可重复读隔离级别是如何实现的?
「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View。
想要知道可重复读隔离级别是如何实现的,我们需要了解两个知识:
- Read View 中四个字段作用;
- 聚族索引记录中两个跟事务有关的隐藏列;
那 Read View 到底是个什么东西?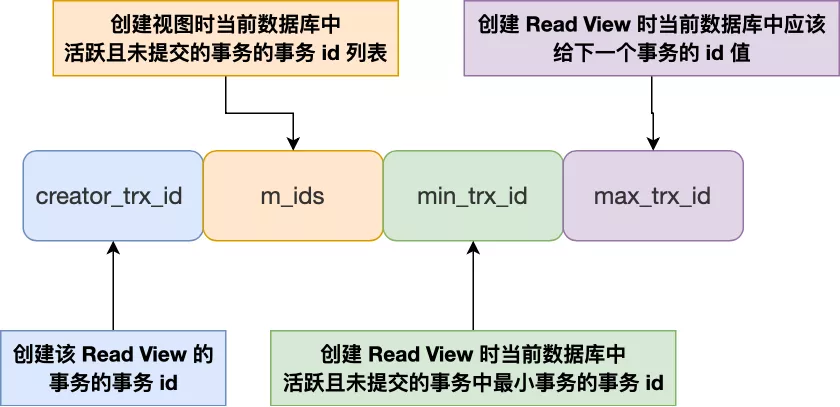
Read View 有四个重要的字段:
- m_ids :指的是创建 Read View 时当前数据库中活跃且未提交的事务的事务 id 列表,注意是一个列表。
- min_trx_id :指的是创建 Read View 时当前数据库中活跃且未提交的事务中最小事务的事务 id,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
知道了 Read View 的字段,我们还需要了解聚族索引记录中的两个隐藏列,假设在账户余额表插入一条小林余额为 100 万的记录,然后我把这两个隐藏列也画出来,该记录的整个示意图如下: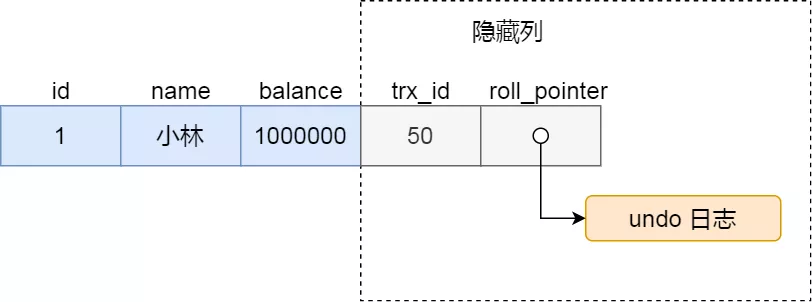
对于使用 InnoDB 存储引擎的数据库表,它的聚族索引记录中都包含下面两个隐藏列:
- trx_id,当一个事务对某条聚族索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚族索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
了解完这两个知识点后,就可以跟大家说说可重复读隔离级别是如何实现的。
假设事务 A 和 事务 B 差不多同一时刻启动,那这两个事务创建的 Read View 如下:
事务 A 和 事务 B 的 Read View 具体内容如下:
- 在事务 A 的 Read View 中,它的事务 id 是 51,由于与事务 B 同时启动,所以此时活跃的事务的事务 id 列表是 51 和 52,活跃的事务 id 中最小的事务 id 是事务 A 本身,下一个事务 id 应该是 53。
- 在事务 B 的 Read View 中,它的事务 id 是 52,由于与事务 A 同时启动,所以此时活跃的事务的事务 id 列表是 51 和 52,活跃的事务 id 中最小的事务 id 是事务 A,下一个事务 id 应该是 53。
然后让事务 A 去读账户余额为 100 万的记录,在找到记录后,它会先看这条记录的 trx_id,此时发现 trx_id 为 50,通过和事务 A 的 Read View 的 m_ids 字段发现,该记录的事务 id 并不在活跃事务的列表中,并且小于事务 A 的事务 id,这意味着,这条记录的事务早就在事务 A 前提交过了,所以该记录对事务 A 可见,也就是事务 A 可以获取到这条记录。
接着,事务 B 通过 update 语句将这条记录修改了,将小林的余额改成 200 万,这时 MySQL 会记录相应的 undo log,并以链表的方式串联起来,形成版本链,如下图: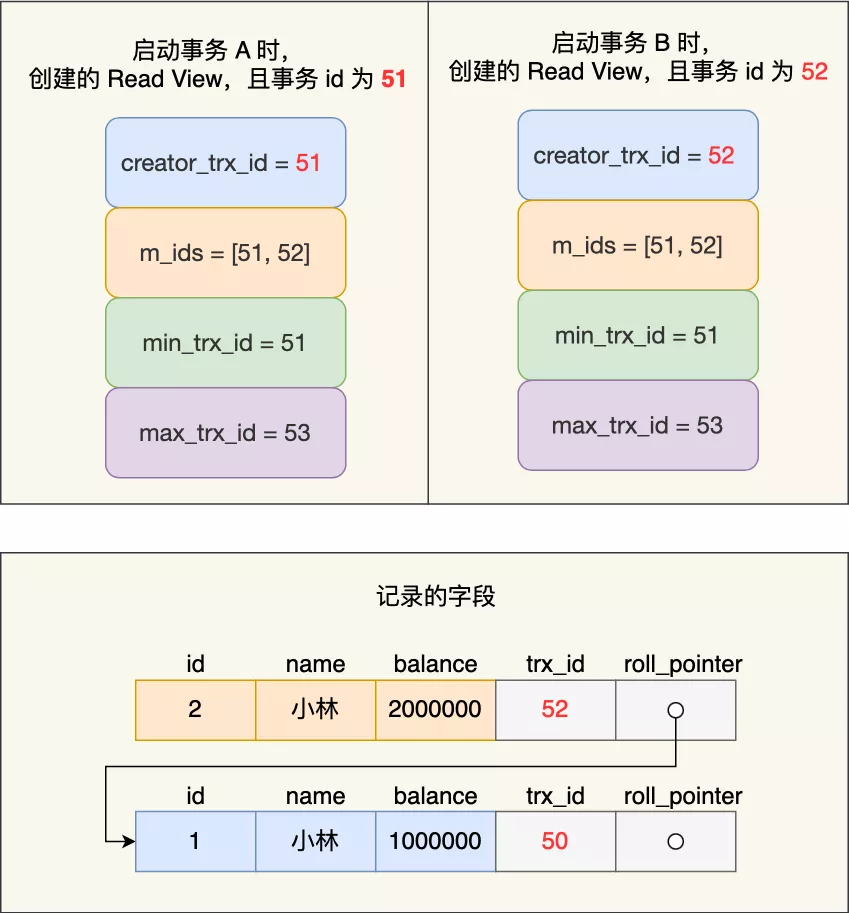
你可以在上图的「记录字段」看到,由于事务 B 修改了该记录,以前的记录就变成旧版本记录了,于是最新记录和旧版本记录通过链表的方式串起来,而且最新记录的 trx_id 是事务 B 的事务 id。
然后如果事务 A 再次读取该记录,发现这条记录的 trx_id 为 52,比自己的事务 id 还大,并且比下一个事务 id 53 小,这意味着,事务 A 读到是和自己同时启动事务的事务 B 修改的数据,这时事务 A 并不会读取这条记录,而是沿着 undo log 链条往下找旧版本的记录,直到找到 trx_id 等于或者小于事务 A 的事务 id 的第一条记录,所以事务 A 再一次读取到 trx_id 为 50 的记录,也就是小林余额是 100 万的这条记录。
「可重复读」隔离级别就是在启动时创建了 Read View,然后在事务期间读取数据的时候,在找到数据后,先会将该记录的 trx_id 和该事务的 Read View 里的字段做个比较:
- 如果记录的 trx_id 比该事务的 Read View 中的 creator_trx_id 要小,且不在 m_ids 列表里,这意味着这条记录的事务早就在该事务前提交过了,所以该记录对该事务可见;
- 如果记录的 trx_id 比该事务的 Read View 中的 creator_trx_id 要大,且在 m_ids 列表里,这意味着该事务读到的是和自己同时启动的另外一个事务修改的数据,这时就不应该读取这条记录,而是沿着 undo log 链条往下找旧版本的记录,直到找到 trx_id 等于或者小于该事务 id 的第一条记录。
就是通过这样的方式实现了,「可重复读」隔离级别下在事务期间读到的数据都是事务启动前的记录。
这种通过记录的版本链来控制并发事务访问同一个记录时的行为,这就叫 MVCC(多版本并发控制)。

若有收获,就点个赞吧
0 人点赞
