1.模块介绍
1.1.认识模块
在python中,一个py文件就是一个模块,文件名xxx.py模块名则是xxx,导入模块可以引用模块中已经写好的功能。如果把开发程序比喻成制造一台电脑,编写模块就像是在制造电脑的零部件,准备好零部件后,剩下的工作就是按照逻辑把它们组装到一起。
将程序模块化会使得程序的组织结构更加清晰,维护起来更加方便。比起直接开发一个完整的程序,单独开发一个小的模块会更加简单,并且程序中的模块与电脑中的零部件稍微不同的是:程序中的模块可以被重复使用。所以总结下来,使用模块既保证了代码的重用性,又增强了程序的结构性和可维护性。另外除了自定义模块外,我们还可以导入使用内置模块提供的现成的功能,这种“拿来主义”极大地提高了程序员的开发效率。
1.2.模块的分类
模块就是一系列功能的集合体
模块有二种来源:1. 自定义模块 py文件,2. 内置的模块。
1.3.模块的格式
1 使用python编写的.py文件
python文件就是一系列功能的集合体
1.4.为何要用模块
1.使用内置模块的好处是: 拿来主义,可以极大提升开发效率
2.使用自定义模块的好处是: 可以减少代码冗余
(抽取我们自己程序中要公用的一些功能定义成模块,
然后程序的各部分组件都去模块中调用共享的功能)
1.5.导入模块的方式
1.首次导入模块发生的事情
- 会产生一个模块的名称空间
- 执行文件spam.py,将执行过程中产生的名字都放到模块的名称空间中
- 在当前执行文件run.py的名称空间中拿到一个模块名,该名字指向模块的名称空间
(文件名是spam.py,模块名则是spam)
2.import导入模块
from 模块名 import 各种名字变量名,函数名等等
之后的导入,都是直接引用第一次导入的成果,不会重新执行文件
import spam
总结import导入模块:在使用时必须 加上前缀:模块名
优点:指名道姓地向某一个名称空间要名字,肯定不会与当前 名称空间中的名字冲突
缺点:但凡应用模块中的名字都需要加前缀,不够简洁
spam.py(作为模块)
# @Author : 大海# @File : spam.py# print('from the spam.py')money = 100def read1():print('spam.py模块')class A:a = 111
run.py(作为执行文件,也就是pycharm右键点击运行的文件)
# @Author : 大海# @File : run.py# 文件名是spam.py,模块名则是spamimport spam# 之后的导入,都是直接引用第一次导入的成果,不会重新执行文件# import spam# import spammoney = 222print(money)# # # # 在执行文件中访问模块名称空间中名字的语法:模块名.名字# # # # 指名道姓地跟spam要名字money,肯定不会与当前执行文件中的名字冲突print(spam.money)print(spam.read1)#spam.read1()print(spam.A)# 一行导入多个模块(不推荐)import spam,time# # 可以为模块起别名import spam as sm#print(sm.money)# 总结import导入模块:在使用时必须加上前缀:模块名.# 优点: 指名道姓地向某一个名称空间要名字,肯定不会与当前名称空间中的名字冲突# 缺点: 但凡应用模块中的名字都需要加前缀,不够简洁
3.from..import..
优点:使用时,无需再加前缀,更简洁
缺点:容易与当前名称空间中的名字冲突
绝对导入:
from 文件夹 import 模块名
绝对导入的目的是为了导入使用不在同一级别或同一文件下的数据包或模块
#绝对导入是指作为非执行文件内模块,并按执行文件级别需要进行导入的包内文件或模块
spam.py(作为模块)
# @Author : 大海# @File : spam.py# print('from the spam.py')money = 100def read1():print('spam.py模块')class A:a = 111
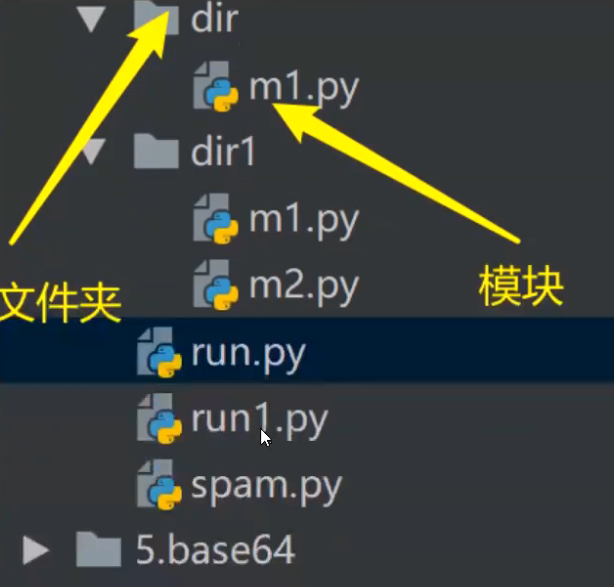
dir文件夹下面的模块(m1.py)(作为模块)
# @Author : 大海# @File : m1.pydef f1():print('from f1')def f2():print('f2')def f3():print('f3')
run.py(作为执行文件)
# @Author : 大海# @File : run.py# 首次导入模块发生3件事# 1. 创建一个模块的名称空间# 2. 执行文件spam.py,将执行过程中产生的名字都放到模块的名称空间中# 3. 在当前执行文件中直接拿到一个名字,该名字就是执行模块中相对应的名字的# from 模块名 import 各种名字: 变量名,函数名,类名等等from spam import money,read1,Amoney = 222# # # 容易与当前名称空间中的名字冲突print(money)read1()print(A)# *代表从被导入模块中拿到所有名字(不推荐使用)from spam import *print(money)read1()print(A)# 起别名from spam import money as r1money = 222print(r1)# 总结from...import...# 优点: 使用时,无需再加前缀,更简洁# 缺点: 容易与当前名称空间中的名字冲突# 绝对导入# from 文件夹 import 模块名from dir import m1#m1.f1()m1.f2()m1.f3()# from 文件夹.模块名 import 函数名# from dir.m1 import f1from dir.m1 import *f1()f2()f3()
相对导入
from. 文件夹 import 模块
from..文件夹 import 模块
from….文件夹 import 模块
相对导入:参照当前所在文件的文件夹为起始开始查找,称之为相对导入
符号:代表当前所在文件夹的文件,..代表上一级文件夹,…代表上一级的上一级文件夹
优点:导入更加简单
缺点:只能在导入包中的模块时才能使用,不能在执行文件中用
(不要建和作者命名一样的模块,不然会覆盖作者的模块内容)
dir1文件夹下面的模块(m1.py和m2.py)
m1模块,
# 绝对导入# import m2# 绝对导入必须以执行文件为主# D:\python代码A9\day11模块\2.from# from dir1 import m2# # 没有前缀# from dir1.m2 import f2# 最正确方式用相对导入# D:\python代码A9\day11模块\2.from\dir1from .m2 import f2def f1():print('from f1')# 去调用m2模块里面的f2函数# m2.f2()f2()
m2模块
# @Author : 大海# @File : m2.pydef f2():print('from f2')
run1.py(作为执行文件)
# @Author : 大海# @File : run1.py'''# 相对导入# from .文件夹 import 模块# from ..文件夹 import 模块# from ...文件夹 import 模块# 相对导入: 参照当前所在文件的文件夹为起始开始查找,称之为相对导入# 符号: .代表当前所在文件夹的文件,..代表上一级文件夹,...代表上一级的上一级文件夹# 优点: 导入更加简单# 缺点: 只能在导入包中的模块时才能使用,不能在执行文件中用'''# 错误# from .dir import m1# 执行文件中只能用绝对导入# from dir import m1# D:\python代码A8\day11模块\2.fromfrom dir1 import m1m1.f1()
2.time模块
# @Author : 大海# @File : 2.time_test.py"""time模块与时间相关的功能在python中 时间分为3种1.时间戳 timestamp 从1970 年 1 月 1日 到现在的秒数 主要用于计算两个时间的差2.localtime 本地时间 表示的是计算机当前所在的位置3.UTC 世界协调时间 又称世界统一时间、世界标准时间、国际协调时间。时间戳 结构化 格式化字符"""import time# 获取时间戳 返回的是浮点型# 作用 用来计算时间差print(time.time())# 获取当地时间 返回的是结构化时间print(time.localtime())# 获取UTC时间 返回的还是结构化时间 比中国时间少8小时print(time.gmtime())# 结构化时间转换成字符串时间print(time.strftime('%Y-%m-%d %H:%M:%S'))# 将格式化字符串的时间转为结构化时间 注意 格式必须匹配print(time.strptime('2022-05-10 20:51:07','%Y-%m-%d %H:%M:%S'))# 时间戳 转结构化# 10秒时间戳print(time.localtime(10))# 当前时间戳print(time.localtime(time.time()))# 结构化转 时间戳print(time.mktime(time.localtime()))# sleep# 让当前进程睡眠一段时间 单位是秒time.sleep(1)print('over')
3.datetime模块
# @Author : 大海# @File : 3.datetime.py"""datetimepython实现的一个时间处理模块time 用起来不太方便 所以就有了datetime总结 datetime相比time 更灵活 更本土化"""# import datetime# print(datetime.datetime.now())from datetime import datetime# # 获取时间 获取当前时间 并且返回的是格式化字符时间# # print(datetime.now())# # 单独获取某个时间 年 月d = datetime.now()print(d.year)print(d.month)print(d.day)print(d.hour)print(d.minute)print(d.second)print(d.microsecond)# # 手动指定时间print(datetime(2018,8,9,9,50,00))d2 = datetime(2018,8,9,9,50,00)print(d-d2)# # 替换某个时间单位的值print(d.replace(year=2019))# 增加一天print((datetime.datetime.now()+datetime.timedelta(days=1)).strftime('%Y-%m-%d %H:%M:%S'))# 减少一天print((datetime.datetime.now()+datetime.timedelta(days=-1)).strftime('%Y-%m-%d %H:%M:%S'))
4.hash模块
什么叫hash: hash是一种算法,该算法接受传入的内容,经过运算得到一串hash值
1.hash值的特点是
1 只要传入的内容一样,得到的hash值必然一样=====>文件完整性校验
2 不能由hash值返解成内容=======》把密码做成hash值,不应该在网络传输明文密码
3 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的,这样不影响传输
2.使用方法
import hashlib
# # 1创建hash工厂
m=hashlib.md5()
# # 2在内存里面运送
# # m.update('helloworld'.encode('utf-8'))
# # 一点一点的给,因为可能二进制会很长 ,这个要好一些
m.update('hello'.encode('utf-8'))
m.update('world'.encode('utf-8'))
# # 3、产出hash值
print(m.hexdigest())
# fc5e038d38a57032085441e7fe7010b0
# fc5e038d38a57032085441e7fe7010b0
3.密码前后加盐
# 输入密码的时候是沿着网络传输到别的服务器上面,黑客可以把包抓下来
# 所以发给服务端是hash值,也就是密文
# 但是还是可以抓下来
# 常用密码字典
# 什么生日 , 123 , 身份证 等等 密码有强烈的个人习惯
# 那么我用一样的hash算法,是不是可以得到一样的hash值 密文 那么明文肯定是一样的
# 撞库风险
# 密码前后加盐
import hashlib
pwd = 'abc123'
m = hashlib.md5()
#
m.update('大海老师'.encode('utf-8'))
m.update(pwd.encode('utf-8'))
m.update('大帅比'.encode('utf-8'))
#
#
print(m.hexdigest())
# 服务器也有相应的规则
# 黑客破解成本远大于收益成本
# 中间加盐
import hashlib
pwd = 'abc123'
m = hashlib.md5()
print(pwd[0])
print(pwd[1:])
m.update('大海老师'.encode('utf-8'))
m.update(pwd[0].encode('utf-8'))
m.update('大帅比'.encode('utf-8'))
m.update(pwd[1:].encode('utf-8'))
m.update('夏洛老师'.encode('utf-8'))
print(m.hexdigest())
4.根据hash算法确定hash的长度
# 3 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的,这样不影响传输
import hashlib
pwd = 'hello worldaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa'
m = hashlib.md5()
m.update(pwd.encode('utf-8'))
print(m.hexdigest())
# 7cf8b5ef208ffbdad568a70863292b4a
# 37febe21cac411a046b1b380393dd063
# # sha后面的数字越大加密的算法越复杂
import hashlib
pwd = 'haaaaaaaaaaaaaaaaaaaaaaaaaaaa'
m = hashlib.sha256()
m.update(pwd.encode('utf-8'))
print(m.hexdigest())
# 7a7c76994ace75e34bc34174c26169e0809ea88828137f9b3917fc36e4a40de4
# 6c01f40d88b34e35478279498abfd20b750be6116ae92602fc096a668e3773f3
import hashlib
pwd = 'hello worldaaaaaaaaaaaaaaaaaaaaaaaaaaaaa'
m = hashlib.sha512()
m.update(pwd.encode('utf-8'))
print(m.hexdigest())
# 394da4cc1c3d3c773dd03e9ef82548ee1dce2126e1e91c1c9f0526bb542c8a2126384ee9b723c6b91b40e701fd453bc3ebe8ae904428b9e7eb57fb0ca90d6b9e
# 29d09ac47225f914370d0037bfd4658f5c6eeb7ba2f6b2ea9233fff8bc6c04f4c7ff602e69920bf5d5f7f04c2d4a3efe46ca51b45f4a96f736965e35fad88958
5.base64模块
1.认识base64
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,
Base64就是一种基于64个可打印字符来表示二进制数据的方法。
定义 8Bit字节代码的编码方式之一
可用于 在HTTP环境下传递较长的标识信息
特性 Base64编码具有不可读性
它只是用传输,并不是加密
Base64编码原理
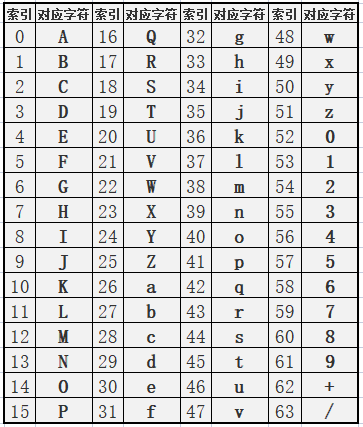
看一下Base64的索引表,字符选用了”A-Z、a-z、0-9、+、/“ 64个可打印字符。
数值代表字符的索引,这个是标准Base64协议规定的,不能更改。
Base64的索引表
2.代码
import base64
a = '大海'
a= a.encode('utf-8')
# print(a)
str_a=base64.b64encode(a)
print(str_a)
# 可以理解成一个中介
# 将base64解码成字符串
str_b = base64.b64decode(str_a).decode('utf-8')
print(str_b)
6.json模块序列号与反序列化
1.回忆变量
什么是变量?
变量即变化的量,核心是“变”与“量”二字,变即变化,量即衡量状态。
为什么要有变量?
程序执行的本质就是一系列状态的变化,变是程序执行的直接体现,
所以我们需要有一种机制能够反映或者说是保存下来程序执行时状态以及状态的变化。
2.什么是序列化/反序列化
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化
序列化就是将内存中的数据结构转换成一种中间格式存储到硬盘或者基于网络传输
反序列化就是硬盘中或者网络中传来的一种数据格式转换成内存中数据结构
为什要有
# 1、可以保存程序的运行状态
# 2、数据的跨平台交互

3.序列化/反序列化方法
序列化
dumps 处理字符串
dump 处理文件
反序列化
loads 处理字符串
load 处理文件
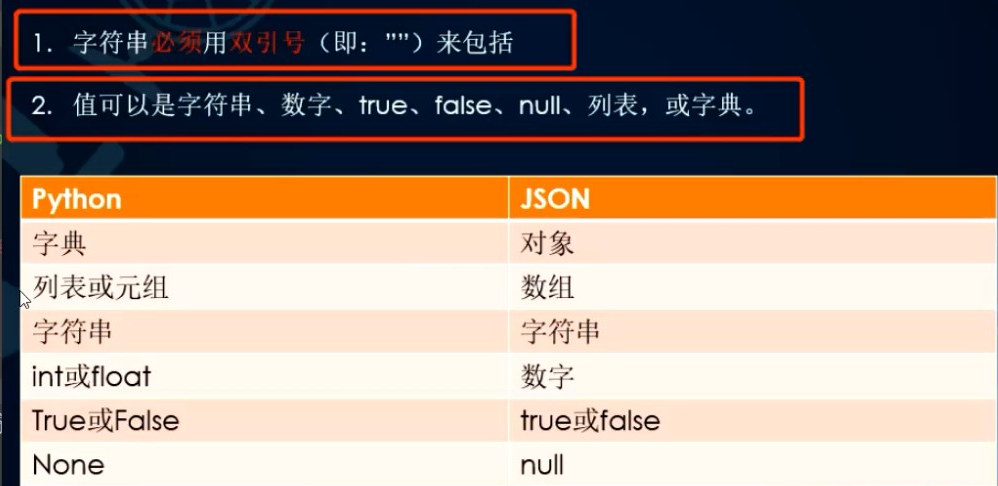
4.json的类型
5.那么我们以字典为例子进行编写代码
1.json序列化
import json
dic = {'name':'dahai','age':18,'sex':'man'}
#序列化:内存中的数据类型------>中间格式json
# dumps(数据类型)
# 1、序列化得到json_str
json_str = json.dumps(dic)
print(json_str)
print(type(json_str))
# # 2、把json_str写入文件
with open('db.json','wt',encoding='utf-8')as f:
f.write(json_str)
# #1和2合为一步
with open('db1.json','wt',encoding='utf-8')as f:
json.dump(dic,f)
2.json反序列化
# @Author : 大海
# @File : json反序列化.py
# 反序列化
# loads 处理字符串
# load 处理文件
#反序列化:中间格式json-----》内存中的数据类型
# loads(json格式字符串)
# 1.读出json文件的json字符串
import json
with open('db.json','rt',encoding='utf-8')as f:
json_str = f.read()
print(json_str)
print(type(json_str))
#
# #2、将json_str转成内存中的数据类型
dic = json.loads(json_str)
print(dic)
print(type(dic))
#1和2可以合作一步
with open('db1.json','rt',encoding='utf-8')as f:
dic = json.load(f)
print(dic)
print(type(dic))
7.os模块
1.认识os模块
os表示操作系统相关的一个模块
os模块是与操作系统交互的一个接口
它可以围绕文件和目录进行操作
2.os和文件夹或文件相关的操作
import os
# 工作目录,当前目录,父级目录都是一个
# D:\python代码A8\day11模块
# 获取当前工作目录,绝对路径
print(os.getcwd())
# 生成目录
os.mkdir('dirname1')
# 空目录,若目录不为空则无法删除
os.rmdir('dirname1')
# 拿到当前脚本工作的目录,相当于cd
os.chdir('dirname1')
# # # # 删除文件
os.remove('aaaa.py')
os.rmdir('dirname1')
# 可生成多层递归目录
os.makedirs('dir1/dir2/dir3/dir4')
# 在dir2下面创建一个文件,会产生保护机制只删除到dir2
os.removedirs('dir1/dir2/dir3/dir4')
# 拿到当前文件夹的文件名或者文件夹放入列表
# 绝对路径
print(os.listdir('D:\python代码A8\day11模块'))
# # 相对路径
print(os.listdir('.'))
# 上一级
print(os.listdir('..'))
# 重命名文件/目录
os.rename('oldname','newname')
# 运行终端命令 了解
os.system('tasklist')
3.os和路径相关的操作
# os.path 下面的方法 path是路径
# 将path分割成目录和文件名二元组返回
print(os.path.split('/a/b/c/d.txt'))
# # 文件夹
print(os.path.split('/a/b/c/d.txt')[0])
# # 文件
print(os.path.split('/a/b/c/d.txt')[1])
#返回path的目录。其实就是os.path.split(path)的第一个元素
print(os.path.dirname('/a/b/c/d.txt'))
# # 返回path最后的文件名。即os.path.split(path)的第二个元素
print(os.path.basename('/a/b/c/d.txt'))
# 判断路径是否存在 文件和文件夹都可以 如果path存在,返回True;如果path不存在,返回False
print(os.path.exists('D:\python代码A8\day11模块'))
print(os.path.exists('D:\python代码A8\day11模块dddd'))
print(os.path.exists(r'D:\python代码A8\day11模块\2.time_test.py'))
print(os.path.exists(r'D:\python代码A8\day11模块\2.timedddd_test.py'))
# 如果path是一个存在的文件,返回True。否则返回False
print(os.path.isfile('D:\python代码A8\day11模块'))
print(os.path.isfile(r'D:\python代码A8\day11模块\2.time_test.py'))
# 也可以用相对路径
print(os.path.isfile(r'./4.hash.py'))
print(os.path.isfile(r'../day11模块/4.hash.py'))
# 如果path是一个存在的目录,则返回True。否则返回False
print(os.path.isdir('D:\python代码A8\day11模块'))
print(os.path.isdir(r'D:\python代码A8\day11模块\2.time_test.py'))
# 拼接一个绝对路径,会忽略前面的路径
print(os.path.join('a','b','c','D:\\','f','d.txt'))
print(os.path.join('D:\\','f','d.txt'))
8.random模块
random随机数相关模块
import random
# 0 - 1 随机浮点 不包含1 random 0-1 开闭
print(random.random())
# randint 1 - 3 开开 整型
print(random.randint(1,3))
# randrange 1 - 3 开闭
print(random.randrange(1,3))
# 随机选⼀个
print(random.choice([1,4,3]))
# 随机选指定个数sample(列表,指定列表的个数)
print(random.sample([1,4,3],2))
# 打乱顺序shuffle(列表)
l = [1,2,3,4,5]
random.shuffle(l)
print(l)
# 闭闭 浮点
print(random.uniform(1,2))
9.sys模块
sys模块是与python解释器交互的一个接口
import sys
# print(sys.path)
# D:\\python代码A8\\day11模块
sys.path.append('D:\python代码A8\day11模块\dir0')
# print(sys.path)
from dir2.aaaaa import a
a()

若有收获,就点个赞吧
0 人点赞
