- 52. 用subprocess管理子进程
- 53. 可以用线程执行阻塞式I/O,但不要用它做并行计算
- 54. 利用Lock防止多个线程争用同一份数据
- 55. 用Queue来协调各线程之间的工作进度
- 56. 学会判断什么场合必须做并发
- 57. 不要在每次fan-out时都新建一批Thread实例
- 58. 学会正确地重构代码,以便用Queue做并发
- 59. 如果必须用线程做并发,那就考虑通过ThreadPoolExecutor实现
- 60. 用协程实现高并发的I/O
- 61. 学会用asyncio改写那些通过线程实现的I/O
- 62. 结合线程与协程,将代码顺利迁移到asyncio
- 63. 让asyncio的事件循环保持畅通,以便进一步提升程序的响应能力
- 64. 考虑用concurrent.futures实现真正的并行计算
52. 用subprocess管理子进程
subprocess是用来执行命令的,比如shell脚本写起来太复杂,可以考虑用这个并行执行一些命令加快速度。可以发现以下10个命令是并行执行的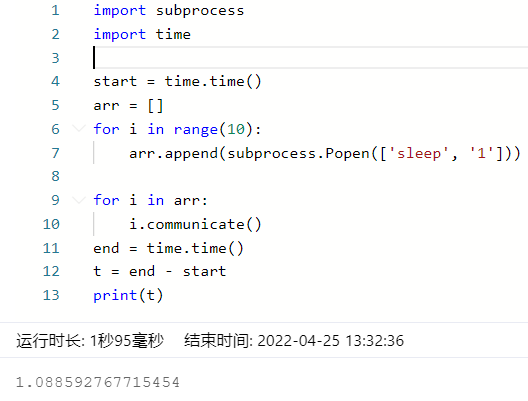
53. 可以用线程执行阻塞式I/O,但不要用它做并行计算
为了保证CPython的解释器在执行python程序过程中,状态不受干扰,cpython中有一种GIL全局解释器锁。GIL防止一个线程突然一个线程突然打断另一个线程,导致解释器状态被破坏。
不足之处:python中的线程受GIL约束,每次只有一条线程向前推进,无法做到多头并进,因此无法做到多线程并行计算提速。
不过,对于阻塞式IO的情况,比如文件读写,网络交互等,这时候IO可能会阻塞或等待,这时候如果采用多线程threading,就可以区执行别的线程,这样可以起到加速作用。
54. 利用Lock防止多个线程争用同一份数据
虽然GIL的限制下,同一时刻只能有一个线程运行,但是对于文件的访问和修改却可能是访问的同一个,而多线程可能会导致文件被破坏。因为当前线程执行的文件,可能被其他线程修改。
threading库中存在Lock类,可以写成下面这样,这时cnt变量就被加了锁了,不同线程之间必须用同一个锁。
from threading import Locklock = Lock()with lock:cnt += 1
55. 用Queue来协调各线程之间的工作进度
典型的生产者-消费者结构,我们可以采用队列来进行数据交互,该队列通常采用现有的list来实现,或者直接用collections中的deque,然后配合lock约束,但是这会面临很多问题,比如生产者和消费者的处理速度难以估计,生产者可能生产的慢而消费者可能消费的快,这时可能面临队列中没有数据的情况。
在多线程中,可以使用queue库中的Queue类,他考虑了线程中会遇到的一些问题,比如Queue类的get方法会一直阻塞直到有新数据可以返回,比如生产者太快了Queue队列满了,也会阻塞,直到被消费者消费掉,可以使用Queue的task_done()和join()方法来确保队列中所有元素处理完毕。
56. 学会判断什么场合必须做并发
程序范围变大、需求变复杂之后,经常要用多条路径平行地处理任务。fan-out与fan-in是最常见的两种并发协调(concurrency coordination)模式,前者用来生成一批新的并发单元,后者用来等待现有的并发单元全部完工。
57. 不要在每次fan-out时都新建一批Thread实例
正如前文所述,fan-out是生成一批新的并发单元,如果每次fan-out时都新建一批Thread实例就会存在一些问题:如维护困难,占用内存大,开销大,出错后难调试。
反例:
for _ in range(n):for _ in range(m):thread ....# 为矩阵中每个单元都创建一个线程
58. 学会正确地重构代码,以便用Queue做并发
不像上述那样为每一个单元都创建一个线程,可以只创建固定大小的线程数量,这样就降低了开销和内存占用。通过Queue来不断地向线程中加入需要处理的单元。
用Queue来重构57中遇到问题的代码,虽然比57好,但是也存在问题,比如需要重构很多代码。
59. 如果必须用线程做并发,那就考虑通过ThreadPoolExecutor实现
其实58中的操作已经比较类似用线程池了,而python中就提供了线程池的相关实现。concurrent.futures提供了ThreadPoolExecutor实现,结合线程和队列Queue的优势。如果你面对的需求,没办法用异步方案解决,而是必须执行完才能往后走(例如文件I/O),那么ThreadPoolExecutor是个不错的选择。
缺点:IO并行能力不高,因为设置了最大线程数max_workers
60. 用协程实现高并发的I/O
61. 学会用asyncio改写那些通过线程实现的I/O
Python已经将异步执行功能很好地集成到语言里面了,所以我们很容易就能把采用线程实现的阻塞式I/O操作转化为采用协程实现的异步I/O操作
62. 结合线程与协程,将代码顺利迁移到asyncio
63. 让asyncio的事件循环保持畅通,以便进一步提升程序的响应能力
64. 考虑用concurrent.futures实现真正的并行计算
想要实现高性能,可以采用c语言重写扩展模块,c语言本身比python更快,并且有原生线程可以用,python针对c扩展设计的API可以参考SWIG和CLIF。但是用c语言重写成本比较高,比如有的在python里面很简单的写法,在c语言里很复杂。移植过程中要做很多测试,确保没bug。Cython,Numba这些工具可以帮助我们顺利向c语言移植。
另一种方式,python的内置库multiprocessing提供了多进程机制,这种机制可以通过concurrent.futures使用。这种方案可以启动许多条子进程(child process),这些进程是独立于主解释器的,它们有各自的解释器与相应的全局解释器锁,因此这些子进程可以平行地运行在CPU的各个核心上面。每条子进程都能够充分利用它所在的这个核心来执行运算。这些子进程都有指向主进程的链接,用来接收所要执行的计算任务并返回结果。
想要发挥multiprocessing的优势,可以使用concurrent.futures中的函数来编写,如ProcessPoolExecutor,用这个库编写起来会比较方便。不要随便使用multiprocessing,因为他底层逻辑比较复杂,需要主进程和子进程之间进行数据交互,序列化反序列化等,用之前的方法无效时,考虑用这个。

若有收获,就点个赞吧
0 人点赞
