- HashMap涉及的知识点非常多,但是HashMap的学习难度不低,一次性学明白是比较难,只能逐步的学习,慢慢丰满对HashMap的理解;
而这篇文章也是数据结构与算法的第一篇,同时会添加一些基础性的知识在其中;
一.容器与结构
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关;
- 数据结构的本质:容器的设计规则;
-
二.容器类别与结构本质
在JAVA中实际的数据容器有两种
- 1.基本存储单元(单个数据存储,包含两块基本数据类型,对象);
- 2.连续数据存储(数组);
- 数据结构的特征:
- 1.对于数据类型设计;
- 2.对于数据存储与提取设计;
- 3.对于数据物理结构设计;
-
三.数组、顺序表、链表、Hash表
3.1.数组
一片物理上连续的大小确定的储存空间;
- 优点:查询快,修改也非常快;
缺陷:无法对数据进行动态的增删改查;
物理上连续,逻辑上连续,大小可以动态增加。eg:ArrayList;
3.3.链表
物理上不连续,逻辑上连续,可以动态的增加和删除节点。eg:LinkedList;
-
3.4.Hash表
-
四.ArrayList和LinkedList
ArrayList的add实际上是System.arraycopy操作,add、remove涉及大量数据的arraycopy(非常耗时);
4.1.ArrayList的面试题
ArrayList删除元素有三种方式,for循环(顺序或倒序),增强for,迭代器。但是只有迭代器删除或倒序删除才不会报错,原因是什么?
- for循环:执行System.arraycopy方法时,导致删除元素时涉及到数组元素的移动。
- 对于顺序删除元素,删除了前面的元素会影响后面元素的删除;
- 对于倒序删除元素,删除了前面的元素不会影响后面元素的删除;
- 增强for
- for循环:执行System.arraycopy方法时,导致删除元素时涉及到数组元素的移动。
如果业务中,诶呦频繁指定位置去插数据的需求,不管有多大量,使用ArrayList;
- 需要频繁往整个队列位置进行插入数据;
● ArrayList还是LinkedList?使用不当性能差千倍
五.HashMap
-
5.1.概念
在梳理HashMap的原理之前,我们先弄明白一些概念;
- 散列表(也叫做哈希表):这种数据结构提供了键(Key)和Value的映射关系。给出Key就能查出所匹配的Value;
- 散列表本质上是一个数组;
- hash 函数(hash 函数,即散列函数,或叫哈希函数):
- 可以将不定长的输入,通过散列算法转换成一个定长的输出,这个输出就是散列值;
- hash 函数并不能保证得到唯一的输出值,不同的输入也有可能得到相同的输出;
- 哈希冲突:不同的Key转换成的数组索引相同;
- 哈希冲突的解决办法,开放寻址法和链表法(HashMap-JDK1.7使用的是链表法);
-
5.2.HashMap的工作原理
分别从put(写),get(读)、resize(扩容)三个方面讲解HashMap即可;
- put:当我们将键值对传递给put方法时(根据源码可知)
- 1.(会调用键对象的hashCode()方法来计算hashcode,然后调用哈希函数计算散列值,接着根据数组长度和散列值)计算Entry所在的数组下标值;
- 2.分两种情况
- 如果数组中对应的元素为空,直接将元素放入到该位置;
- 数组元素不为空,即存在冲突,插入到对应的链表中即可(采用的是头插法,原因:因为HashMap的发明者认为,新插入的节点被查找的可能性更大);
- 看代码更直观 ```java //先计算key的hash值 //根据hash值找到数组位置,再往链表中添加元素O(1)
public V put(K key, V value) {
//…
//计算散列值
int hash = hash(key);
//计算对应在数组中的index
int i = indexFor(hash, table.length);
for (Entry
modCount++;addEntry(hash, key, value, i);return null;
}
static int indexFor(int h, int length) { //使用&不但效果上等同于取模运算,而且大大提高了效率。 //index值完全取决与Key的HashCode的最后几位 return h & (length-1); }
- get:对key值做一次hash计算,然后在计算出该散列值对应的数组的索引位置index,接着就比较数组的index对应的entry,其key值是否与传入的key相同,相同则返回entry,不同,则遍历该entry,在链表上查找,找到了就返回;```java//先计算key的hash值,根据hash值找到数组位置,再遍历链表public V get(Object key) {if (key == null)return getForNullKey();Entry<K,V> entry = getEntry(key);return null == entry ? null : entry.getValue();}final Entry<K,V> getEntry(Object key) {if (size == 0) {return null;}int hash = (key == null) ? 0 : hash(key);for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;}return null;}
resize:
头插法引发的问题:在多线程下头插法会在两个线程同时对其扩容时将对象间的复制引用变更为自己引用自己,已导致当前数组不会结束,同时多个线程间全部跑死的情况。
为什么出现死环,怎么解决
- 因为头插法,完成数据替换后,会出现前后顺序颠倒(为了避免尾部遍历),
如果出现线程切换问题,造成相互引用,从而出现死环; JDK1.8的解决方案(详细代码分析后续再补充):不进行头插法,采用尾插,同时加入高低位,在结束后,断掉末尾,高低位分开插入;
5.3.1.头插法的代码
```java void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; }
Entry[] newTable = new Entry[newCapacity]; transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
- 因为头插法,完成数据替换后,会出现前后顺序颠倒(为了避免尾部遍历),
//分析该方法-JDK1.7版本问题最大点就是该方法
//死环发生的概率不高
//头插法的弊端,一次扩容,内部的数据会形成颠倒
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry
-
5.3.2.死环的产生
HashMap在多线程下运行产生死环,可以简单的先理解(kerwin老师的讲解比较容易理解,只是未像上面的博客中那么详细);
5.4.总结
通过上面原理、头插法、死环的分析,对JDK1.7版本的HashMap已经有很不错的理解了。但是HashMap可以从多角度去思考,下面单独对HashMap的问题进行统一的整理;
六.问题整理
6.1.什么是HashMap
参考文章:什么是HashMap
- 定义上:HashMap是用哈希表(数组加单链表)+红黑树实现的map类;
HashMap的特点:
两个对象的Hashcode相同,哈希后的散列值会相同,对应在数组上的索引会相同,此时存在着哈希冲突;
-
6.3.如果两个键的hashcode相同如何获取值对象
找到数组所对应的index位置之后,遍历该位置对应的链表,通过equals方法比较key值去找到LinkedList中正确的节点,最终找到要找的值对象;
6.4.如果HashMap的大小超过了负载因子定义的容量,该怎么办
-
6.5.重新调整HashMap大小存在着什么问题
有线程切换的情况下,可能会产生死环;
但为什么要在多线程下使用HashMap,而不是直接使用ConcurrentHashMap(反问即可);
6.6.为什么String、Integer这样的wrapper类适合作为键
因为能保证key的不变性,保证放入到HashMap中和从中取出的值是一样的。
因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点;
6.7.我们可以使用自定义的对象作为键吗
- 可以,只要它遵守了equals()和hashCode()方法的定义规则。并且当对象插入到Map中之后将不会再改变了。
如果这个自定义对象是不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。如果这个对象是可变的,当属性值改变了后,他的hash相应改变了,get的时候将找不到原对象了;
6.8.HaspMap的默认初始长度是16,并且每次扩展长度或者手动初始化时,长度必须是2的次幂。其原因是什么
2^x - 1的结果的二进制永远是111111(n个1),如此就可以对低位进行截取,同时将所有的数据落到一个相对均匀分配的位置;
长度是16或者其他2的次幂,Length - 1的值的所有二进制位全为1,这种情况下,index的结果就等同于Hashcode后几位的值。只要输入的Hashcode本身分布均匀,Hash算法的结果就是均匀的;
6.9.为什么扩容是两倍扩容
每次扩容都是2倍,为了保证2的幂次方;
因为2的幂次方,一定程度上解决了hash冲突,但是没有完全解决;
七.Java8中的HashMap
Hash冲突不再是链表来保存相同index的节点,相应的采用红黑树(高性能的平衡树)来保存冲突节点;
JDK1.8提供两套方案:
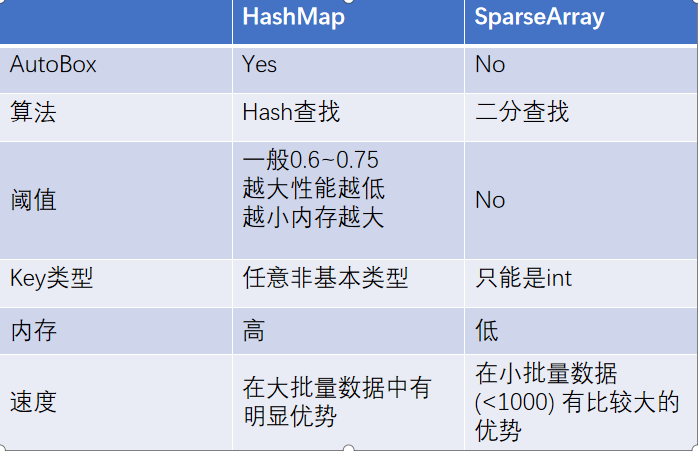
对于Android端,能用SparseAarry则用,不用HashMap(通过简单的demo进行了测试,省空间同时也省时间),其内部使用了两个数组。
- 增:根据key值进行二分查找,找到可以添加元素的位置,然后插入数据,并移动其它数据;
- 删(伪删除,标记成delete):根据key值进行二分查找,找到数组下标,取出对应value值;
- 查:根据hash值找到数组位置,再从链表中删除节点;
- 频繁的增删,用的越多,速度越快(其原因是伪删除);
- 缺点:key是int类型;
- SparseAarry为了解决哈希冲突,但是做了限制 做了两个平行数组;
九.HashMap对比SparseAarry

若有收获,就点个赞吧
0 人点赞
