormNewTagSerializers(instance=article_obj, data=request.data, partial=True)if ser.is_valid():ser.save()return Response(ser.data)else:return Response(ser.errors)def delete(self, request, id=False, *args, **kwargs):models.Article.objects.filter(id=id).first().tag.clear()return Response('删除成功')
models.Article.objects.all()拿到的记录应该是这个样子:
5 drf分页功能
5.1 基于页码
请求url:http://127.0.0.1:8000/page/article/?page=1 page是第几页
1.配置每页显示内容
setting.py
# 配置每页显示数REST_FRAMEWORK = {"PAGE_SIZE": 5}
2.serializer.py
class PageArticleSerializers(serializers.ModelSerializer):class Meta:model = models.Articlefields = "__all__"
因为paginate_queryset方法拿到的是模型对象,需要序列化,所以需要定义序列化类
3.view.py
方式1:拿到的只有数据
from rest_framework.pagination import PageNumberPaginationclass PageArticleView(APIView):def get(self, request, *args, **kwargs):queryset = models.Article.objects.all()# 分页对象page = PageNumberPagination()# 调用方法进行分页,得到的结果是分页之后的数据result = page.paginate_queryset(queryset, request, self)# 序列化ser = PageArticleSerializers(instance=result, many=True)return Response(ser.data)
方式2:数据+分页信息
from rest_framework.pagination import PageNumberPaginationclass PageArticleView(APIView):def get(self, request, *args, **kwargs):queryset = models.Article.objects.all()page = PageNumberPagination()result = page.paginate_queryset(queryset, request, self)ser = PageArticleSerializers(instance=result, many=True)return page.get_paginated_response(ser.data)
5.2 基于位置
请求url:
http://127.0.0.1:8000/page/article/?offset=0&limit=3
offset是起始位置,0代表从第一条记录
limit是取的记录个数
from rest_framework.pagination import LimitOffsetPagination # 引入需要的类class PageArticleView(APIView):def get(self, request, *args, **kwargs):queryset = models.Article.objects.all()page = PageNumberPagination()result = page.paginate_queryset(queryset, request, self)ser = PageArticleSerializers(instance=result, many=True)return page.get_paginated_response(ser.data)
6 实现呼啦圈项目
6.1 设计表结构
from django.db import modelsclass UserInfo(models.Model):"""用户表"""username = models.CharField(verbose_name='用户名', max_length=32)password = models.CharField(verbose_name='密码', max_length=32)class Article(models.Model):"""文章表""""""为什么不创建分类表,使用外键关联?因为类别是定死的,不需要创建表,用choices即可,这样查询的时候是去内存拿数据,而不是去数据库拿,提高了查询效率""""""为什么不把content当作article的属性?因为一般查询文章列表都不看content,只有点进去才显示content,如果把content当作属性,查询文章列表会因为content文字多,影响查询速度,所以单独建一个文章详情表"""category_choices = ((1, '咨询'),(2, '公司动态'),(3, '分享'),(4, '答疑'),(5, '其他'))category = models.IntegerField(verbose_name='分类', choices=category_choices)title = models.CharField(verbose_name='标题', max_length=32)summary = models.CharField(verbose_name='简介', max_length=255)date = models.DateTimeField(verbose_name='创建时间', auto_now_add=True)# 存放的只是图片路径image = models.CharField(verbose_name='图片', max_length=128)comment_count = models.IntegerField(verbose_name='评论数')read_count = models.IntegerField(verbose_name='浏览数')author = models.ForeignKey(verbose_name='作者',to=UserInfo)class ArticleDetail(models.Model):"""文章详情表"""article = models.OneToOneField(verbose_name='文章', to=Article)content = models.TextField(verbose_name='内容')class Comment(models.Model):"""用户表"""article = models.ForeignKey(verbose_name='文章', to=Article, on_delete=models.CASCADE)content = models.TextField(verbose_name='评论内容')user = models.ForeignKey(verbose_name='用户', to=UserInfo)# 自关联属性# parent = models.ForeignKey(verbose_name='回复', to='self', null=True, blank=True)
6.2 系统结构(类似于今日头条网站)
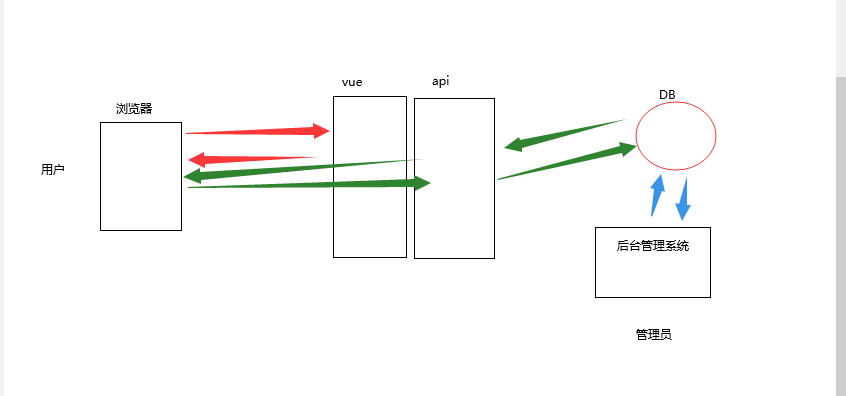
用户先通过浏览器访问url,会返回html、css、js代码,在浏览器进行渲染,当执行到发送ajax请求的代码时会向指定的api发送请求,api去连接数据库做查询拿到数据之后返回给浏览器然后渲染出来。
数据库的数据是通过后台管理系统来写入和读取的。
我们现在做的只是api部分,后台管理就不做了,通过数据库管理系统来操作数据库添加数据。
6.3 功能实现
6.3.1 增加文章
前端要发送的json数据
{"category":1,"title":"python基础","summary":"python的基础语法,开发,实践...","image":"xxx/xxx.jpg","content":"python变量、面向对象、内置方法的使用,web开发爬虫的实战......."}
前台发来的数据,会在两个表里面增加数据article和articledetail
serializer.py
class ArticleSerializer(serializers.ModelSerializer):"""文章列表序列化类"""class Meta:model = models.Article# 因为前端传来的json数据没有author所以不需要反序列化,author是通过读取session中的id获得exclude = ['author',]class ArticleDetailSerializer(serializers.ModelSerializer):"""文章详情序列化类"""class Meta:model = models.ArticleDetail# 因为前端传来的json数据没有article所以不需要反序列化,article的值是当增加一条文章记录时,获取改记录idexclude = ['article',]
增加ArticleDetailSerializer的原因:因为只有一个ArticleSerializer,反序列化之后无法得到content的值,所以增加数据的时候,只有article表增加
而article_detail表没有增加,所以需要一个反序列化content的类
6.3.2 查看文章列表/文章详细
serializer.py
class ArticleListSerializer(serializers.ModelSerializer):"""查看文章列表序列化类"""class Meta:model = models.Articlefields = "__all__"class ArticleDetailShowSerializer(serializers.ModelSerializer):"""查看文章详情序列化类"""# 对传给instance的对象做一个连表操作,source后面的赋值相当于instance引用的对象.# article.外键就可以拿到外键关联的对象# 例如这里source='author.username' 相当于article.author.username 取得username属性值author = serializers.CharField(source='author.username')category = serializers.CharField(source='get_category_display')content = serializers.CharField(source='articledetail.content')class Meta:model = models.Articlefields = ['id', 'title', 'summary', 'content','category','author']
因为文章列表和文章详情所展现的数据不同,所以用两个序列化类
view.py
class ArticleView(APIView):"""文章视图类"""def get(self, request, id=False, *args, **kwargs):"""获取文章列表/文章详细"""if not id:queryset = models.Article.objects.all().order_by('-date')# 分页对象page = PageNumberPagination()# 调用方法进行分页,得到的结果是分页之后page对应页的数据result = page.paginate_queryset(queryset, request, self)# 序列化ser = ArticleListSerializer(instance=result, many=True)return Response(ser.data)else:article_obj = models.Article.objects.filter(id=id).first()ser = ArticleDetailShowSerializer(instance=article_obj, many=False)return Response(ser.data)
6.3.3 文章评论
查看评论列表
url:http://127.0.0.1:8000/hulaquan/comment/?article=2
添加评论两种添加方式:
- article放请求体(建议用这一种)
url:http://127.0.0.1:8000/hulaquan/comment/
{"content": "这篇文章写的不错","article": 2,},
- article放url上
url:http://127.0.0.1:8000/hulaquan/comment/?article=2
{"content": "这篇文章写的不错",},
7 drf筛选
7.1 初识drf
查看文章列表,添加筛选功能:
全部:http://127.0.0.1:8000/hulaquan/article/
筛选:http://127.0.0.1:8000/hulaquan/article/?category=2
# 4-9是筛选代码,自己写的def get(self, request, id=False, *args, **kwargs):"""获取文章列表/文章详细"""if not id:condition = {}# get请求,获取url上的参数category = request.query_params.get('category')if category:condition['category'] = categoryqueryset = models.Article.objects.filter(**condition).order_by('-date')# 分页对象page = PageNumberPagination()# 调用方法进行分页,得到的结果是分页之后page对应页的数据result = page.paginate_queryset(queryset, request, self)# 序列化ser = ArticleListSerializer(instance=result, many=True)return Response(ser.data)
7.2 drf筛选组件
from rest_framework.filters import BaseFilterBackend# 运用筛选组件class MyFilterBackend(BaseFilterBackend):"""筛选组件"""def filter_queryset(self, request, queryset, view):category_id = request.query_params.get('category')queryset = queryset.filter(category=category_id)return querysetclass IndexView(APIView):def get(self,request,*args,**kwargs):queryset = models.Article.objects.all()obj = MyFilterBackend()data = obj.filter_queryset(request,queryset,self)
7.3 drf视图关系
from rest_framework.generics import GenericAPIViewfrom rest_framework.pagination import PageNumberPaginationfrom rest_framework.filters import BaseFilterBackendclass MyFilterBackend(BaseFilterBackend):"""筛选组件"""def filter_queryset(self, request, queryset, view):category_id = request.query_params.get('category')quertset = queryset.filter(category=category_id)class NewsView(GenericAPIView):queryset = models.Article.objects.all() # 查询的全部数据filter_backends = [MyFilterBackend, ] # 配置筛选serializer_class = ArticleSerializer # 配置序列化pagination_class = PageNumberPagination # 配置分页def get(self, request, *args, **kwargs):v = self.get_queryset() # 拿到的是models.Article.objects.all()的queryset对象queryset = self.filter_queryset(v) # 拿到筛选之后的结果selected_result = self.paginate_queryset(queryset) # 拿到分页结果ser = self.get_serializer(instance=selected_result, many=True) # 创建序列化对象return Response(ser.data)
如果继承GenericAPIView就要这样写,可现在有人给你写了get方法了,你只需要继承ListAPIView即可,然后只需要自定义配置信息即可
ListAPIView类源代码
class ListAPIView(mixins.ListModelMixin,GenericAPIView):"""Concrete view for listing a queryset."""def get(self, request, *args, **kwargs):return self.list(request, *args, **kwargs)
其中的list方法源代码,可以发现和自己写的get方法一样
def list(self, request, *args, **kwargs):queryset = self.filter_queryset(self.get_queryset())page = self.paginate_queryset(queryset)if page is not None:serializer = self.get_serializer(page, many=True)return self.get_paginated_response(serializer.data)serializer = self.get_serializer(queryset, many=True)return Response(serializer.data)
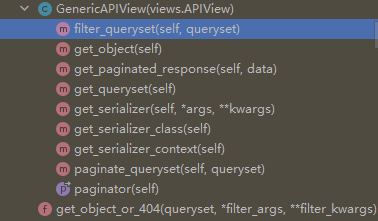
GennricAPIView里面的方法是来读取自定义配置类里面的参数的,ListAPIView,CreateAPIView,UpdateAPIView,DestroyAPIView,RetrieveAPIView是调用GennricAPIView里面的方法完成增删改查
现在用ListAPIView,CreateAPIView,UpdateAPIView,DestroyAPIView,RetrieveAPIView完成文章的增删改查
class MyFilterBackend(BaseFilterBackend):"""筛选组件"""def filter_queryset(self, request, queryset, view):category_id = request.query_params.get('category')data = queryset.filter(category=category_id)return dataclass NewArticleView(ListAPIView,CreateAPIView):"""文章接口的配置类"""queryset = models.Article.objects.all() # 查询的全部数据filter_backends = [MyFilterBackend, ] # 配置筛选serializer_class = ArticleListSerializer # 配置序列化pagination_class = PageNumberPagination # 配置分页
RetrieveAPIView和ListAPIView都有get方法所,以取单个数据会产生冲突所以把RetrieveAPIView额ListAPIView分开,对单个数据的操作的类都可以放到一起,让别的类继承他们
7.4 视图扩展
假设访问re_path(r’^index/(?P
当执行ListAPIView中list方法时,执行get_serializer内部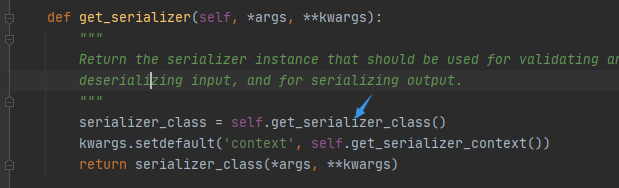
get_serializer_class执行的是NewArticleDetailView的get_serializer_class,但是如果NewArticleDetailView没有这个方法会顺着继承链向上找,最后调用的是GenericAPIView的,如果在NewArticleDetailView中定义get_serializer_class,则执行NewArticleDetailView类中的,所以现在在NewArticleDetailView类中定义get_serializer_class方法,就可以进行序列化器的选择,因为同一个接口增删改查用的序列化器不一定相同
perform_create方法和get_serializer_class原理相同
class NewArticleView(ListAPIView,CreateAPIView):"""文章接口的配置类"""queryset = models.Article.objects.all() # 查询的全部数据filter_backends = [MyFilterBackend, ] # 配置筛选# serializer_class = ArticleListSerializer # 配置序列化pagination_class = PageNumberPagination # 配置分页def get_serializer_class(self):"""可以进行序列化器的选择"""if self.request.method == "GET":return ArticleListSerializerelif self.request.method == "POST":return ArticleSerializerdef perform_create(self,serializer):"""直接从内存获取的数据,不是来自于前端的发来的post数据放在这里传递给save"""serializer.save(author_id=1)
7.5 视图关系总结
类视图执行流程:
启动django程序,执行url里面的as_view()函数,返回view,当访问对应的url时,自动执行view函数,例如访问 views.NewArticleView.as_view()
- obj = NewArticleView()
- obj.dispatch()
- obj.get()
- obj.list()
8 drf请求封装执行流程
预备知识:
class HttpRequest(object):def __init__(self):pass@propertydef GET(self):pass@propertydef POST(self):pass@propertydef body(self):oassclass Request(self):def __init__(self,request):self._request = requestdef data(self):if content-type == "application/json"return json.loads(self._request.body.decode('utf-8'))elif content-type == 'x-www-...':return self._request.POSTdef query_params(self):return self._request.GETreq = HttpRequest()request = Request(req)request.datarequest.query_paramsrequest._request.GETrequest._request.POSTrequest._request.body
drf请求流程—源码分析:
- 路由
django程序一启动,就会执行as_view(),此时请求还没来
urlpatterns = [path('article/', views.ArticleView.as_view()), # 本质:path('article/', csrf_exempt(view)),# csrf_exempt(view)调用完返回的还是view]
- 视图关系 ```python class View(object): pass class APIView(View): pass class ArticleView(APIView): pass
因为ArticleView类没有as_view()方法,回去找父类,APIView类里面有as_view()<br />APIView.as_view方法源码:(此处不重要的省略)```python@classmethoddef as_view(cls, **initkwargs):view = super().as_view(**initkwargs)return csrf_exempt(view)
会去调用父类的as_view
View.as_view方法源码:
@classonlymethoddef as_view(cls, **initkwargs):def view(request, *args, **kwargs):self = cls(**initkwargs) # cls是APIView类self.setup(request, *args, **kwargs)if not hasattr(self, 'request'):raise AttributeError("%s instance has no 'request' attribute. Did you override ""setup() and forget to call super()?" % cls.__name__)return self.dispatch(request, *args, **kwargs)return view
把view函数返回,再执行csrf_exempt(view),返回值就是view函数,所以路由后面的类本质是一个函数
然后前端发来请求,会给view加上括号,也就是进行函数调用,这里的view函数就是APIView里面的view
def view(request, *args, **kwargs):self = cls(**initkwargs)self.setup(request, *args, **kwargs)if not hasattr(self, 'request'):raise AttributeError("%s instance has no 'request' attribute. Did you override ""setup() and forget to call super()?" % cls.__name__)return self.dispatch(request, *args, **kwargs)
执行的dispatch是APIView里面的dispatch(因为ArticleView里面没有dispathch方法就去找父类的)
APIView.dispatch方法源码:
def dispatch(self, request, *args, **kwargs):# 传递进来的是老的request# 新request内部包含老request,是因为新request的里面的_request属性是老requestrequest = self.initialize_request(request, *args, **kwargs)self.request = requestself.initial(request, *args, **kwargs)# 反射,假设请求是GET,则handler = self.gethandler = getattr(self, request.method.lower())# 传入新的request,执行self.get()response = handler(request, *args, **kwargs)self.response = self.finalize_response(request, response, *args, **kwargs)return self.response
drf免除了csrf验证
9 drf版本实现
源码流程:
class APIView(View):# 默认是空的versioning_class = api_settings.DEFAULT_VERSIONING_CLASSdef dispatch(self, request, *args, **kwargs):"""request是django的request,它的内部有request.GET/request.POST/request.methodargs,kwwargs是在路由中匹配到的参数,如:re_path(r'^index/(?P<pk>\d+)/$', views.NewArticleDetailView.as_view())"""###############第一步#####################self.args = argsself.kwargs = kwargs# request = Request(# request,# parsers=self.get_parsers(),# authenticators=self.get_authenticators(),# negotiator=self.get_content_negotiator(),# parser_context=parser_context# )# 是一个新的request对象,对象内部封装了一些值request = self.initialize_request(request, *args, **kwargs)self.request = requestself.headers = self.default_response_headers # deprecate?try:################第二步#############self.initial(request, *args, **kwargs)# Get the appropriate handler method# 执行视图函数self.response = self.finalize_response(request, response, *args, **kwargs)return self.responsedef initial(self, request, *args, **kwargs):############## 2.1处理drf的版本 ################## version, scheme = v1,schemeversion, scheme = self.determine_version(request, *args, **kwargs)# request.version, request.versioning_scheme = v1,schemerequest.version, request.versioning_scheme = version, schemedef determine_version(self, request, *args, **kwargs):############2.2##################if self.versioning_class is None:return (None, None)# 实例化对象# scheme = XXXXXXXX()scheme = self.versioning_class()# 假设scheme.determine_version(request, *args, **kwargs)返回值是v1return (scheme.determine_version(request, *args, **kwargs), scheme)class ArticleView(APIView):versioning_class = XXXXXXXXXdef get(self, request, id=False, *args, **kwargs):pass
执行self.initial(request, args, **kwargs),先去ArticleView类里面找,没有就去APIView里面找
执行self.determine_version(request, args, **kwargs),先去ArticleView类里面找,没有就去APIView里面找
执行self.versioning_class ,先去ArticleView类里面找,没有就去APIView里面找
现在在ArticleView定义versioning_class,访问的就是ArticleView里面的versioning_class
测试一下上面说的
class MyView(object):def determine_version(request, *args, **kwargs):return 'v1'class OrderView(APIView):versioning_class = MyViewdef get(self,request,*args,**kwargs):print(request.version) # v1print(request.versioning_scheme)# <hulaquan.views.MyView object at 0x000001BFBFE7A048>return Response('OK')
第一种请求的url:http://127.0.0.1:8000/hulaquan/order/?version=v10
class MyView(object):def determine_version(self,request, *args, **kwargs):return request.query_params.get('version')class OrderView(APIView):versioning_class = MyViewdef get(self,request,*args,**kwargs):print(request.version) # v10print(request.versioning_scheme)# <hulaquan.views.MyView object at 0x000001BFBFE7A048>return Response('OK')
第二种请求的url:http://127.0.0.1:8000/hulaquan/order/v9/(建议第二种,restful规范要求)
re_path(r'^order/(?P<version>\w+)/$', views.OrderView.as_view())
class MyVersion(object):def determine_version(self,request, *args, **kwargs):return kwargs.get('version')class OrderView(APIView):versioning_class = MyVersiondef get(self,request,*args,**kwargs):print(request.version) # v1print(request.versioning_scheme)# <hulaquan.views.MyView object at 0x000001BFBFE7A048>return Response('OK')
对url进一步改进
一级路由
re_path(r'^api/(?P<version>\w+)/',include('hulaquan.urls'))
二级路由
path('order/', views.OrderView.as_view()),
所以访问的url符合restful规范: http://127.0.0.1:8000/api/v1/order/
现在好处是MyView这个类restframework给你写好了
from rest_framework.versioning import QueryParameterVersioning,URLPathVersioningclass OrderView(APIView):# versioning_class = QueryParameterVersioning 和第一种请求方式一样versioning_class = URLPathVersioning # 和第二种请求方式一样def get(self,request,*args,**kwargs):print(request.version) # v1print(request.versioning_scheme)# <hulaquan.views.MyView object at 0x000001BFBFE7A048>return Response('OK')
总结:局部使用版本控制
在url中写version
urlpatterns = [re_path(r'^(?P<version>[v1|v2]+)/users/$', users_list, name='users-list'),]
在视图中应用 ```python from rest_framework.versioning import QueryParameterVersioning,URLPathVersioning
class OrderView(APIView): versioning_class = URLPathVersioning # 和第二种请求方式一样 def get(self,request,args,*kwargs): print(request.version) # v1
print(request.versioning_scheme)# <hulaquan.views.MyView object at 0x000001BFBFE7A048>return Response('OK')
- 在setting中配置```pythonREST_FRAMEWORK = {"PAGE_SIZE": 2, # 配置每页显示数"ALLOWED_VERSIONS": ['v1', 'v2'], # 版本限制"ERSION_PARAM": 'version' # re_path(r'^order/(?P<version>\w+)/$' P后面<>的参数名}
局部使用也就是
class OrderView(APIView):versioning_class = URLPathVersioningdef get(self,request,*args,**kwargs):print(request.version) # v1print(request.versioning_scheme)# <hulaquan.views.MyView object at 0x000001BFBFE7A048>return Response('OK')class UserView(APIView):versioning_class = URLPathVersioningdef get(self,request,*args,**kwargs):print(request.version) # v1print(request.versioning_scheme)# <hulaquan.views.MyView object at 0x000001BFBFE7A048>return Response('OK')
每个类里都要写versioning_class
全局使用(推荐使用)
"DEFAULT_VERSIONING_CLASS": 'rest_framework.versioning.URLPathVersioning' # 全局使用版本控制
10 drf认证
本质就是用户登录之后,返回给用户token,用户之后携带token去访问某些接口,会得到访问用户得信息。
应用:如果想获取request的用户信息
from rest_framework.views import APIViewfrom rest_framework.response import Responsefrom app01 import modelsimport uuidfrom rest_framework.authentication import BaseAuthenticationclass LoginView(APIView):def post(self, request, *args, **kwargs):obj = models.UserInfo.objects.filter(**request.data).first()if not obj:return Response('登陆失败')random_str = str(uuid.uuid4())obj.token = random_strobj.save()return Response(random_str)class MyAuthentication(BaseAuthentication):"""认证类"""def authenticate(self, request):# 取url传递的tokentoken = request.query_params.get('token')# 根据token查询访问用户user_obj = models.UserInfo.objects.filter(token=token).first()if user_obj:return (user_obj,token)else:return (None,None)class UserView(APIView):# 配置认证类authentication_classes = [MyAuthentication]def get(self, request, *args, **kwargs):print(request.user) # 访问用户信息print(request.auth) # 用户携带的随机字符串if request.user:return Response('user')else:return Response('你是未登录用户,无法访问')
源码流程分析:
请求来了,执行dispatch
def dispatch(self, request, *args, **kwargs):"""request是django的request,它的内部有request.GET/request.POST/request.methodargs,kwwargs是在路由中匹配到的参数,如:re_path(r'^index/(?P<pk>\d+)/$', views.NewArticleDetailView.as_view())""""""request = Request(request,parsers=self.get_parsers(),authenticators=self.get_authenticators(),negotiator=self.get_content_negotiator(),parser_context=parser_context)是一个新的request对象,对象内部封装了一些值内部封装了_request=老的request内部封装了_authenticators = [MyAuthentication(),]"""request = self.initialize_request(request, *args, **kwargs)
initialize_request方法源码
def initialize_request(self, request, *args, **kwargs):return Request(request,parsers=self.get_parsers(),authenticators=self.get_authenticators(),# [MyAuthentication(),]negotiator=self.get_content_negotiator(),parser_context=parser_context)
返回的Request对象封装了一个authenticators属性,这个属性值就是get_authenticators的返回值,因为UserView没有get_authenticators方法,去调用APIView的get_authenticators方法
def get_authenticators(self):return [auth() for auth in self.authentication_classes]
遍历UserView的authentication_classes属性值,然后返回一个列表,是 [MyAuthentication(),]
然后传递给了Response()对象的authenticators属性
然后执行request.user的时候
def user(self)self._authenticate()return self._user
def _authenticate(self):for authenticator in self.authenticators: # [MyAuthentication(),]try:user_auth_tuple = authenticator.authenticate(self) # 调用自己定义的认证类的authenticate方法except exceptions.APIException:self._not_authenticated()raiseif user_auth_tuple is not None:self._authenticator = authenticatorself.user, self.auth = user_auth_tuplereturnself._not_authenticated()
这是局部给视图加认证,如果是全局加认证,就配置settings
REST_FRAMEWORK = {"DEFAULT_AUTHENTICATION_CLASSES":['app01.auth.MyAuthentication']}
总结 当用户请求时,找到认证的所有类并实例化称为对象列表,然后将对象列表封装到新的request中 如果以后在视图中,调用request.user 其内部会循环认证对象列表,并执行每个对象的authenticate方法,该方法用于认证,会返回两个值,两个值会分别赋值给request.user和request.auth
11 drf权限
认证和权限都可以在视图中完成,之所以需要这两个组件,是因为可以更加的分工明确,一个类对应一个功能
使用:(局部使用权限)
class MyPermission(BasePermission):"""权限类"""message = "你没有权限"code = "403" # code无法抛出def has_permission(self, request, view):if request.user:return Truereturn Falsedef has_object_permission(self, request, view, obj):"""查询单个记录会调用"""return Falseclass UserView(APIView):permission_classes = [MyPermission,]authentication_classes = [MyAuthentication,]def get(self, request, *args, **kwargs):return Response('user')
源码分析:
def dispatch(self, request, *args, **kwargs):# 封装request对象self.initial(request, *args, **kwargs)# 通过反射执行视图方法
initial方法
def initial(self, request, *args, **kwargs):############## 处理drf的版本 #################version, scheme = self.determine_version(request, *args, **kwargs)request.version, request.versioning_scheme = version, scheme##############################################self.perform_authentication(request) # 认证self.check_permissions(request) # 权限判断
执行 self.perform_authentication(request)会得到访问用户,
def check_permissions(self, request):# self.get_permissions()返回一个对象列表:[MyPermission(),]for permission in self.get_permissions():# 调用MyPermission的has_permission方法if not permission.has_permission(request, self):self.permission_denied(request,message=getattr(permission, 'message', None),code=getattr(permission, 'code', None))
def get_permissions(self):# self是UserView对象return [permission() for permission in self.permission_classes]
12 总结
drf框架执行流程及内部提供组件
- 视图
- 版本处理
- 认证
- 权限
- 节流
- 解析器
- 序列化器
- 筛选器
- 分页
- 渲染
13 跨域
由于浏览器具有”同源策略”的限制。如果在同一个域下发送ajax请求,浏览器的同源策略不会阻止,如果在不同域下发送ajax请求,浏览器的同源策略会阻止。
总结:
- 域相同,永远不会存在跨域
- 域不同时,才会存在跨域
- 域指的是端口或域名

若有收获,就点个赞吧
0 人点赞
