使用 Golang 的开发者都知道,Go 语言里有指针的概念,它比 C++ 的指针要简单的多,同时你需要记住一个概念:Go 语言是 值传递。我们今天探讨的是在编码的时候到底该使用指针呢还是值类型?在作为参数和返回值的时候该如何去使用?两种传递方式有什么区别?
基础概念
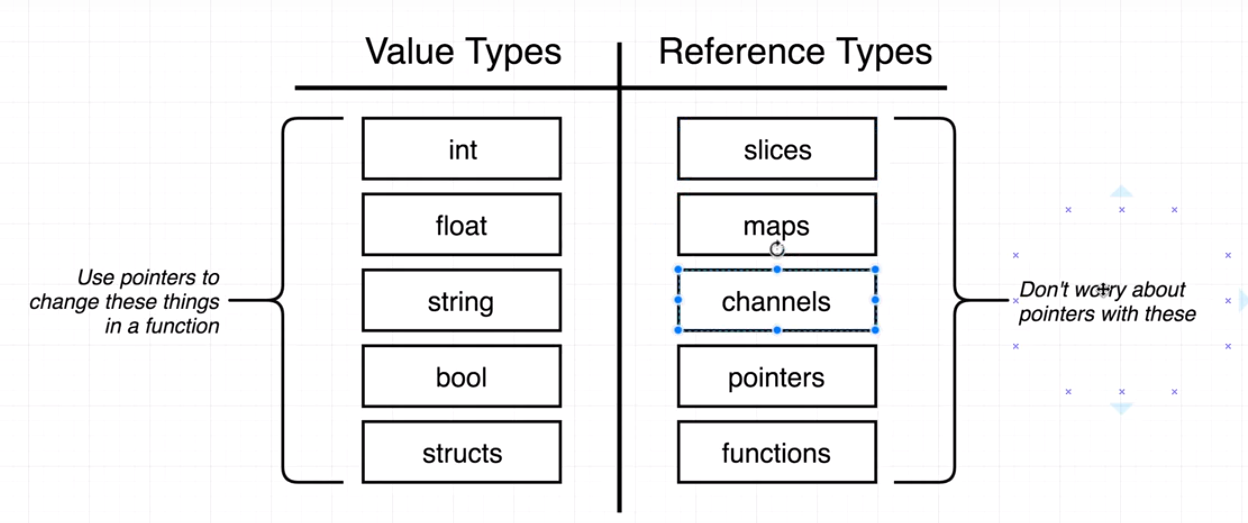
这幅图中展示了常用的值类型和引用类型(引用类型和传引用是两个概念)。在左边是我们常用的一些值类型,函数调用时需要使用指针修改底层数据;而右边是“引用类型”,我们可以理解为它们的底层都是指针类型,所以右边的类型在使用的时候会有些不同,下文中会举例说明。
举个栗子
type Foo struct {Name string}var bar = "hello biezhi"// -------------方法返回值----------------func returnValue() string {return bar}func returnPoint() *string {return &bar}// --------------方法入参-----------------func modifyNameByPoint(foo *Foo) {foo.Name = "emmmm " + foo.Name}func nameToUpper(foo Foo) string {foo.Name = strings.ToUpper(foo.Name)return foo.Name}// --------------实例方法-----------------func (foo Foo) setName(name string) {foo.Name = name}func (foo *Foo) setNameByPoint(name string) {foo.Name = name}
这里我列出了 3 组方法,分别是指针类型和值类型的示例。这几个方法在编写代码的过程中都会经常遇到,我们从使用者的维度和内存的视角来分析一下这几个方法:
使用区别
大部分人都在讨论函数的入参是指针还是值类型呢?我们先来看看第一组方法,返回值的情况:
s1 := returnValue()s2 := returnPoint()fmt.Printf("s1: %v \n", s1) // s1: hello biezhifmt.Printf("s2: %v \n", *s2) // s2: hello biezhi
这两个方法一个返回了指针一个返回值类型,值类型是非 nil 的(在 Go 中所有的值类型都会有 初值),指针类型可以判断是否为 nil。 获取到的数据是相同的,不同之处在于取值的方式,指针类型需要使用 * 号读取数据。
下面尝试传递参数,分别是指针类型参数和值类型参数:
foo := Foo{Name:"biezhi"}fmt.Println("foo.name:", foo.Name) // foo.name: biezhimodifyNameByPoint(&foo)fmt.Println("foo.name:", foo.Name) // foo.name: emmmm biezhifmt.Println("foo.name:", nameToUpper(foo)) // foo.name: EMMMM BIEZHIfmt.Println("foo.name:", foo.Name) // foo.name: emmmm biezhi
modifyNameByPoint需要指针类型,所以我们取foo的指针传入(foo是值类型所以这里用&取其地址)。nameToUpper需要一个值类型的参数,所以foo直接传入,返回值是转大写的 Name。nameToUpper不会修改foo.Name的数据,最后一次输出还是旧数据
综上例子,我们可以看出 指针类型会修改指向的数据,值类型的数据只有在返回的时候被使用,不会修改底层数据。
Go 中是值传递,一个方法/函数总是获取这个传递的拷贝,只是有一个分配声明给这个参数分配这个数值。拷贝一个指针的值就做了这个指针的拷贝,而不是指针指向的数据(重点理解)。
内存变化
我们使用值类型和指针类型在内存的视角上会有什么不同之处吗?这将使得我们对这两个概念理解更加深入。
返回值的情况
var bar = "hello biezhi"s1 := returnValue()s2 := returnPoint()fmt.Printf("bar: %v address: %p \n", bar, &bar) // 1fmt.Printf("s1 : %v address: %p \n", s1, &s1) // 2fmt.Printf("s2 : %v address: %p \n", *s2, &s2) // 3// output» bar: hello biezhi address: 0x115f480» s1 : hello biezhi address: 0xc00000e1e0» s2 : hello biezhi address: 0xc00000c030
从这个输出中可以看到数据都是一样的,这里使用 %p 输出一个指针的值(内存地址)都不同。第一个毋庸置疑是初始的内存地址,s1 是调用返回值类型的结果,s2 是返回指针类型的结果。照这样看的话好像返回指针还是值类型没有区别,地址都是新的。
来分析一下,首先 s1 的内存地址发生变化是因为方法参数被拷贝后产生了一份新的值给 s1,此时 s1 分配了新地址。对于 s2 也拷贝了一份新值,只不过这个值是 指针类型,所以在取数据的时候用了 *。
既然都分配了地址,到底使用值类型还是指针类型作为返回值,我的推荐是这样的:
- 当返回类型不涉及状态变更并且是较简单的数据结构,一律返回值类型
- 当返回类型可能遇到状态变更或者你关心它的生命周期则使用指针类型
- 当返回的结构比较大的时候使用指针类型
方法参数情况
我们在 nameToUpper 中添加一句输出:
func nameToUpper(foo Foo) string {foo.Name = strings.ToUpper(foo.Name)fmt.Printf("nameToUpper foo: %v address: %p \n", foo, &foo) // 2return foo.Name}
foo := Foo{Name:"biezhi"}fmt.Printf("foo: %v address: %p \n", foo, &foo) // 1nameToUpper(foo)fmt.Printf("foo: %v address: %p \n", foo, &foo) // 3// output» foo: {biezhi} address: 0xc00000e1e0» nameToUpper foo: {BIEZHI} address: 0xc00000e200» foo: {biezhi} address: 0xc00000e1e0
nameToUpper 接收值类型的参数,观察输出你会发现在外部的 foo 变量内存地址是没有发生变化的。
在方法内部接收这个 值类型变量 的时候,内存地址和外面不同,这意味着 Go 会将这个值类型参数作为一个拷贝传递过去,在方法内部的改变都不会影响到外面的变量。
如果方法接收一个指针类型呢?来试试 modifyNameByPoint 方法:
func modifyNameByPoint(foo *Foo) {fmt.Printf("modifyNameByPoint foo: %v address: %p \n", foo, &foo) // 2foo.Name = "emmmm " + foo.Name}
foo := &Foo{Name:"biezhi"}fmt.Printf("foo: %v address: %p \n", foo, &foo) // 1modifyNameByPoint(foo)fmt.Printf("foo: %v address: %p \n", foo, &foo) // 3// output» foo: &{biezhi} address: 0xc00000c028» modifyNameByPoint foo: &{biezhi} address: 0xc00000c038» foo: &{emmmm biezhi} address: 0xc00000c028
可以看到,数据被修改了,因为传递的是指针;内存地址没有发生变化,作为入参的 foo 在方法内部的地址也是一份新的拷贝,这一点和前面返回值是相同的(0xc00000c028 和 0xc00000c038 指向同一份数据)。
Receiver Type
如果你编写 Java 代码的话经常会看到这样的代码
public class Bar {String name;public void setName(String name){this.name = name;}}
可以看到这里有 this 关键字,在 Go 中是没有的,这里的 this 可以调用当前对象的成员变量和实例方法,当使用 this 修改了成员变量就相当于在 Go 中使用了指针,看看下面的 Go 代码:
func (foo *Foo) setNameByPoint(name string) {foo.Name = name}func (foo Foo) setName(name string) {foo.Name = name}
Go 中想要为结构体定义属于自己的方法就使用如上的两种方式,这两个方法在 Go 中称为 Receiver Type(接受者类型),可以使用结构体变量调用,我们今天只讨论结构体这种情况,来看看这两个方法有什么不同:
foo := Foo{Name:"biezhi"}foo.setName("2333")fmt.Println("foo.Name:", foo.Name) // foo.Name: biezhifoo.setNameByPoint("2333")fmt.Println("foo.Name:", foo.Name) // foo.Name: 2333
根据输出发现一个结构体,如果不使用指针类型的时候值是不会被修改的。这点也很容易理解,在 setName 方法中 foo 变量被作为值传递,所以如果这时候输出 foo 的内存地址会发现和外面调用的是不一样的,来看看:
func (foo Foo) setName(name string) {fmt.Printf("setName: %v address: %p \n", foo, &foo) // 2foo.Name = name}func (foo *Foo) setNameByPoint(name string) {fmt.Printf("setNameByPoint: %v address: %p \n", foo, &foo) // 4foo.Name = name}
foo := Foo{Name:"biezhi"}fmt.Printf("src foo: %v address: %p \n", foo, &foo) // 1foo.setName("set name")fmt.Printf("by value foo: %v address: %p \n", foo, &foo) // 3foo.setNameByPoint("2333")fmt.Printf("by point foo: %v address: %p \n", foo, &foo) // 5// output» src foo: {biezhi} address: 0xc00000e1e0» setName: {biezhi} address: 0xc00000e200» by value foo: {biezhi} address: 0xc00000e1e0» setNameByPoint: &{biezhi} address: 0xc00000c030» by point foo: {2333} address: 0xc00000e1e0
而 setNameByPoint 方法和前面的指针类型传递是一样的,方法内部内存地址是一份指针的拷贝,修改数据会影响到外部指针变量的数据。
一般而言,工程化的项目中会出现非常多结构体定义方法的代码,这些方法的调用也会很频繁,使用结构体将其封装起来,和 Java 中类封装是一样的,大多数情况下建议都使用指针传递,避免值拷贝的情况。
其他类型
在前面我们有一张图中分了值类型和引用类型,除了那些常用的基本类型,还有像 map 和 slice 这种引用类型,它们在使用上有点像指针(但不用任何操作符如 &、*),来看个例子:
func updateMap(mmp map[string]int) {mmp["biezhi"] = 2333}func main() {mmp := make(map[string]int)mmp["biezhi"] = 1024fmt.Printf("src mmp: %v address: %p \n", mmp, &mmp) // 1updateMap(mmp)fmt.Printf("new mmp: %v address: %p \n", mmp, &mmp) // 2}// output» src mmp: map[biezhi:1024] address: 0xc000094018» new mmp: map[biezhi:2333] address: 0xc000094018
如果你尝试 slice 的话是同样的效果,可以看到给方法传递的并非是一个指针类型,但是 map 的值确实被修改了,这是为什么呢?
其实拷贝一个 map 或者 slice 的时候并没有拷贝这个类型(引用类型)里面指向的数据,而是拷贝了引用类型(可简单理解为指针),如何验证这一说法呢?我们在 updateMap 中添加一行输出代码:
func updateMap(mmp map[string]int) {fmt.Printf("param mmp: %v address: %p \n", mmp, &mmp)mmp["biezhi"] = 2333}
再次运行代码
src mmp: map[biezhi:1024] address: 0xc000094018input mmp: map[biezhi:1024] address: 0xc00000c038new mmp: map[biezhi:2333] address: 0xc000094018
你会发现 input mmp 这行的地址发生了变化,正因为拷贝的是这个特殊的“引用类型”,会产生一个新的地址,而这个地址 0xc00000c038 和 0xc000094018 指向的是同一份数据,所以修改后外部的变量也会得到新的数据。
小结
前面我们通过一些代码示例来演示了在 Go 中值类型和指针类型的一些具体表现,最后我们要回答这么几个问题,希望你能够在使用 Go 编程的过程中更加清晰的掌握这些技巧。
Receiver Type 为什么推荐使用指针?
- 推荐在实例方法上使用指针(前提是这个类型不是一个自定义的
map、slice等引用类型) - 当结构体较大的时候使用指针会更高效
- 如果要修改结构内部的数据或状态必须使用指针
- 当结构类型包含
sync.Mutex或者同步这种字段时,必须使用指针以避免成员拷贝 - 如果你不知道该不该使用指针,使用指针!
“结构较大” 到底多大才算大可能需要自己或团队衡量,如超过 5 个字段或者根据结构体内占用来计算。
方法参数该使用什么类型?
map、slice等类型不需要使用指针(自带 buf)- 指针可以避免内存拷贝,结构大的时候不要使用值类型
- 值类型和指针类型在方法内部都会产生一份拷贝,指向不同
- 小数据类型如
bool、int等没必要使用指针传递 - 初始化一个新类型时(像
NewEngine() *Engine)使用指针 -
参考资料
- Receiver Type
- Pointers vs. values in parameters and return values

若有收获,就点个赞吧
0 人点赞
