本文基于jdk1.8版本进行解析,关于HashMap的源码解析网上有很多,这里着重写实际研究过程遇到的一些代码的理解。所以再看本文之前建议还是先找找其他文章先看看有个大概了解,或者对HashMap源码有一定了解之后进行阅读效果会好点,为啥会写本文实际也是因为我在研究网上写的博文之后发现有些写的不太详细所以才写该文。
HashMap实现原理
HashMap主要由一组散列数组组成,数组中的每个元素都是一个普通的Node,也有可能是TreeNode(红黑树),HashMap定位存储位置并不是使用我们常用的循环遍历的方式,而是通过计算出key的hash值,然后通过hash值与当前数组容量进行一个与操作来计算出存储的位置,避免了遍历数组与key值比较,当然散列数组也会有造成一些空间上的浪费,主要就是空间换时间上的一种策略。
tableSizeFor方法
该方法主要用于设置threshold(散列数组大小),该方法的作用是通过传进来的容量参数cap计算出最接近它的2的幂等数,比如如果cap是10则返回的是16,若cap=20则返回32,若cap等40则返回64等等。
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
方法解析:
- int n = cap-1; 这里为啥需要减一其实是为了解决cap本身就是2的幂等数,比如cap等于16,那么返回也应该是16,而如果没有减一操作计算出来的就是32,因为16的二进制会比15多一位,多一位即意味着要多乘一次2,所以需要减一最后再加一就刚好了
- ‘>>>’ : 无符号右移,看下图的区别

正如我们所知的,有符号数据类型二进制首位即为符号位,而>>>(无符号右移)与>>(有符号右移)的区别就在于符号位是否参与右移,无符号右移将会右移符合位这也导致为什么-10右移1位会变成一个正整数(2147483643),而有符号右移则不会右移符号位,所以负数右移还是负数。
- |= 位或操作:有点类似于+=,-=这种操作,一种便捷写法,如下图

10的二进制位1010,右移1位为0101,两者取或操作为1111,所以为15
- 中间核心的无符号右移跟位或1、2、4、16操作解析,这个操作就有点牛逼了,我们拿个例子来讲,比如65,这个数对应的二进制是1000001,看下图二进制的变化,进行到右移4位的时候已经将所有位数全部变成1,此时

这里开头第一个1非常重要,所有非零的数最大位一定是1,后面的所有操作都是这个1起了作用,一个int类型变量占32位,所以无论多大的变量经过5次的右移之后一定会全是1,第一次右移位或将开头的一个1变成2个1,第二次右移将前面2个1变成4个1,以此类推,当右移16位时就是将前面的16个1,与后面16个1位或得到一个32位的1
- 最后将得到的数加1即可得到最接近cap参数的2的幂等数。
与运算
第一个与运算符位于putVal中,此处的作用类似于求余,计算出value存放在数组中的位置
第二个与操作位于resize(扩容散列数组)中,用于判断链表中节点将被重新放在新扩容的奇偶列表中的哪个
这里为什么会单独拿这两个小细节进行解析呢?
因为(n-1)与oldCap实际相差了1但是实现的效果却是千差万别,比如初始是cap是16的时候,此时n-1应该是15,而扩容的时候oldCap就是16,也就是说 hash & 15 与 hash & 16的作用完全是不一样的。下面分开来讲:
- hash & 15 : 因为15的二进制是1111,所以跟15进行与操作那么得到的结果一定是小于等于15,从而快速技术出数组位置
- hash & 16 : 16的二进制是10000, 所以与16进行与操作只有两种结果就是0和16,该好resize的时候就可以根据这两种情况决定链表中的值新的存放位置
这种应用确实有点精巧,值得学习!!!!!!!!!!!!!!!!!!!!
resize 扩容操作
扩容操作主要逻辑主要就是创建一个2倍的数组,然后将原数组里面的Node重新分配存放地址,分配逻辑主要分为3种:
- 若原节点只存放一个值,则直接重新计算位置,与上面putVal的操作同
- 若原节点为红黑树(链表节点超过8个使用红黑树),则调用拆分方法(后面详解)
- 若原节点链表大于1小于8时,使用两个链表通过上面的与运算计算存存放

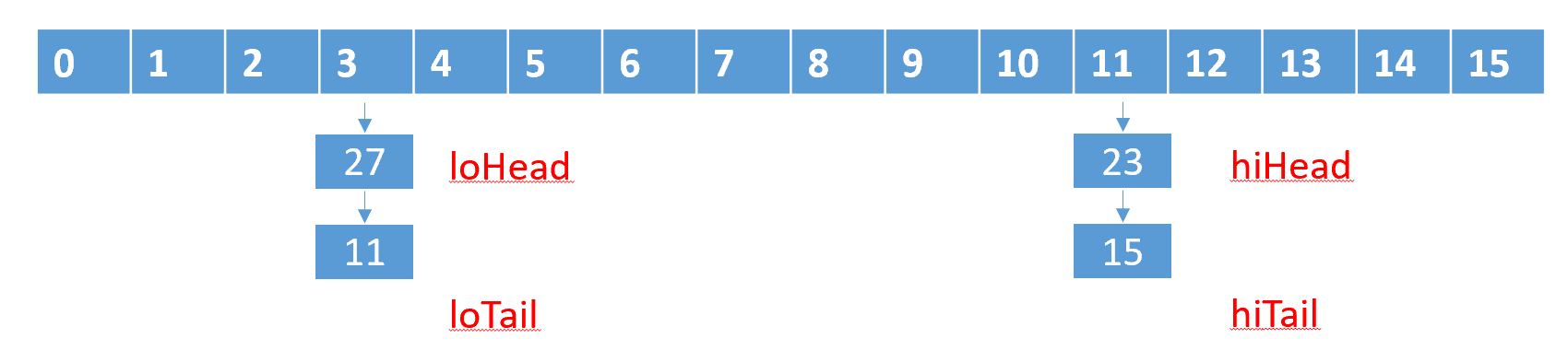
红黑树的后面专门来讲这里着重讲第三种情况,如下图,假设有一个Map初始为8,且存在一个链表长度为4的节点,当数组增长超过阈值时,需要对数组进行扩容,扩容方式为当前的两倍即为16
重新组装链表主要分为两个步骤:
- 将原先链表节点分为lo(低位)/hi(高位)两个链表,然后通过前面说的通过与操作计算出哪些节点需要被放在低位链表,哪些需要被放在高位链表,如上面的27和11放在低位链表,23和15放在高位链表,因为27和11与8进行与操作都是0,而23和15与8进行与操作都是8
- 分配完成之后,低位链表还是放在原先的位置3,而高位链表则放在3+8=11的位置,而不是重新进行计算
TreeNode红黑树解析
红黑树平衡操作主要应用的时机是插入和删除,核心平衡方法有两个:balanceInsertion和balanceDeletion,两个工具方法rotateLeft(左旋)和rotateRight(右旋)
我们这里先从插入节点平衡来进行解析吧,因为我觉得不管是新增还是删除,本质上平衡操作就是为了让整个红黑树遍历所有分支所有黑节点必须一致。
红黑树详细可以查看这篇博文(https://www.jianshu.com/p/e136ec79235c)
插入操作解析
入口方法,当链表长度超过8时,将链表转换为红黑树

这里的逻辑主要就是遍历普通Node链表先转换成TreeNode,并将组成新的双向链表,然后调用treeify将双向列表转换成标准红黑树。
- 步骤1-2 以链表第一个节点为根节点,遍历整个链表将链表上的节点按照左小右大的原则插入到二叉树的合适位置,
- 每插入一个节点平衡一次二叉树,使其变成标准红黑树(详情 查看)
- 将平衡之后的红黑树有可能根节点也会相应变化,所以需要重新将根节点绑到散列数组是上(moveRootToFront)
- checkInvariants 红黑树合法性校验,判断各个树节点关系是否合法,比如左节点是否比父节点小,右节点是否比父节点大等等

图中红框里面的逻辑可能比较绕,这里谈谈我自己的理解,HashMap中的链表本身就是双向链表,而链表在转红黑树的时候,还保留了双向链表的属性,而这里的逻辑就是要把新的root节点从原来的链表中摘出来放到队首位置。然后将原来的root节点放到新的root节点的后面。
删除操作解析
- 无子节点时,删除节点可能为红色或者黑色;
1.1 如果为红色,直接删除即可,不会影响黑色节点的数量;
1.2 如果为黑色,则需要进行删除平衡的操作了(balanceDeletion);
- 只有一个子节点时,可以通过替换的方式将需要删除的节点替换到子节点,然后删除子节点就等同于场景1
2.1 删除节点为黑色,子节点为红色,替换节点位置后,相当于场景1.1无影响
2.2 删除节点为红色或黑色,子节点为黑色,替换节点位置后,相当于场景1.2需要进行平衡操作
- 有两个子节点时,与二叉搜索树一样,使用后继节点作为替换的删除节点,情形转至为1或2处理。
3.1 后继节点无子节点,则转换为场景1
3.2 后继节点有一个子节点,则通过转换为场景2然后再转换为场景1
后继节点:右子树中最左节点,这也意味着后继节点要么没有子节点,又么只有右子节点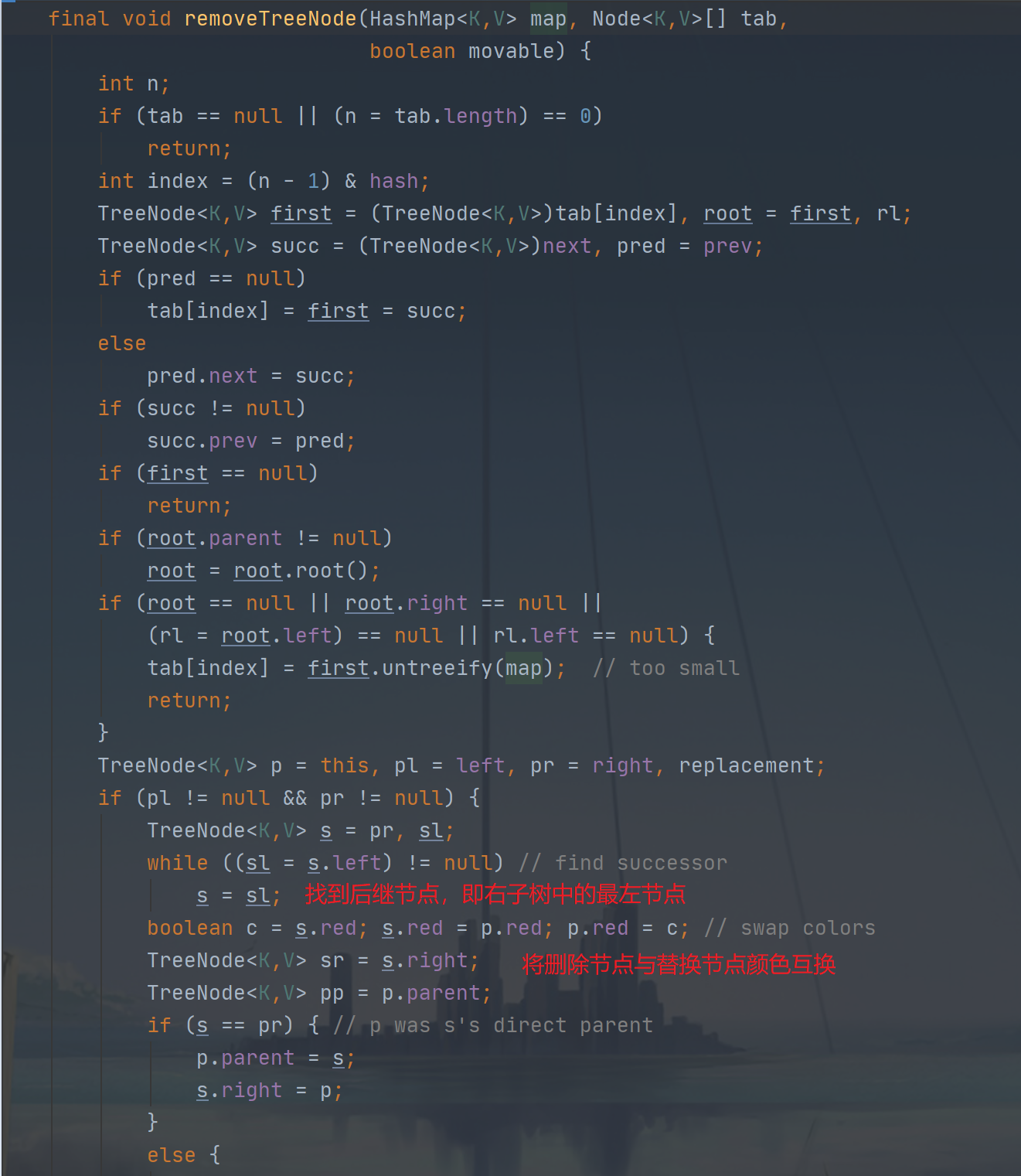


(未完待续。。。)
平衡插入红黑树解析
红黑树直接插入场景:
- 插入根节点,直接插入
- 父节点为根节点,直接插入
- 父节点为红色节点,直接插入
红黑树需要平衡场景(父节点为红色,因为红色节点不能连续两个):
- 叔叔节点为红色,直接将父节点和叔叔节点置黑,爷爷节点置红,然后将当前节点设置为爷爷节点,进行下一轮平衡
叔叔节点为黑色或者为空,可以分成两种情况:
a) 当前节点为左节点,直接以父节点进行右旋一次<br /> b) 当前节点为右节点,先以父节点左旋一次,将当前节点设置为左节点满足a操作的条件,然后再进行右旋一次
上面操作是父节点位于左边,叔叔节点位于右边的情况,如果反过来父节点位于右边,叔叔节点位于左边,则只需要将左旋和右旋颠倒一下即可,总体逻辑一样。
整个平衡过程是迭代进行的,有可能平衡之前叔叔节点是红色而下次平衡叔叔节点就变成了黑色的情况。
红黑树操作工具方法
左旋操作

右旋操作

赋值细节

我们来看下整个HashMap中充斥着大量上图这种逻辑判断语句中进行赋值,这也是一种简化代码写法。

若有收获,就点个赞吧
0 人点赞
