超文本传输协议(Hypertext Transfer Protocol)是 Web 客户端和 Web 服务器间通信的标准协议,指定了客户端与服务器如何建立连接、客户端如何从服务器请求数据,服务器如何响应请求以及最后如何关闭连接。其报文中的每个字段都是一些 ASCII 字符串,而且各个字段的长度都是不固定的。
HTTP 主要有以下特性:
- 无连接:在进行 Web 应用前无需建立专门的 HTTP 应用层会话连接,仅需要直接利用传输层已经为它建立好的 TCP 传输连接即可。
- 高可靠性:虽然 HTTP 本身是不可靠的无连接协议,但它使用了可靠的 TCP 传输层协议,在进行 HTTP 传输之前已经建立了可靠的 TCP 连接,所以从数据传输的角度来讲,HTTP 的报文传输是可靠的。
- 无状态:指同一客户第二次访问同一 Web 服务器上的同一页面时,服务器给客户的响应与第一次是一样的,Web 服务器不会记住这个客户曾经访问过这个页面而做出任何其他响应。
HTTP 使用的默认服务端口就是 TCP 的 80 端口,每个 Web 服务器都有一个应用进程时刻监听着 80 端口的用户访问请求。当有用户请求(以 HTTP 请求报文方式)来到时,它会尽快做出响应(以 HTTP 响应报文方式)返回用户所访问的页面信息。当然,这一切都需要在传输层建立好对应的 TCP 连接之上。
HTTP 请求报文格式
一个 HTTP 请求报文包括:请求行、请求头部行、空行和实体主体行 4 个组成部分。其中各行的字段数是没有固定长度的。
一般的请求通用格式如下图: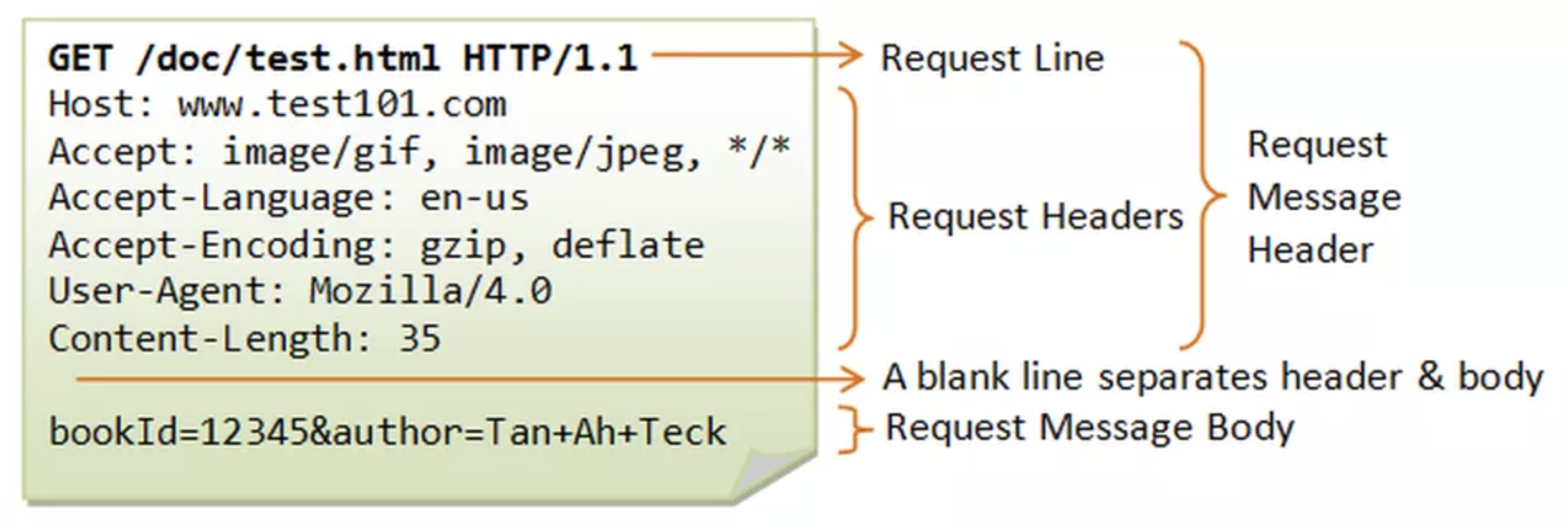
1)请求行
请求行由请求方法、URL 和协议版本组成的,它们之间均以空格进行分隔。在请求行的最后有一个回车符和一个换行符,用来使下面的请求头部信息在下一行显示。
请求方法字段指示本请求报文中所使用的 HTTP 协议操作,具体如表所示(全为大写字母),最常用的就是 GET 和 POST 这两种方法。
| 请求方法 | 含义说明 |
|---|---|
| GET | 请求服务器发送在 URL 字段中指定的 Web 页面 |
| HEAD | 请求读取 URL 字段指定的 Web 页面的头部信息,而不是全部的 Web 页面。利用这一方法可以得到一个页面的最后修改时间或其他头部信息 |
| PUT | 请求在 URL 路径下存储一个 Web 页面 |
| POST | 在 URL 所指定的 Web 服务器后面附加一个以 URI 格式命名的资源,以便可以为 Web 服务器提供更多的信息 |
| DELETE | 删除 URL 字段指定的 Web 页面 |
| TRACE | 指明这是一个用来进行环回测试的请求报文,用于调试 |
| CONNECT | 用于连接代理服务器 |
| OPTIONS | 请求查询一些特定的选项信息 |
比如:GET http://www.yuque.com/xiaomaizi33 HTTP/1.1,GET 是请求方法,中间部分是 URL,HTTP/1.1 是使用的 HTTP 版本,它们三者之间用空格分隔。
2)请求头部行
HTTP 请求头部行由一系列的行组成,表示允许客户端向服务器端传递请求的附加信息以及客户端自身的信息。每一行包括头部字段名和值两个字段,用冒号分隔。每一行的最后都有一个回车符和一个换行符,使下一个请求头在下一行显示。典型的 HTTP 请求头如表所示。
| 请求头 | 含义说明 |
|---|---|
| Accept | 指定客户能处理的页面类型。例如 Accept:image/gif,表示客户希望接受 GIF 图像格式的资源;Accept:text/html,表示客户希望接受 html 文本 |
| Accept-Charset | 指定客户可以接受的字符集。如果在请求消息中没有设置,默认可以接受任何字符集 |
| Accept-Language | 指定客户能处理的语言类型。例如:Accept-Language:zh-cn,表示客户只接受中文简体语言 |
| Authorization | 指定客户信任的凭据列表。当浏览器访问一个页面收到服务器的响应代码为 401 时,可以发送一个包含 Authorization 的请求,要求服务器对所列的用户账号进行验证 |
| Connection | 请求采用持续连接方式,例如 Connection:Keep-Alive |
| Host | 指定被请求服务器的域名和端口 |
| User-Agent | 允许客户端将它的操作系统、浏览器和其它属性告诉服务器 |
3)空行
在 HTTP 请求报文最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
4)实体主体行
在请求报文中“实体主体行”部分通常是不用的,而且不能在 GET 方法中使用,仅在 POST 方法中用于向服务器提供一些用户凭据信息。
HTTP 请求响应格式
在 Web 服务收到客户端发来的 HTTP 请求报文后,通过服务器处理后会返回一个 HTTP 响应报文给请求的客户端,以告知客户端 Web 服务器对客户端请求所做出的处理。HTTP 响应报文也是由 4 个部分组成,分别是:响应行、响应报头行、空行和实体主体行。
一般的响应通用格式如下图: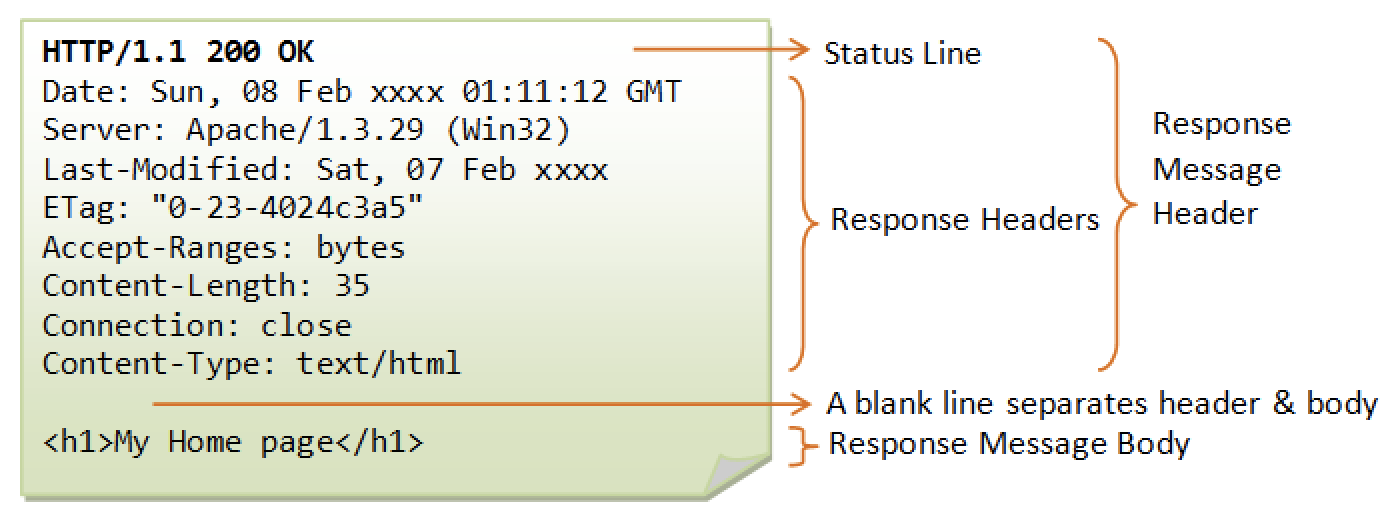
1)响应行
响应行中也主要是 3 个字段,分别是协议版本、状态码和描述短语,它们之间用空格分隔 。最后是一个回车符和一个换行符。状态码字段比较重要,它是用一个三位数表示不同的状态,共有 5 组取值,如表所示。
| 状态码类型 | 含义说明 | 示例 |
|---|---|---|
| 1XX | 为指示类响应,表示请求已接收,继续处理 | 100=服务器同意处理客户请求 |
| 2XX | 为成功类响应,表示请求已被成功接受 | 200=请求成功 204=无内容,也表示请求成功 |
| 3XX | 为重定向类响应,表示要完成请求必须进行更进一步的操作 | 301=页面重定向了 |
| 4XX | 客户端错位类响应,表示客户端请求有语法错误或请求无法实现 | 400=客户请求有语法错误,不能被服务器所理解 401=请求未经授权 403=服务器收到请求,但拒绝提供服务 404=请求资源不存在 |
| 5XX | 服务器端错误类响应,表示服务器未能实现所需要的请求 | 500=服务器发生了不可预期的错误 503=服务器当前不能处理客户端请求,过一段时间再试 |
2)响应报头行
HTTP 响应报文中的“响应报头行”部分是允许服务器传递,但不能放在响应行中的附加响应信息,以及关于服务器的信息和对 URL 所标识的资源进行下一步访问的信息。
响应报头行由一系列的行组成的,每行包括头部字段名和值这两个字段,用冒号分隔。每一行的最后都有一个回车符和一个换行符,使下一个响应报头在下一行显示。典型的 HTTP 响应报头如表所示。
| 响应头 | 含义说明 |
|---|---|
| Allow | 显示服务器支持哪些方法 |
| Content-Encoding | 显示请求文档所采用的编码方式 |
| Content-Language | 显示请求页面所使用的语言。例如 Content-Language:zh/zh-cn,表示页面支持中文和中文简体两种语言 |
| Content-Length | 显示请求页面的长度(以字节为单位) |
| Content-type | 显示页面所支持的类型。例如 Content-type:text/html,表示页面支持 text 和 html 两种 |
| Last-Modified | 显示请求页面最后被编辑或修改的日期和时间 |
| Set-Cookie | 向客户端发送一个 Cookie,通知客户端保存该 Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入 Cookie 。 |
3)空行
就是一个回车符和一个换行符,其目的就是空一行显示下面的主体信息。
HTTP 响应码
1xx 响应码表示一个提供信息的响应
| 100 Continue | 服务器准备接受请求主体,客户端应当发送请求主体。这允许客户端在请求中发送大量数据之前询问服务器是否将接受请求 |
|---|---|
| 101 Switching Protocols | 服务器接受客户端在 Upgrade 首部字段中要求改变应用协议的请求,如从 HTTP 改为 WebSockets |
2xx 响应码总指示成功
| 200 OK | 请求成功。如果请求方法是 GET 或 POST,所请求的数据与正常的首部一起包含在响应中;如果请求方法是 HEAD,则只包括首部信息。 |
|---|---|
| 201 Created | 服务器已经在响应主体中指定的 URL 处创建了资源,客户端现在应当尝试加载该 URL。这个响应码只在响应 POST 请求时发送。 |
| 202 Accepted | 这是个很不常见的响应,表示请求已经被处理,但处理尚未结束,所以不会返回任何响应。 |
| 203 Non-authoritative Information | 由缓存代理或其他本地资源返回资源的表示,不能保证是最新的 |
| 204 No Content | 服务器已经成功地处理了请求,但没有信息发回给客户端。 |
| 205 Reset Content | 服务器已经成功地处理了请求,但没有信息发回给客户端。此外,客户端应当清除发送请求的表单 |
| 206 Partial Content | 服务器返回客户端请求的资源的一部分,而不是整个文档 |
3xx 响应码表示重定位及重定向
| 300 Multiple Choices | 服务器为所请求的文档提供一组不同的表示 |
|---|---|
| 301 Moved Permanently | 资源已经移动到一个新的 URL。客户端应当自动加载这个 URL 的资源,更新所有指向原 URL 的书签 |
| 302 Moved Temporarily | 这个资源暂时位于一个新的 URL,但其位置在不久的将来还会再次改变,所以不应当更新书签。 |
| 303 See Other | 一般用于响应 POST 表单请求,这个响应码表示用户应当使用 GET 从另一个不同的 URL 获取资源 |
4xx 响应码表示客户端错误
| 400 Bad Request | 客户端向服务器发生的请求使用了不正确的语法。这在正常的 Web 浏览时很不常见 |
|---|---|
| 401 Unauthorized | 访问这个页面需要身份认证,一般是用户名和密码。但用户名和密码中可能有一个没有给出或者用户名、密码无效 |
| 402 Payment Required | 现在没有使用,但将来可能用于指示访问该资源需要某种付费 |
| 403 Forbidden | 服务器理解请求,但有意地拒绝进行处理。身份认证没有任何帮助,当客户端超出其配额时有时会使用这个响应码 |
| 404 Not Found | 最常见的错误响应,指示服务器找不到所请求的资源。它可能指示一个不正确的链接、已经移走而没有转发地址的文档、拼写错误的 URL 或其他类似情况 |
| 405 Method Not Allowed | 请求方法不支持指定的资源,例如使用 POST 提交到只支持 GET 的 URI。 |
| 406 Not Acceptable | 所请求的资源不能以客户端希望的格式提供,客户端期望的格式由请求 HTTP 首部的 Accept 字段指示。 |
| 407 Proxy Authentication Required | 中间代理服务器要求客户端在获取所请求的资源之前,先对客户端进行身份认证 |
| 408 Request Timeout | 客户端用了太长时间发送请求,可能是因为网络拥塞的原因 |
| 409 Conflict | 一个临时冲突阻止了请求的实现。例如两个客户端试图同时 PUT 相同的文件 |
| 410 Gone | 与 404 类似,但更有把握地确定资源的存在性。资源已经被有意地删除,不能恢复。应当删除相应的链接 |
5xx 响应码表示服务器错误
| 500 Internal Server Error | 服务器发生了意外情况,不知道如何处理 |
|---|---|
| 501 Not Implemented | 服务器不具有完成这个请求所需要的一个特性 |
| 502 Bad Gateway | 这个响应码只用于作为代理或网关的服务器。它指示该代理在试图完成请求时,从它连接的服务器接收到一个无效的响应 |
| 503 Service Unavailable | 服务器暂时无法处理请求,可能是超负荷或维护原因 |
| 504 Gateway Timeout | 代理服务器在合理的时间内未能接收到上游服务器的响应,所以无法将向客户端发送所需的响应 |
| 505 HTTP Version Not Supported | 服务器不支持客户端正在使用的 HTTP 版本 |
| 507 Insufficient | 服务器没有足够的空间来存放所提供的请求实体。通常用于 POST 或 PUT |
HTTP 方法
HTTP 主要有 4 个方法来标识可以完成的动作,它们有特定的语义,应用程序必须遵循这些语义:
- GET
- POST
- PUT
- DELETE
GET 方法可以获取一个资源的表示。GET 没有副作用,如果失败完全可以重复执行 GET,而不用担心有任何问题。另外 GET 的输出通常会缓存,不过这可以通过请求头参数来控制。
PUT 方法将资源的一个表示上传到已知 URL 的服务器。这个方法并非没有副作用,不过它具有幂等性。也就是说可以重复这个方法而不用担心它是否失败。如果连续两次把同一个文档放在同一个服务器的同一个位置,与只放一次相比,服务器的状态是一样的。
DELETE 方法从一个指定 URL 删除一个资源,这个方法也是具有幂等性的。由于存在明显的安全风险,所以并非所有服务器都配置为支持这个方法,即使服务器支持这个方法,通常也要求完成某种身份认证。
POST 方法也将资源的一个表示上传到已知 URL 的服务器,但没有指定服务器如何处理这个新提供的资源,例如服务器可能使用这个数据来更新一个或多个完全不同的资源的状态。POST 要用于不能重复的不安全操作。但在实际中,对于不完成提交的所有安全操作,有时会错误地选择 POST 而不是 GET,一个原因是表单可能需要大量输入,不过如今主流浏览器都能很好地应对至少 2000 个字符的 URL。
除了这 4 个主要的 HTTP 方法,特殊场合下还会用到另外几个 HTTP 方法。其中最常用的方法是 HEAD,这个方法相当于 GET,只不过它只返回资源的首部,而不返回具体数据。这个方法常用于检查文件的修改日期,查看本地缓存中存储的文件部分是否仍然有效。
Java 支持的另外两个 HTTP 方法是 OPTIONS 和 TRACE。OPTIONS 允许客户端询问服务器可以如何处理一个指定的资源,服务器响应 OPTIONS 请求时,会在 HTTP 首部中添加一个 Allow 字段表示这个 URL 上允许的命令列表。TRACE 会回显客户端请求来进行调试,特别是代理服务器工作不正常时。
Cookie
cookie 在请求和响应的 HTTP 首部,从服务器传递到客户端,再从客户端传回服务器,这可以使服务器在多个无状态的 HTTP 连接上跟踪各个用户和会话。
要在浏览器中设置一个 cookie,服务器会在 HTTP 首部中包含一个 Set-Cookie 的首部行:
HTTP/1.1 200 OKContent-type: text/htmlSet-Cookie: card=ATVPDKIKXODER
如果浏览器再向同一个服务器做出第二个请求,它会在 HTTP 请求首部行中的 Cookie 行发回这个 cookie:
GET /index.html HTTP/1.1Host: www.example.orgCookie: card=ATVPDKIKXODERAccept: text/html
缓存
默认情况下,一般认为使用 GET 通过 HTTP 访问的页面可以缓存,也应当缓存,使用 HTTPS 或 POST 访问的页面通常不应缓存。不过 HTTP 首部可以对此做出调整:
- Expires 首部(主要针对 HTTP 1.0)指示可以缓存这个资源表示,直到指定的时间为止。
- Cache-control 首部(HTTP 1.1)提供了细粒度的缓存策略:
- max-age=[seconds]:从现在直到缓存项过期之前的秒数
- s-maxage=[seconds]:从现在直到缓存项在共享缓存中过期之前的秒数
- public:可以缓存一个经过认证的响应
- private:仅单个用户缓存可以保存响应,共享缓存不应保存
- no-cache:这个策略的作用于名字不太一致。缓存项仍然可以缓存,不过客户端在每次访问时要用一个 Etag 或 Last-modified 首部重新验证响应的状态
- no-store:不管怎样都不缓存
- Last-modified 首部指示资源最后一次修改的时间,只有当本地缓存的副本早于 Last-modified 日期时,它才会真正执行 GET 来获取资源。
- Etag 首部(HTTP 1.1)是资源改变时这个资源的唯一标识符,只有当本地缓存的副本有一个不同的 Etag 时,它才会真正执行 GET 来获取资源。
如下示例,表示这个资源可以缓存 604800 秒(HTTP 1.1)或者缓存到一周以后(HTTP 1.0)。它还指出资源的最后修改日期是 4 月 20 号,而且有一个 Etag,所以如果本地缓存已经有一个更新的副本,那么现在没有必要加载整个文档:
HTTP/1.1 200 OKDate: Sun, 21 Apr 2021 15:12:46 GMTContent-Type: text/html; charset=ISO-8859-1Cache-control: max-age=604800Expires: Sun, 28 Apr 2021 15:12:46 GMTLast-modified: Sat, 20 Apr 2021 09:55:04 GMTEtag: 5257457436365grd634

若有收获,就点个赞吧
0 人点赞
