广义上
数据结构就是指一组数据的存储结构。算法就是操作数据的一组方法。
狭义上
是指某些著名的数据结构和算法,比如队列、栈、堆、二分查找、动态规划等。
复杂度
想要学习数据结构与算法,首先要掌握一个数据结构与算法中最重要的概念——复杂度分析。
数据结构和算法解决的是如何更省、更快地存储和处理数据的问题,因此,我们就需要一个考量效率和资源消耗的方法,这就是复杂度分析方法。所以,如果你只掌握了数据结构和算法的特点、用法,但是没有学会复杂度分析,那就相当于只知道操作口诀,而没掌握心法。只有把心法了然于胸,才能做到无招胜有招!
**
结构图
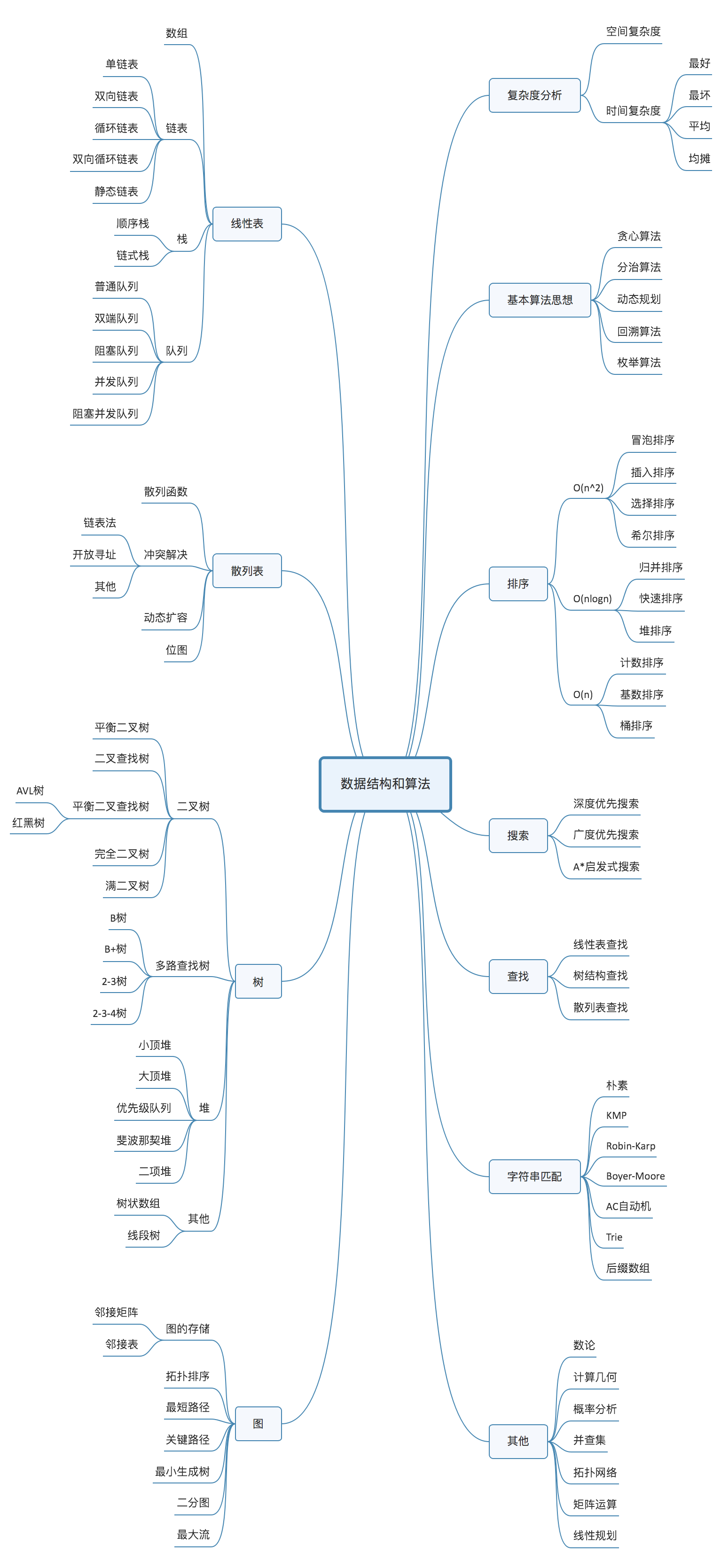
常用
上图并不需要全部掌握,这边挑了最使用的20个数据结构与算法。
这里面有 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树;10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法。
多问为什么
学习数据结构和算法的过程,是非常好的思维训练的过程,所以,千万不要被动地记忆,要多辩证地思考,多问为什么。如果你一直这么坚持做,你会发现,等你学完之后,写代码的时候就会不由自主地考虑到很多性能方面的事情,时间复杂度、空间复杂度非常高的垃圾代码出现的次数就会越来越少。你的编程内功就真正得到了修炼。
复杂度分析
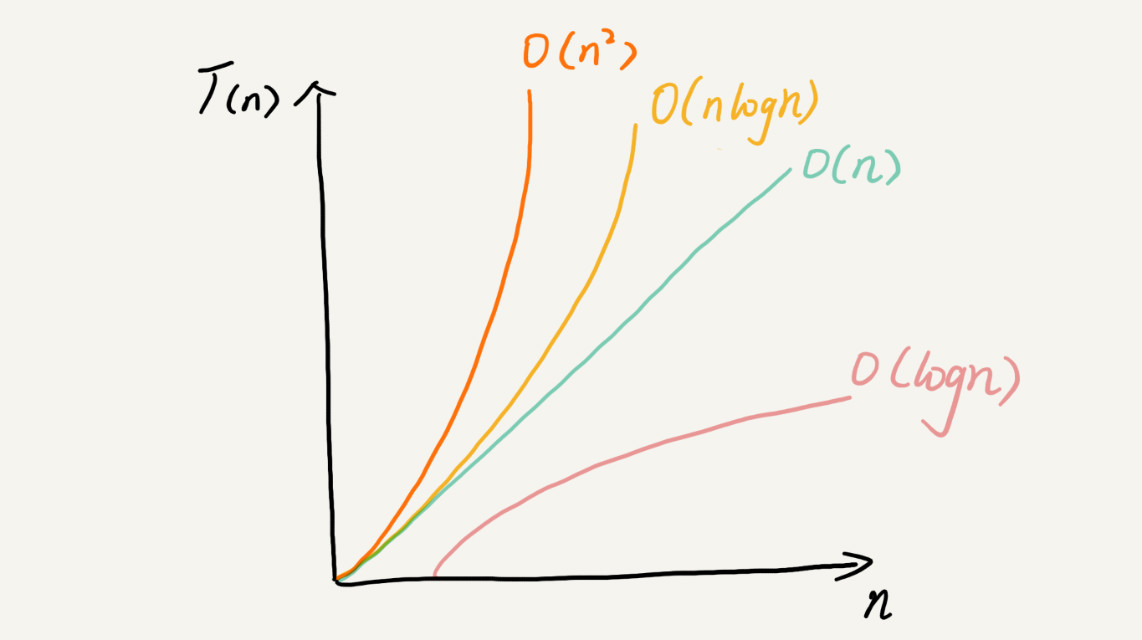
时间复杂度的全称是渐进时间复杂度,表示算法的执行时间与数据规模之间的增长关系。总的时间复杂度就等于量级最大的那段代码的时间复杂度。

logn
log3 n = log3 2 * log2 n => 统称 logn
i=1;while (i <= n) { i = i * 2; }i=1;while (i <= n) { i = i * 3; }
O(m+n) O(m*n)
int cal(int m, int n) {int sum_1 = 0;int i = 1;for (; i < m; ++i) {sum_1 = sum_1 + i;}int sum_2 = 0;int j = 1;for (; j < n; ++j) {sum_2 = sum_2 + j;}return sum_1 + sum_2;}
空间复杂度
空间复杂度全称就是渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系。
void print(int n) {int i = 0;int[] a = new int[n];for (i; i <n; ++i) {a[i] = i * i;}for (i = n-1; i >= 0; --i) {print out a[i]}}
第 2 行代码中,我们申请了一个空间存储变量 i,但是它是常量阶的,跟数据规模 n 没有关系,所以我们可以忽略。第 3 行申请了一个大小为 n 的 int 类型数组,除此之外,剩下的代码都没有占用更多的空间,所以整段代码的空间复杂度就是 O(n)。
常见的空间复杂度就是 O(1)、O(n)、O(n2 ),像 O(logn)、O(nlogn) 这样的对数阶复杂度平时都用不到。而且,空间复杂度分析比时间复杂度分析要简单很多。
渐进时间,空间复杂度分析为我们提供了一个很好的理论分析的方向,并且它是宿主平台无关的,能够让我们对我们的程序或算法有一个大致的认识,让我们知道,比如在最坏的情况下程序的执行效率如何,同时也为我们交流提供了一个不错的桥梁,我们可以说,算法1的时间复杂度是O(n),算法2的时间复杂度是O(logN),这样我们立刻就对不同的算法有了一个“效率”上的感性认识。
当然,渐进式时间,空间复杂度分析只是一个理论模型,只能提供给粗略的估计分析,我们不能直接断定就觉得O(logN)的算法一定优于O(n), 针对不同的宿主环境,不同的数据集,不同的数据量的大小,在实际应用上面可能真正的性能会不同,个人觉得,针对不同的实际情况,进而进行一定的性能基准测试是很有必要的,比如在统一一批手机上(同样的硬件,系统等等)进行横向基准测试,进而选择适合特定应用场景下的最有算法。
综上所述,渐进式时间,空间复杂度分析与性能基准测试并不冲突,而是相辅相成的,但是一个低阶的时间复杂度程序有极大的可能性会优于一个高阶的时间复杂度程序,所以在实际编程中,时刻关心理论时间,空间度模型是有助于产出效率高的程序的,同时,因为渐进式时间,空间复杂度分析只是提供一个粗略的分析模型,因此也不会浪费太多时间,重点在于在编程时,要具有这种复杂度分析的思维。
最好、最坏情况时间复杂度
最好 O(1), 最坏 O(n)
// n表示数组array的长度int find(int[] array, int n, int x) {int i = 0;int pos = -1;for (; i < n; ++i) {if (array[i] == x) {pos = i;break;}}return pos;}
平均情况时间复杂度和均摊时间复杂度
每个值的发生概率不一样,把概率和对应的情况时间复杂度进行计算就是概率论中的加权平均值,也叫做期望值。所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。
数组
最基础、最简单的数据结构。在内存中以连续的存储单元进行存储。地址为
a[i]_address = base_address + i * data_type_size
为什么数组都是以 0 开始编号
如果用 a 来表示数组的首地址,a[0]就是偏移为 0 的位置,也就是首地址,a[k]就表示偏移 k 个 type_size 的位置,所以计算 a[k]的内存地址只需要用上面的公式
但是,如果数组从 1 开始计数,那我们计算数组元素 a[k]的内存地址就会变为:
a[i]_address = base_address + (i - 1) * data_type_size
对比两个公式,我们不难发现,从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。
数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。
C 语言设计者用 0 开始计数数组下标,之后的 Java、JavaScript 等高级语言都效仿了 C 语言,或者说,为了在一定程度上减少 C 语言程序员学习 Java 的学习成本,因此继续沿用了从 0 开始计数的习惯。实际上,很多语言中数组也并不是从 0 开始计数的,比如 Matlab。甚至还有一些语言支持负数下标,比如 Python。
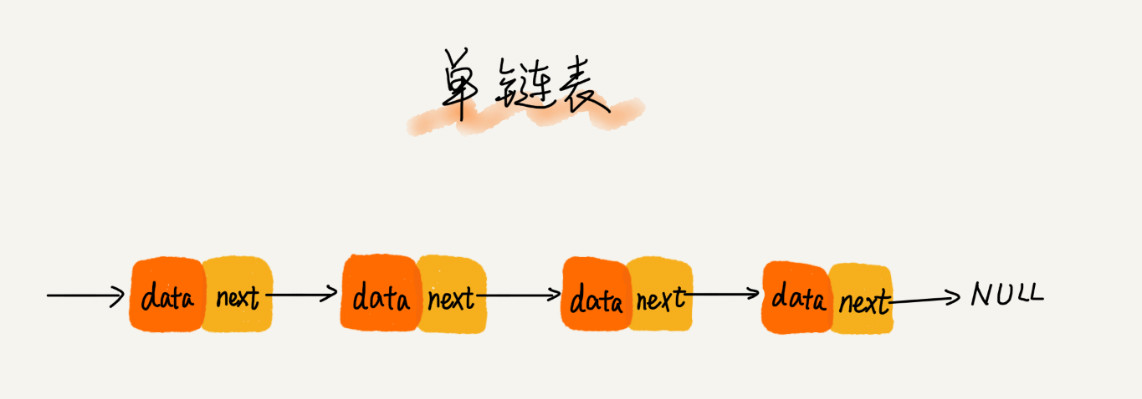
链表
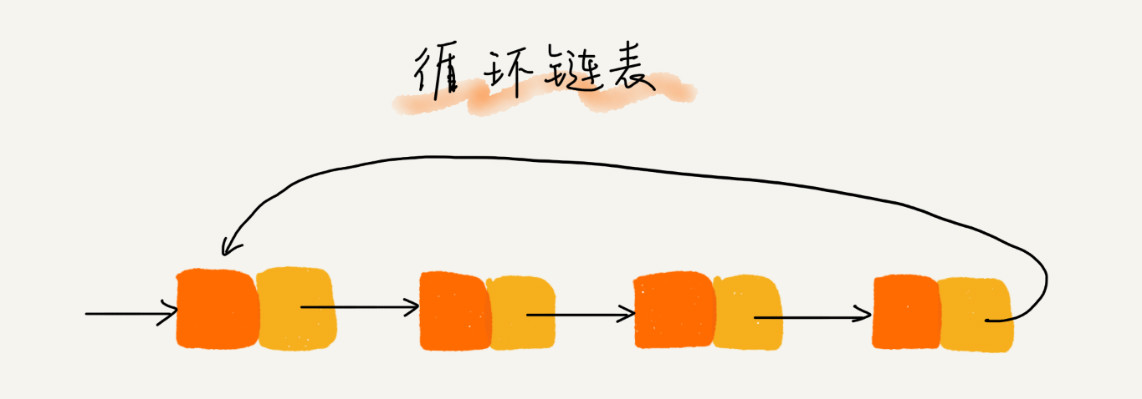
单链表、双向链表和循环链表。
链表相对数组:
优点:不需要连续的存储空间去存储数据,能够利用碎片内存。
缺点:正因为不是连续存储,所以不能随机访问第 k 个元素,每个元素都只知道它后面的一个元素,所以只能一个一个往后遍历。
let commitment = null// 构建单向环状链表for (let i = 0; i < children.length; i++){commitment.next = children[i]commitment = children[i]}commitment.next = children[0]// 循环遍历链表let current = commitment.nextwhile (current) {// do somethingcurrent = current.next}
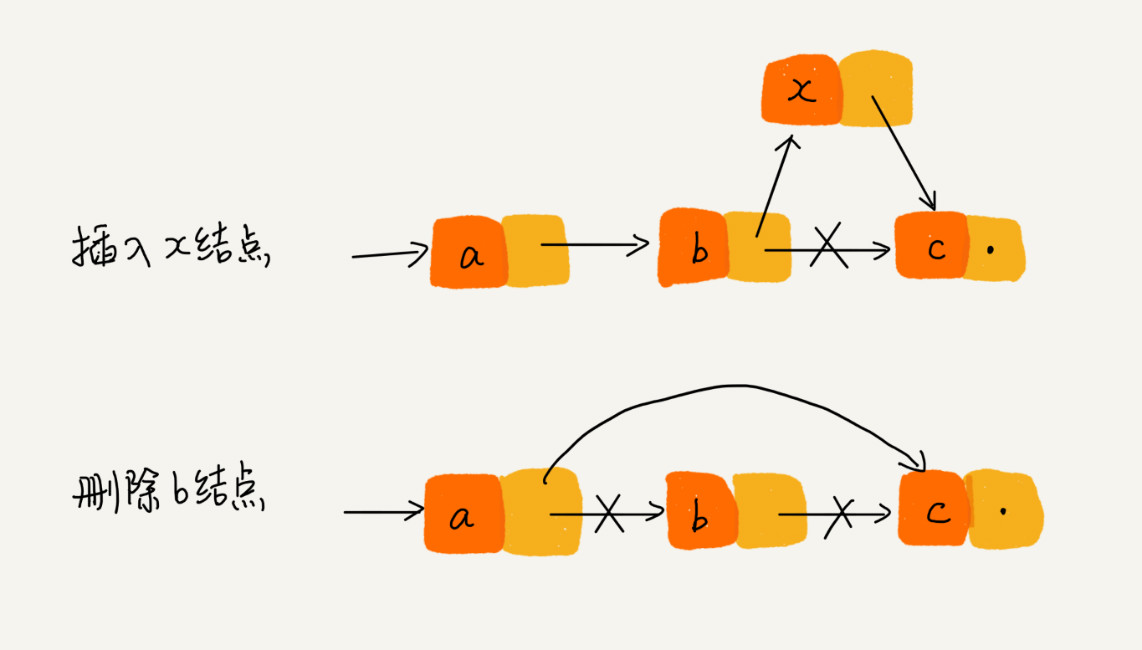
复杂一些的双向链表
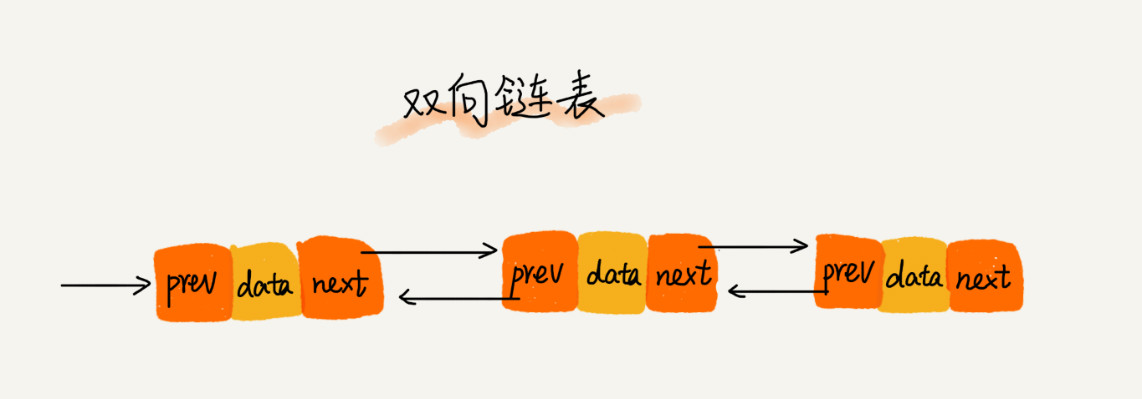
双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历,这样也带来了双向链表操作的灵活性。
应用:删除操作时(已知要删除节点的位置)
单链表删除某个节点,需要知道前节点和后节点。所以时间复杂度是 O(n)…
双向链表已知前后节点。所以时间复杂度是 O(1)…
除了插入、删除操作有优势之外,对于一个有序链表,双向链表的按值查询的效率也要比单链表高一些。因为,我们可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
双向循环链表
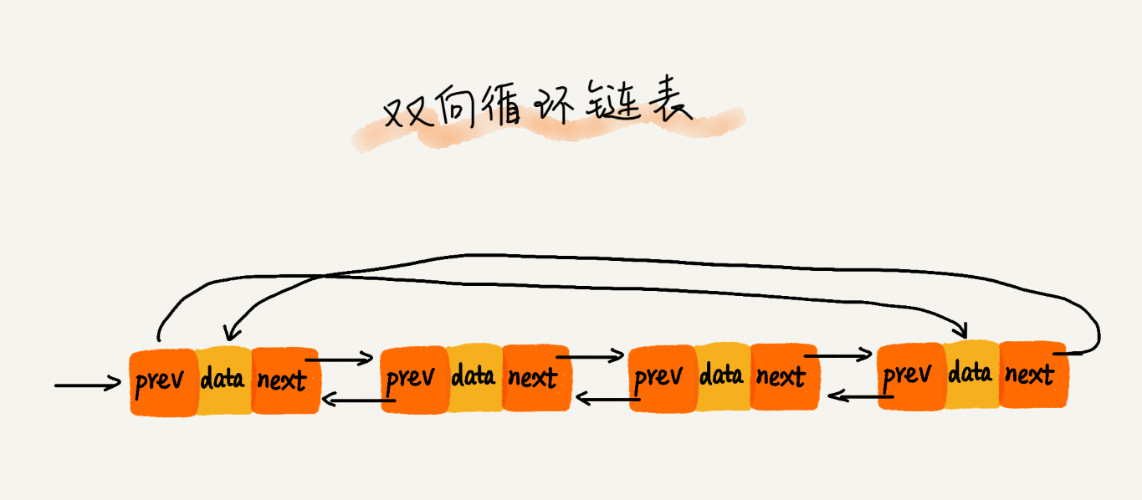
数组 VS 链表
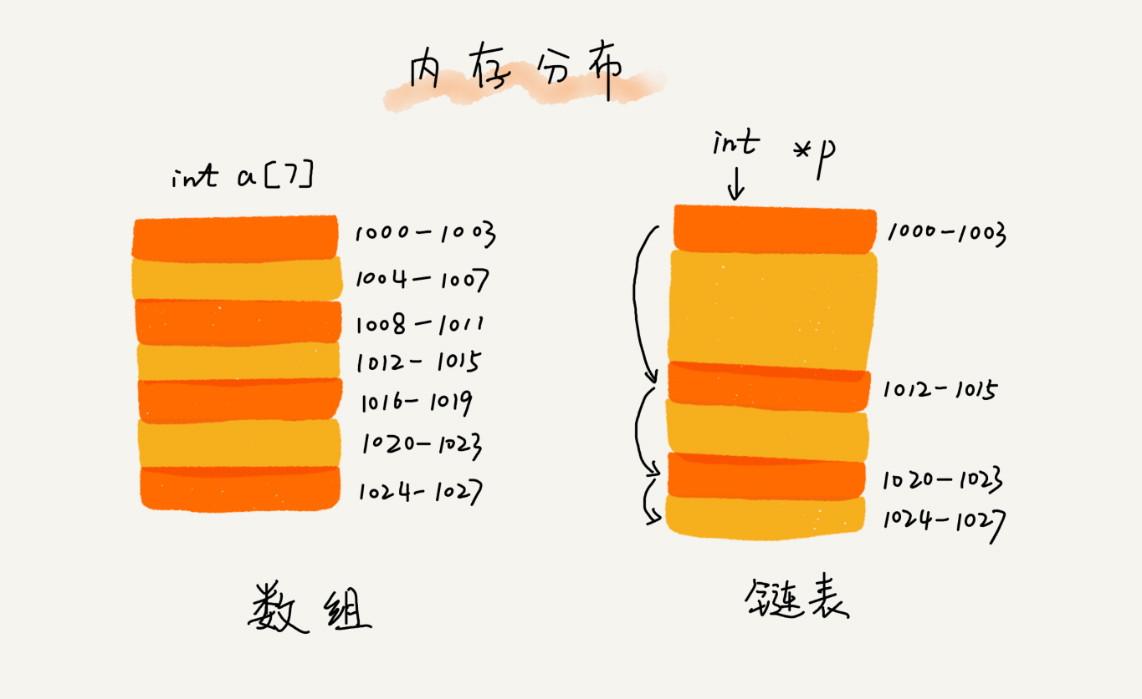
数组和链表是两种截然不同的内存组织方式。正是因为内存存储的区别,它们插入、删除、随机访问操作的时间复杂度正好相反。
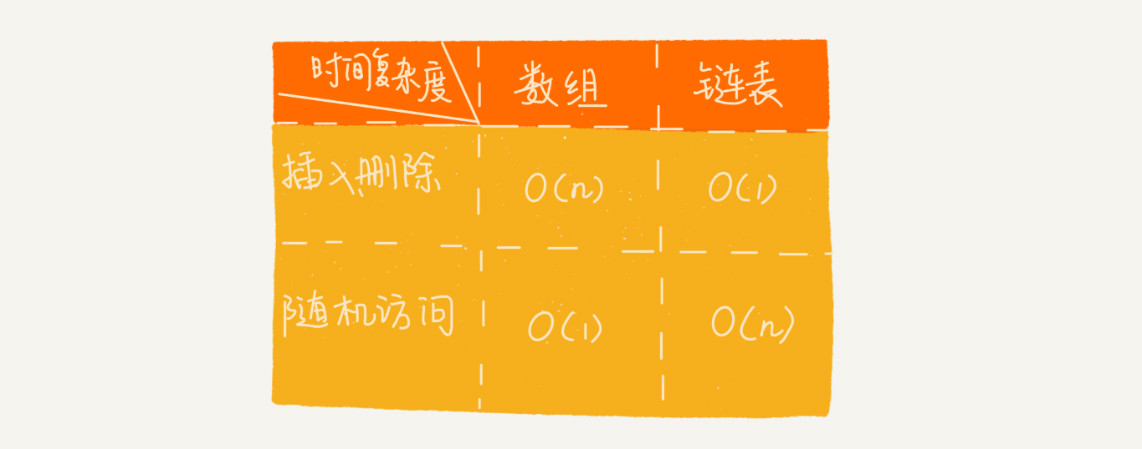
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。
数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。如果声明的数组过小,则可能出现不够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。链表本身没有大小的限制,天然地支持动态扩容,我觉得这也是它与数组最大的区别。
栈
先进后出,只在一端操作,功能”受限“,适用于特定场景。
实际上,栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。
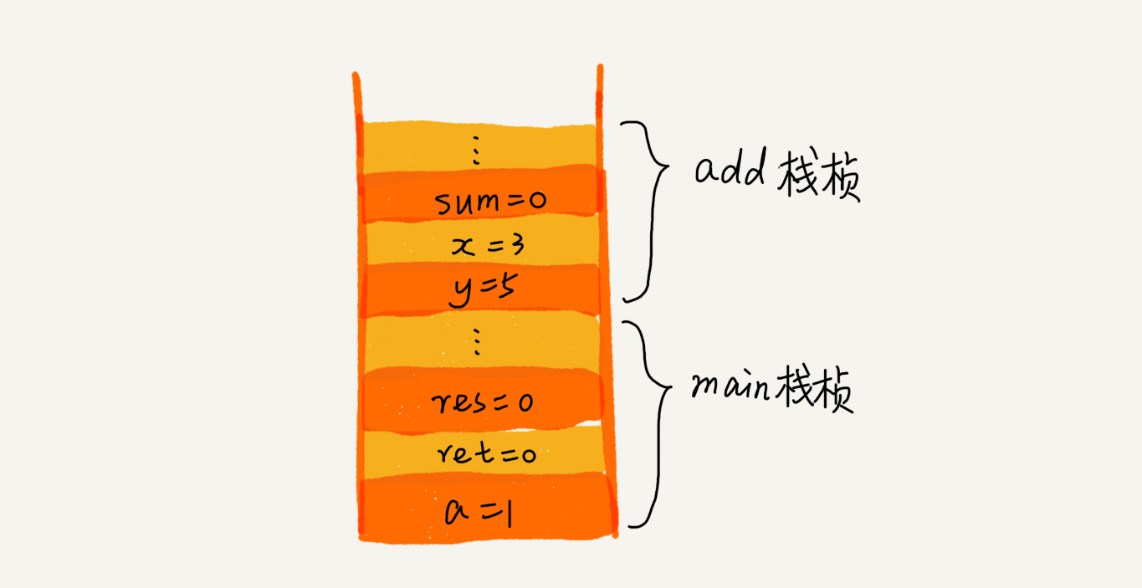
栈在函数调用中的应用
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
int main() {int a = 1;int ret = 0;int res = 0;ret = add(3, 5);res = a + ret;printf("%d", res);reuturn 0;}int add(int x, int y) {int sum = 0;sum = x + y;return sum;}
当然这里跟 JavaScript 中的函数调用栈细节不太一样。函数执行上下文
栈在表达式求值中的应用
实际上,编译器就是通过两个栈来实现的。其中一个保存操作数的栈,另一个是保存运算符的栈。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。
如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。
经典的括号匹配
浏览器的前进后退栈实现
我们使用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了。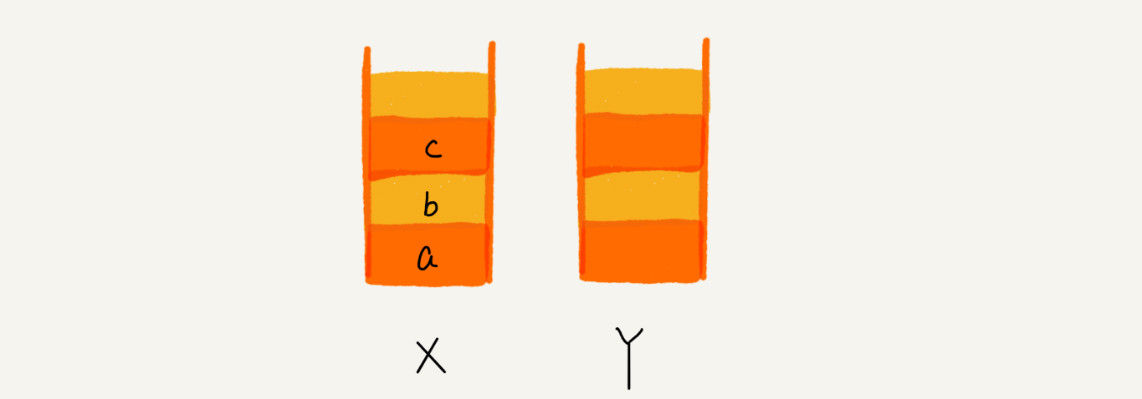
当你通过浏览器的后退按钮,从页面 c 后退到页面 a 之后,我们就依次把 c 和 b 从栈 X 中弹出,并且依次放入到栈 Y。这个时候,两个栈的数据就是这个样子: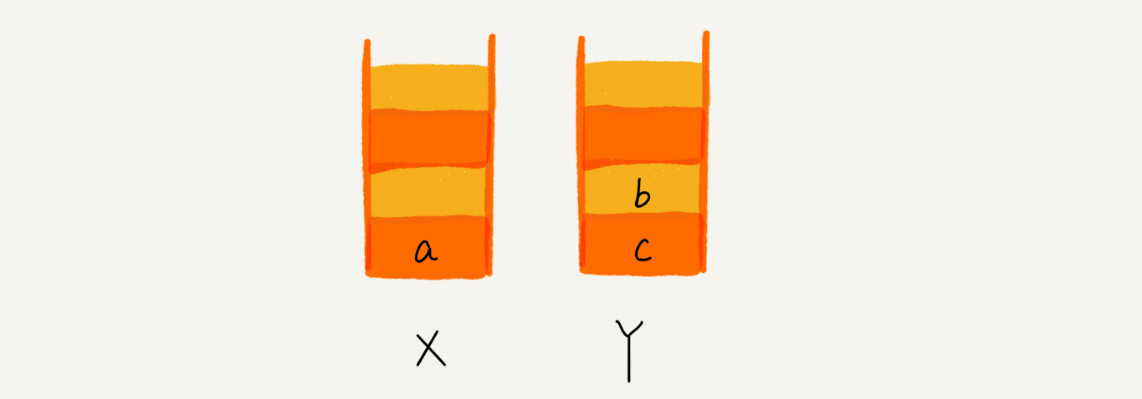
这个时候你又想看页面 b,于是你又点击前进按钮回到 b 页面,我们就把 b 再从栈 Y 中出栈,放入栈 X 中。此时两个栈的数据是这个样子: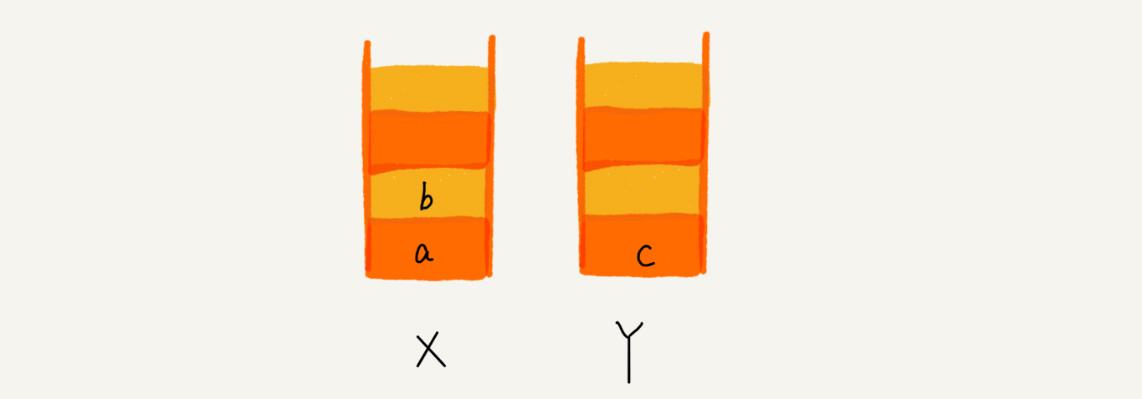
这个时候,你通过页面 b 又跳转到新的页面 d 了,页面 c 就无法再通过前进、后退按钮重复查看了,所以需要清空栈 Y。此时两个栈的数据这个样子: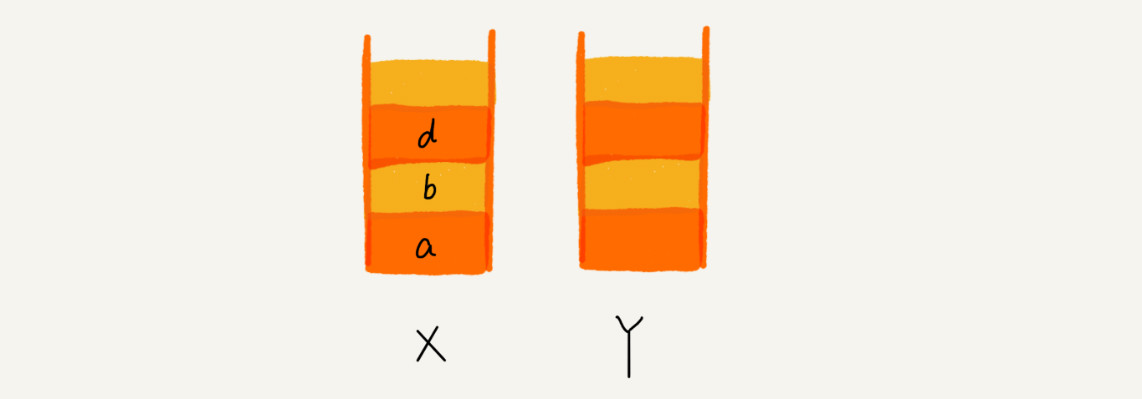
队列
递归 Recursion
递归需要满足的三个条件
一个问题的解可以分解为几个子问题的解
何为子问题?子问题就是数据规模更小的问题。比如,前面讲的电影院的例子,你要知道,“自己在哪一排”的问题,可以分解为“前一排的人在哪一排”这样一个子问题。这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
比如电影院那个例子,你求解“自己在哪一排”的思路,和前面一排人求解“自己在哪一排”的思路,是一模一样的。存在递归终止条件
把问题分解为子问题,把子问题再分解为子子问题,一层一层分解下去,不能存在无限循环,这就需要有终止条件。还是电影院的例子,第一排的人不需要再继续询问任何人,就知道自己在哪一排,也就是 f(1)=1,这就是递归的终止条件。
写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
**
计算机擅长做重复的事情,所以递归正合它的胃口。而我们人脑更喜欢平铺直叙的思维方式。当我们看到递归时,我们总想把递归平铺展开,脑子里就会循环,一层一层往下调,然后再一层一层返回,试图想搞清楚计算机每一步都是怎么执行的,这样就很容易被绕进去。对于递归代码,这种试图想清楚整个递和归过程的做法,实际上是进入了一个思维误区。
经典例题 ·走楼梯·
const now = Date.now()const map = {}function stairsPlus (n) {if (n === 1) return 1if (n === 2) return 2if (map[n]) {return map[n]}map[n] = stairsPlus(n - 1) + stairsPlus(n - 2)return map[n]}function stairs (n) {if (n === 1) return 1if (n === 2) return 2return stairs(n - 1) + stairs(n - 2)}console.log(stairsPlus(44))// console.log(stairs(44))console.log(Date.now() - now)

若有收获,就点个赞吧
0 人点赞
