常用函数
数据函数
| 函数名 | 作用 | 实例 |
|---|---|---|
| ABS | 求绝对值 | SELECT ABS(-8); |
| CEILING | 向上取整 | SELECT CEILING(9.4); |
| FLOOR | 向下取整 | SELECT FLOOR(9.4); |
| RAND | 随机数,返回一个0-1之间的随机数 | SELECT RAND(); |
| SIGN | 符号函数, 负数返回-1,正数返回1,0返回0 | SELECT SIGN(0); |
字符串函数
| 函数名 | 作用 | 实例 |
|---|---|---|
| CHAR_LENGTH | 返回字符串 s 的字符数 | SELECT CHAR_LENGTH(goods_name) FROM goods |
| CONCAT(s1,s2…sn) | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 | |
| LOWER | 小写 | |
| UPPER | 大写 | |
| LEFT(s,n) | 返回字符串 s 的前 n 个字符 | |
| RIGHT(s,n) | 返回字符串 s 的后 n 个字符 | |
| SUBSTR(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 | |
| REVERSE(s) | 将字符串s的顺序反过来 | |
| REPLACE(s,s1,s2) | 将字符串 s2 替代字符串 s 中的字符串 s1 |
日期和时间函数
| 函数名 | 作用 | 实例 |
|---|---|---|
| CURRENT_DATE | 返回当前日期 | SELECT CURRENT_DATE(); |
| CURRENT_TIME | 返回当前时间 | |
| NOW() | 返回当前日期和时间 | |
| LOCALTIME() | 返回当前日期和时间 | |
| SYSDATE | 返回当前日期和时间 | |
| SELECT YEAR(NOW()); SELECT MONTH(NOW()); SELECT DAY(NOW()); SELECT HOUR(NOW()); SELECT MINUTE(NOW()); SELECT SECOND(NOW()); |
— 获取年月日,时分秒 |
| |
系统信息函数
| 函数名 | 作用 | |
|---|---|---|
| VERSION() | 返回数据库的版本号 | |
| USER | 返回当前用户 |
STR_TO_DATE(str,format); 字符转时间
select * from t_student_info where birthday = STR_TO_DATE('1990-04-05','%Y-%m-%d');
DATE_FORMAT(date,format) 时间转字符
-- 数据库的字段转字符串。select * from t_order_info where DATE_FORMAT(order_date,'%Y-%m-%d') = '2022-04-07';
聚合函数
| 函数名称 | 描述 |
|---|---|
| COUNT() | 返回满足Select条件的记录总和数,如 select count() 【不建议使用 ,效率低】 |
| SUM() | 返回数字字段或表达式列作统计,返回一列的总和。 |
| AVG() | 通常为数值字段或表达列作统计,返回一列的平均值 |
| MAX() | 可以为数值字段,字符字段或表达式列作统计,返回最大的值。 |
| MIN() | 可以为数值字段,字符字段或表达式列作统计,返回最小的值。 |
COUNT函数
SELECT COUNT(studentname) FROM student;SELECT COUNT(*) FROM student;SELECT COUNT(1) FROM student; /*推荐*/
从含义上讲,count(1) 与 count() 都表示对全部数据行的查询。
count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
count() 包括了所有的列,相当于行数,在统计结果的时候,包含字段为null 的记录;
count(1) 用1代表代码行,在统计结果的时候,包含字段为null 的记录 。
SUM函数
-- 统计所有学生分数总合SELECT SUM(StudentResult) AS 总和 FROM result;
AVG函数
--求所有学生成绩的平均分SELECT AVG(StudentResult) AS 平均分 FROM result;
MAX函数
-- 找出最高分的学生成绩SELECT MAX(StudentResult) AS 最高分 FROM result;
MIN函数
---- 找出最低分的学生成绩SELECT MIN(StudentResult) AS 最低分 FROM result;
GROUP BY
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
数据表:
例子:统计每个类别的数量
select 类别, sum(数量) as 数量之和 from 数据表
结果: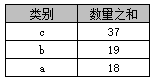
Group By 和 Order By
统计后在排序
select 类别, sum(数量) AS 数量之和from Agroup by 类别order by sum(数量) desc
Group By与聚合函数
示例:求各组平均值select 类别, avg(数量) AS 平均值 from A group by 类别;示例:求各组记录数目select 类别, count(*) AS 记录数 from A group by 类别;
Having与Where的区别
where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例select 类别, sum(数量) as 数量之和 from Agroup by 类别having sum(数量) > 18示例:Having和Where的联合使用方法select 类别, SUM(数量)from Awhere 数量 gt;8group by 类别having SUM(数量) gt; 10
索引
1、索引是什么
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构 ,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
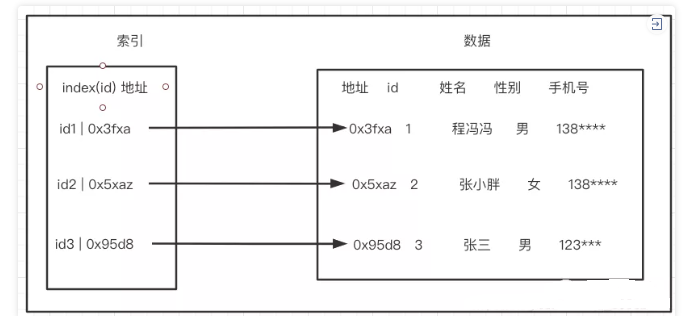
优势:可以快速检索,减少I/O次数,加快检索速度;根据索引分组和排序,可以加快分组和排序;
**劣势:**索引本身也是表,因此会占用存储空间,一般来说,索引表占用的空间的数据表的1.5倍;索引表的维护和创建需要时间成本,这个成本随着数据量增大而增大;构建索引会降低数据表的修改操作(删除,添加,修改)的效率,因为在修改数据表的同时还需要修改索引表;
1.1、什么样的字段适合创建索引
1、表的主键、外键必须有索引;外键是唯一的,而且经常会用来查询2、经常与其他表进行连接的表,在连接字段上应该建立索引;3、数据量超过300的表应该有索引;4、重要的SQL或调用频率高的SQL,比如经常出现在where子句中的字段,order by,group by, distinct的字段都要添加索引5、经常用到排序的列上,因为索引已经排序。6、经常用在范围内搜索的列上创建索引,因为索引已经排序了,其指定的范围是连续的
1.2、什么场景不适合创建索引
1、 对于那些在查询中很少使用或者参考的列不应该创建索引,这是因 为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
2、对于那 些只有很少数据值的列也不应该增加索引。因为本来结果集合就是相当于全表查询了,所以没有必要。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比 例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
3、对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
4、当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因 此,当修改性能远远大于检索性能时,不应该创建索引。
5、不会出现在where条件中的字段不该建立索引。
6、如果列均匀分布在 1 和 100 之间,却只是查询中where key_part1 > 1 and key_part1 < 90不应该增加索引
[
](https://blog.csdn.net/u012954706/article/details/81241049)
1.3、索引使用以及设计规范
1、越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂
2、尽量避免null:应该指定列为not null, 含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂,也可能导致复合索引无效
[
](https://blog.csdn.net/u012954706/article/details/81241049)
2、索引的数据结构
B+Tree索引
innodb默认索引数据结构是B+Tree,什么是B+Tree呢,它的全名叫做平衡多路查找树PLUS。他是由平衡二叉树查找树(AVL树)演化而来。我们来介绍一下他的演化史(敲黑板,必考题)。 我们上面讲到,索引是一种有序的数据结构,因为有序才能快速的进行查找,所以我们一步步看一下索引的定型演化,首先我们讲一下什么是二叉查找树。
Hash索引
Hash索引就是将索引字段进行hash存储,整个hash索引的结构是Hash表+链表(因为会存在hash冲突)。
3、MySQL中索引的语法
创建索引
在创建表的时候添加索引
CREATE TABLE mytable(ID INT NOT NULL,username VARCHAR(16) NOT NULL,INDEX [indexName] (username(length)));
在创建表以后添加索引
ALTER TABLE my_table ADD [UNIQUE] INDEX index_name(column_name);或者CREATE INDEX index_name ON my_table(column_name);
注意:
1、索引需要占用磁盘空间,因此在创建索引时要考虑到磁盘空间是否足够
2、创建索引时需要对表加锁,因此实际操作中需要在业务空闲期间进行
删除索引
DROP INDEX my_index ON tablename;或者ALTER TABLE table_name DROP INDEX index_name;
查看表中的索引
SHOW INDEX FROM tablename
查看查询语句使用索引的情况
explain SELECT * FROM table_name WHERE column_1='123';
4、索引的分类
常见的索引类型有:主键索引、唯一索引、普通索引、全文索引、组合索引
4. 1 主键索引
即主索引,根据主键pk_clolum(length)建立索引,不允许重复,不允许空值;
特点 :
- 最常见的索引类型
- 确保数据记录的唯一性
- 确定特定数据记录在数据库中的位置
ALTER TABLE 'table_name' ADD PRIMARY KEY pk_index('col');
4. 2 唯一索引
唯一索引是不允许其中任何两行具有相同索引值的索引。例如我们在性别这一列上创建索引,因为性别目前只有男女,所以我们会直接创建失败,提示我们存在重复。我们可以在身份证号、手机号等字段上进行创建。
创建唯一性索引的目的往往不是为了提高访问速度,而是为了避免数据出现重复。
创建索引CREATE UNIQUE INDEX 索引的名字 ON tablename (列的列表);修改表索引ALTER TABLE tablename ADD UNIQUE 索引的名字 (列的列表);创建表的时候指定索引CREATE TABLE tablename ( [...], UNIQUE 索引的名字 (列的列 );
4. 3 普通型索引
普通索引是最基本的索引类型,唯一任务是加快对数据的访问速度,没有任何限制。创建普通索引时,通常使用的关键字是 INDEX 或 KEY。
创建索引CREATE INDEX 索引的名字 ON tablename (列名1,列名2,...);修改表ALTER TABLE tablename ADD INDEX 索引的名字 (列名1,列名2,...);创建表的时候指定索引CREATE TABLE tablename ( [...], INDEX 索引的名字 (列名1,列名2,...) );
4.4 组合索引
复合索引也叫组合索引,指的是我们在建立索引的时候使用多个字段,例如同时使用身份证和手机号建立索引,同样的可以建立为普通索引或者是唯一索引。 复合索引的使用复合最左原则。举个例子 我们使用 phone和name创建索引。
创建索引例如 CREATE INDEX 索引的名字 ON tablename (列名1,列名2,…);修改表例如 ALTER TABLE tablename ADD INDEX 索引的名字 (列名1,列名2,…);创建表例如 CREATE TABLE tablename ( […], INDEX 索引的名字 (列名1,列名2,…) );
组合索引,联合索引 又叫复合索引
5. 索引的删除
删除索引的mysql格式 :DORP INDEX IndexName ON `TableName`
使用索引需要注意的地方

若有收获,就点个赞吧
0 人点赞
