数据结构模拟网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
一、二叉查找树(BST) Binary Search Tree
二叉查找树不同于二叉树,二叉查找树的每个节点的左节点都比其上级节点小,右边节点比其上级节点大,它的高度决定了它的查找效率,在理想的情况下,二叉查找树增删查改的时间复杂度为O(logN)(其中N为节点数),最坏的情况下为O(N)。
二叉树没有这种大小的关系,仅仅是每个节点可以增加两个子节点。 二叉查找树存在倾斜的问题,例如每次新增的元素都比其父元素大,那么就会退化成一个链表,新插入的元素都会在其父元素的右节点下。这种情况下不是一个平衡的树,时间复杂度就是O(N)。
二叉查找树存在倾斜的问题,例如每次新增的元素都比其父元素大,那么就会退化成一个链表,新插入的元素都会在其父元素的右节点下。这种情况下不是一个平衡的树,时间复杂度就是O(N)。 需要解决这种链表的问题,就需要其他的结构来解决,例如完全平衡二叉树(AVL Tree),我们一次插入10,20,30,40,50,在插入30时,20的阶段会进行旋转(左旋),提升为根节点,左节点是10,右节点是30,当插入50的时候,40的节点会进行旋转(左旋),提升为父节点,左节点是30,右节点是50,任一左边和右边子树的高度差大于1,那么就会进行平衡(左旋或者右旋)。
需要解决这种链表的问题,就需要其他的结构来解决,例如完全平衡二叉树(AVL Tree),我们一次插入10,20,30,40,50,在插入30时,20的阶段会进行旋转(左旋),提升为根节点,左节点是10,右节点是30,当插入50的时候,40的节点会进行旋转(左旋),提升为父节点,左节点是30,右节点是50,任一左边和右边子树的高度差大于1,那么就会进行平衡(左旋或者右旋)。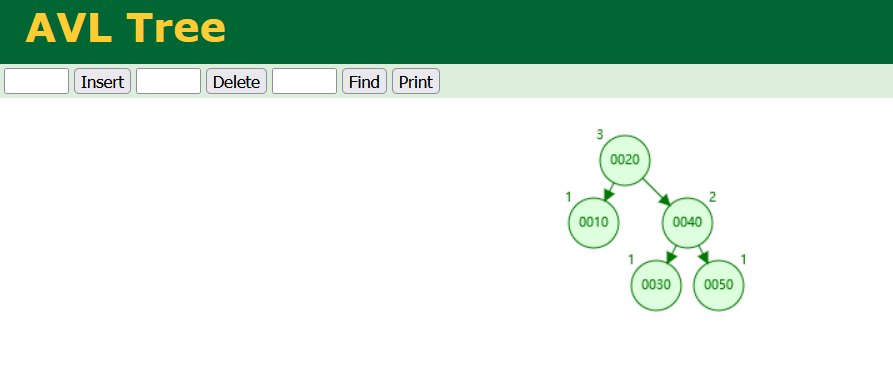
二、红黑树(RBTree)Red/Black Tree
基于BST存在的问题,一种新的树——平衡二叉查找树(Balanced BST)产生了。平衡树在插入和删除的时候,会通过旋转操作将高度保持在logN。其中两款具有代表性的平衡树分别为AVL树和红黑树。AVL树由于实现比较复杂,而且插入和删除性能差,在实际环境下的应用不如红黑树。
1、红黑树的定义
1)每个节点或是红的,或是黑的
2)根节点是黑的
3)每个叶节点是黑的,意思是每个最下级节点(例如下图中的节点10)下面还有左右两个空节点,这两个空的节点是黑色的。
4)如果一个节点是红的,则它的两个子节点都是黑的(即没有两个红节点是连续的),如果节点是黑色的,则没有这个要求。
5)对每个节点,从该节点到其子孙节点的所有路径上包含相同数目的黑节点
红黑树在理论上还是一棵BST树,但是它在对BST的插入和删除操作时会维持树的平衡,即保证树的高度在[logN,logN+1](理论上,极端的情况下可以出现RBTree的高度达到2*logN,但实际上很难遇到)。这样RBTree的查找时间复杂度始终保持在O(logN)从而接近于理想的BST。RBTree的删除和插入操作的时间复杂度也是O(logN)。RBTree的查找操作就是BST的查找操作。
红黑树插入数据的代码与二叉查找树是相同的,只是在插入以后,会对不满足红黑树性质的结点进行调整
红黑树的根节点是黑色的,每次新增加的节点都是红色的,例如先增加节点10,此时10是根节点,是黑色。新增节点20,为10的右子节点是红色,新增节点30,是20的右子节点是红色,此时左右两边节点发生了不平衡的状态,所以节点20会进行左旋,提升为根节点,变为黑色,10是20的左子节点是红色,30是20的右子节点是红色。此时插入节点40,会作为30的右子节点是红色,此时节点10和30会变为黑色。当插入元素50,会作为40的右子节点,此时会再次进行平衡,节点40左旋,成为节点30和50的父节点变成黑色,节点30和50变为红色。插入节点60,成为节点50的右节点是红色节点,此时节点30和50会变为黑色,节点40变为红色。插入节点70,作为60的右子节点,节点60会进行左旋,节点50成为节点60的左子节点,节点70是节点60的右子节点,节点60变为黑色,节点50变为红色,节点70为红色。
当新增一个节点(红色)的父节点是黑色时,是不需要调整的。
如果是新增的节点的父节点是红色的,分一下几种情况:
1)新增的节点的叔叔节点是空的,那么会进行父节点的旋转,并变色。
2)新增的节点的叔叔节点不是空的,如果叔叔节点是红色,那么就将父节点和叔叔节点变为黑色,祖父节点变为红色,如果祖父节点上面还有父节点,还需要继续向上调整。
3)新增的节点的叔叔节点不是空的,叔叔节点是黑色,这种情况在上面的调整中会存在,例如新增一个节点是红色,父节点和叔叔节点是红色,此时要变成黑色,祖父节点会由黑色变成红色,那么此时,祖父节点的父节点是红色,叔叔节点是黑色的,此时是不满足红黑树标准的,会继续向上调整(旋转,变色)直到根节点。
2、红黑树源码
 二、HashMap
二、HashMap
在JDK1.8中加入了红黑树,优化了链表的查询,当链表的长度超过8,就会变成红黑树。
1、put()方法源码
在1.8中的对key的hash算法没有1.7那么复杂,因为有了红黑树,对于1.7的hash算法复杂的原因就是为了让key能够增加散列性。
在其中一个元素put到下标位置时,如果链表长度已经大于8了,那么会在链表设置进去当前元素(第9个元素)之后,开始树化逻辑,在树化逻辑中,还会判断当前hashmap中的数组长度是不是大于64,如果不大于64会进行扩容,扩容时会把元素重新hash,分配到不同的下标位置,会缩短链表的长度。
把链表树化的过程,会把node节点转存为treenode节点。
TreeNode是HashMap的一个内部类,其父类LinkedHashMap.entry是node类的子类,所以TreeNode也包含了Node的属性,TreeNode的属性包括parent父节点,left左子节点,right右子节点,red节点颜色,prev前驱节点,还包含Node的属性,hash元素的hash值,key,value和next后继节点,这就说明TreeNode会形成一个双向链表。
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;TreeNode(int hash, K key, V val, Node<K,V> next) {// 这里会调用node类的构造方法super(hash, key, val, next);}// Node 的构造方法Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}
 2、putTreeVal()方法源码
2、putTreeVal()方法源码
当HashMap的数组中,其中某个下标上的元素是红黑树时,此时如果put到这个下标上,即插入到这个红黑树中的方法。
此方法会从根节点开始遍历红黑树,判断插入到某个元素的左子节点还是右子节点,构建成一个TreeNode,逻辑和树化基本相同,最后也调用方法:
moveRootToFront(tab, balanceInsertion(root, x)),把元素插入到红黑树中并重新设置数组中的第一个节点。
3、resize()方法
这个方法包含了初始化HashMap中数组的初始化逻辑和扩容逻辑。让数组的size大于阈值时,会进行扩容,这里和1.7的扩容逻辑不同,1.7除了判断阈值之外还会判断当前位置的元素是否为空。
4、remove()方法
首先会根据key的hash值找到key,其中如果数组的对应下标上还有链表或者红黑树,那么会循环遍历每一个元素进行判断,remove()方法底层是调用这个removeNode()方法来移除元素的,
final Node

若有收获,就点个赞吧
0 人点赞
