1. Spirng Data JPA 与 Hibernate 的关系
JPA是一套规范,内部是有接口和抽象类组成的。hibernate是一套成熟的ORM框架,而且Hibernate实现了JPA规范。
Spring Data JPA是Spring提供的一套对JPA操作更加高级的封装。SpringData Jpa 极大简化了DAO 层代码。如何简化的呢? 使用了SpringDataJpa,我们的dao层中只需要写接口,就自动具有了增删改查、分页查询等方法。
我们使用JPA的API编程,意味着站在更高的角度上看待问题(面向接口编程)。在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
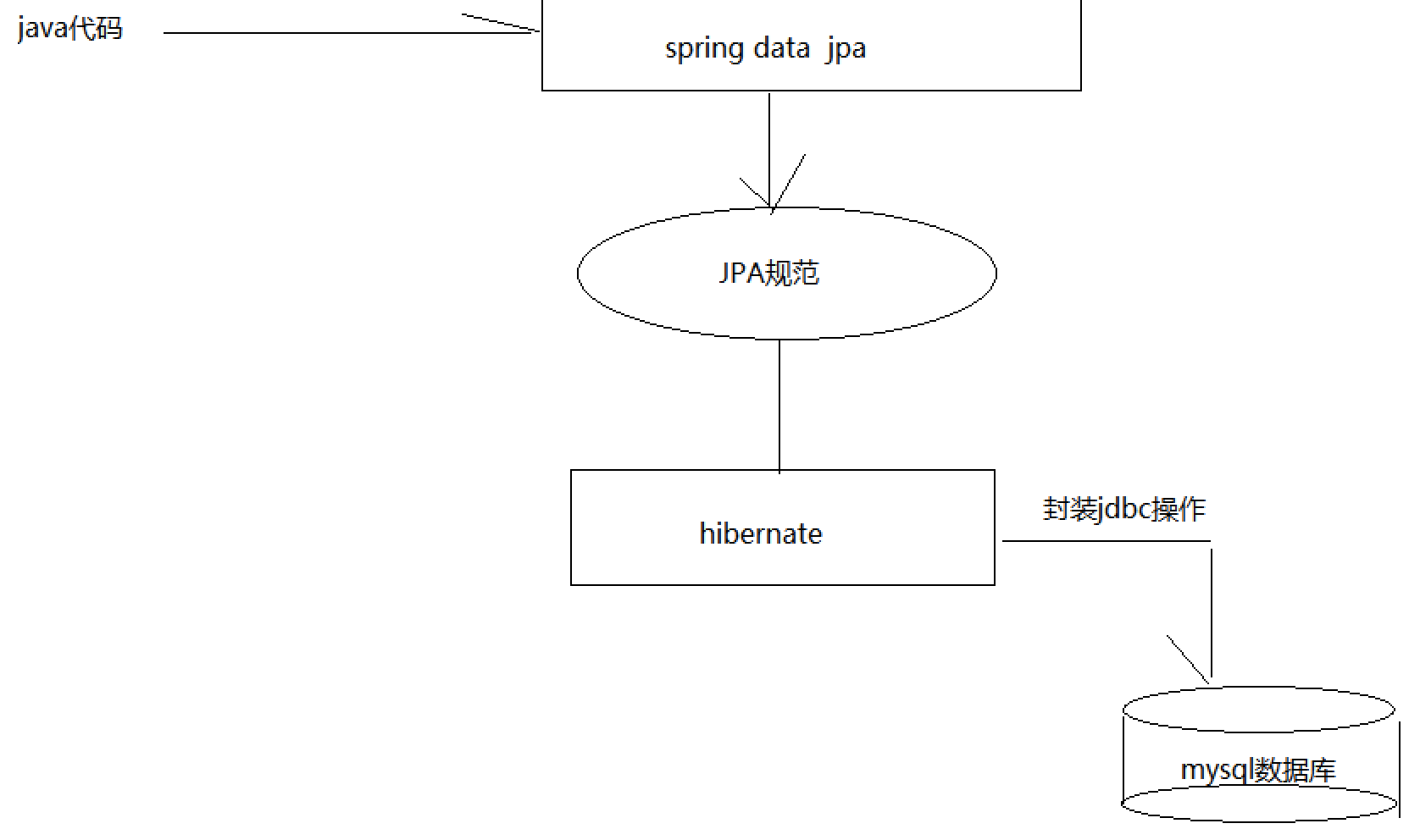
一句话:Spring Data Jpa 让我们不需要再写 jpql 语句了!
2. 实现原理
1.通过JdkDynamicAopProxy的invoke方法创建了一个动态代理对象
2.SimpleJpaRepository当中封装了JPA的操作(借助JPA的api完成数据库的CRUD)
3.通过hibernate完成数据库操作(封装了jdbc)
3. 基本使用
A. JPA 注解
- 实体类和表的映射:
- @Entity - 指定当前类是实体类。
- @Table - 指定实体类和表之间的对应关系。
属性:name- 指定数据库表的名称
- 主键字段的映射:
- @Id - 声明主键的配置
- @GeneratedValue - 配置主键的生成策略
属性:strategy- GenerationType.IDENTITY :自增,mysql
底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增) - GenerationType.SEQUENCE : 序列,oracle
底层数据库必须支持序列 - GenerationType.TABLE : jpa提供的一种机制,通过在数据库中建立一个 table hibernate_sequences, 来记录自增主键。
- GenerationType.IDENTITY :自增,mysql
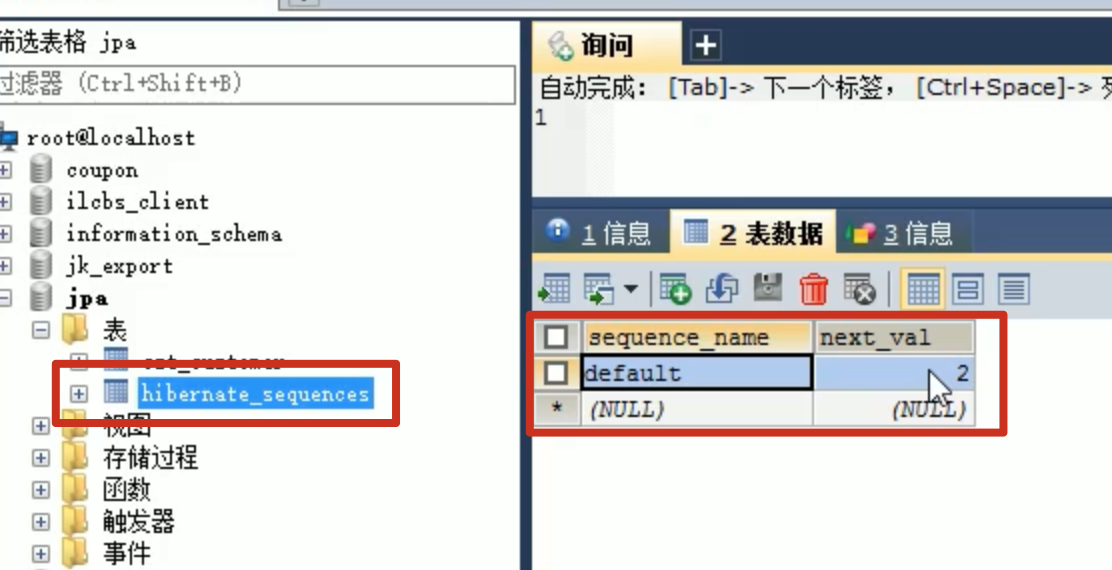
- GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略 ==> 一般会选择TABLE
- 普通字段的映射:
- @Column:配置属性和字段的映射关系
属性:name- 数据库表中字段的名称 ```java package com.example.domain;
- @Column:配置属性和字段的映射关系
import javax.persistence.*; import java.io.Serializable;
/**
- @ClassName Customer
- @Description TODO
- @Author Henry
- @Date 2021-01-17 8:03 p.m.
- @Version 1.0
*/
@Entity
@Table(name = “cst_customer”)
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = “cust_id”)
private Long custId;
@Column(name = “cust_name”)
private String custName;
@Column(name = “cust_source”)
private String custSource;
@Column(name = “cust_level”)
private String custLevel;
@Column(name = “cust_industry”)
private String custIndustry;
@Column(name = “cust_phone”)
private String custPhone;
@Column(name = “cust_address”)
private String custAddress;
}
```
B. 编写一个符合springDataJpa的dao层接口
- 只需要编写dao层接口,不需要编写dao层接口的实现类
- dao层接口规范:
- 需要继承两个接口(
JpaRepository,JpaSpecificationExecutor)- JpaRepository接口 - 封装了基本CRUD操作
JpaRepository``<操作的实体类类型,实体类中主键属性的类型> - JpaSpecificationExecutor接口 - 封装了复杂查询(比如分页操作)
JpaSpecificationExecutor<操作的实体类类型>
- JpaRepository接口 - 封装了基本CRUD操作
- 提供相应泛型 ```java package com.example.dao;
- 需要继承两个接口(
import com.example.domain.Customer; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
public interface ICustomerDao extends JpaRepository
}
<a name="G5P7d"></a>## C. 基本的增删改查:- dao.findByXXX(<condition_value>)- dao.findAll()- dao.save(<T> obj): 保存 或者 更新 - (依据:传递的实体类对象中,是否包含id属性)- 注意:如果 id 不存在,插入一条新数据,这条数据的 id 是自动生成的,与实体类对象的 id 值无关- dao.deleteById(id): 根据 id 删除dao.delete(<T> obj): 根据实体类对象中的 id```java@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration(locations = "classpath:applicationContext.xml") //指定 Spring 容器的配置信息public class ICustomerDaoTest {@Autowiredprivate ICustomerDao customerDao;@Testpublic void testFindOne(){Optional<Customer> customer = customerDao.findById(1L);System.out.println(customer.get());}@Testpublic void testSave(){Customer customer = new Customer();customer.setCustName("Whitney");customer.setCustIndustry("education");customer.setCustLevel("senior");customerDao.save(customer);}@Testpublic void testUpdate(){Customer customer = new Customer();customer.setCustId(4L);customer.setCustAddress("Canada");customerDao.save(customer);}@Testpublic void testDelete(){customerDao.deleteById(4L);}}
Spring Data Jpa 查询
1. 借助接口中定义好的方法
- 查找全部:List
list = dao.findAll() - 统计:Long count = dao.count();
是否存在:boolean isExisted = dao.existsById(1L)
2. jpql或 sql 的查询方式
配置jpql语句,使用的@Query注解:
value 属性 : jpql 或者 sql语句
- nativeQuery 属性: 查询方式
- true : sql查询
- false(默认值):jpql查询
```java
/**
- 案例:根据客户名称查询客户
- 使用jpql的形式查询
- jpql:from Customer where custName = ? */ @Query(value=”from Customer where custName = ?”) public Customer findJpql(String custName);
/**
- 使用sql的形式查询:
- 查询全部的客户
- sql : select from cst_customer; / @Query(value=”select from cst_customer where cust_name like ?1”,nativeQuery = true) public List

若有收获,就点个赞吧
0 人点赞
