数据仓库分层(Layering)
目的
- 避免重复计算和重复开发
- 数据血缘追踪
- 把复杂问题切分成几部分完成,使问题简单化
- 提升数据开发过程对业务变更的弹性
分层模型
ODS(Operational Data Storage):运营数据层,这一层的数据是最接近业务数据的,数据源(数据库、日志等)中的数据经过ETL之后会进入本层,数据存储的schema和原始数据非常类似,大多数schema符合三范式的设计原则。
ODS层可能包含的数据表包括:用户信息表(id、身份信息、手机号等),订单表(用户id、商品id、发生时间等)等等一系列原始的业务数据。
ODS层常见的操作包括:结构化、清洗、去重、砍字段、字段拆分、提取、单位统一等等。
DWD(Data Warehouse Design):明细数据层(宽表),ODS的数据在这一层会按照主题组合成大宽表,同时,主题中的维度会被抽象出来,组成维表。
DWD层可能包含的数据表包括:订单主题表(订单部分、用户部分、商品部分等等)等宽表
DWD层常见的操作包括:连接(Join)、清洗(处理Join之后的NULL值)等
DWS(Data Warehouse Summary):汇总数据层,这一层的数据是基于ODS数据层做的汇总,例如按用户id、商品id、小时、天等等聚合,来进行各种公共指标的计算。
DWD层常见的操作包括:聚合(Group by)、计数、求和等
ADS(applicational Data Storage):应用数据层,这一层数据主要是针对特定应用,主要包含一些可复用性不高、复杂性较高(比值型、排名型等)的指标。此外,还有针对特定业务需求的数据组装,如横表转纵表、大宽表集市等等。
总之,ADS层数据是通过数据服务透出给业务系统使用的。
分层模型示意图:
TMP:每层的数据可能要经过多次处理才能完成,中间表可以存为TMP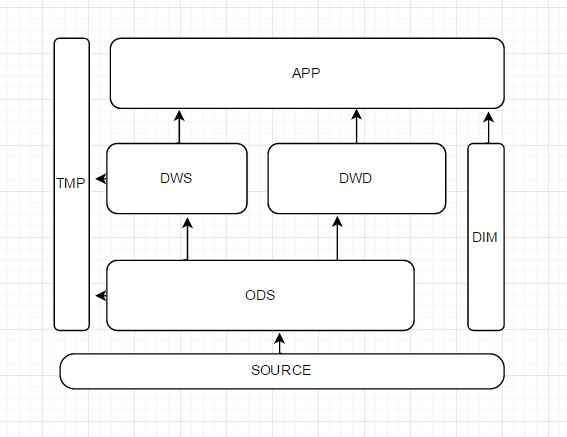
数仓为什么要分层?
如果不分层,都从原始数据获取,那么每次计算指标时都可能需要进行清洗数据、脱敏、去重这类操作,重复劳动。一旦出现问题,就直接通过原始数据进行排查,而指标可能涉及原始数据的多张表,非常麻烦。
分层优点:复杂问题简单化、清晰数据结构(方便管理)、增加数据的复用性、隔离原始数据(解耦)
注 意:数仓中各层建的表都是外部表
每层都做了什么?
ODS: 原始数据层 (存放原始数据,保持原貌不做处理)
1)用户行为数据:
是一个标准的json字符串,建立分区表,提高查询效率
采用lzo进行压缩,压缩/解压速度较快,合理的压缩率,且支持切片
采用parquet列式存储格式,统计相关的操作用列式存储效率高
2)用户业务数据:
是利用sqoop将数据从mysql导入HDFS,还可以使用DataX,甚至可以采用MR自定义inputFormat和 outputFormat的方式
DWD:明细数据层 (对ods层数据清洗:去除空值,脏数据,超过极限范围的数据)
1)ETL清洗掉不完整的数据
2)核心字段需要判断,比如订单ID,支付流水ID需要去除空值,订单金额、支付金额不能为负,也不能极大。
3)对手机号、身份证号等敏感数据脱敏
4)维度退化,将商品的一、二、三级分类退化到商品表
DWS:服务数据层 (轻度聚合)
1)形成宽表,如用户行为宽表、与用户购买商品明细行为宽表、商品宽表
用户行为宽表最宽,60-100个字段
2)商品详情到购物车转换率是多少
商品详情 ——- 购物车 ——- 订单 ——— 付款的转换比率
5% 50% 80%
3)每天的GMV是多少,哪个商品卖的最好?每天下单量多少?
(1)100万的日活每天大概有10万人购买,平均每人消费100元,一天的GMV在1000万
(2)面膜,每天销售5000个
(3)每天下单量在10万左右
ADS :应用数据层 (具体需求)
1)分析过多少指标?都有哪些指标?(一分钟说出30个左右指标)
具体参考高频面试题9.2.4小节
2) 分析过最有难度的指标?
讲出最近连续3周活跃用户数、最近7天内连续3天活跃用户数的实现逻辑
3.4 数仓建模问题,谈一谈建模经验和对数仓建模的理解
ODS层
保持数据原样,不做任何处理。分区,压缩,parquet列式存储
DWD层
确定业务过程 + 声明粒度 + 确定维度 + 确定事实
维度退化:维度建模(星型模型)
DWS层
每日聚合宽表
DWT层
累积宽表(从用户产生,一直到现在累积过程)
DWS和DWT建主题宽表的依据:站在维度的角度去观察事实表
创建主题宽表原则:拿事实表的度量值(个数、件数、次数、金额)
DWT主题宽表字段:拿事实表(首次、末次、今天的积累、连续30日积累)
ADS层
**
3.4.1 确定业务过程 + 声明粒度 + 确定维度 + 确定事实
数仓建模的核心在于确定 哪些表—>每条记录所代表的含义—>哪些字段。按照这个思路,我们来捋一捋。
1)确定业务过程:选择一条业务线,比如说下单、支付,都算一条业务线,只有确定了业务线,才便于确定这个业务线所涉及的表。
2)声明粒度:即确定表的一条记录所表示的范围,以订单表为例,一条记录是代表一次下单?一日下单?一周下单?一月下单?声明粒度的原则就是粒度最小,所以选择一次下单
3)确定维度:即确定事实表和哪些维表有关
维度表就是指那种通用的,数据比较固定的,例如用户、时间、地点、商品分类等等。
事实表则是业务线中,随业务进行,数据相应发生变化的表。
再举个实际的例子。银行对存款记账,A表中存放实际数据,包括账号、所属机构号、存款金额等,B表存放机构号和机构名称的对应关系。则A是事实表,B是维表。
4)确定事实:即确定事实表有哪些度量字段(个数、件数、次数、金额)

若有收获,就点个赞吧
0 人点赞
