- 一、K8S安装篇
- 2.二进制高可用安装k8s集群(生产级)
- 10.96.0.是k8s service的网段,如果说需要更改k8s service网段,那就需要更改10.96.0.1,
# 如果不是高可用集群,192.168.68.48为Master01的IP - 二、K8S基础篇
- 三、K8S进阶篇
- 创建目录
- 暴露服务
- 重启服务
- 创建 pv
- 查看pv
- 创建pvc
- 查看pvc
- 查看pv
- 创建pod
- 查看pod
- 查看pvc
- 查看pv
- 查看nfs中的文件存储
- 3.高级准入控制
- 4.细粒度权限控制
- 四、K8S高级篇
- 五、K8S运维篇
一、K8S安装篇
1.Kubeadm高可用安装k8s集群
0.网段说明
集群安装时会涉及到三个网段:
宿主机网段:就是安装k8s的服务器
Pod网段:k8s Pod的网段,相当于容器的IP
Service网段:k8s service网段,service用于集群容器通信。
一般service网段会设置为10.96.0.0/12
Pod网段会设置成10.244.0.0/12或者172.16.0.1/12
宿主机网段可能是192.168.0.0/24
需要注意的是这三个网段不能有任何交叉。
比如如果宿主机的IP是10.105.0.x
那么service网段就不能是10.96.0.0/12,因为10.96.0.0/12网段可用IP是:
10.96.0.1 ~ 10.111.255.255
所以10.105是在这个范围之内的,属于网络交叉,此时service网段需要更换,
可以更改为192.168.0.0/16网段(注意如果service网段是192.168开头的子网掩码最好不要是12,最好为16,因为子网掩码是12他的起始IP为192.160.0.1 不是192.168.0.1)。
同样的道理,技术别的网段也不能重复。可以通过http://tools.jb51.net/aideddesign/ip_net_calc/计算:
所以一般的推荐是,直接第一个开头的就不要重复,比如你的宿主机是192开头的,那么你的service可以是10.96.0.0/12.
如果你的宿主机是10开头的,就直接把service的网段改成192.168.0.0/16
如果你的宿主机是172开头的,就直接把pod网段改成192.168.0.0/12
注意搭配,均为10网段、172网段、192网段的搭配,第一个开头数字不一样就免去了网段冲突的可能性,也可以减去计算的步骤。
1.1Kubeadm基础环境配置
1.修改apt源
所有节点配置vim /etc/apt/sources.list
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
ubuntu镜像-ubuntu下载地址-ubuntu安装教程-阿里巴巴开源镜像站 (aliyun.com)
2.修改hosts文件
所有节点配置vim /etc/hosts
192.168.68.20 k8s-m01192.168.68.21 k8s-m02192.168.68.22 k8s-m03192.168.68.18 k8s-master-lb # 如果不是高可用集群,该IP为Master01的IP192.168.68.23 k8s-n01192.168.68.24 k8s-n02192.168.68.25 k8s-n03
3.关闭swap分区
所有节点配置vim /etc/fstab
临时禁用:swapoff -a永久禁用:vim /etc/fstab 注释掉swap条目,重启系统
4.时间同步
所有节点
apt install ntpdate -yrm -rf /etc/localtimeln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtimentpdate cn.ntp.org.cn# 加入到crontab -e*/5 * * * * /usr/sbin/ntpdate time2.aliyun.com# 加入到开机自动同步,vim /etc/rc.localntpdate cn.ntp.org.cn
5.配置limit
所有节点ulimit -SHn 65535vim /etc/security/limits.conf
# 末尾添加如下内容
* soft nofile 655360* hard nofile 131072* soft nproc 655350* hard nproc 655350* soft memlock unlimited* hard memlock unlimited
6.修改内核参数
cat >/etc/sysctl.conf <<EOF# Controls source route verificationnet.ipv4.conf.default.rp_filter = 1net.ipv4.ip_nonlocal_bind = 1net.ipv4.ip_forward = 1# Do not accept source routingnet.ipv4.conf.default.accept_source_route = 0# Controls the System Request debugging functionality of the kernelkernel.sysrq = 0# Controls whether core dumps will append the PID to the core filename.# Useful for debugging multi-threadedapplications. kernel.core_uses_pid = 1# Controls the use of TCP syncookiesnet.ipv4.tcp_syncookies = 1# Disable netfilter on bridges.net.bridge.bridge-nf-call-ip6tables = 0net.bridge.bridge-nf-call-iptables = 0net.bridge.bridge-nf-call-arptables = 0# Controls the default maxmimum size of a mesage queuekernel.msgmnb = 65536# # Controls the maximum size of a message, in byteskernel.msgmax = 65536# Controls the maximum shared segment size, in byteskernel.shmmax = 68719476736# # Controls the maximum number of shared memory segments, in pageskernel.shmall = 4294967296# TCP kernel paramaternet.ipv4.tcp_mem = 786432 1048576 1572864net.ipv4.tcp_rmem = 4096 87380 4194304net.ipv4.tcp_wmem = 4096 16384 4194304 net.ipv4.tcp_window_scaling = 1net.ipv4.tcp_sack = 1# socket buffernet.core.wmem_default = 8388608net.core.rmem_default = 8388608net.core.rmem_max = 16777216net.core.wmem_max = 16777216net.core.netdev_max_backlog = 262144net.core.somaxconn = 20480net.core.optmem_max = 81920# TCP connnet.ipv4.tcp_max_syn_backlog = 262144net.ipv4.tcp_syn_retries = 3net.ipv4.tcp_retries1 = 3net.ipv4.tcp_retries2 = 15# tcp conn reusenet.ipv4.tcp_timestamps = 0net.ipv4.tcp_tw_reuse = 0net.ipv4.tcp_tw_recycle = 0net.ipv4.tcp_fin_timeout = 1net.ipv4.tcp_max_tw_buckets = 20000net.ipv4.tcp_max_orphans = 3276800net.ipv4.tcp_synack_retries = 1net.ipv4.tcp_syncookies = 1# keepalive connnet.ipv4.tcp_keepalive_time = 300net.ipv4.tcp_keepalive_intvl = 30net.ipv4.tcp_keepalive_probes = 3net.ipv4.ip_local_port_range = 10001 65000# swapvm.overcommit_memory = 0vm.swappiness = 10#net.ipv4.conf.eth1.rp_filter = 0#net.ipv4.conf.lo.arp_ignore = 1#net.ipv4.conf.lo.arp_announce = 2#net.ipv4.conf.all.arp_ignore = 1#net.ipv4.conf.all.arp_announce = 2EOF
安装常用软件apt install wget jq psmisc vim net-tools telnet lvm2 git -y
所有节点安装ipvsadm
apt install ipvsadm ipset conntrack -ymodprobe -- ip_vsmodprobe -- ip_vs_rrmodprobe -- ip_vs_wrrmodprobe -- ip_vs_shmodprobe -- nf_conntrackvim /etc/modules-load.d/ipvs.conf# 加入以下内容ip_vsip_vs_lcip_vs_wlcip_vs_rrip_vs_wrrip_vs_lblcip_vs_lblcrip_vs_dhip_vs_ship_vs_foip_vs_nqip_vs_sedip_vs_ftpip_vs_shnf_conntrackip_tablesip_setxt_setipt_setipt_rpfilteript_REJECTipip
然后执行systemctl enable —now systemd-modules-load.service即可
开启一些k8s集群中必须的内核参数,所有节点配置k8s内核
cat <<EOF > /etc/sysctl.d/k8s.confnet.ipv4.ip_forward = 1net.bridge.bridge-nf-call-iptables = 1net.bridge.bridge-nf-call-ip6tables = 1fs.may_detach_mounts = 1net.ipv4.conf.all.route_localnet = 1vm.overcommit_memory=1vm.panic_on_oom=0fs.inotify.max_user_watches=89100fs.file-max=52706963fs.nr_open=52706963net.netfilter.nf_conntrack_max=2310720net.ipv4.tcp_keepalive_time = 600net.ipv4.tcp_keepalive_probes = 3net.ipv4.tcp_keepalive_intvl =15net.ipv4.tcp_max_tw_buckets = 36000net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_max_orphans = 327680net.ipv4.tcp_orphan_retries = 3net.ipv4.tcp_syncookies = 1net.ipv4.tcp_max_syn_backlog = 16384net.ipv4.ip_conntrack_max = 65536net.ipv4.tcp_max_syn_backlog = 16384net.ipv4.tcp_timestamps = 0net.core.somaxconn = 16384EOF
sysctl —system
所有节点配置完内核后,重启服务器,保证重启后内核依旧加载
reboot
查看
lsmod | grep —color=auto -e ip_vs -e nf_conntrack
8.Master01节点免密钥登录其他节点
安装过程中生成配置文件和证书均在Master01上操作,集群管理也在Master01上操作,阿里云或者AWS上需要单独一台kubectl服务器。密钥配置如下:
ssh-keygen -t rsa -f /root/.ssh/id_rsa -C "192.168.68.20@k8s-m01" -N "" for i in k8s-m01 k8s-m02 k8s-m03 k8s-n01 k8s-n02 k8s-n03;do ssh-copy-id -i /root/.ssh/id_rsa.pub $i;done
1.2基本组件安装
1.所有节点安装docker
apt install docker.io -y
提示:
由于新版kubelet建议使用systemd,所以可以把docker的CgroupDriver改成systemd
registry-mirros配置镜像加速
mkdir /etc/dockercat > /etc/docker/daemon.json <<EOF{"exec-opts": ["native.cgroupdriver=systemd"],"registry-mirrors": ["https://zksmnpbq.mirror.aliyuncs.com"]}EOF
设置开机自启**systemctl daemon-reload && systemctl enable --now docker**
2.所有节点安装k8s组件
apt install kubeadm kubelet kubectl -y
如果无法下载先配置k8s软件源
默认配置的pause镜像使用gcr.io仓库,国内可能无法访问,所以这里配置Kubelet使用阿里云的pause镜像:
# 查看 kubelet 配置systemctl status kubeletcd /etc/systemd/system/kubelet.service.d# 添加 Environment="KUBELET_POD_INFRA_CONTAINER= --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.4.1" 如下cat 10-kubeadm.conf# Note: This dropin only works with kubeadm and kubelet v1.11+[Service]Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"Environment="KUBELET_CGROUP_ARGS=--system-reserved=memory=10Gi --kube-reserved=memory=400Mi --eviction-hard=imagefs.available<15%,memory.available<300Mi,nodefs.available<10%,nodefs.inodesFree<5% --cgroup-driver=systemd"Environment="KUBELET_POD_INFRA_CONTAINER= --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1"# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamicallyEnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.EnvironmentFile=-/etc/sysconfig/kubeletExecStart=ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_CGROUP_ARGS $KUBELET_EXTRA_ARGS# 重启 kubelet 服务systemctl daemon-reloadsystemctl restart kubelet
3.所有节点安装k8s软件源
apt-get update && apt-get install -y apt-transport-httpscurl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -vim /etc/apt/sources.list.d/kubernetes.listdeb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial mainapt-get updateapt-get install -y kubelet=1.20.15-00 kubeadm=1.20.15-00 kubectl=1.20.15-00
1.3高可用组件安装
(注意:如果不是高可用集群,haproxy和keepalived无需安装)
公有云要用公有云自带的负载均衡,比如阿里云的SLB,腾讯云的ELB,用来替代haproxy和keepalived,因为公有云大部分都是不支持keepalived的,另外如果用阿里云的话,kubectl控制端不能放在master节点,推荐使用腾讯云,因为阿里云的slb有回环的问题,也就是slb代理的服务器不能反向访问SLB,但是腾讯云修复了这个问题。
所有Master节点通过apt安装HAProxy和KeepAlived:apt install keepalived haproxy -y
所有Master节点配置HAProxy(详细配置参考HAProxy文档,所有Master节点的HAProxy配置相同):
vim /etc/haproxy/haproxy.cfgglobalmaxconn 2000ulimit-n 16384log 127.0.0.1 local0 errstats timeout 30sdefaultslog globalmode httpoption httplogtimeout connect 5000timeout client 50000timeout server 50000timeout http-request 15stimeout http-keep-alive 15sfrontend monitor-inbind *:33305mode httpoption httplogmonitor-uri /monitorfrontend k8s-masterbind 0.0.0.0:16443bind 127.0.0.1:16443mode tcpoption tcplogtcp-request inspect-delay 5sdefault_backend k8s-masterbackend k8s-mastermode tcpoption tcplogoption tcp-checkbalance roundrobindefault-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100server k8s-m01 192.168.68.20:6443 checkserver k8s-m02 192.168.68.21:6443 checkserver k8s-m03 192.168.68.22:6443 check
所有Master节点配置KeepAlived,配置不一样,注意区分
# vim /etc/keepalived/keepalived.conf ,注意每个节点的IP和网卡(interface参数)
M01节点的配置:
vim /etc/keepalived/keepalived.conf! Configuration File for keepalivedglobal_defs {router_id LVS_DEVELscript_user rootenable_script_security}vrrp_script chk_apiserver {script "/etc/keepalived/check_apiserver.sh"interval 5weight -5fall 2rise 1}vrrp_instance VI_1 {state MASTERinterface ens33mcast_src_ip 192.168.68.20virtual_router_id 51priority 101advert_int 2authentication {auth_type PASSauth_pass K8SHA_KA_AUTH}virtual_ipaddress {192.168.68.18}track_script {chk_apiserver}}
M02节点的配置:
! Configuration File for keepalivedglobal_defs {router_id LVS_DEVELscript_user rootenable_script_security}vrrp_script chk_apiserver {script "/etc/keepalived/check_apiserver.sh"interval 5weight -5fall 2rise 1}vrrp_instance VI_1 {state BACKUPinterface ens33mcast_src_ip 192.168.68.21virtual_router_id 51priority 100advert_int 2authentication {auth_type PASSauth_pass K8SHA_KA_AUTH}virtual_ipaddress {192.168.68.18}track_script {chk_apiserver}}
M03节点的配置:
! Configuration File for keepalivedglobal_defs {router_id LVS_DEVELscript_user rootenable_script_security}vrrp_script chk_apiserver {script "/etc/keepalived/check_apiserver.sh"interval 5weight -5fall 2rise 1}vrrp_instance VI_1 {state BACKUPinterface ens33mcast_src_ip 192.168.68.22virtual_router_id 51priority 100advert_int 2authentication {auth_type PASSauth_pass K8SHA_KA_AUTH}virtual_ipaddress {192.168.68.18}track_script {chk_apiserver}}
所有master节点配置KeepAlived健康检查文件:
vim /etc/keepalived/check_apiserver.sh#!/bin/basherr=0for k in $(seq 1 3)docheck_code=$(pgrep haproxy)if [[ $check_code == "" ]]; thenerr=$(expr $err + 1)sleep 1continueelseerr=0breakfidoneif [[ $err != "0" ]]; thenecho "systemctl stop keepalived"/usr/bin/systemctl stop keepalivedexit 1elseexit 0fichmod +x /etc/keepalived/check_apiserver.sh
启动haproxy和keepalived
systemctl daemon-reloadsystemctl enable --now haproxysystemctl enable --now keepalivedsystemctl restart keepalived haproxy
重要:如果安装了keepalived和haproxy,需要测试keepalived是否是正常的
测试VIP
root:kubelet.service.d/ # ping 192.168.68.18 -c 4 [11:34:19]PING 192.168.68.18 (192.168.68.18) 56(84) bytes of data.64 bytes from 192.168.68.18: icmp_seq=1 ttl=64 time=0.032 ms64 bytes from 192.168.68.18: icmp_seq=2 ttl=64 time=0.043 ms64 bytes from 192.168.68.18: icmp_seq=3 ttl=64 time=0.033 ms64 bytes from 192.168.68.18: icmp_seq=4 ttl=64 time=0.038 ms--- 192.168.68.18 ping statistics ---4 packets transmitted, 4 received, 0% packet loss, time 3075msrtt min/avg/max/mdev = 0.032/0.036/0.043/0.004 ms
root:~/ # telnet 192.168.68.18 16443 [11:44:03]Trying 192.168.68.18...Connected to 192.168.68.18.Escape character is '^]'.Connection closed by foreign host.
1.4.集群初始化
1.以下操作只在master01节点执行
M01节点创建kubeadm-config.yaml配置文件如下:
Master01:(# 注意,如果不是高可用集群,192.168.68.18:16443改为m01的地址,16443改为apiserver的端口,默认是6443,
注意更改kubernetesVersion的值和自己服务器kubeadm的版本一致:kubeadm version)
注意:以下文件内容,宿主机网段、podSubnet网段、serviceSubnet网段不能重复
apiVersion: kubeadm.k8s.io/v1beta2bootstrapTokens:- groups:- system:bootstrappers:kubeadm:default-node-tokentoken: 7t2weq.bjbawausm0jaxuryttl: 24h0m0susages:- signing- authenticationkind: InitConfigurationlocalAPIEndpoint:advertiseAddress: 192.168.68.20bindPort: 6443nodeRegistration:criSocket: /var/run/dockershim.sockname: k8s-m01taints:- effect: NoSchedulekey: node-role.kubernetes.io/master---apiServer:certSANs:- 192.168.68.18timeoutForControlPlane: 4m0sapiVersion: kubeadm.k8s.io/v1beta2certificatesDir: /etc/kubernetes/pkiclusterName: kubernetescontrolPlaneEndpoint: 192.168.68.18:16443controllerManager: {}dns:type: CoreDNSetcd:local:dataDir: /var/lib/etcdimageRepository: registry.cn-hangzhou.aliyuncs.com/google_containerskind: ClusterConfigurationkubernetesVersion: v1.23.5networking:dnsDomain: cluster.localpodSubnet: 172.16.0.0/12serviceSubnet: 10.96.0.0/16scheduler: {}
更新kubeadm文件kubeadm config migrate --old-config kubeadm-config.yaml --new-config new.yaml
将new.yaml文件复制到其他master节点,for i in k8s-m02 k8s-m03; do scp new.yaml $i:/root/; done
所有Master节点提前下载镜像,可以节省初始化时间(其他节点不需要更改任何配置,包括IP地址也不需要更改):kubeadm config images pull --config /root/new.yaml
2.所有节点设置开机自启动kubelet
systemctl enable --now kubelet(如果启动失败无需管理,初始化成功以后即可启动)
3.Master01节点初始化
M01节点初始化,初始化以后会在/etc/kubernetes目录下生成对应的证书和配置文件,之后其他Master节点加入M01即可:kubeadm init --config /root/new.yaml --upload-certs
如果初始化失败,重置后再次初始化,命令如下:kubeadm reset -f ; ipvsadm --clear ; rm -rf ~/.kube
初始化成功以后,会产生Token值,用于其他节点加入时使用,因此要记录下初始化成功生成的token值(令牌值):
Your Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:export KUBECONFIG=/etc/kubernetes/admin.confYou should now deploy a pod network to the cluster.Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:https://kubernetes.io/docs/concepts/cluster-administration/addons/You can now join any number of the control-plane node running the following command on each as root:kubeadm join 192.168.68.18:16443 --token 7t2weq.bjbawausm0jaxury \--discovery-token-ca-cert-hash sha256:d9c52c2db865df54fd9db22e911ffb7adf12d1244103005fc1885933c6d27673 \--control-plane --certificate-key 8da0fbf16c11810bb4930846896d21d633af936839c3941890d3c5cf85b98316Please note that the certificate-key gives access to cluster sensitive data, keep it secret!As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.Then you can join any number of worker nodes by running the following on each as root:kubeadm join 192.168.68.18:16443 --token 7t2weq.bjbawausm0jaxury \--discovery-token-ca-cert-hash sha256:d9c52c2db865df54fd9db22e911ffb7adf12d1244103005fc1885933c6d27673
4.Master01节点配置环境变量,用于访问Kubernetes集群:
cat <<EOF >> /root/.bashrcexport KUBECONFIG=/etc/kubernetes/admin.confEOFcat <<EOF >> /root/.zshrcexport KUBECONFIG=/etc/kubernetes/admin.confEOF
查看节点状态:kubectl get node
采用初始化安装方式,所有的系统组件均以容器的方式运行并且在kube-system命名空间内,此时可以查看Pod状态:kubectl get po -n kube-system
5.配置k8s命令补全
临时可以使用apt install -y bash-completionsource /usr/share/bash-completion/bash_completionsource <(kubectl completion bash)永久使用编辑~/.bashrc或echo "source <(kubectl completion bash)" >>~/.bashrcvim ~/.bashrc添加以下内容source <(kubectl completion bash)保存退出,输入以下命令source ~/.bashrc
1.Kubectl 自动补全
BASH
apt install -y bash-completionsource <(kubectl completion bash) # 在 bash 中设置当前 shell 的自动补全,要先安装 bash-completion 包。echo "source <(kubectl completion bash)" >> ~/.bashrc # 在您的 bash shell 中永久的添加自动补全source ~/.bashrc
您还可以为 kubectl 使用一个速记别名,该别名也可以与 completion 一起使用:
alias k=kubectlcomplete -F __start_kubectl k
ZSH
apt install -y bash-completionsource <(kubectl completion zsh) # 在 zsh 中设置当前 shell 的自动补全echo "[[ $commands[kubectl] ]] && source <(kubectl completion zsh)" >> ~/.zshrc # 在您的 zsh shell 中永久的添加自动补全source ~/.zshrc
1.5.Master和node节点
注意:以下步骤是上述init命令产生的Token过期了才需要执行以下步骤,如果没有过期不需要执行
Token过期后生成新的token:
kubeadm token create —print-join-command
Master需要生成__—certificate-key
kubeadm init phase upload-certs —upload-certs
Token没有过期直接执行Join就行了
其他master加入集群,master02和master03分别执行
kubeadm join 192.168.68.18:16443 --token 7t2weq.bjbawausm0jaxury \--discovery-token-ca-cert-hash sha256:d9c52c2db865df54fd9db22e911ffb7adf12d1244103005fc1885933c6d27673 \--control-plane --certificate-key 8da0fbf16c11810bb4930846896d21d633af936839c3941890d3c5cf85b98316
查看当前状态:kubectl get node
Node节点的配置
Node节点上主要部署公司的一些业务应用,生产环境中不建议Master节点部署系统组件之外的其他Pod,测试环境可以允许Master节点部署Pod以节省系统资源。
kubeadm join 192.168.68.18:16443 --token 7t2weq.bjbawausm0jaxury \--discovery-token-ca-cert-hash sha256:d9c52c2db865df54fd9db22e911ffb7adf12d1244103005fc1885933c6d27673
所有节点初始化完成后,查看集群状态
kubectl get node
1.6.网络组件Calico组件的安装
calico-etcd.yaml
---# Source: calico/templates/calico-etcd-secrets.yaml# The following contains k8s Secrets for use with a TLS enabled etcd cluster.# For information on populating Secrets, see http://kubernetes.io/docs/user-guide/secrets/apiVersion: v1kind: Secrettype: Opaquemetadata:name: calico-etcd-secretsnamespace: kube-systemdata:# Populate the following with etcd TLS configuration if desired, but leave blank if# not using TLS for etcd.# The keys below should be uncommented and the values populated with the base64# encoded contents of each file that would be associated with the TLS data.# Example command for encoding a file contents: cat <file> | base64 -w 0# etcd-key: null# etcd-cert: null# etcd-ca: null---# Source: calico/templates/calico-config.yaml# This ConfigMap is used to configure a self-hosted Calico installation.kind: ConfigMapapiVersion: v1metadata:name: calico-confignamespace: kube-systemdata:# Configure this with the location of your etcd cluster.etcd_endpoints: "http://<ETCD_IP>:<ETCD_PORT>"# If you're using TLS enabled etcd uncomment the following.# You must also populate the Secret below with these files.etcd_ca: "" # "/calico-secrets/etcd-ca"etcd_cert: "" # "/calico-secrets/etcd-cert"etcd_key: "" # "/calico-secrets/etcd-key"# Typha is disabled.typha_service_name: "none"# Configure the backend to use.calico_backend: "bird"# Configure the MTU to use for workload interfaces and tunnels.# By default, MTU is auto-detected, and explicitly setting this field should not be required.# You can override auto-detection by providing a non-zero value.veth_mtu: "0"# The CNI network configuration to install on each node. The special# values in this config will be automatically populated.cni_network_config: |-{"name": "k8s-pod-network","cniVersion": "0.3.1","plugins": [{"type": "calico","log_level": "info","log_file_path": "/var/log/calico/cni/cni.log","etcd_endpoints": "__ETCD_ENDPOINTS__","etcd_key_file": "__ETCD_KEY_FILE__","etcd_cert_file": "__ETCD_CERT_FILE__","etcd_ca_cert_file": "__ETCD_CA_CERT_FILE__","mtu": __CNI_MTU__,"ipam": {"type": "calico-ipam"},"policy": {"type": "k8s"},"kubernetes": {"kubeconfig": "__KUBECONFIG_FILEPATH__"}},{"type": "portmap","snat": true,"capabilities": {"portMappings": true}},{"type": "bandwidth","capabilities": {"bandwidth": true}}]}---# Source: calico/templates/calico-kube-controllers-rbac.yaml# Include a clusterrole for the kube-controllers component,# and bind it to the calico-kube-controllers serviceaccount.kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata:name: calico-kube-controllersrules:# Pods are monitored for changing labels.# The node controller monitors Kubernetes nodes.# Namespace and serviceaccount labels are used for policy.- apiGroups: [""]resources:- pods- nodes- namespaces- serviceaccountsverbs:- watch- list- get# Watch for changes to Kubernetes NetworkPolicies.- apiGroups: ["networking.k8s.io"]resources:- networkpoliciesverbs:- watch- list---kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1metadata:name: calico-kube-controllersroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: calico-kube-controllerssubjects:- kind: ServiceAccountname: calico-kube-controllersnamespace: kube-system------# Source: calico/templates/calico-node-rbac.yaml# Include a clusterrole for the calico-node DaemonSet,# and bind it to the calico-node serviceaccount.kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata:name: calico-noderules:# The CNI plugin needs to get pods, nodes, and namespaces.- apiGroups: [""]resources:- pods- nodes- namespacesverbs:- get# EndpointSlices are used for Service-based network policy rule# enforcement.- apiGroups: ["discovery.k8s.io"]resources:- endpointslicesverbs:- watch- list- apiGroups: [""]resources:- endpoints- servicesverbs:# Used to discover service IPs for advertisement.- watch- list# Pod CIDR auto-detection on kubeadm needs access to config maps.- apiGroups: [""]resources:- configmapsverbs:- get- apiGroups: [""]resources:- nodes/statusverbs:# Needed for clearing NodeNetworkUnavailable flag.- patch---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:name: calico-noderoleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: calico-nodesubjects:- kind: ServiceAccountname: calico-nodenamespace: kube-system---# Source: calico/templates/calico-node.yaml# This manifest installs the calico-node container, as well# as the CNI plugins and network config on# each master and worker node in a Kubernetes cluster.kind: DaemonSetapiVersion: apps/v1metadata:name: calico-nodenamespace: kube-systemlabels:k8s-app: calico-nodespec:selector:matchLabels:k8s-app: calico-nodeupdateStrategy:type: RollingUpdaterollingUpdate:maxUnavailable: 1template:metadata:labels:k8s-app: calico-nodespec:nodeSelector:kubernetes.io/os: linuxhostNetwork: truetolerations:# Make sure calico-node gets scheduled on all nodes.- effect: NoScheduleoperator: Exists# Mark the pod as a critical add-on for rescheduling.- key: CriticalAddonsOnlyoperator: Exists- effect: NoExecuteoperator: ExistsserviceAccountName: calico-node# Minimize downtime during a rolling upgrade or deletion; tell Kubernetes to do a "force# deletion": https://kubernetes.io/docs/concepts/workloads/pods/pod/#termination-of-pods.terminationGracePeriodSeconds: 0priorityClassName: system-node-criticalinitContainers:# This container installs the CNI binaries# and CNI network config file on each node.- name: install-cniimage: registry.cn-beijing.aliyuncs.com/dotbalo/cni:v3.22.0command: ["/opt/cni/bin/install"]envFrom:- configMapRef:# Allow KUBERNETES_SERVICE_HOST and KUBERNETES_SERVICE_PORT to be overridden for eBPF mode.name: kubernetes-services-endpointoptional: trueenv:# Name of the CNI config file to create.- name: CNI_CONF_NAMEvalue: "10-calico.conflist"# The CNI network config to install on each node.- name: CNI_NETWORK_CONFIGvalueFrom:configMapKeyRef:name: calico-configkey: cni_network_config# The location of the etcd cluster.- name: ETCD_ENDPOINTSvalueFrom:configMapKeyRef:name: calico-configkey: etcd_endpoints# CNI MTU Config variable- name: CNI_MTUvalueFrom:configMapKeyRef:name: calico-configkey: veth_mtu# Prevents the container from sleeping forever.- name: SLEEPvalue: "false"volumeMounts:- mountPath: /host/opt/cni/binname: cni-bin-dir- mountPath: /host/etc/cni/net.dname: cni-net-dir- mountPath: /calico-secretsname: etcd-certssecurityContext:privileged: true# Adds a Flex Volume Driver that creates a per-pod Unix Domain Socket to allow Dikastes# to communicate with Felix over the Policy Sync API.- name: flexvol-driverimage: registry.cn-beijing.aliyuncs.com/dotbalo/pod2daemon-flexvol:v3.22.0volumeMounts:- name: flexvol-driver-hostmountPath: /host/driversecurityContext:privileged: truecontainers:# Runs calico-node container on each Kubernetes node. This# container programs network policy and routes on each# host.- name: calico-nodeimage: registry.cn-beijing.aliyuncs.com/dotbalo/node:v3.22.0envFrom:- configMapRef:# Allow KUBERNETES_SERVICE_HOST and KUBERNETES_SERVICE_PORT to be overridden for eBPF mode.name: kubernetes-services-endpointoptional: trueenv:# The location of the etcd cluster.- name: ETCD_ENDPOINTSvalueFrom:configMapKeyRef:name: calico-configkey: etcd_endpoints# Location of the CA certificate for etcd.- name: ETCD_CA_CERT_FILEvalueFrom:configMapKeyRef:name: calico-configkey: etcd_ca# Location of the client key for etcd.- name: ETCD_KEY_FILEvalueFrom:configMapKeyRef:name: calico-configkey: etcd_key# Location of the client certificate for etcd.- name: ETCD_CERT_FILEvalueFrom:configMapKeyRef:name: calico-configkey: etcd_cert# Set noderef for node controller.- name: CALICO_K8S_NODE_REFvalueFrom:fieldRef:fieldPath: spec.nodeName# Choose the backend to use.- name: CALICO_NETWORKING_BACKENDvalueFrom:configMapKeyRef:name: calico-configkey: calico_backend# Cluster type to identify the deployment type- name: CLUSTER_TYPEvalue: "k8s,bgp"# Auto-detect the BGP IP address.- name: IPvalue: "autodetect"# Enable IPIP- name: CALICO_IPV4POOL_IPIPvalue: "Always"# Enable or Disable VXLAN on the default IP pool.- name: CALICO_IPV4POOL_VXLANvalue: "Never"# Set MTU for tunnel device used if ipip is enabled- name: FELIX_IPINIPMTUvalueFrom:configMapKeyRef:name: calico-configkey: veth_mtu# Set MTU for the VXLAN tunnel device.- name: FELIX_VXLANMTUvalueFrom:configMapKeyRef:name: calico-configkey: veth_mtu# Set MTU for the Wireguard tunnel device.- name: FELIX_WIREGUARDMTUvalueFrom:configMapKeyRef:name: calico-configkey: veth_mtu# The default IPv4 pool to create on startup if none exists. Pod IPs will be# chosen from this range. Changing this value after installation will have# no effect. This should fall within `--cluster-cidr`.- name: CALICO_IPV4POOL_CIDRvalue: "POD_CIDR"# Disable file logging so `kubectl logs` works.- name: CALICO_DISABLE_FILE_LOGGINGvalue: "true"# Set Felix endpoint to host default action to ACCEPT.- name: FELIX_DEFAULTENDPOINTTOHOSTACTIONvalue: "ACCEPT"# Disable IPv6 on Kubernetes.- name: FELIX_IPV6SUPPORTvalue: "false"- name: FELIX_HEALTHENABLEDvalue: "true"securityContext:privileged: trueresources:requests:cpu: 250mlifecycle:preStop:exec:command:- /bin/calico-node- -shutdownlivenessProbe:exec:command:- /bin/calico-node- -felix-live- -bird-liveperiodSeconds: 10initialDelaySeconds: 10failureThreshold: 6timeoutSeconds: 10readinessProbe:exec:command:- /bin/calico-node- -felix-ready- -bird-readyperiodSeconds: 10timeoutSeconds: 10volumeMounts:# For maintaining CNI plugin API credentials.- mountPath: /host/etc/cni/net.dname: cni-net-dirreadOnly: false- mountPath: /lib/modulesname: lib-modulesreadOnly: true- mountPath: /run/xtables.lockname: xtables-lockreadOnly: false- mountPath: /var/run/caliconame: var-run-calicoreadOnly: false- mountPath: /var/lib/caliconame: var-lib-calicoreadOnly: false- mountPath: /calico-secretsname: etcd-certs- name: policysyncmountPath: /var/run/nodeagent# For eBPF mode, we need to be able to mount the BPF filesystem at /sys/fs/bpf so we mount in the# parent directory.- name: sysfsmountPath: /sys/fs/# Bidirectional means that, if we mount the BPF filesystem at /sys/fs/bpf it will propagate to the host.# If the host is known to mount that filesystem already then Bidirectional can be omitted.mountPropagation: Bidirectional- name: cni-log-dirmountPath: /var/log/calico/cnireadOnly: truevolumes:# Used by calico-node.- name: lib-moduleshostPath:path: /lib/modules- name: var-run-calicohostPath:path: /var/run/calico- name: var-lib-calicohostPath:path: /var/lib/calico- name: xtables-lockhostPath:path: /run/xtables.locktype: FileOrCreate- name: sysfshostPath:path: /sys/fs/type: DirectoryOrCreate# Used to install CNI.- name: cni-bin-dirhostPath:path: /opt/cni/bin- name: cni-net-dirhostPath:path: /etc/cni/net.d# Used to access CNI logs.- name: cni-log-dirhostPath:path: /var/log/calico/cni# Mount in the etcd TLS secrets with mode 400.# See https://kubernetes.io/docs/concepts/configuration/secret/- name: etcd-certssecret:secretName: calico-etcd-secretsdefaultMode: 0400# Used to create per-pod Unix Domain Sockets- name: policysynchostPath:type: DirectoryOrCreatepath: /var/run/nodeagent# Used to install Flex Volume Driver- name: flexvol-driver-hosthostPath:type: DirectoryOrCreatepath: /usr/libexec/kubernetes/kubelet-plugins/volume/exec/nodeagent~uds---apiVersion: v1kind: ServiceAccountmetadata:name: calico-nodenamespace: kube-system---# Source: calico/templates/calico-kube-controllers.yaml# See https://github.com/projectcalico/kube-controllersapiVersion: apps/v1kind: Deploymentmetadata:name: calico-kube-controllersnamespace: kube-systemlabels:k8s-app: calico-kube-controllersspec:# The controllers can only have a single active instance.replicas: 1selector:matchLabels:k8s-app: calico-kube-controllersstrategy:type: Recreatetemplate:metadata:name: calico-kube-controllersnamespace: kube-systemlabels:k8s-app: calico-kube-controllersspec:nodeSelector:kubernetes.io/os: linuxtolerations:# Mark the pod as a critical add-on for rescheduling.- key: CriticalAddonsOnlyoperator: Exists- key: node-role.kubernetes.io/mastereffect: NoScheduleserviceAccountName: calico-kube-controllerspriorityClassName: system-cluster-critical# The controllers must run in the host network namespace so that# it isn't governed by policy that would prevent it from working.hostNetwork: truecontainers:- name: calico-kube-controllersimage: registry.cn-beijing.aliyuncs.com/dotbalo/kube-controllers:v3.22.0env:# The location of the etcd cluster.- name: ETCD_ENDPOINTSvalueFrom:configMapKeyRef:name: calico-configkey: etcd_endpoints# Location of the CA certificate for etcd.- name: ETCD_CA_CERT_FILEvalueFrom:configMapKeyRef:name: calico-configkey: etcd_ca# Location of the client key for etcd.- name: ETCD_KEY_FILEvalueFrom:configMapKeyRef:name: calico-configkey: etcd_key# Location of the client certificate for etcd.- name: ETCD_CERT_FILEvalueFrom:configMapKeyRef:name: calico-configkey: etcd_cert# Choose which controllers to run.- name: ENABLED_CONTROLLERSvalue: policy,namespace,serviceaccount,workloadendpoint,nodevolumeMounts:# Mount in the etcd TLS secrets.- mountPath: /calico-secretsname: etcd-certslivenessProbe:exec:command:- /usr/bin/check-status- -lperiodSeconds: 10initialDelaySeconds: 10failureThreshold: 6timeoutSeconds: 10readinessProbe:exec:command:- /usr/bin/check-status- -rperiodSeconds: 10volumes:# Mount in the etcd TLS secrets with mode 400.# See https://kubernetes.io/docs/concepts/configuration/secret/- name: etcd-certssecret:secretName: calico-etcd-secretsdefaultMode: 0440---apiVersion: v1kind: ServiceAccountmetadata:name: calico-kube-controllersnamespace: kube-system---# This manifest creates a Pod Disruption Budget for Controller to allow K8s Cluster Autoscaler to evictapiVersion: policy/v1beta1kind: PodDisruptionBudgetmetadata:name: calico-kube-controllersnamespace: kube-systemlabels:k8s-app: calico-kube-controllersspec:maxUnavailable: 1selector:matchLabels:k8s-app: calico-kube-controllers---# Source: calico/templates/calico-typha.yaml---# Source: calico/templates/configure-canal.yaml---# Source: calico/templates/kdd-crds.yaml
修改calico-etcd.yaml的以下位置sed -i 's#etcd_endpoints: "http://<ETCD_IP>:<ETCD_PORT>"#etcd_endpoints: "https://192.168.68.20:2379,https://192.168.68.21:2379,https://192.168.68.22:2379"#g' calico-etcd.yamlETCD_CA=cat /etc/kubernetes/pki/etcd/ca.crt | base64 | tr -d ‘\n’<br />`ETCD_CERT=`cat /etc/kubernetes/pki/etcd/server.crt | base64 | tr -d '\n'ETCD_KEY=cat /etc/kubernetes/pki/etcd/server.key | base64 | tr -d ‘\n’<br />`sed -i "s@# etcd-key: null@etcd-key: ${ETCD_KEY}@g; s@# etcd-cert: null@etcd-cert: ${ETCD_CERT}@g; s@# etcd-ca: null@etcd-ca: ${ETCD_CA}@g" calico-etcd.yaml`<br />`sed -i 's#etcd_ca: ""#etcd_ca: "/calico-secrets/etcd-ca"#g; s#etcd_cert: ""#etcd_cert: "/calico-secrets/etcd-cert"#g; s#etcd_key: "" #etcd_key: "/calico-secrets/etcd-key" #g' calico-etcd.yaml`<br />`POD_SUBNET=`cat /etc/kubernetes/manifests/kube-controller-manager.yaml | grep cluster-cidr= | awk -F= '{print $NF}'sed -i 's@# - name: CALICO_IPV4POOL_CIDR@- name: CALICO_IPV4POOL_CIDR@g; s@# value: "172.16.0.0/12"@ value: '"${POD_SUBNET}"'@g' calico-etcd.yamlkubectl apply -f calico-etcd.yaml
部署calico 时报错,下载的官方的calico.yaml 文件 【数据存储在Kubernetes API Datastore服务中】https://docs.projectcalico.org/manifests/calico.yaml
报错内容:
Warning: policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
解决方法: 其实报错很很明显了 calico.yaml 文件里的 用的是 v1beta1 PodDisruptionBudget ,而在K8S 1.21 版本之后就不支持v1beta1 PodDisruptionBudget ,改为支持
v1 PodDisruptionBudget
使用 Kubernetes API 数据存储安装 Calico,50 个节点或更少
1.下载 Kubernetes API 数据存储的 Calico 网络清单。curl https://docs.projectcalico.org/manifests/calico.yaml -O
2.如果您使用的是 Pod CIDR ,请跳到下一步。如果您将不同的 pod CIDR 与 kubeadm 配合使用,则无需进行任何更改 - Calico 将根据正在运行的配置自动检测 CIDR。对于其他平台,请确保取消对清单中CALICO_IPV4POOL_CIDR变量的注释,并将其设置为与所选 pod CIDR 相同的值。192.168.0.0/16
- name: CALICO_IPV4POOL_CIDRvalue: "172.16.0.0/12"修改calico.yaml取消注释,value和podSubnet一样
3.根据需要自定义清单。
4.使用以下命令应用清单。kubectl apply -f calico.yaml
使用 Kubernetes API 数据存储安装 Calico,超过 50 个节点
- 下载 Kubernetes API 数据存储的 Calico 网络清单。
- $ curl https://docs.projectcalico.org/manifests/calico-typha.yaml -o calico.yaml
- 如果您使用的是 Pod CIDR ,请跳到下一步。如果您将不同的 pod CIDR 与 kubeadm 配合使用,则无需进行任何更改 - Calico 将根据正在运行的配置自动检测 CIDR。对于其他平台,请确保取消对清单中CALICO_IPV4POOL_CIDR变量的注释,并将其设置为与所选 pod CIDR 相同的值。192.168.0.0/16
- 将副本计数修改为命名 中的所需数字。Deploymentcalico-typha
- apiVersion: apps/v1beta1 kind: Deployment metadata: name: calico-typha … spec: … replicas:
- 我们建议每 200 个节点至少一个副本,并且不超过 20 个副本。在生产环境中,我们建议至少使用三个副本,以减少滚动升级和故障的影响。副本数应始终小于节点数,否则滚动升级将停止。此外,Typha 仅当 Typha 实例数少于节点数时,才有助于扩展。
- 警告:如果将 Typha 部署副本计数设置为 0,则 Felix 将不会启动。typha_service_name
- 如果需要,自定义清单。
- 应用清单。
- $ kubectl apply -f calico.yaml
使用 etcd 数据存储安装 Calico
注意:不建议将etcd数据库用于新安装。但是,如果您将Calico作为OpenStack和Kubernetes的网络插件运行,则可以选择它。
- 下载 etcd 的 Calico 网络清单。
- $ curl https://docs.projectcalico.org/manifests/calico-etcd.yaml -o calico.yaml
- 如果您使用的是 Pod CIDR ,请跳到下一步。如果您将不同的 pod CIDR 与 kubeadm 配合使用,则无需进行任何更改 - Calico 将根据正在运行的配置自动检测 CIDR。对于其他平台,请确保取消对清单中CALICO_IPV4POOL_CIDR变量的注释,并将其设置为与所选 pod CIDR 相同的值。192.168.0.0/16
- 在 命名中, 将 的值设置为 etcd 服务器的 IP 地址和端口。
- ConfigMap
- calico-config
- etcd_endpoints
- 提示:您可以使用逗号作为分隔符指定多个。etcd_endpoint
- 如果需要,自定义清单。
- 使用以下命令应用清单。
- $ kubectl apply -f calico.yaml
1.7.Metrics部署和Dashboard部署
1.Metrics部署
下载并修改名称
docker pull bitnami/metrics-server:0.5.2
docker tag bitnami/metrics-server:0.5.2 k8s.gcr.io/metrics-server/metrics-server:v0.5.2
vim components0.5.2.yaml
$ cat components0.5.2.yamlapiVersion: v1kind: ServiceAccountmetadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:labels:k8s-app: metrics-serverrbac.authorization.k8s.io/aggregate-to-admin: "true"rbac.authorization.k8s.io/aggregate-to-edit: "true"rbac.authorization.k8s.io/aggregate-to-view: "true"name: system:aggregated-metrics-readerrules:- apiGroups:- metrics.k8s.ioresources:- pods- nodesverbs:- get- list- watch---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:labels:k8s-app: metrics-servername: system:metrics-serverrules:- apiGroups:- ""resources:- pods- nodes- nodes/stats- namespaces- configmapsverbs:- get- list- watch---apiVersion: rbac.authorization.k8s.io/v1kind: RoleBindingmetadata:labels:k8s-app: metrics-servername: metrics-server-auth-readernamespace: kube-systemroleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: extension-apiserver-authentication-readersubjects:- kind: ServiceAccountname: metrics-servernamespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:labels:k8s-app: metrics-servername: metrics-server:system:auth-delegatorroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:auth-delegatorsubjects:- kind: ServiceAccountname: metrics-servernamespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:labels:k8s-app: metrics-servername: system:metrics-serverroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:metrics-serversubjects:- kind: ServiceAccountname: metrics-servernamespace: kube-system---apiVersion: v1kind: Servicemetadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-systemspec:ports:- name: httpsport: 443protocol: TCPtargetPort: httpsselector:k8s-app: metrics-server---apiVersion: apps/v1kind: Deploymentmetadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-systemspec:selector:matchLabels:k8s-app: metrics-serverstrategy:rollingUpdate:maxUnavailable: 0template:metadata:labels:k8s-app: metrics-serverspec:containers:- args:- --cert-dir=/tmp- --secure-port=4443- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname- --kubelet-use-node-status-port- --metric-resolution=15s- --kubelet-insecure-tlsimage: k8s.gcr.io/metrics-server/metrics-server:v0.5.2imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 3httpGet:path: /livezport: httpsscheme: HTTPSperiodSeconds: 10name: metrics-serverports:- containerPort: 4443name: httpsprotocol: TCPreadinessProbe:failureThreshold: 3httpGet:path: /readyzport: httpsscheme: HTTPSinitialDelaySeconds: 20periodSeconds: 10resources:requests:cpu: 100mmemory: 200MisecurityContext:readOnlyRootFilesystem: truerunAsNonRoot: truerunAsUser: 1000volumeMounts:- mountPath: /tmpname: tmp-dirnodeSelector:kubernetes.io/os: linuxpriorityClassName: system-cluster-criticalserviceAccountName: metrics-servervolumes:- emptyDir: {}name: tmp-dir---apiVersion: apiregistration.k8s.io/v1kind: APIServicemetadata:labels:k8s-app: metrics-servername: v1beta1.metrics.k8s.iospec:group: metrics.k8s.iogroupPriorityMinimum: 100insecureSkipTLSVerify: trueservice:name: metrics-servernamespace: kube-systemversion: v1beta1versionPriority: 100
**kubectl create -f **components0.5.2.yaml
1.23.5存在问题下面的方法
地址:https://github.com/kubernetes-sigs/metrics-server
将Master01节点的front-proxy-ca.crt复制到所有Node节点**scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-node01:/etc/kubernetes/pki/front-proxy-ca.crt****scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-node(其他节点自行拷贝):/etc/kubernetes/pki/front-proxy-ca.crt**
增加证书vim components.yaml
- —requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt # change to front-proxy-ca.crt for kubeadm
安装metrics server**kubectl create -f **components.yaml
2.Dashboard部署
地址:https://github.com/kubernetes/dashboardkubectl apply -f recommended.yaml
创建管理员用户vim admin.yaml
apiVersion: v1kind: ServiceAccountmetadata:name: admin-usernamespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:name: admin-userannotations:rbac.authorization.kubernetes.io/autoupdate: "true"roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: cluster-adminsubjects:- kind: ServiceAccountname: admin-usernamespace: kube-system
kubectl apply -f admin.yaml -n kube-system
启动错误:
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Scheduled 4m52s default-scheduler Successfully assigned kube-system/metrics-server-d9c898cdf-kpc5k to k8s-node03Normal SandboxChanged 4m32s (x2 over 4m34s) kubelet Pod sandbox changed, it will be killed and re-created.Normal Pulling 3m34s (x3 over 4m49s) kubelet Pulling image "k8s.gcr.io/metrics-server/metrics-server:v0.5.2"Warning Failed 3m19s (x3 over 4m34s) kubelet Failed to pull image "k8s.gcr.io/metrics-server/metrics-server:v0.5.2": rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)Warning Failed 3m19s (x3 over 4m34s) kubelet Error: ErrImagePullNormal BackOff 2m56s (x7 over 4m32s) kubelet Back-off pulling image "k8s.gcr.io/metrics-server/metrics-server:v0.5.2"Warning Failed 2m56s (x7 over 4m32s) kubelet Error: ImagePullBackOff
解决方法:
需要手动下载镜像再进行改名(每个节点都需要下载)
镜像地址:bitnami/metrics-server - Docker Image | Docker Hub
docker pull bitnami/metrics-server:0.6.1docker tag bitnami/metrics-server:0.6.1 k8s.gcr.io/metrics-server/metrics-server:v0.6.1
3.登录dashboard
更改dashboard的svc为NodePort:
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
将ClusterIP更改为NodePort(如果已经为NodePort忽略此步骤):
查看端口号:
kubectl get svc kubernetes-dashboard -n kubernetes-dashboard
根据自己的实例端口号,通过任意安装了kube-proxy的宿主机的IP+端口即可访问到dashboard:
访问Dashboard:https://10.103.236.201:18282(请更改18282为自己的端口),选择登录方式为令牌(即token方式)
查看token值:kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
4.一些必须的配置更改
将Kube-proxy改为ipvs模式,因为在初始化集群的时候注释了ipvs配置,所以需要自行修改一下:
在master01节点执行
kubectl edit cm kube-proxy -n kube-system
mode: ipvs
更新Kube-Proxy的Pod:kubectl patch daemonset kube-proxy -p "{\"spec\":{\"template\":{\"metadata\":{\"annotations\":{\"date\":\"date +’%s’\"}}}}}" -n kube-system
验证Kube-Proxy模式
curl 127.0.0.1:10249/proxyMode
1.8dashboard其它选择
Kuboard - Kubernetes 多集群管理界面
地址:https://kuboard.cn/
- 用户名: admin
密 码: Kuboard123
kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
查看watch kubectl get pods -n kuboard
访问 Kuboard在浏览器中打开链接 http://your-node-ip-address:30080 192.168.68.18:30080
- 输入初始用户名和密码,并登录
- 用户名:admin
- 密码:Kuboard123
卸载
- 执行 Kuboard v3 的卸载
kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
- kubectl delete -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
- 清理遗留数据
在 master 节点以及带有 k8s.kuboard.cn/role=etcd 标签的节点上执行
rm -rf /usr/share/kuboard
2.二进制高可用安装k8s集群(生产级)
2.1高可用基本配置
1.修改apt源
所有节点配置vim /etc/apt/sources.list
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
ubuntu镜像-ubuntu下载地址-ubuntu安装教程-阿里巴巴开源镜像站 (aliyun.com)
2.修改hosts文件
所有节点配置vim /etc/hosts
192.168.68.50 k8s-master01192.168.68.51 k8s-master02192.168.68.52 k8s-master03192.168.68.48 k8s-master-lb # 如果不是高可用集群,该IP为Master01的IP192.168.68.53 k8s-node01192.168.68.54 k8s-node02
3.关闭swap分区
所有节点配置vim /etc/fstab
临时禁用:swapoff -a永久禁用:vim /etc/fstab 注释掉swap条目,重启系统
4.时间同步
所有节点
apt install ntpdate -yrm -rf /etc/localtimeln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtimentpdate cn.ntp.org.cn# 加入到crontab -e 3*/5 * * * * /usr/sbin/ntpdate time2.aliyun.com# 加入到开机自动同步,vim /etc/rc.localntpdate cn.ntp.org.cn
5.配置limit
所有节点ulimit -SHn 65535vim /etc/security/limits.conf
# 末尾添加如下内容
* soft nofile 655360* hard nofile 131072* soft nproc 655350* hard nproc 655350* soft memlock unlimited* hard memlock unlimited
6.修改内核参数
cat >/etc/sysctl.conf <<EOF# Controls source route verificationnet.ipv4.conf.default.rp_filter = 1net.ipv4.ip_nonlocal_bind = 1net.ipv4.ip_forward = 1# Do not accept source routingnet.ipv4.conf.default.accept_source_route = 0# Controls the System Request debugging functionality of the kernelkernel.sysrq = 0# Controls whether core dumps will append the PID to the core filename.# Useful for debugging multi-threadedapplications. kernel.core_uses_pid = 1# Controls the use of TCP syncookiesnet.ipv4.tcp_syncookies = 1# Disable netfilter on bridges.net.bridge.bridge-nf-call-ip6tables = 0net.bridge.bridge-nf-call-iptables = 0net.bridge.bridge-nf-call-arptables = 0# Controls the default maxmimum size of a mesage queuekernel.msgmnb = 65536# # Controls the maximum size of a message, in byteskernel.msgmax = 65536# Controls the maximum shared segment size, in byteskernel.shmmax = 68719476736# # Controls the maximum number of shared memory segments, in pageskernel.shmall = 4294967296# TCP kernel paramaternet.ipv4.tcp_mem = 786432 1048576 1572864net.ipv4.tcp_rmem = 4096 87380 4194304net.ipv4.tcp_wmem = 4096 16384 4194304 net.ipv4.tcp_window_scaling = 1net.ipv4.tcp_sack = 1# socket buffernet.core.wmem_default = 8388608net.core.rmem_default = 8388608net.core.rmem_max = 16777216net.core.wmem_max = 16777216net.core.netdev_max_backlog = 262144net.core.somaxconn = 20480net.core.optmem_max = 81920# TCP connnet.ipv4.tcp_max_syn_backlog = 262144net.ipv4.tcp_syn_retries = 3net.ipv4.tcp_retries1 = 3net.ipv4.tcp_retries2 = 15# tcp conn reusenet.ipv4.tcp_timestamps = 0net.ipv4.tcp_tw_reuse = 0net.ipv4.tcp_tw_recycle = 0net.ipv4.tcp_fin_timeout = 1net.ipv4.tcp_max_tw_buckets = 20000net.ipv4.tcp_max_orphans = 3276800net.ipv4.tcp_synack_retries = 1net.ipv4.tcp_syncookies = 1# keepalive connnet.ipv4.tcp_keepalive_time = 300net.ipv4.tcp_keepalive_intvl = 30net.ipv4.tcp_keepalive_probes = 3net.ipv4.ip_local_port_range = 10001 65000# swapvm.overcommit_memory = 0vm.swappiness = 10#net.ipv4.conf.eth1.rp_filter = 0#net.ipv4.conf.lo.arp_ignore = 1#net.ipv4.conf.lo.arp_announce = 2#net.ipv4.conf.all.arp_ignore = 1#net.ipv4.conf.all.arp_announce = 2EOF
安装常用软件apt install wget jq psmisc vim net-tools telnet lvm2 git -y
所有节点安装ipvsadm
apt install ipvsadm ipset conntrack -ymodprobe -- ip_vsmodprobe -- ip_vs_rrmodprobe -- ip_vs_wrrmodprobe -- ip_vs_shmodprobe -- nf_conntrackvim /etc/modules-load.d/ipvs.conf# 加入以下内容ip_vsip_vs_lcip_vs_wlcip_vs_rrip_vs_wrrip_vs_lblcip_vs_lblcrip_vs_dhip_vs_ship_vs_foip_vs_nqip_vs_sedip_vs_ftpip_vs_shnf_conntrackip_tablesip_setxt_setipt_setipt_rpfilteript_REJECTipip
然后执行systemctl enable —now systemd-modules-load.service即可
开启一些k8s集群中必须的内核参数,所有节点配置k8s内核
cat <<EOF > /etc/sysctl.d/k8s.confnet.ipv4.ip_forward = 1net.bridge.bridge-nf-call-iptables = 1net.bridge.bridge-nf-call-ip6tables = 1fs.may_detach_mounts = 1net.ipv4.conf.all.route_localnet = 1vm.overcommit_memory=1vm.panic_on_oom=0fs.inotify.max_user_watches=89100fs.file-max=52706963fs.nr_open=52706963net.netfilter.nf_conntrack_max=2310720net.ipv4.tcp_keepalive_time = 600net.ipv4.tcp_keepalive_probes = 3net.ipv4.tcp_keepalive_intvl =15net.ipv4.tcp_max_tw_buckets = 36000net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_max_orphans = 327680net.ipv4.tcp_orphan_retries = 3net.ipv4.tcp_syncookies = 1net.ipv4.tcp_max_syn_backlog = 16384net.ipv4.ip_conntrack_max = 65536net.ipv4.tcp_max_syn_backlog = 16384net.ipv4.tcp_timestamps = 0net.core.somaxconn = 16384EOF
sysctl —system
所有节点配置完内核后,重启服务器,保证重启后内核依旧加载
reboot
查看
lsmod | grep —color=auto -e ip_vs -e nf_conntrack
8.Master01节点免密钥登录其他节点
安装过程中生成配置文件和证书均在Master01上操作,集群管理也在Master01上操作,阿里云或者AWS上需要单独一台kubectl服务器。密钥配置如下:
ssh-keygen -t rsa -f /root/.ssh/id_rsa -C "192.168.68.10@k8s-master01" -N "" for i in k8s-master01 k8s-master02 k8s-node01 k8s-node02 ;do ssh-copy-id -i /root/.ssh/id_rsa.pub $i;done
9.下载安装文件
cd /root/ ; git clone [https://github.com/dotbalo/k8s-ha-install.git](https://github.com/dotbalo/k8s-ha-install.git)
2.2基本组件安装
1.所有节点安装docker
docker20.10版本K8S不支持需要安装19.03
将官方 Docker 版本库的 GPG 密钥添加到系统中:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
将 Docker 版本库添加到APT源:
add-apt-repository “deb [arch=amd64] https://download.docker.com/linux/ubuntu focal stable”
我们用新添加的 Docker 软件包来进行升级更新。
apt update
确保要从 Docker 版本库,而不是默认的 Ubuntu 版本库进行安装:
apt-cache policy docker-ce
安装 Docker :
apt install docker-ce=5:19.03.15~3-0~ubuntu-focal docker-ce-cli=5:19.03.15~3-0~ubuntu-focal -y
启动docker
systemctl status docker
提示:
由于新版kubelet建议使用systemd,所以可以把docker的CgroupDriver改成systemd
registry-mirros配置镜像加速
mkdir /etc/dockercat > /etc/docker/daemon.json <<EOF{"exec-opts": ["native.cgroupdriver=systemd"],"registry-mirrors": ["https://zksmnpbq.mirror.aliyuncs.com"]}EOF
设置开机自启**systemctl daemon-reload && systemctl enable --now docker**
2.k8s及etcd安装
以下在master01上执行
1.下载kubernetes安装包
wget [https://dl.k8s.io/v1.23.5/kubernetes-server-linux-amd64.tar.gz](https://dl.k8s.io/v1.23.5/kubernetes-server-linux-amd64.tar.gz)
2.下载etcd安装包
wget https://github.com/etcd-io/etcd/releases/download/v3.5.2/etcd-v3.5.2-linux-amd64.tar.gz
3.解压kubernetes安装文件
**tar -xf kubernetes-server-linux-amd64.tar.gz --strip-components=3 -C /usr/local/bin kubernetes/server/bin/kube{let,ctl,-apiserver,-controller-manager,-scheduler,-proxy}**
4.解压etcd安装文件
**tar -zxvf etcd-v3.5.2-linux-amd64.tar.gz --strip-components=1 -C /usr/local/bin etcd-v3.5.2-linux-amd64/etcd{,ctl}**
5.版本查看
kubelet --versionetcdctl version
6.将组件发送到其他节点
for NODE in k8s-master02 k8s-master03; do echo $NODE; scp /usr/local/bin/kube{let,ctl,-apiserver,-controller-manager,-scheduler,-proxy} $NODE:/usr/local/bin/; scp /usr/local/bin/etcd* $NODE:/usr/local/bin/; donefor NODE in k8s-node01 k8s-node02; do scp /usr/local/bin/kube{let,-proxy} $NODE:/usr/local/bin/ ; done
所有节点创建/opt/cni/bin目录
mkdir -p /opt/cni/bin
切换分支
Master01切换到1.23.x分支(其他版本可以切换到其他分支)
cd k8s-ha-install && git checkout manual-installation-v1.23.x
2.3生成证书
二进制安装最关键步骤,一步错误全盘皆输,一定要注意每个步骤都要是正确的
1.Master01下载生成证书工具
wget “https://pkg.cfssl.org/R1.2/cfssl_linux-amd64“ -O /usr/local/bin/cfssl
wget “https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64“ -O /usr/local/bin/cfssljson
chmod +x /usr/local/bin/cfssl /usr/local/bin/cfssljson
2.etcd证书
所有Master节点创建etcd证书目录
mkdir /etc/etcd/ssl -p
所有节点创建kubernetes相关目录
mkdir -p /etc/kubernetes/pki
Master01节点生成etcd证书
生成证书的CSR文件:证书签名请求文件,配置了一些域名、公司、单位
cd /root/k8s-ha-install/pki
# 生成etcd CA证书和CA证书的key
cfssl gencert -initca etcd-ca-csr.json | cfssljson -bare /etc/etcd/ssl/etcd-ca
cfssl gencert \-ca=/etc/etcd/ssl/etcd-ca.pem \-ca-key=/etc/etcd/ssl/etcd-ca-key.pem \-config=ca-config.json \-hostname=127.0.0.1,k8s-master01,k8s-master02,k8s-master03,192.168.68.50,192.168.68.51,192.168.68.52 \-profile=kubernetes \etcd-csr.json | cfssljson -bare /etc/etcd/ssl/etcd执行结果2022/04/08 07:09:20 [INFO] generate received request2022/04/08 07:09:20 [INFO] received CSR2022/04/08 07:09:20 [INFO] generating key: rsa-20482022/04/08 07:09:21 [INFO] encoded CSR2022/04/08 07:09:21 [INFO] signed certificate with serial number 728982787326070968690424877239840705408470785677
将证书复制到其他节点
MasterNodes=’k8s-master02 k8s-master03’
for NODE in k8s-master02 k8s-master03; do
ssh $NODE “mkdir -p /etc/etcd/ssl”
for FILE in etcd-ca-key.pem etcd-ca.pem etcd-key.pem etcd.pem; do
scp /etc/etcd/ssl/${FILE} $NODE:/etc/etcd/ssl/${FILE}
done
done
3.k8s组件证书
Master01生成kubernetes证书
cd /root/k8s-ha-install/pki
cfssl gencert -initca ca-csr.json | cfssljson -bare /etc/kubernetes/pki/ca
10.96.0.是k8s service的网段,如果说需要更改k8s service网段,那就需要更改10.96.0.1,
# 如果不是高可用集群,192.168.68.48为Master01的IP
cfssl gencert -ca=/etc/kubernetes/pki/ca.pem -ca-key=/etc/kubernetes/pki/ca-key.pem -config=ca-config.json -hostname=10.96.0.1,192.168.68.48,127.0.0.1,kubernetes,kubernetes.default,kubernetes.default.svc,kubernetes.default.svc.cluster,kubernetes.default.svc.cluster.local,192.168.68.50,192.168.68.51,192.168.68.52 -profile=kubernetes apiserver-csr.json | cfssljson -bare /etc/kubernetes/pki/apiserver
生成apiserver的聚合证书。Requestheader-client-xxx requestheader-allowwd-xxx:aggerator
cfssl gencert -initca front-proxy-ca-csr.json | cfssljson -bare /etc/kubernetes/pki/front-proxy-ca
cfssl gencert -ca=/etc/kubernetes/pki/front-proxy-ca.pem -ca-key=/etc/kubernetes/pki/front-proxy-ca-key.pem -config=ca-config.json -profile=kubernetes front-proxy-client-csr.json | cfssljson -bare /etc/kubernetes/pki/front-proxy-client
返回结果(忽略警告)
2022/04/08 07:26:57 [INFO] generate received request
2022/04/08 07:26:57 [INFO] received CSR
2022/04/08 07:26:57 [INFO] generating key: rsa-2048
2022/04/08 07:26:58 [INFO] encoded CSR
2022/04/08 07:26:58 [INFO] signed certificate with serial number 429580583316239045765562931851686133793149712576
2022/04/08 07:26:58 [WARNING] This certificate lacks a “hosts” field. This makes it unsuitable for
websites. For more information see the Baseline Requirements for the Issuance and Management
of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org);
specifically, section 10.2.3 (“Information Requirements”).
生成controller-manage的证书
cfssl gencert \
-ca=/etc/kubernetes/pki/ca.pem \
-ca-key=/etc/kubernetes/pki/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
manager-csr.json | cfssljson -bare /etc/kubernetes/pki/controller-manager
# 注意,如果不是高可用集群,192.168.68.48:8443改为master01的地址,8443改为apiserver的端口,默认是6443
# set-cluster:设置一个集群项,
kubectl config set-cluster kubernetes \
—certificate-authority=/etc/kubernetes/pki/ca.pem \
—embed-certs=true \
—server=https://192.168.68.48:8443 \
—kubeconfig=/etc/kubernetes/controller-manager.kubeconfig
# set-credentials 设置一个用户项
kubectl config set-credentials system:kube-controller-manager \
—client-certificate=/etc/kubernetes/pki/controller-manager.pem \
—client-key=/etc/kubernetes/pki/controller-manager-key.pem \
—embed-certs=true \
—kubeconfig=/etc/kubernetes/controller-manager.kubeconfig
# 设置一个环境项,一个上下文
kubectl config set-context system:kube-controller-manager@kubernetes \
—cluster=kubernetes \
—user=system:kube-controller-manager \
—kubeconfig=/etc/kubernetes/controller-manager.kubeconfig
# 使用某个环境当做默认环境
kubectl config use-context system:kube-controller-manager@kubernetes \
—kubeconfig=/etc/kubernetes/controller-manager.kubeconfig
cfssl gencert \
-ca=/etc/kubernetes/pki/ca.pem \
-ca-key=/etc/kubernetes/pki/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
scheduler-csr.json | cfssljson -bare /etc/kubernetes/pki/scheduler
# 注意,如果不是高可用集群,192.168.68.48:8443改为master01的地址,8443改为apiserver的端口,默认是6443
kubectl config set-cluster kubernetes \
—certificate-authority=/etc/kubernetes/pki/ca.pem \
—embed-certs=true \
—server=https://192.168.68.48:8443 \
—kubeconfig=/etc/kubernetes/scheduler.kubeconfig
kubectl config set-credentials system:kube-scheduler \
—client-certificate=/etc/kubernetes/pki/scheduler.pem \
—client-key=/etc/kubernetes/pki/scheduler-key.pem \
—embed-certs=true \
—kubeconfig=/etc/kubernetes/scheduler.kubeconfig
kubectl config set-context system:kube-scheduler@kubernetes \
—cluster=kubernetes \
—user=system:kube-scheduler \
—kubeconfig=/etc/kubernetes/scheduler.kubeconfig
kubectl config use-context system:kube-scheduler@kubernetes \
—kubeconfig=/etc/kubernetes/scheduler.kubeconfig
cfssl gencert \
-ca=/etc/kubernetes/pki/ca.pem \
-ca-key=/etc/kubernetes/pki/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
admin-csr.json | cfssljson -bare /etc/kubernetes/pki/admin
# 注意,如果不是高可用集群,192.168.68.48:8443改为master01的地址,8443改为apiserver的端口,默认是6443
kubectl config set-cluster kubernetes —certificate-authority=/etc/kubernetes/pki/ca.pem —embed-certs=true —server=https://192.168.68.48:8443 —kubeconfig=/etc/kubernetes/admin.kubeconfig
kubectl config set-credentials kubernetes-admin —client-certificate=/etc/kubernetes/pki/admin.pem —client-key=/etc/kubernetes/pki/admin-key.pem —embed-certs=true —kubeconfig=/etc/kubernetes/admin.kubeconfig
kubectl config set-context kubernetes-admin@kubernetes —cluster=kubernetes —user=kubernetes-admin —kubeconfig=/etc/kubernetes/admin.kubeconfig
kubectl config use-context kubernetes-admin@kubernetes —kubeconfig=/etc/kubernetes/admin.kubeconfig
创建ServiceAccount Key à secret
openssl genrsa -out /etc/kubernetes/pki/sa.key 2048
返回结果
Generating RSA private key, 2048 bit long modulus (2 primes)
……………………………+++++
……………………………………………………………………………………………..+++++
e is 65537 (0x010001)
openssl rsa -in /etc/kubernetes/pki/sa.key -pubout -out /etc/kubernetes/pki/sa.pub
发送证书至其他节点
for NODE in k8s-master02 k8s-master03; do for FILE in $(ls /etc/kubernetes/pki | grep -v etcd); do scp /etc/kubernetes/pki/${FILE} $NODE:/etc/kubernetes/pki/${FILE};done; for FILE in admin.kubeconfig controller-manager.kubeconfig scheduler.kubeconfig; do scp /etc/kubernetes/${FILE} $NODE:/etc/kubernetes/${FILE};done;done**
查看证书文件
[root@k8s-master01 pki]# ls /etc/kubernetes/pki/
admin.csr apiserver.csr ca.csr controller-manager.csr front-proxy-ca.csr front-proxy-client.csr sa.key scheduler-key.pem
admin-key.pem apiserver-key.pem ca-key.pem controller-manager-key.pem front-proxy-ca-key.pem front-proxy-client-key.pem sa.pub scheduler.pem
admin.pem apiserver.pem ca.pem controller-manager.pem front-proxy-ca.pem front-proxy-client.pem scheduler.csr
[root@k8s-master01 pki]# ls /etc/kubernetes/pki/ |wc -l
23
2.4高可用及etcd配置
1.etcd配置
etcd配置大致相同,注意修改每个Master节点的etcd配置的主机名和IP地址
Master01
vim /etc/etcd/etcd.config.yml
name: 'k8s-master01'data-dir: /var/lib/etcdwal-dir: /var/lib/etcd/walsnapshot-count: 5000heartbeat-interval: 100election-timeout: 1000quota-backend-bytes: 0listen-peer-urls: 'https://192.168.68.50:2380'listen-client-urls: 'https://192.168.68.50:2379,http://127.0.0.1:2379'max-snapshots: 3max-wals: 5cors:initial-advertise-peer-urls: 'https://192.168.68.50:2380'advertise-client-urls: 'https://192.168.68.50:2379'discovery:discovery-fallback: 'proxy'discovery-proxy:discovery-srv:initial-cluster: 'k8s-master01=https://192.168.68.50:2380,k8s-master02=https://192.168.68.51:2380,k8s-master03=https://192.168.68.52:2380'initial-cluster-token: 'etcd-k8s-cluster'initial-cluster-state: 'new'strict-reconfig-check: falseenable-v2: trueenable-pprof: trueproxy: 'off'proxy-failure-wait: 5000proxy-refresh-interval: 30000proxy-dial-timeout: 1000proxy-write-timeout: 5000proxy-read-timeout: 0client-transport-security:cert-file: '/etc/kubernetes/pki/etcd/etcd.pem'key-file: '/etc/kubernetes/pki/etcd/etcd-key.pem'client-cert-auth: truetrusted-ca-file: '/etc/kubernetes/pki/etcd/etcd-ca.pem'auto-tls: truepeer-transport-security:cert-file: '/etc/kubernetes/pki/etcd/etcd.pem'key-file: '/etc/kubernetes/pki/etcd/etcd-key.pem'peer-client-cert-auth: truetrusted-ca-file: '/etc/kubernetes/pki/etcd/etcd-ca.pem'auto-tls: truedebug: falselog-package-levels:log-outputs: [default]force-new-cluster: false
Master02
vim /etc/etcd/etcd.config.yml
name: 'k8s-master02'data-dir: /var/lib/etcdwal-dir: /var/lib/etcd/walsnapshot-count: 5000heartbeat-interval: 100election-timeout: 1000quota-backend-bytes: 0listen-peer-urls: 'https://192.168.68.51:2380'listen-client-urls: 'https://192.168.68.51:2379,http://127.0.0.1:2379'max-snapshots: 3max-wals: 5cors:initial-advertise-peer-urls: 'https://192.168.68.51:2380'advertise-client-urls: 'https://192.168.68.51:2379'discovery:discovery-fallback: 'proxy'discovery-proxy:discovery-srv:initial-cluster: 'k8s-master01=https://192.168.68.50:2380,k8s-master02=https://192.168.68.51:2380,k8s-master03=https://192.168.68.52:2380'initial-cluster-token: 'etcd-k8s-cluster'initial-cluster-state: 'new'strict-reconfig-check: falseenable-v2: trueenable-pprof: trueproxy: 'off'proxy-failure-wait: 5000proxy-refresh-interval: 30000proxy-dial-timeout: 1000proxy-write-timeout: 5000proxy-read-timeout: 0client-transport-security:cert-file: '/etc/kubernetes/pki/etcd/etcd.pem'key-file: '/etc/kubernetes/pki/etcd/etcd-key.pem'client-cert-auth: truetrusted-ca-file: '/etc/kubernetes/pki/etcd/etcd-ca.pem'auto-tls: truepeer-transport-security:cert-file: '/etc/kubernetes/pki/etcd/etcd.pem'key-file: '/etc/kubernetes/pki/etcd/etcd-key.pem'peer-client-cert-auth: truetrusted-ca-file: '/etc/kubernetes/pki/etcd/etcd-ca.pem'auto-tls: truedebug: falselog-package-levels:log-outputs: [default]force-new-cluster: false
Master03
vim /etc/etcd/etcd.config.yml
name: 'k8s-master03'data-dir: /var/lib/etcdwal-dir: /var/lib/etcd/walsnapshot-count: 5000heartbeat-interval: 100election-timeout: 1000quota-backend-bytes: 0listen-peer-urls: 'https://192.168.68.52:2380'listen-client-urls: 'https://192.168.68.52:2379,http://127.0.0.1:2379'max-snapshots: 3max-wals: 5cors:initial-advertise-peer-urls: 'https://192.168.68.52:2380'advertise-client-urls: 'https://192.168.68.52:2379'discovery:discovery-fallback: 'proxy'discovery-proxy:discovery-srv:initial-cluster: 'k8s-master01=https://192.168.68.50:2380,k8s-master02=https://192.168.68.51:2380,k8s-master03=https://192.168.68.52:2380'initial-cluster-token: 'etcd-k8s-cluster'initial-cluster-state: 'new'strict-reconfig-check: falseenable-v2: trueenable-pprof: trueproxy: 'off'proxy-failure-wait: 5000proxy-refresh-interval: 30000proxy-dial-timeout: 1000proxy-write-timeout: 5000proxy-read-timeout: 0client-transport-security:cert-file: '/etc/kubernetes/pki/etcd/etcd.pem'key-file: '/etc/kubernetes/pki/etcd/etcd-key.pem'client-cert-auth: truetrusted-ca-file: '/etc/kubernetes/pki/etcd/etcd-ca.pem'auto-tls: truepeer-transport-security:cert-file: '/etc/kubernetes/pki/etcd/etcd.pem'key-file: '/etc/kubernetes/pki/etcd/etcd-key.pem'peer-client-cert-auth: truetrusted-ca-file: '/etc/kubernetes/pki/etcd/etcd-ca.pem'auto-tls: truedebug: falselog-package-levels:log-outputs: [default]force-new-cluster: false
创建Service
所有Master节点创建etcd service并启动
vim /usr/lib/systemd/system/etcd.service
[Unit]Description=Etcd ServiceDocumentation=https://coreos.com/etcd/docs/latest/After=network.target[Service]Type=notifyExecStart=/usr/local/bin/etcd --config-file=/etc/etcd/etcd.config.ymlRestart=on-failureRestartSec=10LimitNOFILE=65536[Install]WantedBy=multi-user.targetAlias=etcd3.service
所有Master节点创建etcd的证书目录
mkdir /etc/kubernetes/pki/etcd
ln -s /etc/etcd/ssl/* /etc/kubernetes/pki/etcd/
systemctl daemon-reload
systemctl enable —now etcd
启动异常
Job for etcd.service failed because the control process exited with error code.
See “systemctl status etcd.service” and “journalctl -xe” for details.
~ # journalctl -xe 1 ↵ root@k8s-master02Apr 09 08:24:08 k8s-master02 multipathd[707]: sda: failed to get sysfs uid: Invalid argumentApr 09 08:24:08 k8s-master02 multipathd[707]: sda: failed to get sgio uid: No such file or directoryApr 09 08:24:12 k8s-master02 systemd[1]: etcd.service: Scheduled restart job, restart counter is at 3989.-- Subject: Automatic restarting of a unit has been scheduled-- Defined-By: systemd-- Support: http://www.ubuntu.com/support---- Automatic restarting of the unit etcd.service has been scheduled, as the result for-- the configured Restart= setting for the unit.Apr 09 08:24:12 k8s-master02 systemd[1]: Stopped Etcd Service.-- Subject: A stop job for unit etcd.service has finished-- Defined-By: systemd-- Support: http://www.ubuntu.com/support---- A stop job for unit etcd.service has finished.---- The job identifier is 308572 and the job result is done.Apr 09 08:24:12 k8s-master02 systemd[1]: Starting Etcd Service...-- Subject: A start job for unit etcd.service has begun execution-- Defined-By: systemd-- Support: http://www.ubuntu.com/support---- A start job for unit etcd.service has begun execution.---- The job identifier is 308572.Apr 09 08:24:12 k8s-master02 etcd[109903]: {"level":"info","ts":"2022-04-09T08:24:12.320+0800","caller":"etcdmain/config.go:339","msg":"loaded server configuration, other configuration command line flags a>Apr 09 08:24:12 k8s-master02 etcd[109903]: {"level":"info","ts":"2022-04-09T08:24:12.321+0800","caller":"etcdmain/etcd.go:72","msg":"Running: ","args":["/usr/local/bin/etcd","--config-file=/etc/etcd/etcd.c>Apr 09 08:24:12 k8s-master02 etcd[109903]: {"level":"info","ts":"2022-04-09T08:24:12.321+0800","caller":"embed/etcd.go:131","msg":"configuring peer listeners","listen-peer-urls":["https://192.168.68.51:238>Apr 09 08:24:12 k8s-master02 etcd[109903]: {"level":"info","ts":"2022-04-09T08:24:12.321+0800","caller":"embed/etcd.go:368","msg":"closing etcd server","name":"k8s-master02","data-dir":"/var/lib/etcd","adv>Apr 09 08:24:12 k8s-master02 etcd[109903]: {"level":"info","ts":"2022-04-09T08:24:12.321+0800","caller":"embed/etcd.go:370","msg":"closed etcd server","name":"k8s-master02","data-dir":"/var/lib/etcd","adve>Apr 09 08:24:12 k8s-master02 etcd[109903]: {"level":"warn","ts":"2022-04-09T08:24:12.321+0800","caller":"etcdmain/etcd.go:145","msg":"failed to start etcd","error":"cannot listen on TLS for 192.168.68.51:2>Apr 09 08:24:12 k8s-master02 etcd[109903]: {"level":"fatal","ts":"2022-04-09T08:24:12.321+0800","caller":"etcdmain/etcd.go:203","msg":"discovery failed","error":"cannot listen on TLS for 192.168.68.51:2380>Apr 09 08:24:12 k8s-master02 systemd[1]: etcd.service: Main process exited, code=exited, status=1/FAILURE-- Subject: Unit process exited-- Defined-By: systemd-- Support: http://www.ubuntu.com/support---- An ExecStart= process belonging to unit etcd.service has exited.---- The process' exit code is 'exited' and its exit status is 1.Apr 09 08:24:12 k8s-master02 systemd[1]: etcd.service: Failed with result 'exit-code'.-- Subject: Unit failed-- Defined-By: systemd-- Support: http://www.ubuntu.com/support---- The unit etcd.service has entered the 'failed' state with result 'exit-code'.Apr 09 08:24:12 k8s-master02 systemd[1]: Failed to start Etcd Service.-- Subject: A start job for unit etcd.service has failed-- Defined-By: systemd-- Support: http://www.ubuntu.com/support---- A start job for unit etcd.service has finished with a failure.---- The job identifier is 308572 and the job result is failed.Apr 09 08:24:13 k8s-master02 multipathd[707]: sda: add missing pathApr 09 08:24:13 k8s-master02 multipathd[707]: sda: failed to get udev uid: Invalid argumentApr 09 08:24:13 k8s-master02 multipathd[707]: sda: failed to get sysfs uid: Invalid argumentApr 09 08:24:13 k8s-master02 multipathd[707]: sda: failed to get sgio uid: No such file or directory
1.修改/etc/multipath.conf文件
sudo vi /etc/multipath.conf
2.添加以下内容,sda视本地环境做调整
blacklist {
devnode “^sda”
}
3.重启multipath-tools服务
sudo service multipath-tools restart
[
](https://blog.csdn.net/zhangchenbin/article/details/117886448)
查看etcd状态
export ETCDCTL_API=3
etcdctl —endpoints=”192.168.68.50:2379,192.168.68.51:2379,192.168.68.52:2379” —cacert=/etc/kubernetes/pki/etcd/etcd-ca.pem —cert=/etc/kubernetes/pki/etcd/etcd.pem —key=/etc/kubernetes/pki/etcd/etcd-key.pem endpoint status —write-out=table
2.高可用配置
高可用配置(注意:如果不是高可用集群,haproxy和keepalived无需安装)
如果在云上安装也无需执行此章节的步骤,可以直接使用云上的lb,比如阿里云slb,腾讯云elb等
公有云要用公有云自带的负载均衡,比如阿里云的SLB,腾讯云的ELB,用来替代haproxy和keepalived,因为公有云大部分都是不支持keepalived的,另外如果用阿里云的话,kubectl控制端不能放在master节点,推荐使用腾讯云,因为阿里云的slb有回环的问题,也就是slb代理的服务器不能反向访问SLB,但是腾讯云修复了这个问题。
Slb -> haproxy -> apiserver
所有Master节点安装keepalived和haproxy
apt install keepalived haproxy -y
所有Master配置HAProxy,配置一样
vim /etc/haproxy/haproxy.cfg
globalmaxconn 2000ulimit-n 16384log 127.0.0.1 local0 errstats timeout 30sdefaultslog globalmode httpoption httplogtimeout connect 5000timeout client 50000timeout server 50000timeout http-request 15stimeout http-keep-alive 15sfrontend k8s-masterbind 0.0.0.0:8443bind 127.0.0.1:8443mode tcpoption tcplogtcp-request inspect-delay 5sdefault_backend k8s-masterbackend k8s-mastermode tcpoption tcplogoption tcp-checkbalance roundrobindefault-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100server k8s-master01 192.168.68.50:6443 checkserver k8s-master02 192.168.68.51:6443 checkserver k8s-master03 192.168.68.52:6443 check
Master01 keepalived
所有Master节点配置KeepAlived,配置不一样,注意区分 [root@k8s-master01 pki]# vim /etc/keepalived/keepalived.conf ,注意每个节点的IP和网卡(interface参数)
! Configuration File for keepalivedglobal_defs {router_id LVS_DEVEL}vrrp_script chk_apiserver {script "/etc/keepalived/check_apiserver.sh"interval 5weight -5fall 2rise 1}vrrp_instance VI_1 {state MASTERinterface ens33mcast_src_ip 192.168.68.50virtual_router_id 51priority 101nopreemptadvert_int 2authentication {auth_type PASSauth_pass K8SHA_KA_AUTH}virtual_ipaddress {192.168.68.48}track_script {chk_apiserver} }
Master02 keepalived
! Configuration File for keepalivedglobal_defs {router_id LVS_DEVEL}vrrp_script chk_apiserver {script "/etc/keepalived/check_apiserver.sh"interval 5weight -5fall 2rise 1}vrrp_instance VI_1 {state BACKUPinterface ens33mcast_src_ip 192.168.68.51virtual_router_id 51priority 100nopreemptadvert_int 2authentication {auth_type PASSauth_pass K8SHA_KA_AUTH}virtual_ipaddress {192.168.68.48}track_script {chk_apiserver} }
Master03 keepalived
! Configuration File for keepalivedglobal_defs {router_id LVS_DEVEL}vrrp_script chk_apiserver {script "/etc/keepalived/check_apiserver.sh"interval 5weight -5fall 2rise 1}vrrp_instance VI_1 {state BACKUPinterface ens33mcast_src_ip 192.168.68.52virtual_router_id 51priority 100nopreemptadvert_int 2authentication {auth_type PASSauth_pass K8SHA_KA_AUTH}virtual_ipaddress {192.168.68.48}track_script {chk_apiserver} }
健康检查配置
所有master节点
[root@k8s-master01 keepalived]# cat /etc/keepalived/check_apiserver.sh
#!/bin/basherr=0for k in $(seq 1 3)docheck_code=$(pgrep haproxy)if [[ $check_code == "" ]]; thenerr=$(expr $err + 1)sleep 1continueelseerr=0breakfidoneif [[ $err != "0" ]]; thenecho "systemctl stop keepalived"/usr/bin/systemctl stop keepalivedexit 1elseexit 0fi
chmod +x /etc/keepalived/check_apiserver.sh
所有master节点启动haproxy和keepalived
[root@k8s-master01 keepalived]# systemctl daemon-reload
[root@k8s-master01 keepalived]# systemctl enable —now haproxy
[root@k8s-master01 keepalived]# systemctl enable —now keepalived
VIP测试
[root@k8s-master01 pki]# ping 192.168.68.48
PING 192.168.0.236 (192.168.0.236) 56(84) bytes of data.
64 bytes from 192.168.0.236: icmp_seq=1 ttl=64 time=1.39 ms
64 bytes from 192.168.0.236: icmp_seq=2 ttl=64 time=2.46 ms
64 bytes from 192.168.0.236: icmp_seq=3 ttl=64 time=1.68 ms
64 bytes from 192.168.0.236: icmp_seq=4 ttl=64 time=1.08 ms
重要:如果安装了keepalived和haproxy,需要测试keepalived是否是正常的
telnet 192.168.68.48 8443
如果ping不通且telnet没有出现 ],则认为VIP不可以,不可在继续往下执行,需要排查keepalived的问题,比如防火墙和selinux,haproxy和keepalived的状态,监听端口等
所有节点查看防火墙状态必须为disable和inactive:systemctl status firewalld
所有节点查看selinux状态,必须为disable:getenforce
master节点查看haproxy和keepalived状态:systemctl status keepalived haproxy
master节点查看监听端口:netstat -lntp
2.5k8s组件配置
1.Apiserver
所有Master节点创建kube-apiserver service,# 注意,如果不是高可用集群,192.168.0.236改为master01的地址
Master01配置
注意本文档使用的k8s service网段为10.96.0.0/12,该网段不能和宿主机的网段、Pod网段的重复,请按需修改
[root@k8s-master01 pki]# cat /usr/lib/systemd/system/kube-apiserver.service
[Unit]Description=Kubernetes API ServerDocumentation=https://github.com/kubernetes/kubernetesAfter=network.target[Service]ExecStart=/usr/local/bin/kube-apiserver \--v=2 \--logtostderr=true \--allow-privileged=true \--bind-address=0.0.0.0 \--secure-port=6443 \--insecure-port=0 \--advertise-address=192.168.68.50 \--service-cluster-ip-range=10.96.0.0/12 \--service-node-port-range=30000-32767 \--etcd-servers=https://192.168.68.50:2379,https://192.168.68.51:2379,https://192.168.68.52:2379 \--etcd-cafile=/etc/etcd/ssl/etcd-ca.pem \--etcd-certfile=/etc/etcd/ssl/etcd.pem \--etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \--client-ca-file=/etc/kubernetes/pki/ca.pem \--tls-cert-file=/etc/kubernetes/pki/apiserver.pem \--tls-private-key-file=/etc/kubernetes/pki/apiserver-key.pem \--kubelet-client-certificate=/etc/kubernetes/pki/apiserver.pem \--kubelet-client-key=/etc/kubernetes/pki/apiserver-key.pem \--service-account-key-file=/etc/kubernetes/pki/sa.pub \--service-account-signing-key-file=/etc/kubernetes/pki/sa.key \--service-account-issuer=https://kubernetes.default.svc.cluster.local \--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \--authorization-mode=Node,RBAC \--enable-bootstrap-token-auth=true \--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \--requestheader-allowed-names=aggregator \--requestheader-group-headers=X-Remote-Group \--requestheader-extra-headers-prefix=X-Remote-Extra- \--requestheader-username-headers=X-Remote-User# --token-auth-file=/etc/kubernetes/token.csvRestart=on-failureRestartSec=10sLimitNOFILE=65535[Install]WantedBy=multi-user.target
Master02配置
注意本文档使用的k8s service网段为10.96.0.0/12,该网段不能和宿主机的网段、Pod网段的重复,请按需修改
[root@k8s-master01 pki]# cat /usr/lib/systemd/system/kube-apiserver.service
[Unit]Description=Kubernetes API ServerDocumentation=https://github.com/kubernetes/kubernetesAfter=network.target[Service]ExecStart=/usr/local/bin/kube-apiserver \--v=2 \--logtostderr=true \--allow-privileged=true \--bind-address=0.0.0.0 \--secure-port=6443 \--insecure-port=0 \--advertise-address=192.168.68.51 \--service-cluster-ip-range=10.96.0.0/12 \--service-node-port-range=30000-32767 \--etcd-servers=https://192.168.68.50:2379,https://192.168.68.51:2379,https://192.168.68.52:2379 \--etcd-cafile=/etc/etcd/ssl/etcd-ca.pem \--etcd-certfile=/etc/etcd/ssl/etcd.pem \--etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \--client-ca-file=/etc/kubernetes/pki/ca.pem \--tls-cert-file=/etc/kubernetes/pki/apiserver.pem \--tls-private-key-file=/etc/kubernetes/pki/apiserver-key.pem \--kubelet-client-certificate=/etc/kubernetes/pki/apiserver.pem \--kubelet-client-key=/etc/kubernetes/pki/apiserver-key.pem \--service-account-key-file=/etc/kubernetes/pki/sa.pub \--service-account-signing-key-file=/etc/kubernetes/pki/sa.key \--service-account-issuer=https://kubernetes.default.svc.cluster.local \--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \--authorization-mode=Node,RBAC \--enable-bootstrap-token-auth=true \--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \--requestheader-allowed-names=aggregator \--requestheader-group-headers=X-Remote-Group \--requestheader-extra-headers-prefix=X-Remote-Extra- \--requestheader-username-headers=X-Remote-User# --token-auth-file=/etc/kubernetes/token.csvRestart=on-failureRestartSec=10sLimitNOFILE=65535[Install]WantedBy=multi-user.target
Master03配置
注意本文档使用的k8s service网段为10.96.0.0/12,该网段不能和宿主机的网段、Pod网段的重复,请按需修改
cat /usr/lib/systemd/system/kube-apiserver.service
[Unit]Description=Kubernetes API ServerDocumentation=https://github.com/kubernetes/kubernetesAfter=network.target[Service]ExecStart=/usr/local/bin/kube-apiserver \--v=2 \--logtostderr=true \--allow-privileged=true \--bind-address=0.0.0.0 \--secure-port=6443 \--insecure-port=0 \--advertise-address=192.168.68.52 \--service-cluster-ip-range=10.96.0.0/12 \--service-node-port-range=30000-32767 \--etcd-servers=https://192.168.68.50:2379,https://192.168.68.51:2379,https://192.168.68.52:2379 \--etcd-cafile=/etc/etcd/ssl/etcd-ca.pem \--etcd-certfile=/etc/etcd/ssl/etcd.pem \--etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \--client-ca-file=/etc/kubernetes/pki/ca.pem \--tls-cert-file=/etc/kubernetes/pki/apiserver.pem \--tls-private-key-file=/etc/kubernetes/pki/apiserver-key.pem \--kubelet-client-certificate=/etc/kubernetes/pki/apiserver.pem \--kubelet-client-key=/etc/kubernetes/pki/apiserver-key.pem \--service-account-key-file=/etc/kubernetes/pki/sa.pub \--service-account-signing-key-file=/etc/kubernetes/pki/sa.key \--service-account-issuer=https://kubernetes.default.svc.cluster.local \--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \--authorization-mode=Node,RBAC \--enable-bootstrap-token-auth=true \--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \--requestheader-allowed-names=aggregator \--requestheader-group-headers=X-Remote-Group \--requestheader-extra-headers-prefix=X-Remote-Extra- \--requestheader-username-headers=X-Remote-User# --token-auth-file=/etc/kubernetes/token.csvRestart=on-failureRestartSec=10sLimitNOFILE=65535[Install]WantedBy=multi-user.target
启动apiserver
所有Master节点开启kube-apiserver
systemctl daemon-reload && systemctl enable —now kube-apiserver
检测kube-server状态
# systemctl status kube-apiserver
● kube-apiserver.service - Kubernetes API Server
Loaded: loaded (/usr/lib/systemd/system/kube-apiserver.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2020-08-22 21:26:49 CST; 26s ago
系统日志的这些提示可以忽略
Dec 11 20:51:15 k8s-master01 kube-apiserver: I1211 20:51:15.004739 7450 clientconn.go:948] ClientConn switching balancer to “pick_first”
Dec 11 20:51:15 k8s-master01 kube-apiserver: I1211 20:51:15.004843 7450 balancer_conn_wrappers.go:78] pickfirstBalancer: HandleSubConnStateChange: 0xc011bd4c80, {CONNECTING
Dec 11 20:51:15 k8s-master01 kube-apiserver: I1211 20:51:15.010725 7450 balancer_conn_wrappers.go:78] pickfirstBalancer: HandleSubConnStateChange: 0xc011bd4c80, {READY
Dec 11 20:51:15 k8s-master01 kube-apiserver: I1211 20:51:15.011370 7450 controlbuf.go:508] transport: loopyWriter.run returning. connection error: desc = “transport is closing”
2. ControllerManager
所有Master节点配置kube-controller-manager service
注意本文档使用的k8s Pod网段为172.16.0.0/12,该网段不能和宿主机的网段、k8s Service网段的重复,请按需修改
[root@k8s-master01 pki]# cat /usr/lib/systemd/system/kube-controller-manager.service
[Unit]Description=Kubernetes Controller ManagerDocumentation=https://github.com/kubernetes/kubernetesAfter=network.target[Service]ExecStart=/usr/local/bin/kube-controller-manager \--v=2 \--logtostderr=true \--address=127.0.0.1 \--root-ca-file=/etc/kubernetes/pki/ca.pem \--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \--service-account-private-key-file=/etc/kubernetes/pki/sa.key \--kubeconfig=/etc/kubernetes/controller-manager.kubeconfig \--leader-elect=true \--use-service-account-credentials=true \--node-monitor-grace-period=40s \--node-monitor-period=5s \--pod-eviction-timeout=2m0s \--controllers=*,bootstrapsigner,tokencleaner \--allocate-node-cidrs=true \--cluster-cidr=172.16.0.0/12 \--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \--node-cidr-mask-size=24Restart=alwaysRestartSec=10s[Install]WantedBy=multi-user.target
所有Master节点启动kube-controller-manager
[root@k8s-master01 pki]# systemctl daemon-reload
[root@k8s-master01 pki]# systemctl enable —now kube-controller-manager
Created symlink /etc/systemd/system/multi-user.target.wants/kube-controller-manager.service → /usr/lib/systemd/system/kube-controller-manager.service.
查看启动状态
[root@k8s-master01 pki]# systemctl enable —now kube-controller-manager
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-controller-manager.service to /usr/lib/systemd/system/kube-controller-manager.service.
[root@k8s-master01 pki]# systemctl status kube-controller-manager
● kube-controller-manager.service - Kubernetes Controller Manager
Loaded: loaded (/usr/lib/systemd/system/kube-controller-manager.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2020-12-11 20:53:05 CST; 8s ago
Docs: https://github.com/kubernetes/kubernetes
Main PID: 7518 (kube-controller)
3.Scheduler
所有Master节点配置kube-scheduler service
[root@k8s-master01 pki]# cat /usr/lib/systemd/system/kube-scheduler.service
[Unit]Description=Kubernetes SchedulerDocumentation=https://github.com/kubernetes/kubernetesAfter=network.target[Service]ExecStart=/usr/local/bin/kube-scheduler \--v=2 \--logtostderr=true \--address=127.0.0.1 \--leader-elect=true \--kubeconfig=/etc/kubernetes/scheduler.kubeconfigRestart=alwaysRestartSec=10s[Install]WantedBy=multi-user.target
[root@k8s-master01 pki]# systemctl daemon-reload
[root@k8s-master01 pki]# systemctl enable —now kube-scheduler
Created symlink /etc/systemd/system/multi-user.target.wants/kube-scheduler.service → /usr/lib/systemd/system/kube-scheduler.service.
2.6 TLS Bootstrapping自动颁发证书
2.7 二进制Node节点及Calico配置
2.8 二进制Metrics&Dashboard安装
2.9 二进制高可用集群可用性验证
2.10 生产环境k8s集群关键性配置
2.11Bootstrapping
1.Kubelet启动过程
2.CSR申请和证书颁发原理
3.证书自动续期原理_
二、K8S基础篇
1.必备Docker知识
2.基本概念
3.资源调度
4.服务发布入门
5.配置管理
三、K8S进阶篇
1.持久化存储入门
1.1 Volumes
容器的生命周期可能很短,会被频繁地创建和销毁。那么容器在销毁时,保存在容器中的数据也会被清除。这种结果对用户来说,在某些情况下是不乐意看到的。Container(容器)中的磁盘文件是短暂的,当容器崩溃时,kubelet会重新启动容器,但最初的文件将丢失,Container会以最干净的状态启动。为了持久化保存容器的数据,kubernetes引入了Volume的概念。
Volume是Pod中能够被多个容器访问的共享目录,它被定义在Pod上,然后被一个Pod里的多个容器挂载到具体的文件目录下,kubernetes通过Volume实现同一个Pod中不同容器之间的数据共享以及数据的持久化存储。Volume的生命容器不与Pod中单个容器的生命周期相关,当容器终止或者重启时,Volume中的数据也不会丢失。
一些需要持久化数据的程序才会用到Volumes,或者一些需要共享数据的容器需要volumes。
Redis-Cluster:nodes.conf
日志收集的需求:需要在应用程序的容器里面加一个sidecar,这个容器是一个收集日志的容器,比如filebeat,它通过volumes共享应用程序的日志文件目录。
Volumes:官方文档https://kubernetes.io/docs/concepts/storage/volumes/
Docker也有卷的概念,但是在Docker中卷只是磁盘上或另一个Container中的目录,其生命周期不受管理。虽然目前Docker已经提供了卷驱动程序,但是功能非常有限,从Docker 1.7版本开始,每个Container只允许一个卷驱动程序,并且无法将参数传递给卷。
另一方面,Kubernetes卷具有明确的生命周期,与使用它的Pod相同。因此,在Kubernetes中的卷可以比Pod中运行的任何Container都长,并且可以在Container重启或者销毁之后保留数据。Kubernetes支持多种类型的卷,Pod可以同时使用任意数量的卷。
kubernetes的Volume支持多种类型,比较常见的有下面几个:
- 简单存储:EmptyDir、HostPath、NFS
- 高级存储:PV、PVC
- 配置存储:ConfigMap、Secret
从本质上讲,卷只是一个目录,可能包含一些数据,Pod中的容器可以访问它。要使用卷Pod需要通过.spec.volumes字段指定为Pod提供的卷,以及使用.spec.containers.volumeMounts 字段指定卷挂载的目录。从容器中的进程可以看到由Docker镜像和卷组成的文件系统视图,卷无法挂载其他卷或具有到其他卷的硬链接,Pod中的每个Container必须独立指定每个卷的挂载位置。
1.1.1基本存储
1.1.1.1EmptyDir
EmptyDir是最基础的Volume类型,一个EmptyDir就是Host上的一个空目录。
EmptyDir是在Pod被分配到Node时创建的,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为kubernetes会自动分配一个目录,当Pod销毁时, EmptyDir中的数据也会被永久删除。一般emptyDir卷用于Pod中的不同Container共享数据。它可以被挂载到相同或不同的路径上。 EmptyDir用途如下:
- 临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留
- 一个容器需要从另一个容器中获取数据的目录(多容器共享目录)
默认情况下,emptyDir卷支持节点上的任何介质,可能是SSD、磁盘或网络存储,具体取决于自身的环境。可以将emptyDir.medium字段设置为Memory,让Kubernetes使用tmpfs(内存支持的文件系统),虽然tmpfs非常快,但是tmpfs在节点重启时,数据同样会被清除,并且设置的大小会被计入到Container的内存限制当中。
接下来,通过一个容器之间文件共享的案例来使用一下EmptyDir。
在一个Pod中准备两个容器nginx和busybox,然后声明一个Volume分别挂在到两个容器的目录中,然后nginx容器负责向Volume中写日志,busybox中通过命令将日志内容读到控制台。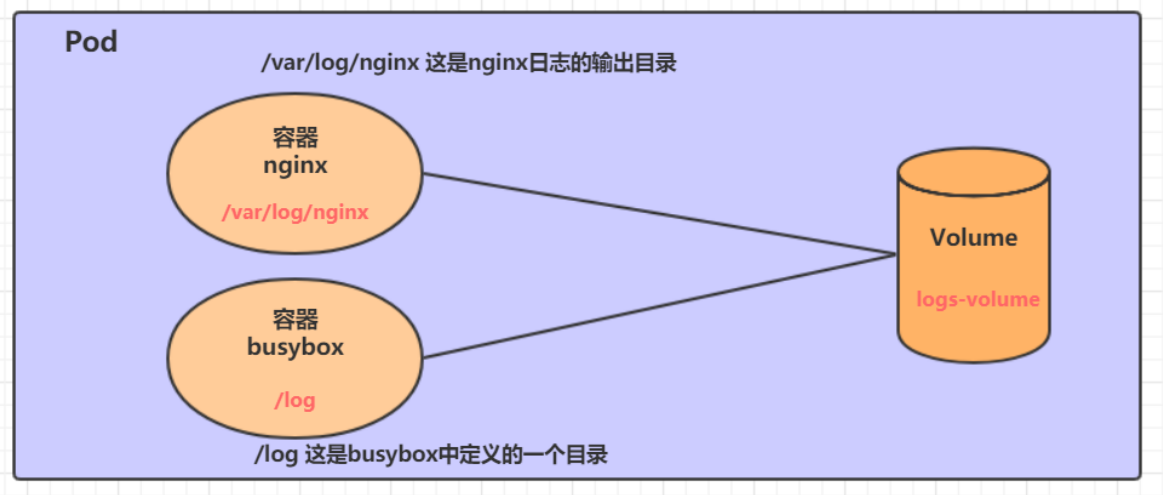
apiVersion: v1kind: Podmetadata:name: volume-emptydirnamespace: devspec:containers:- name: nginximage: nginx:1.17.1ports:- containerPort: 80volumeMounts: # 将logs-volume挂在到nginx容器中,对应的目录为 /var/log/nginx- name: logs-volumemountPath: /var/log/nginx- name: busyboximage: busybox:1.30command: ["/bin/sh","-c","tail -f /logs/access.log"] # 初始命令,动态读取指定文件中内容volumeMounts: # 将logs-volume 挂在到busybox容器中,对应的目录为 /logs- name: logs-volumemountPath: /logsvolumes: # 声明volume, name为logs-volume,类型为emptyDir- name: logs-volumeemptyDir: {}
# 创建Pod[root@k8s-master01 ~]# kubectl create -f volume-emptydir.yamlpod/volume-emptydir created# 查看pod[root@k8s-master01 ~]# kubectl get pods volume-emptydir -n dev -o wideNAME READY STATUS RESTARTS AGE IP NODE ......volume-emptydir 2/2 Running 0 97s 10.42.2.9 node1 ......# 通过podIp访问nginx[root@k8s-master01 ~]# curl 10.42.2.9......# 通过kubectl logs命令查看指定容器的标准输出[root@k8s-master01 ~]# kubectl logs -f volume-emptydir -n dev -c busybox10.42.1.0 - - [27/Jun/2021:15:08:54 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.29.0" "-"
使用emptyDir卷的示例,直接指定emptyDir为{}即可:
# cat nginx-deploy.yamlapiVersion: apps/v1kind: Deploymentmetadata:labels:app: nginxname: nginxnamespace: defaultspec:progressDeadlineSeconds: 600replicas: 2revisionHistoryLimit: 10selector:matchLabels:app: nginxstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:creationTimestamp: nulllabels:app: nginxspec:containers:- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginxresources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /optname: share-volume- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginx2command:- sh- -c- sleep 3600resources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /mntname: share-volumednsPolicy: ClusterFirstrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- name: share-volumeemptyDir: {}#medium: Memory
1.1.1.2HostPath
EmptyDir中数据不会被持久化,它会随着Pod的结束而销毁,如果想简单的将数据持久化到主机中,可以选择HostPath。
HostPath就是将Node主机中一个实际目录挂在到Pod中,以供容器使用,可以用于Pod自定义日志输出或访问Docker内部的容器等,这样的设计就可以保证Pod销毁了,但是数据依据可以存在于Node主机上。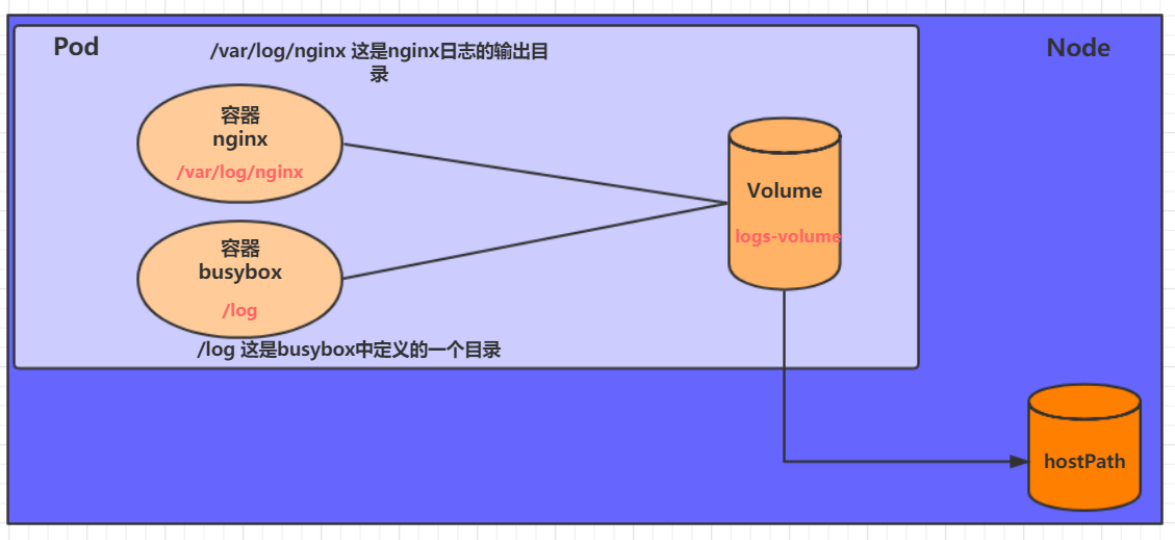
创建一个volume-hostpath.yaml:
apiVersion: v1kind: Podmetadata:name: volume-hostpathnamespace: devspec:containers:- name: nginximage: nginx:1.17.1ports:- containerPort: 80volumeMounts:- name: logs-volumemountPath: /var/log/nginx- name: busyboximage: busybox:1.30command: ["/bin/sh","-c","tail -f /logs/access.log"]volumeMounts:- name: logs-volumemountPath: /logsvolumes:- name: logs-volumehostPath:path: /root/logstype: DirectoryOrCreate # 目录存在就使用,不存在就先创建后使用
关于type的值的一点说明:type为空字符串:默认选项,意味着挂载hostPath卷之前不会执行任何检查。DirectoryOrCreate 如果给定的path不存在任何东西,那么将根据需要创建一个权限为0755的空目录,和Kubelet具有相同的组和权限。Directory 目录必须存在于给定的路径下。FileOrCreate 如果给定的路径不存储任何内容,则会根据需要创建一个空文件,权限设置为0644,和Kubelet具有相同的组和所有权。File 文件,必须存在于给定路径中。Socket UNIX套接字,必须存在于给定路径中。CharDevice 字符设备,必须存在于给定路径中。BlockDevice 块设备,必须存在于给定路径中。
# 创建Pod[root@k8s-master01 ~]# kubectl create -f volume-hostpath.yamlpod/volume-hostpath created# 查看Pod[root@k8s-master01 ~]# kubectl get pods volume-hostpath -n dev -o wideNAME READY STATUS RESTARTS AGE IP NODE ......pod-volume-hostpath 2/2 Running 0 16s 10.42.2.10 node1 ......#访问nginx[root@k8s-master01 ~]# curl 10.42.2.10[root@k8s-master01 ~]# kubectl logs -f volume-emptydir -n dev -c busybox# 接下来就可以去host的/root/logs目录下查看存储的文件了### 注意: 下面的操作需要到Pod所在的节点运行(案例中是node1)[root@node1 ~]# ls /root/logs/access.log error.log# 同样的道理,如果在此目录下创建一个文件,到容器中也是可以看到的
使用hostPath卷的示例。将主机的/data目录挂载到Pod的/test-pd目录:
# cat nginx-deploy.yamlapiVersion: apps/v1kind: Deploymentmetadata:labels:app: nginxname: nginxnamespace: defaultspec:progressDeadlineSeconds: 600replicas: 2revisionHistoryLimit: 10selector:matchLabels:app: nginxstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:creationTimestamp: nulllabels:app: nginxspec:containers:- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginxresources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /optname: share-volume- mountPath: /etc/timezonename: timezone- mountPath: /etc/localtimename: time-config- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginx2command:- sh- -c- sleep 3600resources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /mntname: share-volumednsPolicy: ClusterFirstrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- name: share-volumeemptyDir: {}#medium: Memory- name: timezonehostPath:path: /etc/timezonetype: File- name: timezone- name: time-config #同步宿主机时间hostPath:path: /usr/share/zoneinfo/Asia/Shanghaitype: File
1.1.1.3NFS
HostPath可以解决数据持久化的问题,但是一旦Node节点故障了,Pod如果转移到了别的节点,又会出现问题了,此时需要准备单独的网络存储系统,比较常用的用NFS、CIFS。
NFS是一个网络文件存储系统,可以搭建一台NFS服务器,然后将Pod中的存储直接连接到NFS系统上,这样的话,无论Pod在节点上怎么转移,只要Node跟NFS的对接没问题,数据就可以成功访问。
NFS生产环境不建议使用,无法保证高可用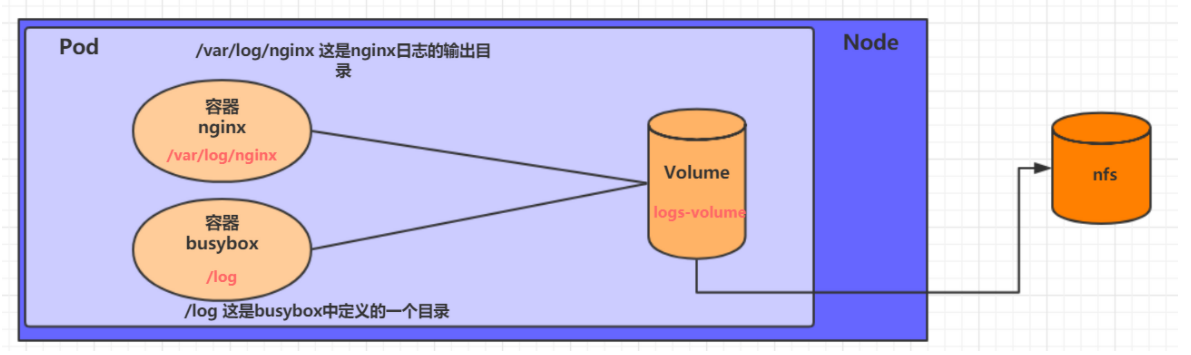
1.首先要准备nfs的服务器,这里为了简单,直接是master节点做nfs服务器
# 在nfs上安装nfs服务apt install nfs-kernel-server -y#启动nfssystemctl restart nfs-kernel-server.service#查看nfs支持的版本cat /proc/fs/nfsd/versions# 创建一个共享目录mkdir -p /data/nfs# 将共享目录以读写权限暴露给192.168.68.0/24网段中的所有主机vim /etc/exports/root/data/nfs 192.168.68.0/24(rw,no_root_squash,no_subtree_check)# 启动nfs服务exportfs -rsystemctl restart nfs-server
2.接下来,要在的每个node节点上都安装下nfs,这样的目的是为了node节点可以驱动nfs设备
# 在node上安装nfs服务,注意不需要启动apt install nfs-kernel-server -y#在其它机器上测试挂载mount -t nfs 192.168.68.115:/data/nfs /mnt
3.接下来,就可以编写pod的配置文件了,创建volume-nfs.yaml
apiVersion: v1kind: Podmetadata:name: volume-nfsnamespace: devspec:containers:- name: nginximage: nginx:1.17.1ports:- containerPort: 80volumeMounts:- name: logs-volumemountPath: /var/log/nginx- name: busyboximage: busybox:1.30command: ["/bin/sh","-c","tail -f /logs/access.log"]volumeMounts:- name: logs-volumemountPath: /logsvolumes:- name: logs-volumenfs:server: 192.168.68.115 #nfs服务器地址path: /data/nfs #共享文件路径
4.最后,运行下pod,观察结果
# 创建pod[root@k8s-master01 ~]# kubectl create -f volume-nfs.yamlpod/volume-nfs created# 查看pod[root@k8s-master01 ~]# kubectl get pods volume-nfs -n devNAME READY STATUS RESTARTS AGEvolume-nfs 2/2 Running 0 2m9s# 查看nfs服务器上的共享目录,发现已经有文件了[root@k8s-master01 ~]# ls /data/nfsaccess.log error.log
实验2:
创建nginx-deploy-nfs.yaml文件
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: nginxname: nginx-nfsnamespace: defaultspec:progressDeadlineSeconds: 600replicas: 2revisionHistoryLimit: 10selector:matchLabels:app: nginxstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:creationTimestamp: nulllabels:app: nginxspec:containers:- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginxresources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /optname: share-volume- mountPath: /etc/timezonename: timezone- mountPath: /etc/localtimename: time-config- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginx2command:- sh- -c- sleep 3600resources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /mntname: share-volume- mountPath: /var/log/nginxname: nfs-volumednsPolicy: ClusterFirstrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- name: share-volumeemptyDir: {}#medium: Memory- name: timezonehostPath:path: /etc/timezonetype: File- name: time-confighostPath:path: /usr/share/zoneinfo/Asia/Shanghaitype: File- name: nfs-volumenfs:server: 192.168.68.115path: /data/nfs/nginx-log
创建容器
kubectl create -f nginx-deploy-nfs.yaml
进入容器并创建一个123.txt文件
返回宿主机文件夹目录查看文件
1.1.2高级存储
Volumes无法满足需求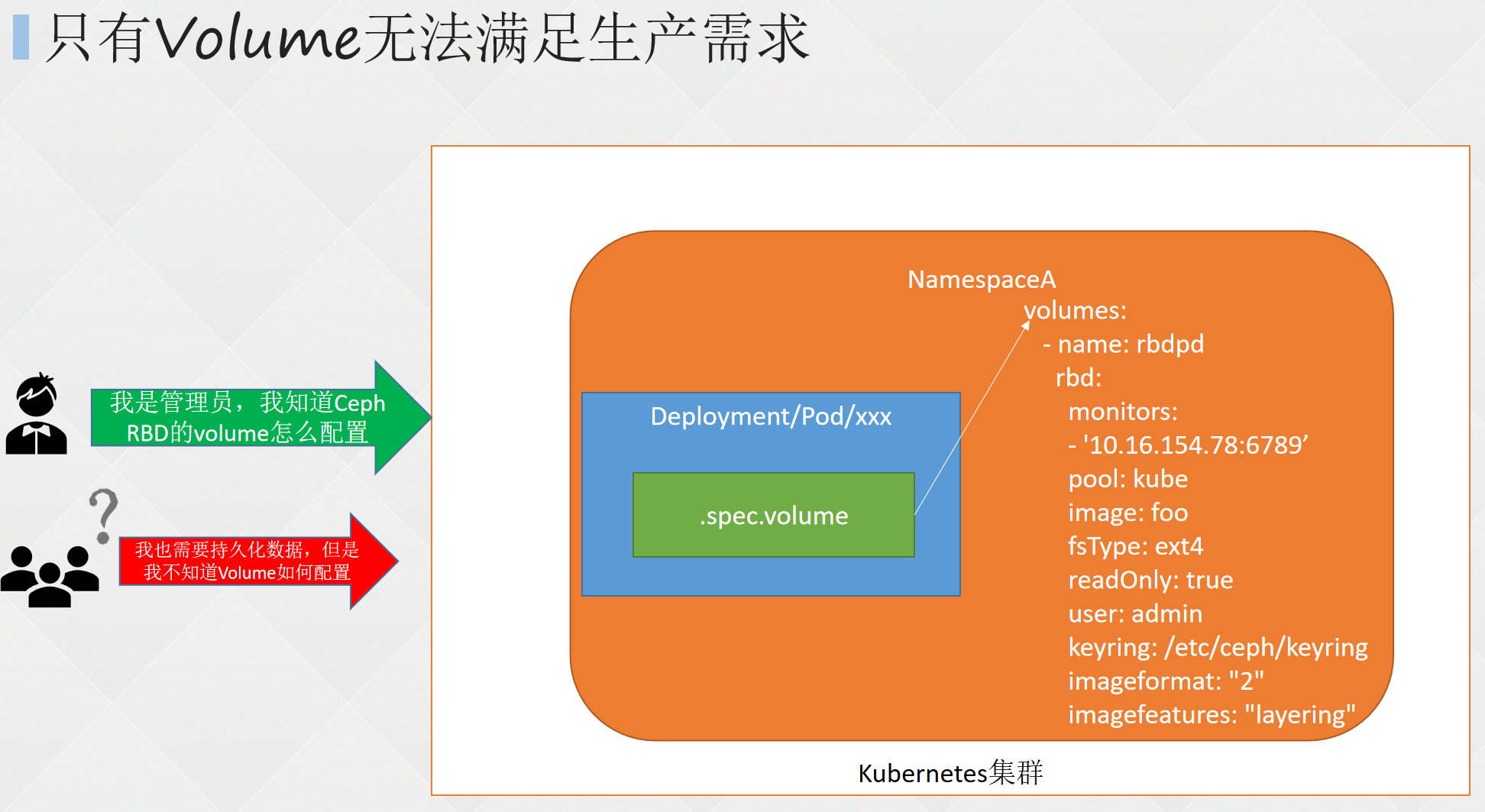
Volume无法解决的问题:
- 当某个数据卷不再被挂载使用时,里面的数据如何处理?
- 如果想要实现只读挂载如何处理?
- 如果想要只能一个Pod挂载如何处理?
- 如何只允许某个Pod使用10G的空间?
为了能够屏蔽底层存储实现的细节,方便用户使用, kubernetes引入PV和PVC两种资源对象。
- PV(Persistent Volume)是持久化卷的意思,是对底层的共享存储的一种抽象。一般情况下PV由kubernetes管理员进行创建和配置,它与底层具体的共享存储技术有关,并通过插件完成与共享存储的对接。
- PersistentVolume:简称PV,是由Kubernetes管理员设置的存储,可以配置Ceph、NFS、GlusterFS等常用存储配置,相对于Volume配置,提供了更多的功能,比如生命周期的管理、大小的限制。PV分为静态和动态。
- PVC(Persistent Volume Claim)是持久卷声明的意思,是用户对于存储需求的一种声明。换句话说,PVC其实就是用户向kubernetes系统发出的一种资源需求申请。
- PersistentVolumeClaim:简称PVC,是对存储PV的请求,表示需要什么类型的PV,需要存储的技术人员只需要配置PVC即可使用存储,或者Volume配置PVC的名称即可。
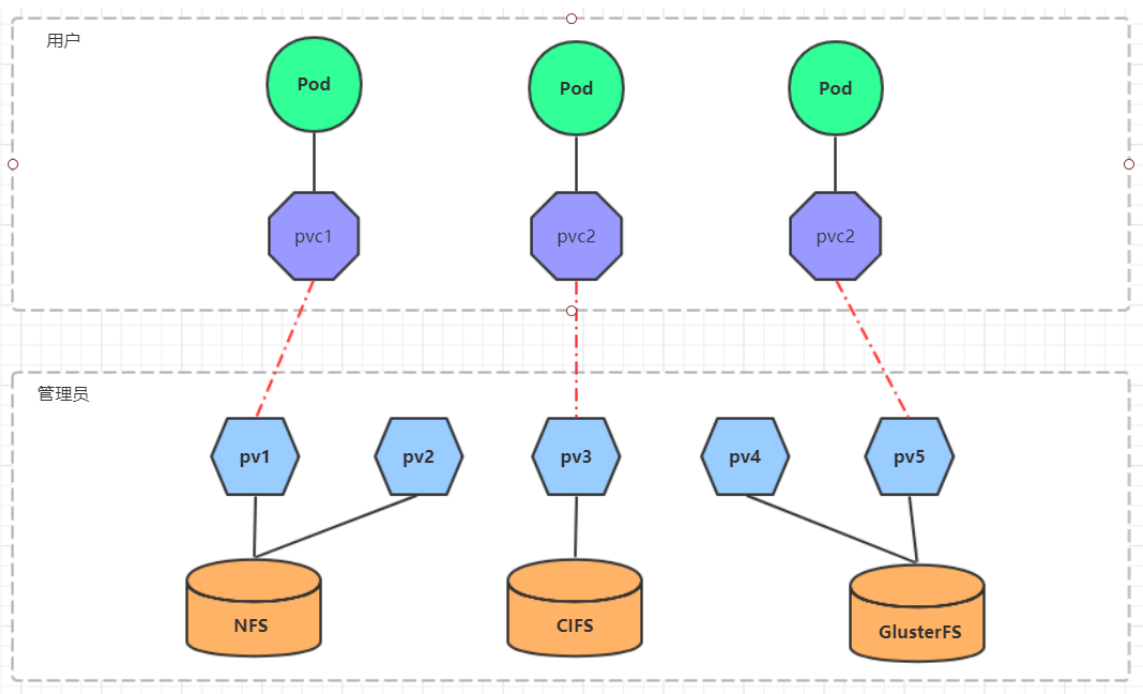
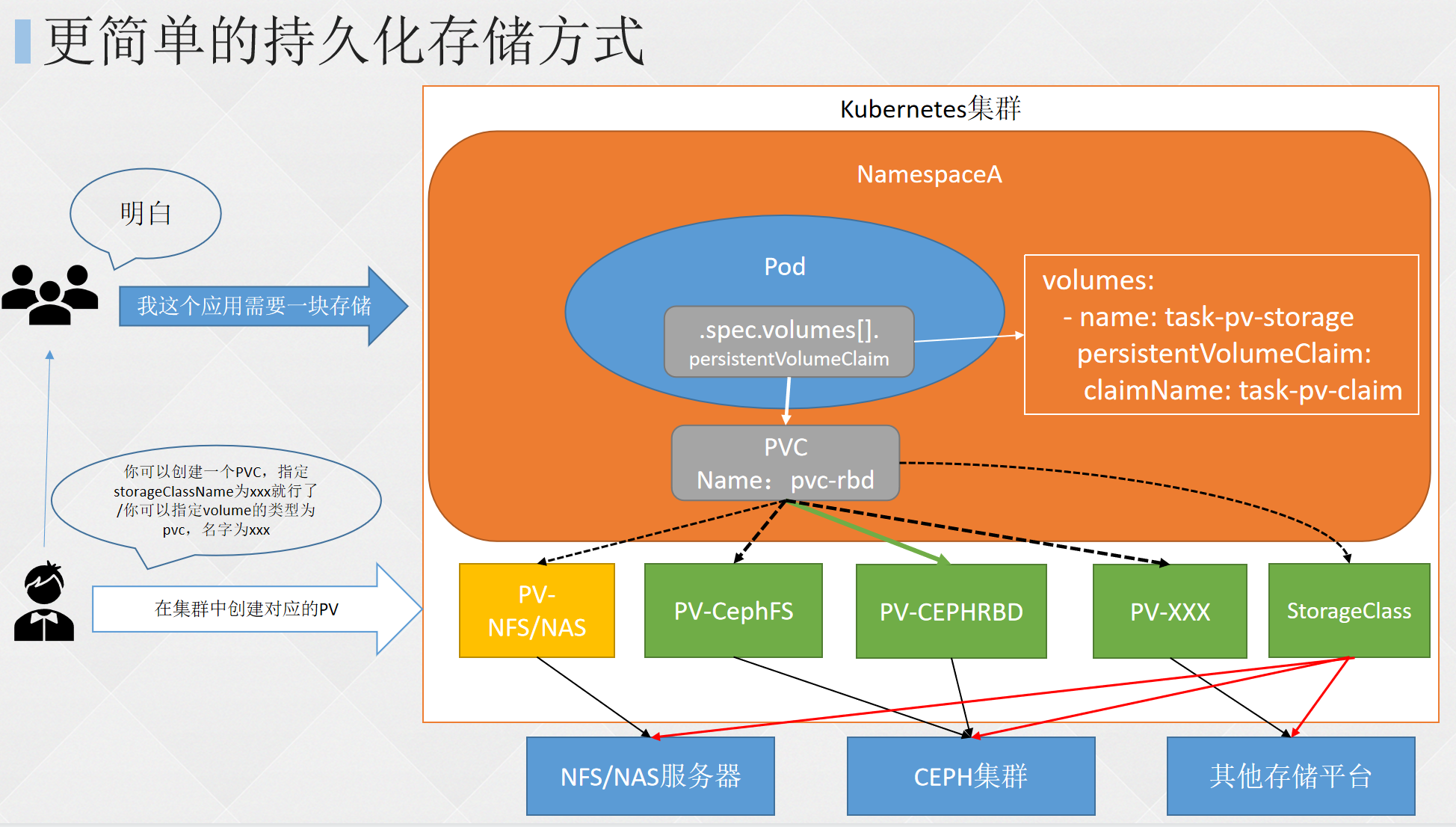
使用了PV和PVC之后,工作可以得到进一步的细分:
- 存储:存储工程师维护
- PV: kubernetes管理员维护
- PVC:kubernetes用户维护
官方文档:https://kubernetes.io/docs/concepts/storage/persistent-volumes/
1.1.2.1 PV
PV是存储资源的抽象,下面是资源清单文件:
apiVersion: v1kind: PersistentVolumemetadata:name: pv2spec:nfs: # 存储类型,与底层真正存储对应capacity: # 存储能力,目前只支持存储空间的设置storage: 2GiaccessModes: # 访问模式storageClassName: # 存储类别persistentVolumeReclaimPolicy: # 回收策略
PV 的关键配置参数说明:
- 存储类型
底层实际存储的类型,kubernetes支持多种存储类型,每种存储类型的配置都有所差异
- 存储能力(capacity)
目前只支持存储空间的设置( storage=1Gi ),不过未来可能会加入IOPS、吞吐量等指标的配置
- 访问模式(accessModes)
用于描述用户应用对存储资源的访问权限,访问权限包括下面几种方式:需要注意的是,底层不同的存储类型可能支持的访问模式不同
- ReadWriteOnce(RWO):可以被单节点以读写模式挂载,命令行中可以被缩写为RWO。
- ReadOnlyMany(ROX): 可以被多个节点以只读模式挂载,命令行中可以被缩写为ROX。
- ReadWriteMany(RWX):可以被多个节点以读写模式挂载,命令行中可以被缩写为RWX。
- storageClassName:PV的类,一个特定类型的PV只能绑定到特定类别的PVC;
官方文档:https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes
- 回收策略(persistentVolumeReclaimPolicy)
当PV不再被使用了之后,对其的处理方式。目前支持三种策略:需要注意的是,底层不同的存储类型可能支持的回收策略不同
- Retain (保留) 保留,该策略允许手动回收资源,当删除PVC时,PV仍然存在,PV被视为已释放,管理员可以手动回收卷。
- Recycle(回收) 回收,如果Volume插件支持,Recycle策略会对卷执行rm -rf清理该PV,并使其可用于下一个新的PVC,但是本策略将来会被弃用,目前只有NFS和HostPath支持该策略。
- Delete (删除) 删除,如果Volume插件支持,删除PVC时会同时删除PV,动态卷默认为Delete,目前支持Delete的存储后端包括AWS EBS, GCE PD, Azure Disk, or OpenStack Cinder等。
通过persistentVolumeReclaimPolicy: Recycle字段配置
官方文档:https://kubernetes.io/docs/concepts/storage/persistent-volumes/#reclaim-policy
- 存储类别
PV可以通过storageClassName参数指定一个存储类别
- 具有特定类别的PV只能与请求了该类别的PVC进行绑定
- 未设定类别的PV则只能与不请求任何类别的PVC进行绑定
- 存储分类
- 文件存储:一些数据可能需要被多个节点使用,比如用户的头像、用户上传的文件等,实现方式:NFS、NAS、FTP、CephFS等。
- 块存储:一些数据只能被一个节点使用,或者是需要将一块裸盘整个挂载使用,比如数据库、Redis等,实现方式:Ceph、GlusterFS、公有云。
- 对象存储:由程序代码直接实现的一种存储方式,云原生应用无状态化常用的实现方式,实现方式:一般是符合S3协议的云存储,比如AWS的S3存储、Minio、七牛云等。
- 状态(status)
一个 PV 的生命周期中,可能会处于4中不同的阶段:
- Available(可用): 表示可用状态,还未被任何 PVC 绑定
- Bound(已绑定): 表示 PV 已经被 PVC 绑定
- Released(已释放): 表示 PVC 被删除,但是资源还未被集群重新声明
- Failed(失败): 表示该 PV 的自动回收失败
- PV配置示例-NFS/NAS ``` apiVersion: v1 kind: PersistentVolume metadata: name: pv-nfs spec: capacity: storage: 5Gi volumeMode: Filesystem accessModes:
- ReadWriteMany persistentVolumeReclaimPolicy: Recycle storageClassName: nfs-slow mountOptions:
- hard
- nfsvers=4.1 nfs: path: /data/k8s-data/testDir server: 192.168.68.119
capacity:容量配置 volumeMode:卷的模式,目前支持Filesystem(文件系统) 和 Block(块),其中Block类型需要后端存储支持,默认为文件系统 accessModes:该PV的访问模式 storageClassName:PV的类,一个特定类型的PV只能绑定到特定类别的PVC; persistentVolumeReclaimPolicy:回收策略 mountOptions:非必须,新版本中已弃用 nfs:NFS服务配置,包括以下两个选项 path:NFS上的共享目录 server:NFS的IP地址
pv与pvc绑定 cat nfs-pv-pvc.yaml
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: nfs-pvc spec: accessModes:
- ReadWriteMany
volumeMode: Filesystem storageClassName: nfs-slow resources: requests: storage: 5Gi
挂载PVC root@k8s-master01:~/yaml# cat nginx-deploy-nfs-pvc.yaml apiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx name: nginx-nfs-pvc namespace: default spec: progressDeadlineSeconds: 600 replicas: 2 revisionHistoryLimit: 10 selector: matchLabels: app: nginx strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate template: metadata: creationTimestamp: null labels: app: nginx spec: containers:
- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginxresources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /optname: share-volume- mountPath: /etc/timezonename: timezone- mountPath: /etc/localtimename: time-config- mountPath: /tmp/pvcname: pvc-nfs- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginx2command:- sh- -c- sleep 3600resources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /mntname: share-volume- mountPath: /var/log/nginxname: nfs-volumednsPolicy: ClusterFirstrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- name: share-volumeemptyDir: {}#medium: Memory- name: timezonehostPath:path: /etc/timezonetype: File- name: time-confighostPath:path: /usr/share/zoneinfo/Asia/Shanghaitype: File- name: nfs-volumenfs:server: 192.168.68.115path: /data/nfs/nginx-log- name: pvc-nfspersistentVolumeClaim:claimName: nfs-pvc
- **PV配置示例-HostPath**
kind: PersistentVolume apiVersion: v1 metadata: name: task-pv-volume labels: type: local spec: storageClassName: hostpath capacity: storage: 10Gi accessModes:
- ReadWriteOnce
hostPath: path: “/mnt/data”
hostPath:hostPath服务配置 path:宿主机路径
- **PV配置示例-CephRBD**
apiVersion: v1 kind: PersistentVolume metadata: name: ceph-rbd-pv spec: capacity: storage: 1Gi storageClassName: ceph-fast accessModes:
- ReadWriteOnce
rbd: monitors:
- 192.168.1.123:6789- 192.168.1.124:6789- 192.168.1.125:6789pool: rbdimage: ceph-rbd-pv-testuser: adminsecretRef:name: ceph-secretfsType: ext4readOnly: false
monitors:Ceph的monitor节点的IP pool:所用Ceph Pool的名称,可以使用ceph osd pool ls查看 image:Ceph块设备中的磁盘映像文件,可以使用rbd create POOL_NAME/IMAGE_NAME —size 1024创建,使用rbd list POOL_NAME查看 user:Rados的用户名,默认是admin secretRef:用于验证Ceph身份的密钥 fsType:文件类型,可以是ext4、XFS等 readOnly:是否是只读挂载
**实验**<br />使用NFS作为存储,来演示PV的使用,创建3个PV,对应NFS中的3个暴露的路径。1. 准备NFS环境
创建目录
mkdir /root/data/{pv1,pv2,pv3} -pv
暴露服务
vim /etc/exports /root/data/pv1 192.168.68.0/24(rw,no_root_squash,no_subtree_check) /root/data/pv2 192.168.68.0/24(rw,no_root_squash,no_subtree_check) /root/data/pv3 192.168.68.0/24(rw,no_root_squash,no_subtree_check)
重启服务
systemctl restart nfs-kernel-server.service
2. 创建pv.yaml
apiVersion: v1 kind: PersistentVolume metadata: name: pv1 spec: capacity: storage: 1Gi accessModes:
- ReadWriteMany persistentVolumeReclaimPolicy: Retain nfs: path: /root/data/pv1 server: 192.168.68.115
apiVersion: v1 kind: PersistentVolume metadata: name: pv2 spec: capacity: storage: 2Gi accessModes:
- ReadWriteMany persistentVolumeReclaimPolicy: Retain nfs: path: /root/data/pv2 server: 192.168.68.115
apiVersion: v1 kind: PersistentVolume metadata: name: pv3 spec: capacity: storage: 3Gi accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /root/data/pv3
server: 192.168.68.115
创建 pv
kubectl create -f pv.yaml
查看pv
kubectl get pv -o wide NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE pv1 1Gi RWX Retain Available 13s Filesystem pv2 2Gi RWX Retain Available 13s Filesystem pv3 3Gi RWX Retain Available 13s Filesystem
<a name="HTdBJ"></a>##### 1.1.2.2 PVC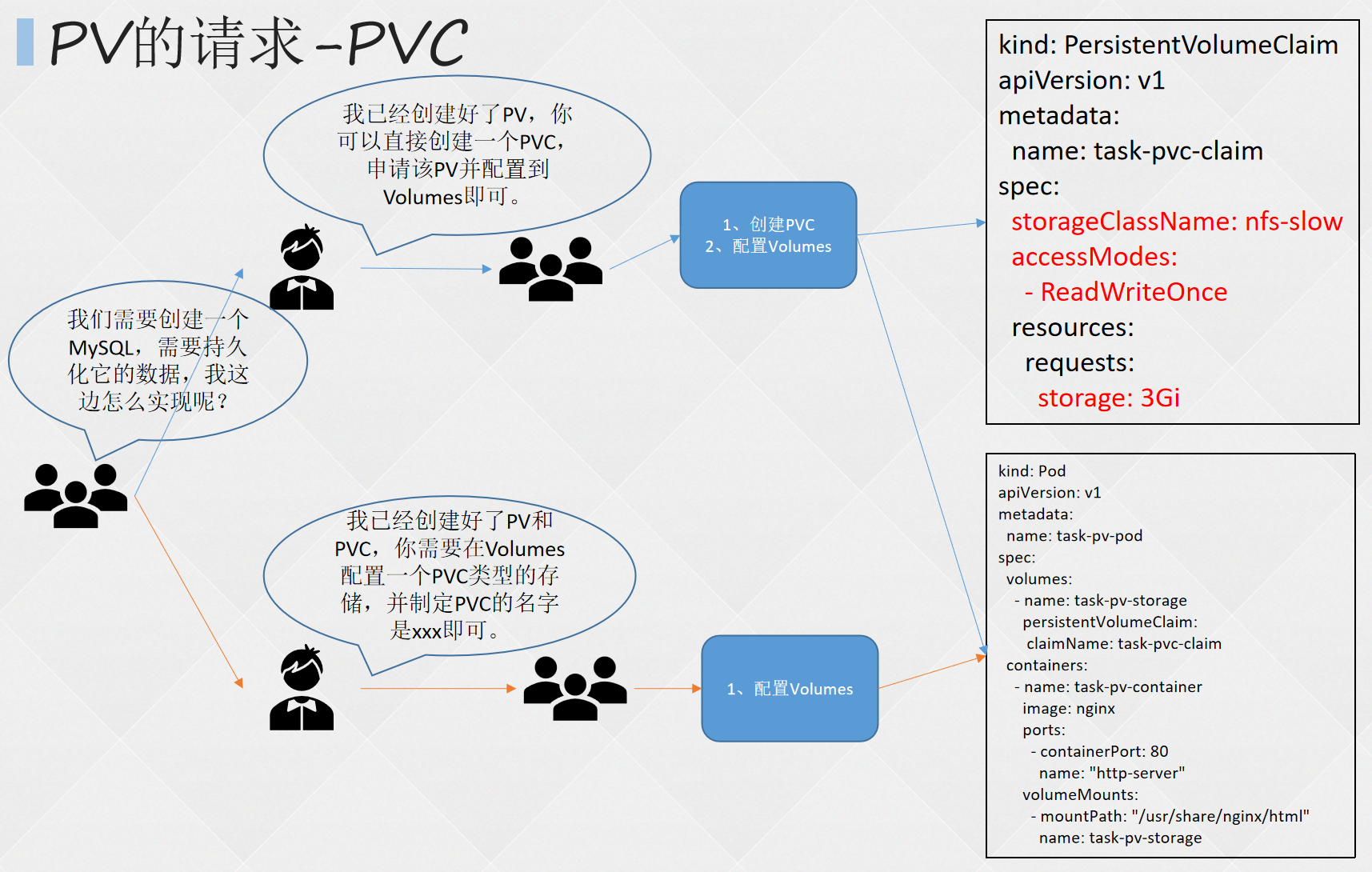<br />PVC是资源的申请,用来声明对存储空间、访问模式、存储类别需求信息。下面是资源清单文件:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc namespace: dev spec: accessModes: # 访问模式 selector: # 采用标签对PV选择 storageClassName: # 存储类别 resources: # 请求空间 requests: storage: 5Gi
PVC 的关键配置参数说明:- **访问模式(accessModes)**用于描述用户应用对存储资源的访问权限- **选择条件(selector)**通过Label Selector的设置,可使PVC对于系统中己存在的PV进行筛选- **存储类别(storageClassName)**PVC在定义时可以设定需要的后端存储的类别,只有设置了该class的pv才能被系统选出- **资源请求(Resources )**描述对存储资源的请求PVC创建和挂载失败的原因:- PVC一直Pending的原因:- PVC的空间申请大小大于PV的大小- PVC的StorageClassName没有和PV的一致- PVC的accessModes和PV的不一致- 挂载PVC的Pod一直处于Pending:- PVC没有创建成功/PVC不存在- PVC和Pod不在同一个Namespace删除PVC后-->k8s会创建一个用于回收的pod-->根据PV的回收策略进行PV的回收-->回收完成后,PV的状态就会变成可绑定的状态也就是空闲状态-->其他的pending状态的pvc,如果匹配到这个pvc,就能和这个PV进行绑定。**实验**- 创建pvc.yaml,申请pv
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc1 namespace: dev spec: accessModes:
- ReadWriteMany resources: requests: storage: 1Gi
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc2 namespace: dev spec: accessModes:
- ReadWriteMany resources: requests: storage: 1Gi
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc3 namespace: dev spec: accessModes:
查看pvc
root@k8s-master01:~/yaml# kubectl get pvc -n dev -o wide NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE pvc1 Bound pv1 1Gi RWX 19s Filesystem pvc2 Bound pv2 2Gi RWX 19s Filesystem pvc3 Bound pv3 3Gi RWX 19s Filesystem
查看pv
root@k8s-master01:~/yaml# kubectl get pv -o wide NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE pv1 1Gi RWX Retain Bound dev/pvc1 5m27s Filesystem pv2 2Gi RWX Retain Bound dev/pvc2 5m27s Filesystem pv3 3Gi RWX Retain Bound dev/pvc3 5m27s Filesystem
- 创建pods-pv.yaml, 使用pv
apiVersion: v1 kind: Pod metadata: name: pod1 namespace: dev spec: containers:
- name: busybox
image: busybox:1.30
command: [“/bin/sh”,”-c”,”while true;do echo pod1 >> /root/out.txt; sleep 10; done;”]
volumeMounts:
- name: volume mountPath: /root/ volumes:
- name: volume persistentVolumeClaim: claimName: pvc1 readOnly: false
apiVersion: v1 kind: Pod metadata: name: pod2 namespace: dev spec: containers:
- name: busybox image: busybox:1.30 command: [“/bin/sh”,”-c”,”while true;do echo pod2 >> /root/out.txt; sleep 10; done;”] volumeMounts:
查看pod
kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod1 1/1 Running 0 38s 172.27.14.203 k8s-node02
查看pvc
kubectl get pvc -n dev -o wide NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE pvc1 Bound pv1 1Gi RWX 2m44s Filesystem pvc2 Bound pv2 2Gi RWX 2m44s Filesystem pvc3 Bound pv3 3Gi RWX 2m44s Filesystem
查看pv
kubectl get pv -n dev -o wide NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE pv1 1Gi RWX Retain Bound dev/pvc1 8m2s Filesystem pv2 2Gi RWX Retain Bound dev/pvc2 8m2s Filesystem pv3 3Gi RWX Retain Bound dev/pvc3 8m2s Filesystem
查看nfs中的文件存储
root@k8s-master01:~/yaml# more /root/data/pv1/out.txt pod1 pod1 pod1 pod1 pod1 pod1 pod1 pod1 pod1 pod1 pod1 pod1 root@k8s-master01:~/yaml# cat /root/data/pv2/out.txt pod2 pod2 pod2 pod2 pod2 pod2 pod2 pod2 pod2 pod2 pod2 pod2
<a name="zNKUQ"></a>##### 1.1.2.3 生命周期PVC和PV是一一对应的,PV和PVC之间的相互作用遵循以下生命周期:- **资源供应**:管理员手动创建底层存储和PV- **资源绑定**:用户创建PVC,kubernetes负责根据PVC的声明去寻找PV,并绑定在用户定义好PVC之后,系统将根据PVC对存储资源的请求在已存在的PV中选择一个满足条件的PV一旦绑定到某个PVC上,就会被这个PVC独占,不能再与其他PVC进行绑定了- 一旦找到,就将该PV与用户定义的PVC进行绑定,用户的应用就可以使用这个PVC了- 如果找不到,PVC则会无限期处于Pending状态,直到等到系统管理员创建了一个符合其要求的PV- **资源使用**:用户可在pod中像volume一样使用pvcPod使用Volume的定义,将PVC挂载到容器内的某个路径进行使用。- **资源释放**:用户删除pvc来释放pv当存储资源使用完毕后,用户可以删除PVC,与该PVC绑定的PV将会被标记为“已释放”,但还不能立刻与其他PVC进行绑定。通过之前PVC写入的数据可能还被留在存储设备上,只有在清除之后该PV才能再次使用。- **资源回收**:kubernetes根据pv设置的回收策略进行资源的回收对于PV,管理员可以设定回收策略,用于设置与之绑定的PVC释放资源之后如何处理遗留数据的问题。只有PV的存储空间完成回收,才能供新的PVC绑定和使用。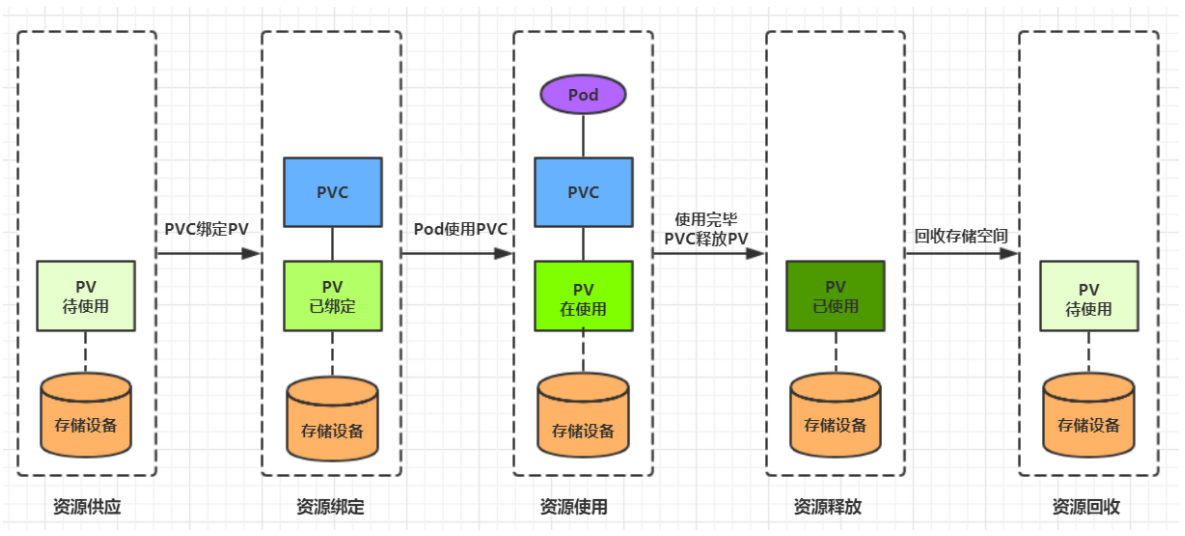<a name="SLN5D"></a>## 2.高级调度<a name="bS3Ol"></a>### 2.1 CronJob计划任务CronJob用于以时间为基准周期性地执行任务,这些自动化任务和运行在Linux或UNIX系统上的CronJob一样。CronJob对于创建定期和重复任务非常有用,例如执行备份任务、周期性调度程序接口、发送电子邮件等。<br />对于Kubernetes 1.8以前的版本,需要添加--runtime-config=batch/v2alpha1=true参数至APIServer中,然后重启APIServer和Controller Manager用于启用API,对于1.8以后的版本无须修改任何参数,可以直接使用,本节的示例基于1.8以上的版本。<br />在k8s里面运行周期性的计划任务,cronjob。- * * * * * 分时日月周- 计划任务可能需要调用应用的接口。- 计划任务可能需要依赖某些环境。- php xxx ,直接用php项目的镜像进行执行计划任务。- php-wordpress:v1.0.1- cronjob被调用的时间,是用的controller-manager的时间<a name="OMKRT"></a>#### 1.创建cronjob创建CronJob有两种方式,一种是直接使用kubectl创建,一种是使用yaml文件创建。<br />使用kubectl创建CronJob的命令如下:<br />`kubectl run hello --schedule="*/1 * * * *" --restart=OnFailure --image=busybox -- /bin/sh -c "date; echo Hello from the Kubernetes cluster" 命令报错`<br />对应的yaml文件如下:cronjob.yaml<br />kubectl create -f cronjob.yaml
apiVersion: batch/v1beta1 kind: CronJob metadata: name: hello spec: schedule: “/1 *” jobTemplate: spec: template: spec: containers:
- name: helloimage: busyboxargs:- /bin/sh- -c- date; echo Hello from the Kubernetes clusterrestartPolicy: OnFailure
说 明s<br />说明:本例创建一个每分钟执行一次、打印当前时间和Hello from the Kubernetes cluster的计划任务。查看创建的CronJob:
root@k8s-master01:~/yaml# kubectl get cj NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE hello /1 * False 0 26s 2m29s
等待1分钟可以查看执行的任务(Jobs):
root@k8s-master01:~/yaml# kubectl get job NAME COMPLETIONS DURATION AGE hello-27472436 1/1 21s 3m7s hello-27472437 1/1 20s 2m7s hello-27472438 1/1 20s 67s hello-27472439 0/1 7s 7s
CronJob每次调用任务的时候会创建一个Pod执行命令,执行完任务后,Pod状态就会变成Completed,如下所示:
root@k8s-master01:~/yaml# kubectl get pod NAME READY STATUS RESTARTS AGE hello-27472437-ck9zc 0/1 Completed 0 3m14s hello-27472438-gsfr7 0/1 Completed 0 2m14s hello-27472439-ms6sw 0/1 Completed 0 74s hello-27472440-tgfbh 0/1 ContainerCreating 0 14s
可以通过logs查看Pod的执行日志:
root@k8s-master01:~/yaml# kubectl logs -f hello-27472440-tgfbh Sun Mar 27 02:00:17 UTC 2022 Hello from the Kubernetes cluster
如果要删除CronJob,直接使用delete即可:
kubectl delete -f cronjob.yaml
<a name="nphmv"></a>#### 2.可用参数的配置定义一个CronJob的yaml文件如下:
apiVersion: v1 items:
apiVersion: batch/v1beta1 kind: CronJob metadata: labels:
run: hello
name: hello namespace: default spec: concurrencyPolicy: Allow failedJobsHistoryLimit: 1 jobTemplate:
metadata:creationTimestamp: nullspec:template:metadata:creationTimestamp: nulllabels:run: hellospec:containers:- args:- /bin/sh- -c- date; echo Hello from the Kubernetes clusterimage: busyboximagePullPolicy: Alwaysname: helloresources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FilednsPolicy: ClusterFirstrestartPolicy: OnFailureschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30
schedule: ‘/1 *’ successfulJobsHistoryLimit: 3 suspend: false ``` 其中各参数的说明如下,可以按需修改:
schedule:调度周期,和Linux一致,分别是分时日月周。
- restartPolicy:重启策略,和Pod一致。
- concurrencyPolicy:并发调度策略。可选参数如下:
- Allow:允许同时运行多个任务。
- Forbid:不允许并发运行,如果之前的任务尚未完成,新的任务不会被创建。
- Replace:如果之前的任务尚未完成,新的任务会替换的之前的任务。
- suspend:如果设置为true,则暂停后续的任务,默认为false。
- successfulJobsHistoryLimit:保留多少已完成的任务,按需配置。
- failedJobsHistoryLimit:保留多少失败的任务。
相对于Linux上的计划任务,Kubernetes的CronJob更具有可配置性,并且对于执行计划任务的环境只需启动相对应的镜像即可。比如,如果需要Go或者PHP环境执行任务,就只需要更改任务的镜像为Go或者PHP即可,而对于Linux上的计划任务,则需要安装相对应的执行环境。此外,Kubernetes的CronJob是创建Pod来执行,更加清晰明了,查看日志也比较方便。可见,Kubernetes的CronJob更加方便和简单。
2.2污点和容忍Taint&Toleration
1.介绍
Taint&Toleration
1.在不同的机房
2.在不同的城市
3.不一样的配置
GPU服务器
纯固态硬盘的服务器
NodeSelect
Gpu-server:ture
Ssd-server:ture
Normal-server:ture
污点和容忍的说明
Taint在一类服务器上打上污点,让不能容忍这个污点的pod不能部署在打了污点的服务器上。
Master节点不应该部署系统pod之外的任何pod
2.Taint&Toleration
Taint能够使节点排斥一类特定的Pod,Taint和Toleration相互配合可以用来避免Pod被分配到不合适的节点,比如Master节点不允许部署系统组件之外的其他Pod。每个节点上都可以应用一个或多个Taint,这表示对于那些不能容忍这些Taint的Pod是不会被该节点接受的。如果将Toleration应用于Pod上,则表示这些Pod可以(但不要求)被调度到具有匹配Taint的节点上。
1. 概念
给节点增加一个Taint:kubectl taint nodes k8s-master01 master-test=test:NoSchedule
删除一个Taint:kubectl taint nodes k8s-master01 master-test-
上述命令给k8s-master01增加一个Taint,它的master-test对应的就是键,test对应就是值,effect对应的就是NoSchedule。这表明只有和这个Taint相匹配的Toleration的Pod才能够被分配到k8s-node01节点上。按如下方式在PodSpec中定义Pod的Toleration,就可以将Pod部署到该节点上。
方式一:
tolerations:- key: "master-test"operator: "Equal"value: "test"effect: "NoSchedule"
方式二:
tolerations:- key: "master-test"operator: "Exists"effect: "NoSchedule"
一个Toleration和一个Taint相匹配是指它们有一样的key和effect,并且如果operator是Exists(此时toleration不指定value)或者operator是Equal,则它们的value应该相等。
注意两种情况:
- 如果一个Toleration的key为空且operator为Exists,表示这个Toleration与任意的key、value和effect都匹配,即这个Toleration能容忍任意的Taint: ``` tolerations:
operator: “Exists” ```
如果一个Toleration的effect为空,则key与之相同的相匹配的Taint的effect可以是任意值: ``` tolerations:
- key: “key” operator: “Exists” ``` 上述例子使用到effect的一个值NoSchedule,也可以使用PreferNoSchedule,该值定义尽量避免将Pod调度到存在其不能容忍的Taint的节点上,但并不是强制的。effect的值还可以设置为NoExecute。
一个节点可以设置多个Taint,也可以给一个Pod添加多个Toleration。Kubernetes处理多个Taint和Toleration的过程就像一个过滤器:从一个节点的所有Taint开始遍历,过滤掉那些Pod中存在与之相匹配的Toleration的Taint。余下未被过滤的Taint的effect值决定了Pod是否会被分配到该节点,特别是以下情况:
- 如果未被过滤的Taint中存在一个以上effect值为NoSchedule的Taint,则Kubernetes不会将Pod分配到该节点。NoSchedule禁止调度
- 如果未被过滤的Taint中不存在effect值为NoExecute的Taint,但是存在effect值为PreferNoSchedule的Taint,则Kubernetes会尝试将Pod分配到该节点。NoExecute如果不符合这个污点,会立马被驱逐
- 如果未被过滤的Taint中存在一个以上effect值为NoExecute的Taint,则Kubernetes不会将Pod分配到该节点(如果Pod还未在节点上运行),或者将Pod从该节点驱逐(如果Pod已经在节点上运行)。
例如,假设给一个节点添加了以下的Taint:
kubectl taint nodes k8s-node01 key1=value1:NoSchedulekubectl taint nodes k8s-node01 key1=value1:NoExecutekubectl taint nodes k8s-node01 key2=value2:NoSchedule
然后存在一个Pod,它有两个Toleration:
tolerations:- key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule"- key: "key1"operator: "Equal"value: "value1"effect: "NoExecute"
在上述例子中,该Pod不会被分配到上述节点,因为没有匹配第三个Taint。但是如果给节点添加上述3个Taint之前,该Pod已经在上述节点中运行,那么它不会被驱逐,还会继续运行在这个节点上,因为第3个Taint是唯一不能被这个Pod容忍的。
通常情况下,如果给一个节点添加了一个effect值为NoExecute的Taint,则任何不能容忍这个Taint的Pod都会马上被驱逐,任何可以容忍这个Taint的Pod都不会被驱逐。但是,如果Pod存在一个effect值为NoExecute的Toleration指定了可选属性tolerationSeconds的值,则该值表示是在给节点添加了上述Taint之后Pod还能继续在该节点上运行的时间,例如:
tolerations:- key: "key1"operator: "Equal"value: "value1"effect: "NoExecute"tolerationSeconds: 3600
表示如果这个Pod正在运行,然后一个匹配的Taint被添加到其所在的节点,那么Pod还将继续在节点上运行3600秒,然后被驱逐。如果在此之前上述Taint被删除了,则Pod不会被驱逐。
删除一个Taint:kubectl taint nodes k8s-node01 key1:NoExecute-
查看Taint:kubectl describe node k8s-node01 | grep Tain
2. 用例
通过Taint和Toleration可以灵活地让Pod避开某些节点或者将Pod从某些节点被驱逐。下面是几种情况。
(1)专用节点
如果想将某些节点专门分配给特定的一组用户使用,可以给这些节点添加一个Taint(kubectl taint nodes nodename dedicated=groupName:NoSchedule),然后给这组用户的Pod添加一个相对应的Toleration。拥有上述Toleration的Pod就能够被分配到上述专用节点,同时也能够被分配到集群中的其他节点。如果只希望这些Pod只能分配到上述专用节点中,那么还需要给这些专用节点另外添加一个和上述Taint类似的Label(例如:dedicated=groupName),然后给Pod增加节点亲和性要求或者使用NodeSelector,就能将Pod只分配到添加了dedicated=groupName标签的节点上。
(2)特殊硬件的节点
在部分节点上配备了特殊硬件(比如GPU)的集群中,我们只允许特定的Pod才能部署在这些节点上。这时可以使用Taint进行控制,添加Taint如kubectl taint nodes nodename special=true:NoSchedule或者kubectl taint nodes nodename special=true:PreferNoSchedule,然后给需要部署在这些节点上的Pod添加相匹配的Toleration即可。
(3)基于Taint的驱逐
属于alpha特性,在每个Pod中配置在节点出现问题时的驱逐行为。
3. 基于Taint的驱逐
之前提到过Taint的effect值NoExecute,它会影响已经在节点上运行的Pod。如果Pod不能忍受effect值为NoExecute的Taint,那么Pod将会被马上驱逐。如果能够忍受effect值为NoExecute的Taint,但是在Toleration定义中没有指定tolerationSeconds,则Pod还会一直在这个节点上运行。
在Kubernetes 1.6版以后已经支持(alpha)当某种条件为真时,Node Controller会自动给节点添加一个Taint,用以表示节点的问题。当前内置的Taint包括:
- node.kubernetes.io/not-ready:节点未准备好,相当于节点状态Ready的值为False。
- node.kubernetes.io/unreachable:Node Controller访问不到节点,相当于节点状态Ready的值为Unknown。
- node.kubernetes.io/out-of-disk:节点磁盘耗尽。
- node.kubernetes.io/memory-pressure:节点存在内存压力。
- node.kubernetes.io/disk-pressure:节点存在磁盘压力。
- node.kubernetes.io/network-unavailable:节点网络不可达。
- node.kubernetes.io/unschedulable:节点不可调度。
- node.cloudprovider.kubernetes.io/uninitialized:如果Kubelet启动时指定了一个外部的cloudprovider,它将给当前节点添加一个Taint将其标记为不可用。在cloud-controller-manager的一个controller初始化这个节点后,Kubelet将删除这个Taint。
使用这个alpha功能特性,结合tolerationSeconds,Pod就可以指定当节点出现一个或全部上述问题时,Pod还能在这个节点上运行多长时间。
比如,一个使用了很多本地状态的应用程序在网络断开时,仍然希望停留在当前节点上运行一段时间,愿意等待网络恢复以避免被驱逐。在这种情况下,Pod的Toleration可以这样配置:
tolerations:- key: "node.alpha.kubernetes.io/unreachable"operator: "Exists"effect: "NoExecute"tolerationSeconds: 6000
Kubernetes会自动给Pod添加一个key为node.kubernetes.io/not-ready的Toleration并配置tolerationSeconds=300,同样也会给Pod添加一个key为node.kubernetes.io/unreachable的Toleration并配置tolerationSeconds=300,除非用户自定义了上述key,否则会采用这个默认设置。
这种自动添加Toleration的机制保证了在其中一种问题被检测到时,Pod默认能够继续停留在当前节点运行5分钟。这两个默认Toleration是由DefaultTolerationSeconds admission controller添加的。
DaemonSet中的Pod被创建时,针对以下Taint自动添加的NoExecute的Toleration将不会指定tolerationSeconds:
- node.alpha.kubernetes.io/unreachable
- node.kubernetes.io/not-ready
这保证了出现上述问题时DaemonSet中的Pod永远不会被驱逐。
2.3初始化容器InitContainer
1.初始化容器的用途
- Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码;
- Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低;
- Init容器可以以root身份运行,执行一些高权限命令;
- Init容器相关操作执行完成以后即退出,不会给业务容器带来安全隐患。
在主应用启动之前,做一些初始化的操作,比如创建文件、修改内核参数、等待依赖程序启动或其他需要在主程序启动之前需要做的工作
2.初始化容器和PostStart区别
PostStart:依赖主应用的环境,而且并不一定先于Command运行
InitContainer:不依赖主应用的环境,可以有更高的权限和更多的工具,一定会在主应用启动之前完成
3.初始化容器和普通容器的区别
Init 容器与普通的容器非常像,除了如下几点:
- 它们总是运行到完成;
- 上一个运行完成才会运行下一个;
- 如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止,但是Pod 对应的 restartPolicy 值为 Never,Kubernetes 不会重新启动 Pod。
- Init 容器不支持 lifecycle、livenessProbe、readinessProbe 和 startupProbe
查看示例:
root@k8s-master01:~/yaml# cat nginx-deploy-initcontainer.yamlapiVersion: apps/v1kind: Deploymentmetadata:labels:app: nginxname: nginxnamespace: defaultspec:progressDeadlineSeconds: 600replicas: 2revisionHistoryLimit: 10selector:matchLabels:app: nginxstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:creationTimestamp: nulllabels:app: nginxspec:initContainers: #初始化操作部分- image: nginximagePullPolicy: IfNotPresentcommand: ["sh", "-c", "echo InitContainer"]name: init1containers:- image: nginximagePullPolicy: IfNotPresentname: nginxresources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /optname: share-volume- image: nginximagePullPolicy: IfNotPresentname: nginx2command:- sh- -c- sleep 3600resources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /mntname: share-volumednsPolicy: ClusterFirstrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- name: share-volumeemptyDir: {}#medium: Memory
2.3 Affinity 亲和力
1.仍然存在的问题
Pod和节点之间的关系:
- 某些Pod优先选择有ssd=true标签的节点,如果没有在考虑部署到其它节点;
- 某些Pod需要部署在ssd=true和type=physical的节点上,但是优先部署在ssd=true的节点上;
Pod和Pod之间的关系:
- 同一个应用的Pod不同的副本或者同一个项目的应用尽量或必须不部署在同一个节点或者符合某个标签的一类节点上或者不同的区域;
相互依赖的两个Pod尽量或必须部署在同一个节点上或者同一个域内。
2.Affinity亲和力分类
NodeAffinity:节点亲和力/反亲和力
- ReqauiredDurinaSchedulinalanaredDuioqExesutiog:硬亲和力,即支持必须部署在指定的节点上,也支持必须不部署在指定的节点上。
- PrefesredDuriogSchedulinalanoredDurinsExesution:软亲和力,尽量部署在满足条件的节点上,或者是尽量不要部署在被匹配的节点。
- PodAffinity:Pod亲和力
- A应用B应用C应用,将A应用根据某种策略尽量部署在一块。Label
- ReqauiredDurinaSchedulinalanaredDuioqExesutiog
- 将A应用和B应用部署在一块
- PrefesredDuriogSchedulinalanoredDurinsExesution
- 尽量将A应用和B应用部署在一块
- Pod
- tiAffinity:Pod反亲和力
- 尽量将A应用和B应用部署在一块
- ReqauiredDurinaSchedulinalanaredDuioqExesutiog
- A应用B应用C应用,将A应用根据某种策略尽量尽量或不部署在一块。Label
- ReqauiredDurinaSchedulinalanaredDuioqExesutiog
- 不要将A应用与之匹配的应用部署在一块
- PrefesredDuriogSchedulinalanoredDurinsExesution
- 尽量不要将A应用与之匹配的应用部署在一块
- ReqauiredDurinaSchedulinalanaredDuioqExesutiog
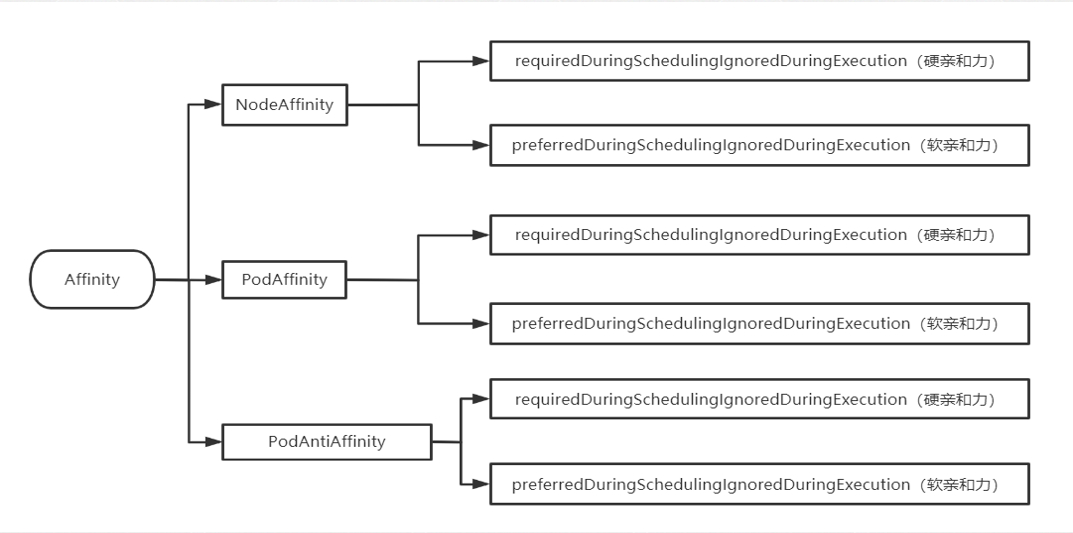
3.提高可用率—部署至不同宿主机
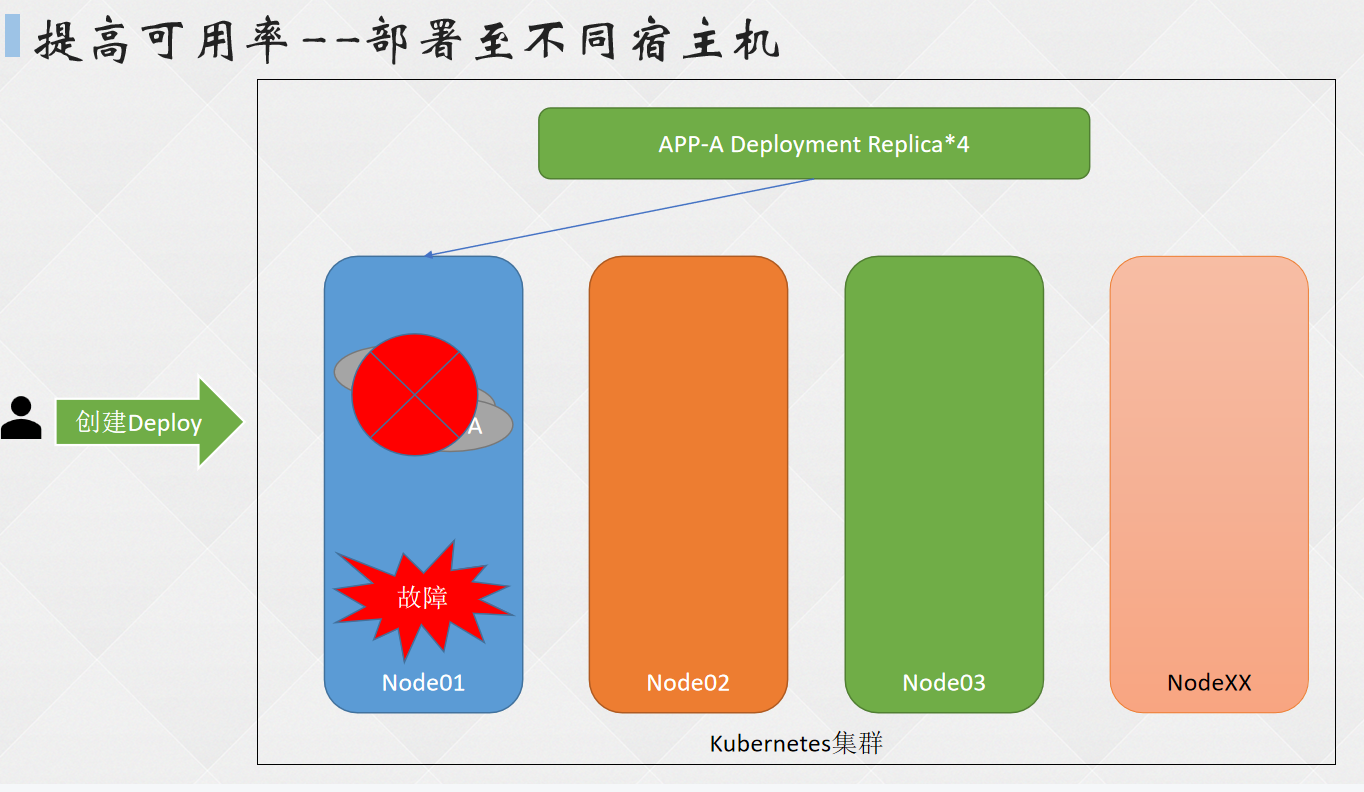
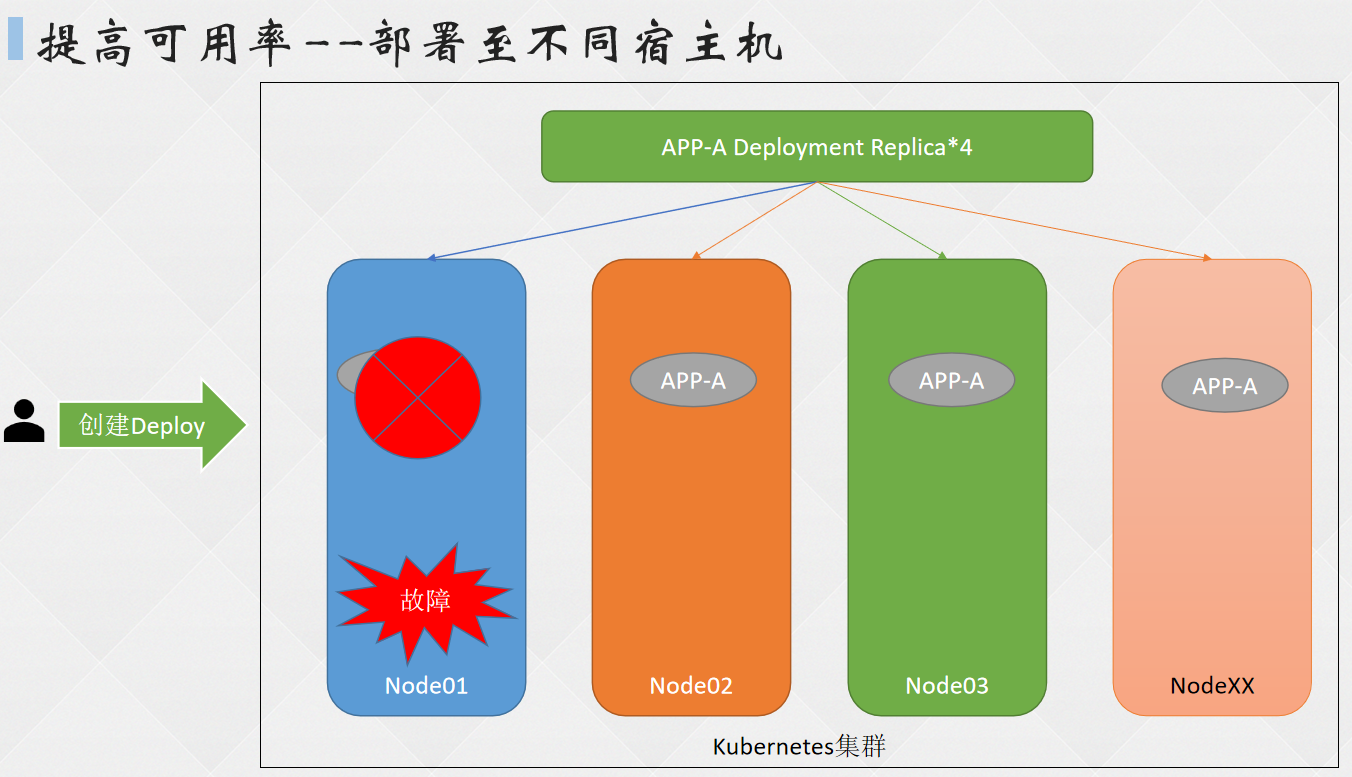
4.提高可用率—部署至不同机房/机柜
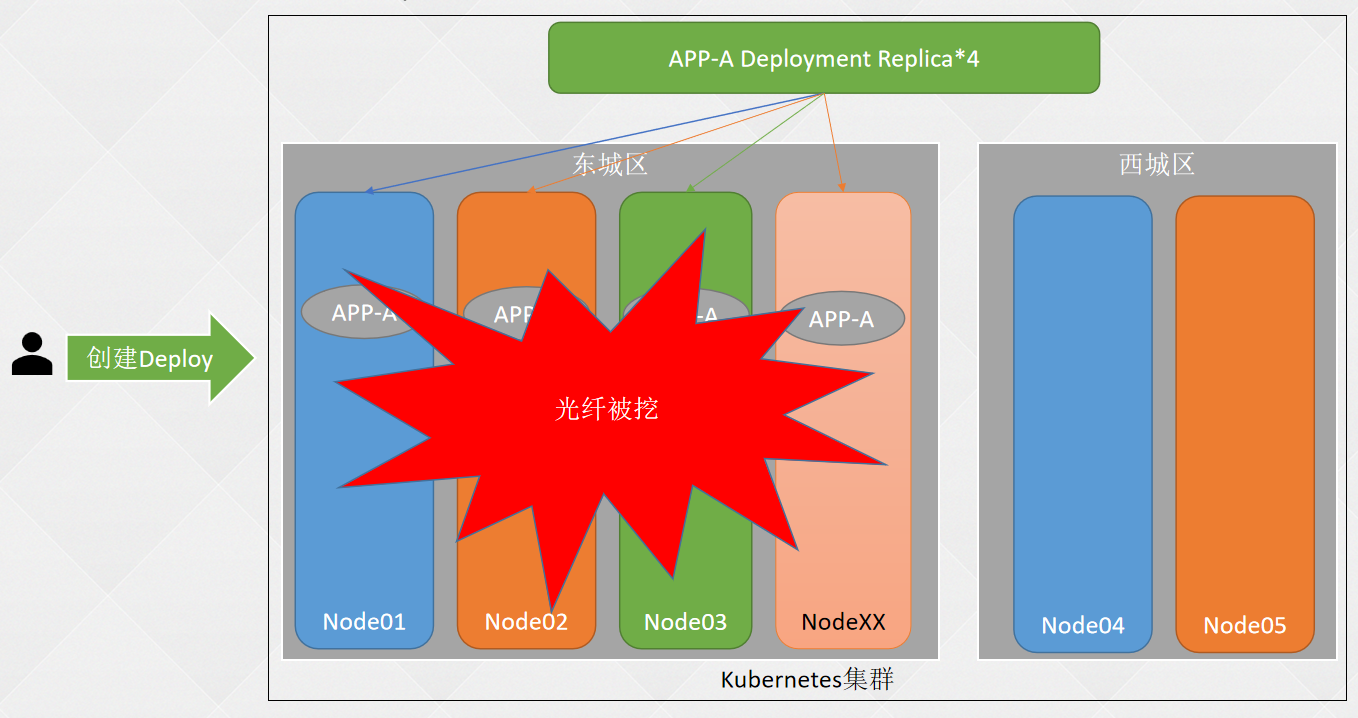

5.提高可用率—不放在同一个篮子里
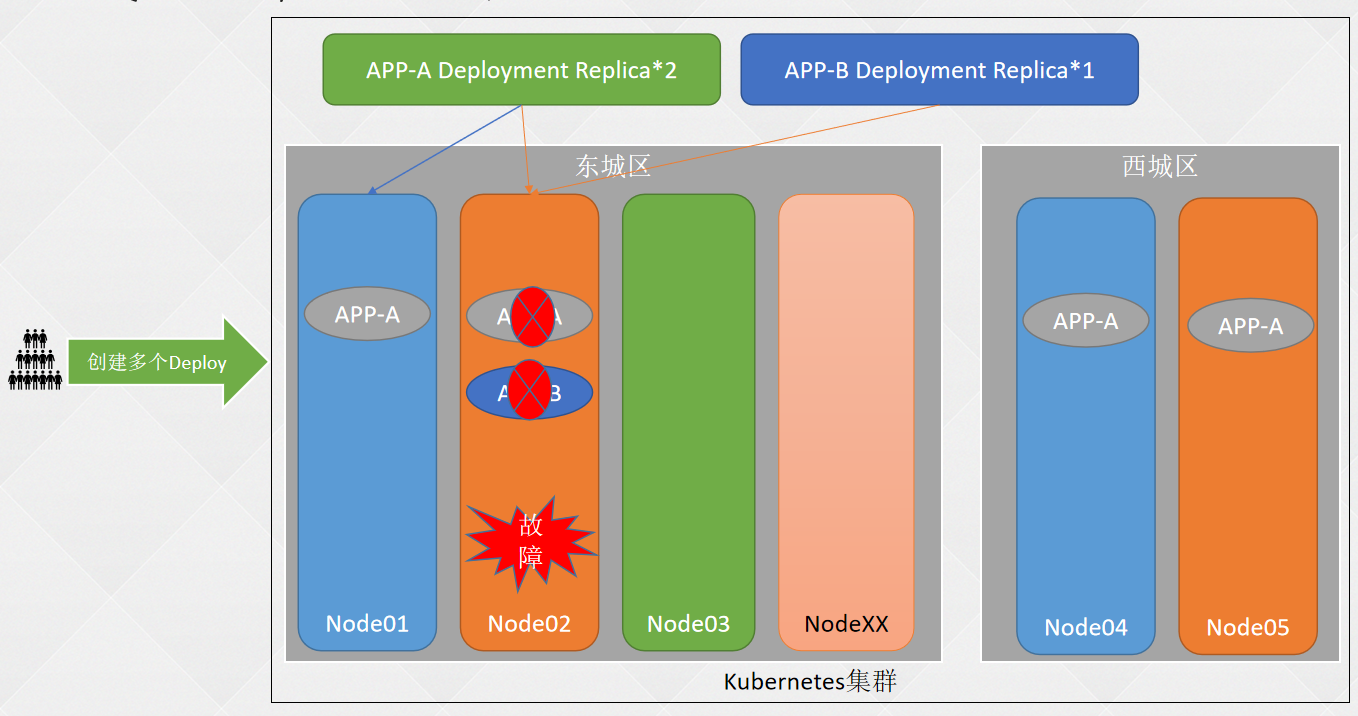
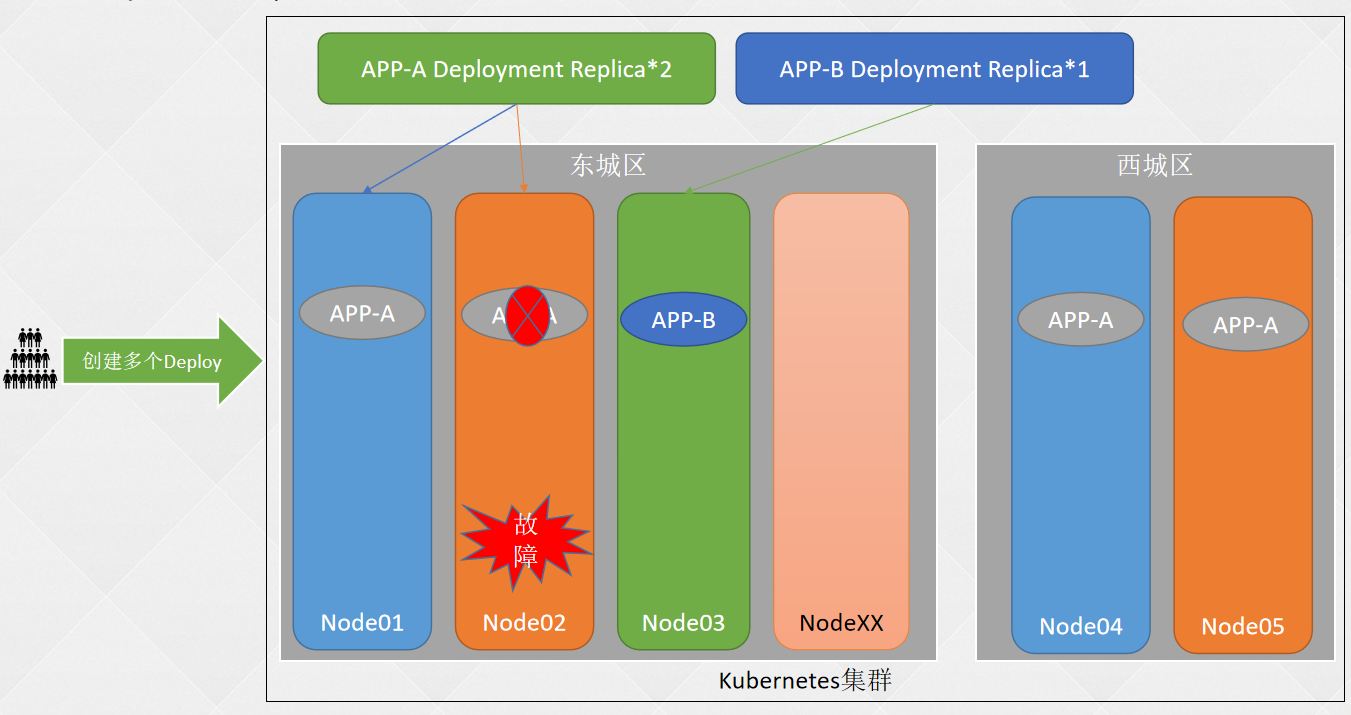
6.NodeAffinity:节点亲和力
查看节点labelskubectl get node --show-labels
给节点打上label
kubectl label nodes k8s-node02 kubernetes.io/e2e-az-name=e2e-az2
kubectl label nodes k8s-node03 kubernetes.io/e2e-az-name=e2e-az3
kubectl label nodes k8s-node02 another-node-label-key=another-node-label-value
kubectl label nodes k8s-master01 another-node-label-key=another-node-label-value
pod配置示例
apiVersion: apps/v1kind: Deploymentmetadata:annotations:deployment.kubernetes.io/revision: "2"creationTimestamp: "2022-03-27T04:03:07Z"generation: 2labels:app: nginxname: nginxnamespace: defaultresourceVersion: "259372"uid: 6de3d5a5-9324-4ba4-870b-d964953fd263spec:progressDeadlineSeconds: 600replicas: 2revisionHistoryLimit: 10selector:matchLabels:app: nginxstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:creationTimestamp: nulllabels:app: nginxspec:affinity: #节点亲和力配置nodeAffinity:preferredDuringSchedulingIgnoredDuringExecution:- preference:matchExpressions:- key: another-node-label-keyoperator: In #满足多个条件的节点values:- another-node-label-valueweight: 1requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/e2e-az-nameoperator: Invalues:- e2e-az2- e2e-az3#说明operatorIn 部署在满足多个条件的节点上NotIn 不部署在满足多个条件的节点上Exists 部署在具有某个存在的KEY为指定的值的node节点上DoesNotExist 不部署在具有某个存在的KEY为指定的值的node节点上Gt: 大于指定的条件 条件为number数字,不能为字符串Lt: 小于指定的条件 条件为number数字,不能为字符串containers:- image: nginximagePullPolicy: IfNotPresentname: nginxresources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /optname: share-volume- command:- sh- -c- sleep 3600image: nginximagePullPolicy: IfNotPresentname: nginx2resources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /mntname: share-volumednsPolicy: ClusterFirstinitContainers:- command:- sh- -c- echo InitContainerimage: nginximagePullPolicy: IfNotPresentname: init1resources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FilerestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- emptyDir: {}name: share-volume
查看nginx部署的节点
root@k8s-master01:~/yaml# kubectl get pod -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESnginx-748b86ff5c-hn8gw 2/2 Running 0 14m 172.27.14.215 k8s-node02 <none> <none>nginx-748b86ff5c-qgjb4 2/2 Running 0 14m 172.27.14.214 k8s-node02 <none> <none>
删除k8s-node2的label another-node-label-key
kubectl label nodes k8s-node02 another-node-label-key-
在看nginx部署的节点
root@k8s-master01:~/yaml# kubectl get pod -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESnginx-748b86ff5c-hn8gw 2/2 Running 0 16m 172.27.14.215 k8s-node02 <none> <none>nginx-748b86ff5c-qgjb4 2/2 Running 0 17m 172.27.14.214 k8s-node02 <none> <none>
可以看到还是在node02上,说明
- ReqauiredDurinaSchedulinalanaredDuioqExesutiog:硬亲和力
- PrefesredDuriogSchedulinalanoredDurinsExesution:软亲和力
硬亲和力和软亲和力是和的关系
7.pod亲和力和反亲和力
示例:
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: nginxname: nginx-podAffinitynamespace: defaultspec:progressDeadlineSeconds: 600replicas: 2revisionHistoryLimit: 10selector:matchLabels:app: nginxstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:creationTimestamp: nulllabels:app: nginxspec:#配置说明在下面把demo-nginx和kube-system namespaces下的符合label为k8s-app=calico-kube-controllers的pod部署在同一个节点上affinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: k8s-appoperator: Invalues:- calico-kube-controllers#如果写了namespaces 的字段,但是留空,他是匹配所有namespace 下的指定label的Pod,如果写了namespace并且指定了值,就是匹配指定namespace下的指定label的Pod。namespaces:- kube-systemtopologyKey: kubernetes.io/hostname 修改自己服务器上的keycontainers:- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginxresources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /optname: share-volume- image: nginx:1.15.2imagePullPolicy: IfNotPresentname: nginx2command:- sh- -c- sleep 3600resources: {}terminationMessagePath: /dev/termination-logterminationMessagePolicy: FileterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /mntname: share-volumednsPolicy: ClusterFirstrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- name: share-volumeemptyDir: {}#medium: Memory
说明:
- labelSelector:Pod选择器配置,可以配置多个
- matchExpressions:和节点亲和力配置一致
- operator:配置和节点亲和力一致,但是没有Gt和Lt
- topologyKey:匹配的拓扑域的key,也就是节点上label的key,key和value相同的为同一个域,可以用于标注不同的机房和地区
- namespaces 如果写了namespaces 的字段,但是留空,他是匹配所有namespace 下的指定label的Pod,如果写了namespace并且指定了值,就是匹配指定namespace下的指定label的Pod。
8. Topology拓扑域
1.什么是topology key
pod亲和性调度需要各个相关的pod对象运行于”同一位置”, 而反亲和性调度则要求他们不能运行于”同一位置”,
这里指定“同一位置” 是通过 topologyKey 来定义的,topologyKey 对应的值是 node 上的一个标签名称,比如各别节点zone=A标签,各别节点有zone=B标签,pod affinity topologyKey定义为zone,那么调度pod的时候就会围绕着A拓扑,B拓扑来调度,而相同拓扑下的node就为“同一位置”。
如果基于各个节点kubernetes.io/hostname标签作为评判标准,那么很明显“同一位置”意味着同一节点,不同节点既为不同位置,
一般用于:
- 我启动一个pod,希望(亲和性)或不希望(反亲和性)调度一台node上,并且这台node上有service=nginx标签的pod
- 我启动一个2个副本控制器,pod标签为service=tomcat,可以调度到任意node上,不希望两个pod调度到同一个node上
个人理解:pod affinity的调度范围为topology
官方解释:
如果该X已经在运行一个或多个满足规则Y的Pod,则该Pod应该(或者在非亲和性的情况下不应该)在X中运行
Y表示为LabelSelector规则
X是一个拓扑域,例如节点,机架,云提供者区域,云提供者区域等。您可以使用topologyKey这是系统用来表示这种拓扑域的节点标签的密钥
2.例子:
需求:当前有两个机房( beijing,shanghai),需要部署一个nginx产品,副本为两个,为了保证机房容灾高可用场景,需要在两个机房分别部署一个副本
apiVersion: apps/v1kind: StatefulSetmetadata:name: nginx-affinity-testspec:serviceName: nginx-servicereplicas: 2selector:matchLabels:service: nginxtemplate:metadata:name: nginxlabels:service: nginxspec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: serviceoperator: Invalues:- nginxtopologyKey: zonecontainers:- name: nginximage: contos7:latestcommand:- sleep- "360000000"
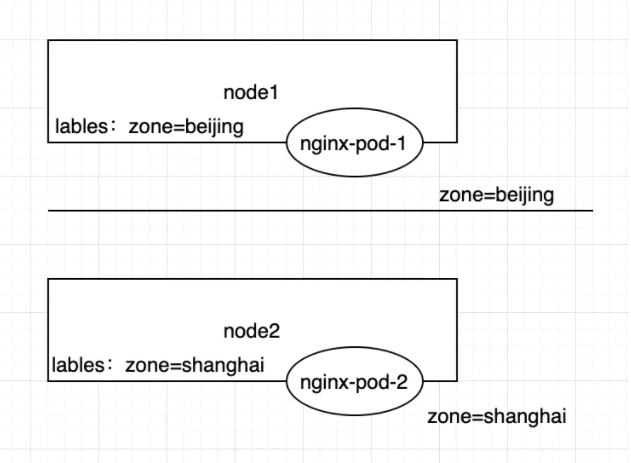
解释:两个node上分别有zone标签,来标注自己属于哪个机房,topologyKey定义为zone,pod所以在调度的时候,会根据node上zone标签来区分拓扑域,当前用的上 反亲和性调度 根据拓扑纬度调度,beijing机房调度完一个pod后,然后控制器判断beijing 拓扑域已经有server=nginx标签的pod,就在下一个拓扑域的node上调度了。
9,临时容器概念和配置
临时容器与其他容器的不同之处在于,它们缺少对资源或执行的保证,并且永远不会自动重启, 因此不适用于构建应用程序。临时容器使用与常规容器相同的 ContainerSpec 节来描述,但许多字段是不兼容和不允许的。
- 临时容器没有端口配置,因此像 ports,livenessProbe,readinessProbe 这样的字段是不允许的。
- Pod 资源分配是不可变的,因此 resources 配置是不允许的。
- 有关允许字段的完整列表,请参见 EphemeralContainer 参考文档。
临时容器是使用 API 中的一种特殊的 ephemeralcontainers 处理器进行创建的, 而不是直接添加到 pod.spec 段,因此无法使用 kubectl edit 来添加一个临时容器。
与常规容器一样,将临时容器添加到 Pod 后,将不能更改或删除临时容器。
使用临时容器需要开启 EphemeralContainers 特性门控, kubectl 版本为 v1.18 或者更高。
1.从镜像角度探讨容器安全
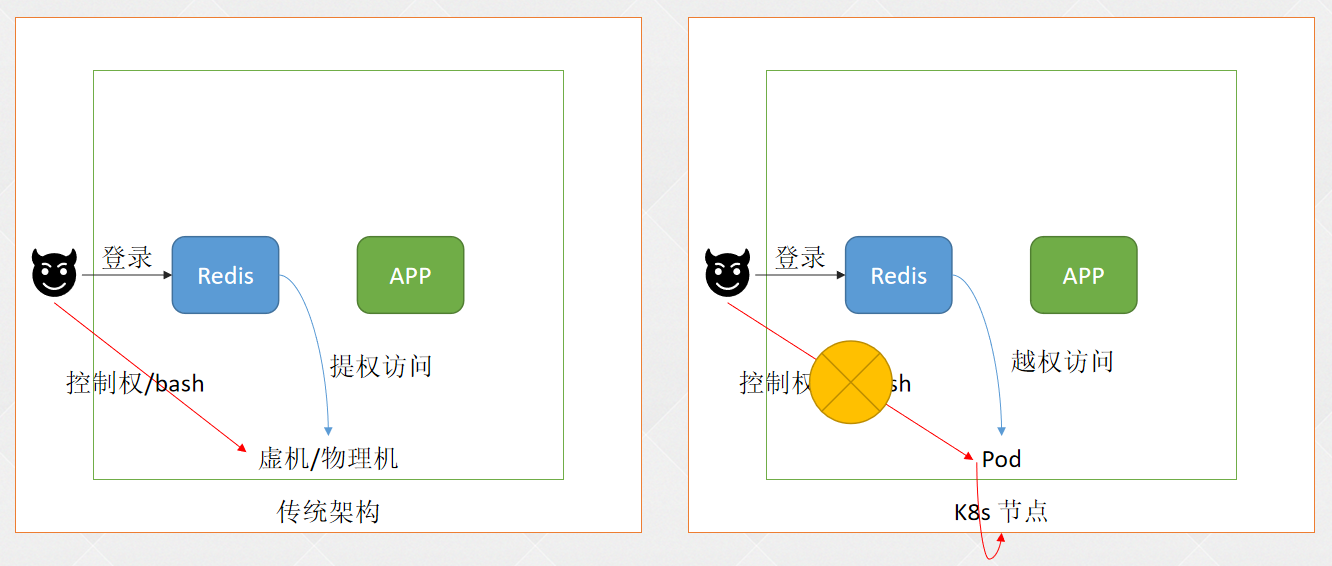
2.临时容器
3.开启临时容器
master节点上操作
修改apiserver
编辑/etc/kubernetes/manifests/kube-apiserver.yaml
将—feature-gates=TTLAfterFinished=true修改为—feature-gates=TTLAfterFinished=true,EphemeralContainers=true
修改controller-manager
编辑/etc/kubernetes/manifests/kube-controller-manager.yaml
将—feature-gates=TTLAfterFinished=true修改为—feature-gates=TTLAfterFinished=true,EphemeralContainers=true
修改kube-scheduler
编辑/etc/kubernetes/manifests/kube-scheduler.yaml
将—feature-gates=TTLAfterFinished=true修改为—feature-gates=TTLAfterFinished=true,EphemeralContainers=true
所以节点上操作
修改kubelet
编辑/var/lib/kubelet/kubeadm-flags.env
添加—feature-gates=EphemeralContainers=true
修改后如下
KUBELET_KUBEADM_ARGS=”—cgroup-driver=systemd —network-plugin=cni —pod-infra-container-image=k8s.gcr.io/pause:3.6 —feature-gates=EphemeralContainers=true”
重启kubelet
systemctl daemon-reload
systemctl restat kubelet
4.临时容器使用
官方文档 https://kubernetes.io/docs/concepts/workloads/pods/ephemeral-containers/
K8s 1.18+ kubectl alpha debug redis-new-5b577b46c7-2jv4j -ti --image=registry.cn-beijing.aliyuncs.com/dotbalo/debug-tools
K8s 1.20+ kubectl debug redis-new-5b577b46c7-2jv4j -ti --image=registry.cn-beijing.aliyuncs.com/dotbalo/debug-toolskubectl debug node/k8s-node01 -it --image=registry.cn-beijing.aliyuncs.com/dotbalo/debug-tools
参考文档:https://www.hebbao.com/1431.html
参考文档:https://blog.51cto.com/u_14848702/5055176
https://blog.csdn.net/chengyinwu/article/details/120867944
https://jishuin.proginn.com/p/763bfbd69bdc
http://114.115.155.37/2022/03/21/k8s-19/
3.高级准入控制
4.细粒度权限控制
API Server目前支持以下几种授权策略:
AlwaysDeny:表示拒绝所有请求,一般用于测试。
AlwaysAllow:允许接收所有请求。
如果集群不需要授权流程,则可以采用该策略,这也是Kubernetes的默认配置。
ABAC(Attribute-Based Access Control):基于属性的访问控制。
表示使用用户配置的授权规则对用户请求进行匹配和控制。
Webhook:通过调用外部REST服务对用户进行授权。
RBAC:Role-Based Access Control,基于角色的访问控制。
Node:是一种专用模式,用于对kubelet发出的请求进行访问控制。
1.RBAC权限管理概念
RBAC(Role-Based Access Control,基于角色的访问控制)是一种基于企业内个人用户的角色来管理对计算机或网络资源的访问方法,其在Kubernetes 1.5版本中引入,在1.6时升级为Beta版本,并成为Kubeadm安装方式下的默认选项。启用RBAC需要在启动APIServer时指定—authorization-mode=RBAC。
RBAC使用rbac.authorization.k8s.io API组来推动授权决策,允许管理员通过Kubernetes API动态配置策略。
RBAC API声明了4种顶级资源对象,即Role、ClusterRole、RoleBinding、ClusterRoleBinding,管理员可以像使用其他API资源一样使用kubectl API调用这些资源对象。例如:kubectl create -f (resource).yml。
授权介绍
在RABC API中,通过如下的步骤进行授权:
- 定义角色:在定义角色时会指定此角色对于资源的访问控制的规则。
- 绑定角色:将主体与角色进行绑定,对用户进行访问授权。
角色
- Role:授权特定命名空间的访问权限
- ClusterRole:授权所有命名空间的访问权限
- Role和ClusterRole的关键区别是,Role是作用于命名空间内的角色,ClusterRole作用于整个集群的角色。
- 在RBAC API中,Role包含表示一组权限的规则。权限纯粹是附加允许的,没有拒绝规则。Role只能授权对单个命名空间内的资源的访问权限,比如授权对default命名空间的读取权限
- ClusterRole也可将上述权限授予作用于整个集群的Role,主要区别是,ClusterRole是集群范围的,因此它们还可以授予对以下内容的访问权限:
- l 集群范围的资源(如Node)。
- 非资源端点(如/healthz)。
- 跨所有命名空间的命名空间资源(如Pod)。
角色绑定
- RoleBinding:将角色绑定到主体(即subject)
- ClusterRoleBinding:将集群角色绑定到主体
- RoleBinding将Role中定义的权限授予User、Group或Service Account。RoleBinding和ClusterRoleBinding最大的区别与Role和ClusterRole的区别类似,即RoleBinding作用于命名空间,ClusterRoleBinding作用于集群。
- RoleBinding可以引用同一命名空间的Role进行授权,比如将上述创建的pod-reader的Role授予default命名空间的用户jane,这将允许jane读取default命名空间中的Pod
- RoleBinding也可以引用ClusterRole来授予对命名空间资源的某些权限。管理员可以为整个集群定义一组公用的ClusterRole,然后在多个命名空间中重复使用。
- ClusterRoleBinding可用于在集群级别和所有命名空间中授予权限,比如允许组manager中的所有用户都能读取任何命名空间的Secret:
主体(subject)
- User:用户
- Group:用户组
- ServiceAccount:服务账号
四、K8S高级篇
1.云原生存储及存储进阶
2.中间件容器化及Helm
五、K8S运维篇

若有收获,就点个赞吧
0 人点赞
