Loss分为bias 和 variance
(注:下图中每个蓝色点代表着同一个model使用某组数据训练出的模型)
bias 偏差
原因:模型复杂度不够,导致可学习的函数域本身就不包含目标函数,所以多次拟合后所有模型的均值距离目标函数仍然有距离,这种误差称为 bias 。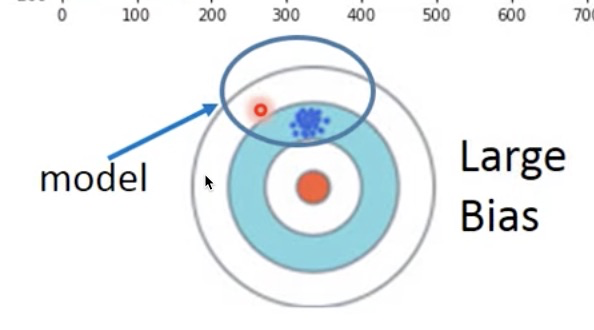
variance 方差
原因:模型复杂度够了,偏差足够小,可能每个模型训练完都有一定的误差,但是其均值,还是可以逼近真实目标函数的。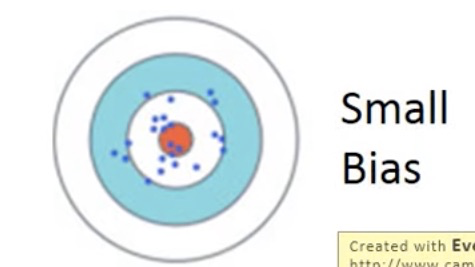
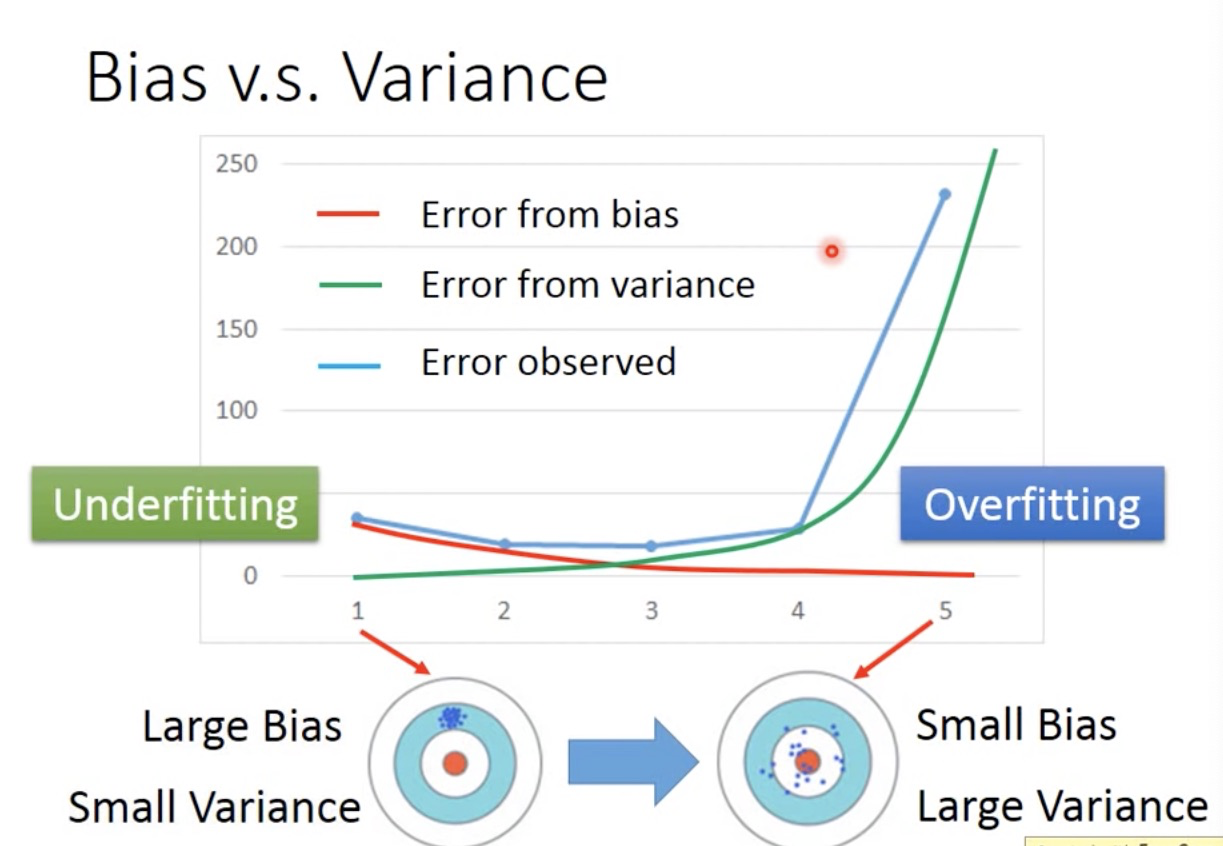
蓝色是test数据集上观察到的loss,由左到右,bias loss逐渐下降,就是模型逐渐复杂,瞄的越来越准(准星与目标越来越接近),但是误差缺越来越大(瞄的准打得歪),variance loss越来越大。
大概在3这个转折点,左边是欠拟合,右边是过拟合
如何判断欠拟合还是过拟合 ,或者说你的loss是主要来自bias还是variance?
1.如果training set都无法拟合,说明学习能力不够,loss主要来自bias,欠拟合
2.如果在training set 上loss 小,但是testing set上loss大,loss主要来自variance,过拟合
如何解决欠拟合和过拟合?
bias大,即欠拟合时:
重新设计模型,增加模型复杂度,使得你的函数域包含目标函数(增加feature啊等等)
(此时更多的data没有帮助,因为本身的学习域根本学不到目标函数)
variance大,即过拟合:
1.增加数据量(常用数据增强方法)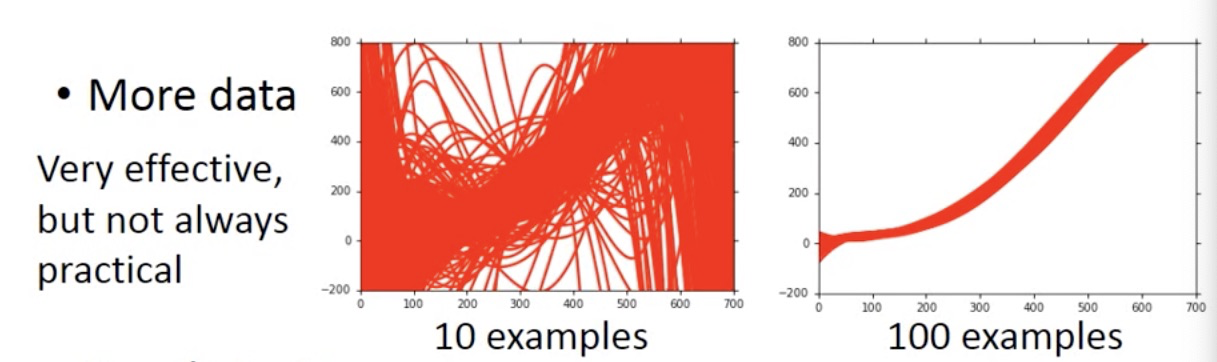
2.使用正则化项
因为本身每个模型针对某一组数据产生过拟合的现象,模型要强行过每一个点,实际上是对数据太过于敏感,但是我们想要较为平滑的模型,这样对于测试集才有更好的泛化能力,所以为了让模型更加平滑,就要减少模型对x的特征的敏感程度,所以就是减少x的系数w的大小,所以加正则化项。(正则化只对w不对b的原因也正是如此,b不会改变模型对x的敏感程度,而是控制模型平移的位置,如果控制b的大小,好像是要让b不要离0太远,模型要过原点一样,没有意义,大部分情况下会让模型变坏。)
(注:有可能增加正则化项会让bias变大,因为本质上是我们缩小了函数域的范围,只允许一些很平滑的函数)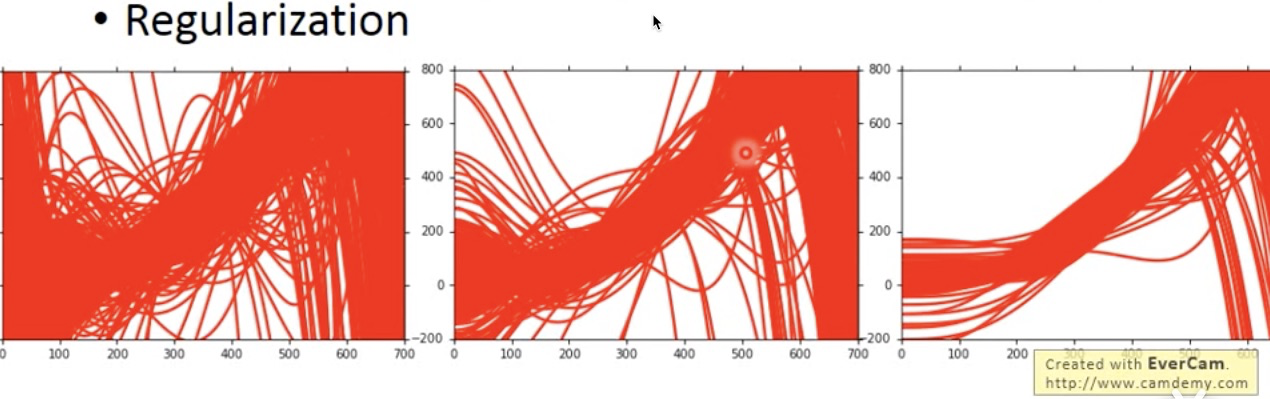

若有收获,就点个赞吧
0 人点赞
