并发的主要问题就是解决可见性,原子性,有序性等问题。为什么会有这三个问题呢,我们还需要从源头来解决这个问题。
硬件问题是源头
CPU、内存、IO设备,是计算机重要的组成设备。CPU的速度是最快的,其次内存的速度是大于IO设备的。为了解决这个问题,硬件工程师为了平衡三者的差异,做了以下的处理。
- CPU增加缓存,平衡和内存的速度差异。
- 操作系统通过进程和线程,分时复用CPU,均衡CPU和IO设备的差异。
优化指令的执行次序,20%的指令,在80%的时间频繁使用,80%的指令在20%的情况下偶尔会用,因此会重排指令。
CPU缓存导致可见性问题
CPU在单核时代,所有的线程在一个CPU上执行,CPU缓存和内存的数据一致性很容易解决。因为所有的线程操作的都是同一个缓存。线程A对缓存操作,另外一个线程一定是可见的。

如图所示,线程A修改了CPU中变量V的值,线程B是能够知道已经把变量V修改了的。
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。
当CPU有多个核心,就会出现问题,一个线程修改了共享变量,另一个线程就不能立刻看到了。
如图所示:
线程A在核心CPU-1上修改了变量V的值,线程B看到的是修改前的值。线程切换导致的原子性问题
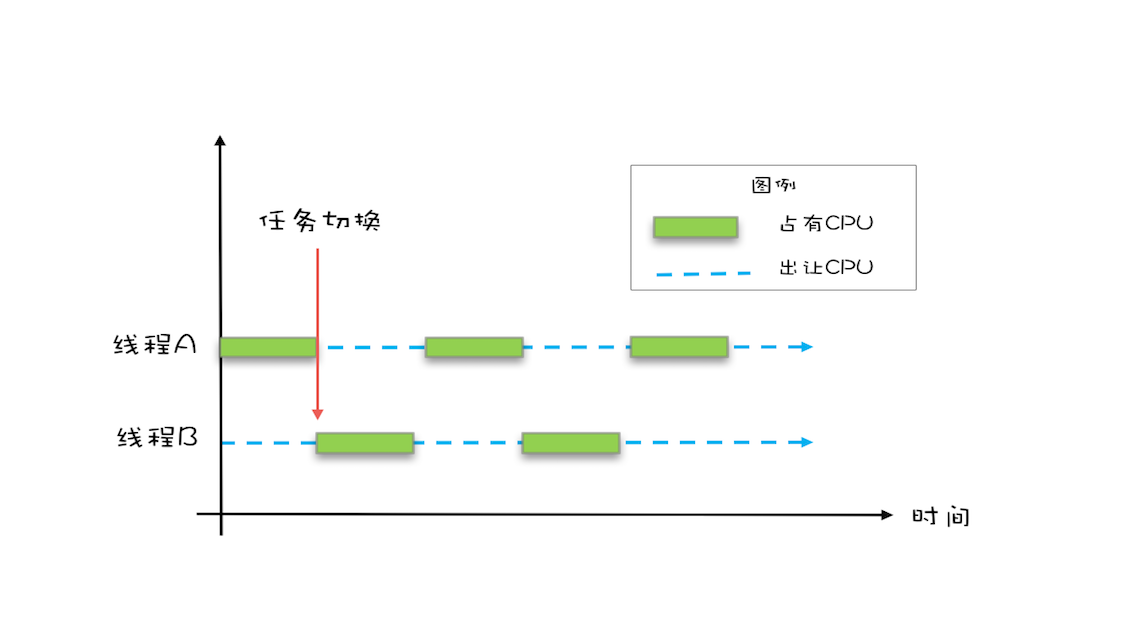
Java等高级语言,一条代码需要多条指令执行,例如count += 1,至少需要三步。
1.把值从内存加载到CPU。
2.寄存器总执行 + 1 操作。
3.把结果写入内存,CPU缓存。
线程切换可能发生在任意一步,如图所示,假设A线程把0加载到寄存器,线程切换了,线程B再次把count =0加载到了寄存器,然后执行+1操作,count = 1写入内存,线程切换到A,进行+1操作,count =1 写入内存,结果就变成了1,并不是我们期望的2.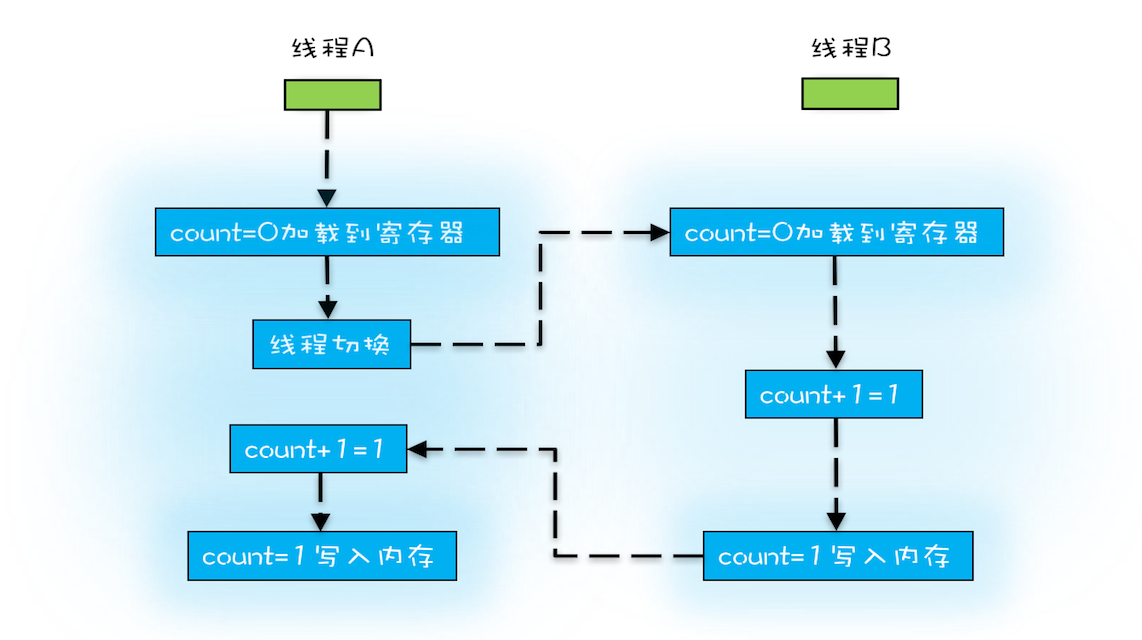
编译优化带来的有序性问题
我们使用高级语言进行编码,编译器为了优化性能,可能会调整代码的执行顺序。a = 7, b = c.调整为 b = c ,a = 7 .这种没什么问题。举个简单的例子,单例模式中我们会有双重校验锁的写法。
`public class Test2 {
private static Test2 singleton;
public static Test2 getSingleton() {
if (null == singleton) {
synchronized (Test.class) {
if (null == singleton) {
singleton = new Test2();
}
}}<br /> return _singleton_;<br /> }<br />}<br />`<br />代码本身是没有问题的,通过加锁的方式,一个线程只能创建一个对象。问题就出在new 这个操作上,一个new操作执行逻辑是这样的:
分配内存空间。
- 将地址赋给内存变量。
- 初始化对象。
如果在第二步结束后,进行了线程切换,B线程发现singleton并不为空,但是我们的对象还没有初始化,就会发生空指针异常。
例如long类型在32位机器上进行加减都会有隐患,因为Long是64位,在32位机器上进行操作需要更多地指令,没办法保证原子性。

若有收获,就点个赞吧
0 人点赞
