原生雪花算法
原生雪花算法
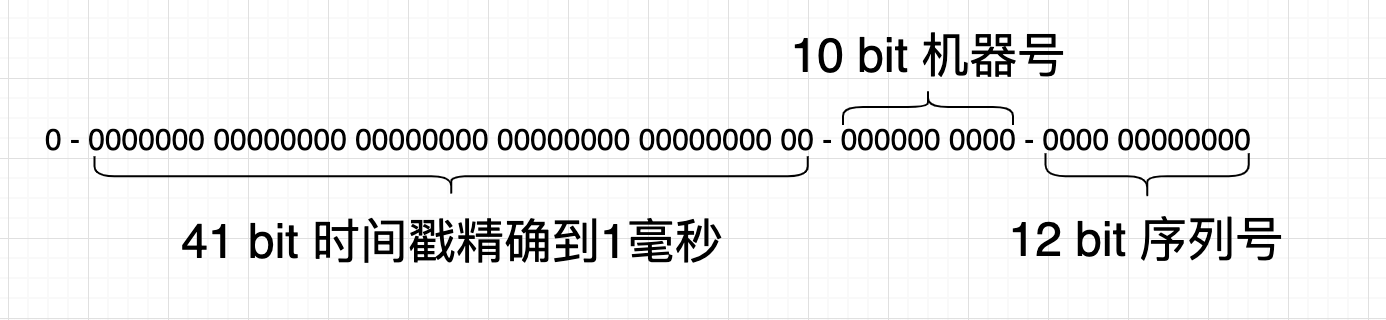
snowflake算法使用的一个64 bit的整型数据,被划分为四部分。
- 不含开头的第一个bit,因为是符号位;
- 41bit来表示收到请求时的时间戳,精确到1毫秒;也就是说最大可使用的年限是69年。
- 5bit表示数据中心的id, 5bit表示机器实例id,共计10bit的机器位,因此能部署在1024台机器节点上生成ID;
- 12bit循环自增序列号,增至最大后归0,1毫秒最大生成唯一ID的数量是4096个。
原生的**Snowflake**算法是完全依赖于时间的,如果有时钟回拨的情况发生,会生成重复的ID,市场上的解决方案也是非常多的:
时钟回拨解决方案:
- 最简单的方案,就是关闭生成唯一ID机器的时间同步。
- 使用阿里云的的时间服务器进行同步,2017年1月1日的闰秒调整,阿里云服务器NTP系统24小时“消化”闰秒,完美解决了问题。
- 如果发现有时钟回拨,时间很短比如5毫秒,就等待,然后再生成。或者就直接报错,交给业务层去处理。
- 可以找2bit位作为时钟回拨位,发现有时钟回拨就将回拨位加1,达到最大位后再从0开始进行循环。
:::
:::color2
推荐的是最后一个方案: 找2bit位作为时钟回拨位,发现有时钟回拨就将回拨位加1,达到最大位后再从0开始进行循环。如:
:::
sonyflake
Snowflake算法是相当灵活的,我们可以根据自己的业务需要,对63 bit的的各个部分进行增减。索尼公司的Sonyflake对原生的Snowflake进行改进,重新分配了各部分的bit位:
耗时的原因是时间回拨时其内部用了sleep等待;

:::color2
- 39bit 来保存时间戳,与原生的
Snowflake不同的地方是,Sonyflake是以10毫秒为单位来保存时间的。这样的话,可以使用的年限为174年 比Snowflake长太多了。 - 8bit 做为序列号,每10毫最大生成256个,1秒最多生成25600个,比原生的Snowflake少好多,如果感觉不够用,目前的解决方案是跑多个实例生成同一业务的ID来弥补。
- 16bit 做为机器号,默认的是当前机器的私有IP的最后两位。sonyflake对于snowflake的改进是用
**<font style="color:#DF2A3F;">空间换时间</font>**,时间戳位数减少,以从69年升至174年。
:::

若有收获,就点个赞吧
0 人点赞
