Java 内存模型指定 Java 虚拟机如何与计算机的内存协同工作。Java 虚拟机是一个完整计算机的模型,因此这个模型自然就包括一个内存模型 - 也就是 Java 内存模型。
如果想设计正确的并发程序,了解 Java 内存模型就是很重要的。Java 内存模型指定不同的线程如何以及什么时候可以看到被其它线程写入到共享变量的值,以及如何在需要的时候同步访问共享变量。
最初的 Java 内存模型有不少不足之处,所以 Java 1.5 中对其做了修订。这个版本的 Java 内存模型现在仍在 Java(Java 14+ )中使用。
内部 Java 内存模型
JVM 内部使用的 Java 内存模型将内存划分为线程栈(Thread Stack)和堆(Heap)。如下是逻辑视角上的 Java 内存模型示意图:
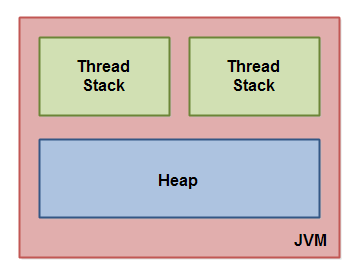
Java 虚拟机中运行的每个线程都有它自己的线程栈。线程栈包含要到达当前执行点,线程已经调用哪些方法的信息。我将之称为调用栈。随着线程执行其代码,调用栈会发生变化。
线程栈还包含每个被执行的方法(调用栈上的所有方法)的所有局部变量。一个线程只能访问它自己的线程栈。一个线程创建的局部变量对于创建它的线程以外的所有其它线程都是不可见的。即使两个线程都在执行完全相同的代码,这两个线程仍然会在每个它们各自的线程栈中创建该代码的局部变量。因此,每个线程都有各自版本的每个局部变量。
所有基础类型(boolean、byte、short、char、int、long、float、double)的局部变量完全存储在线程栈上,因而对其它线程是不可见的。一个线程可能会传递一个基础类型的变量的副本给另一个线程,但是它本身不能共享基础类型的局部变量。
堆包含应用程序中创建的所有对象,不管是哪个线程创建的对象。这包括基础类型的对象版本(比如,Byte、Integer、Long 等)。不管一个对象是被创建并赋值给一个局部变量,还是被创建为另一个对象的成员变量,该对象仍然被存储在堆上。
如下是一个示意图,阐述调用栈、存储在线程栈上的局部变量以及存储在堆上的对象:
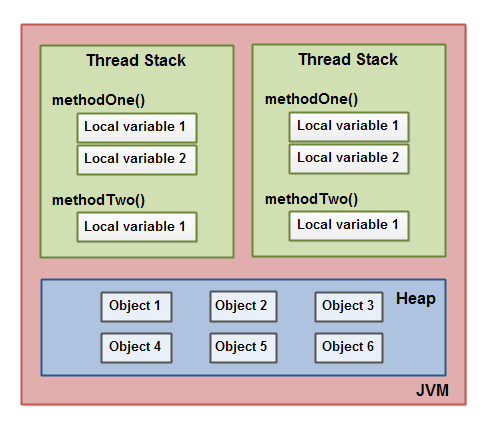
一个局部变量可以是基础数据类型,在这种情况下,它完全保留在线程栈上。
一个局部变量也可以是一个对对象的引用。在这种情况下,引用(局部变量)存储在线程栈上,但是对象本身存储在堆上。
一个对象可能包含方法,而这些方法可能包含局部变量。这些局部变量也存储在线程栈上,即使该方法所属的对象是存储在堆上。
对象的成员变量与对象本身一起存储在堆上。当成员变量是基础类型,或者是对对象的一个引用时,也都是如此。
静态类变量也与类定义一起存储在堆上。
堆上的对象可以被持有该对象的一个引用的所有线程访问。当一个线程访问一个对象时,它还可以访问该对象的成员变量。如果两个线程同时调用同一个对象的方法,它们就都可以访问该对象的成员变量,但是每个线程都会有它自己的成员变量副本。
如下是示意图:
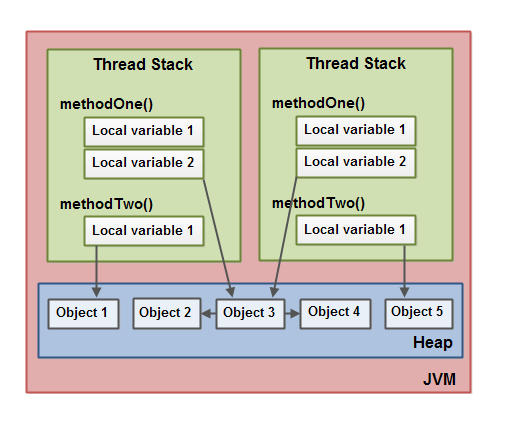
两个线程都有一套局部变量。局部变量之一(Local Variable2)指向堆上的共享对象(Object 3)。这两个线程各自有对同一个对象的不同的引用。它们的引用是局部变量,因此都存储在各自的线程栈中。不过,这两个不同的引用都指向堆上同一个对象。
请注意,共享对象(Object 3)是如何引用 Object 2 和 Object 4 作为成员变量(用从 Object 3 到 Object 2 和 Object 4 的箭头表示)的。通过 Object 3 中这些成员变量引用,这两个线程就都可以访问 Object 2 和 Object 4。
这个图还展示了一个局部变量指向堆上的两个不同对象。在这种情况下,引用是指向两个不同对象(Object 1 和 Object 5),而不是同一个对象。从理论上讲,如果这两个线程都有两个对象的引用的话,这两个线程都可以访问 Object 1 和 Object 5。但是在上图中,每个线程只有对两个对象之一的一个引用。
那么,什么类型的 Java 代码会导致上面的内存图呢?好吧,代码如下所示:
MyRunnable.java
public class MyRunnable implements Runnable() {public void run() {methodOne();}public void methodOne() {int localVariable1 = 45;MySharedObject localVariable2 = MySharedObject.sharedInstance;//... 用局部变量做更多事情。methodTwo();}public void methodTwo() {Integer localVariable1 = new Integer(99);//... 用局部变量做更多事情。}}
MySharedObject.java
public class MySharedObject {// 静态变量指向 MySharedObject 的实例public static final MySharedObject sharedInstance = new MySharedObject();// 成员变量指向堆中的两个对象public Integer object2 = new Integer(22);public Integer object4 = new Integer(44);public long member1 = 12345;public long member2 = 67890;}
如果两个线程都在执行 run() 方法,那么上面的示意图就是结果。run() 方法调用 methodOne(),methodOne() 调用 methodTwo()。
methodOne() 声明了一个基础类型的局部变量(int 类型的 localVariable1),以及一个对象引用类型的局部变量(localVariable2)。
每个执行 methodOne() 的线程会在它们各自的线程栈上创建它自己的 localVariable1 和 localVariable2 的副本。变量 localVariable1 会是完全相互隔离的,只存在每个线程的线程栈上。一个线程不同看见另一个线程对其 localVariable1 的副本修改了什么。
每个执行 methodOne() 的线程也会创建它们自己的 localVariable2 的副本。不过,localVariable2 的这两个不同副本最终都指向堆上的同一个对象。代码设置 localVariable2 指向被一个静态变量引用的对象。静态变量的副本只有一份,这个副本存储在堆上。因此,localVariable2 的这两个副本最终都指向静态变量指向的 MySharedObject 的同一个实例。MySharedObject 实例也存储在堆上。它对应于上图中的 Object 3。
请注意,MySharedObject 类包含了两个成员变量。成员变量本身与对象一起存储在堆上。这两个成员变量指向另外两个 Integer 对象。这些 Integer 对象对应于上图中的 Object 2 和 Object 4。
还请注意,methodTwo() 创建了一个名为 localVariable1 的局部变量。这个局部变量是一个对 Integer 对象的引用。该方法设置 localVariable1 引用指向一个新的 Integer 实例。对于执行 methodTwo() 的每个线程,localVariable1 引用会被以一个线程一个副本的方式存储。两个被实例化的 Integer 对象会被存储在堆上,不过因为每次方法被执行时,该方法都会创建一个新的 Integer 对象,所以两个执行该方法的线程会创建单独的 Integer 实例。methodTwo() 内创建的 Integer 对象对应于上图中的 Object 1 和 Object 5。
还请注意,MySharedObject 类中两个 long 类型的成员变量是基础数据类型。因为这些变量是成员变量,所以它们与该对象一起存储在堆上。只有局部变量存储在线程栈上。
硬件内存架构
现代硬件内存架构与 Java 内部内存模型有些不同。为理解 Java 内存模型如何与硬件内存架构协同工作,理解硬件内存架构也很重要。本节描述常见的硬件内存架构,后一节描述 Java 内存模型如何与它协同工作。
如下是一个现代计算机硬件架构的简化图:
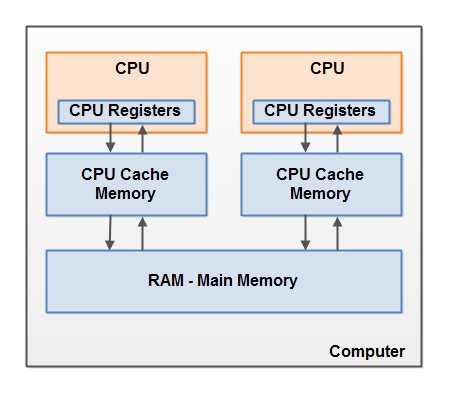
现代计算机通常有两到多个 CPU。有些 CPU 还可能是多核的。关键是,在有 2 到多个 CPU的现代计算机上有可能并发执行多个线程。每个 CPU 在任何给定时间都可以运行一个线程。也就是说,如果我们的 Java 应用程序是多线程的,那么每个 CPU 一个线程可能就在 Java 应用程序内并发(同时)运行。
每个 CPU 都包含一组寄存器,这些寄存器本质上是 CPU 内的内存。CPU 在这些寄存器上执行的速度,比在主内存中的变量上执行的速度要快得多。这是因为 CPU 访问这些寄存器的速度比访问主内存的速度快得多。
每个 CPU 还可以有 CPU 缓存层。事实上,大多数现代 CPU 都有一定大小的缓存层。CPU 访问缓存的速度比访问主内存的速度快多了,但是通常没有访问内部寄存器的速度快。所以,CPU 缓存的速度在内部寄存器和主内存之间。有些 CPU 可能有多级缓存(L1 级和 L2 级),但是这对理解 Java 内存模型如何与内存交互来说,是不重要的。重要的是,要知道 CPU 可以有某种缓存层。
计算机还包含一个主内存区(RAM)。所有 CPU 都可以访问主内存。主内存区通常比 CPU 缓存要大得多。
通常,当 CPU 需要访问主内存时,它会把一部分主内存读到它的 CPU 缓存中。甚至还可以把一部分缓存读到内部寄存器中,然后在寄存器上执行操作。当 CPU 需要把结果写回主内存时,它会把值从内部寄存器刷新到缓存中,并在某个时候将值刷新回主内存。
当 CPU 需要在缓存中存储其它内容时,存储在缓存中的值通常会被刷新回主内存。CPU 缓存可以一次把数据写到部分缓存,并一次刷新部分缓存。它不必在每次被更新时读写整个缓存。通常,缓存是以称为缓存行(Cache Line)的较小内存块的方式更新的。一到多个缓存行可以读到缓存中,并且一到多个缓存行可以再次被刷新回主内存。
弥补 Java 内存模型和硬件内存架构之间的鸿沟
如前所述,Java 内存模型和硬件内存架构是不同的。硬件内存架构不区分线程栈和堆。在硬件上,线程栈和堆都放在主内存中。一部分线程栈和堆有时候可能出现在 CPU 缓存和 CPU 内部的寄存器中。如图所示:
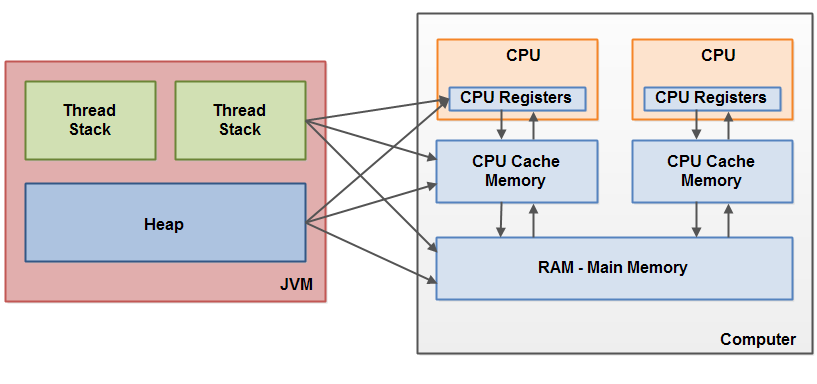
当对象和变量可以存储在计算机中各种不同的内存区时,可能会出现某些问题。两个主要的问题是:
- 更新(写)到共享变量时线程的可见性
- 当读取、检查和写入共享变量时的竞态条件。
这两个问题在如下小节中解释。
共享对象的可见性
如果两到多个线程正在共享一个对象,如果不能正确使用 volatile 声明或者同步,由一个线程对共享对象的更新可能对其它线程是不可见的。
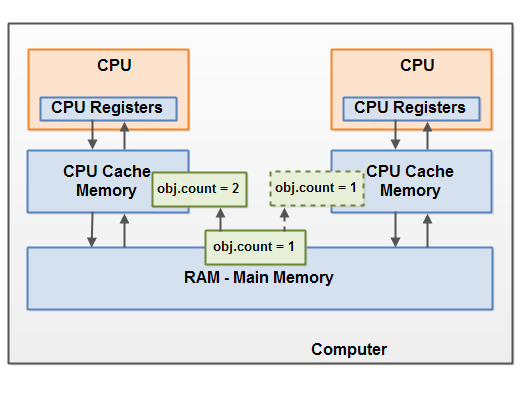
假设共享对象最初是存储在主内存中的。然后运行在 CPU1 上的一个线程把共享对象读到 CPU 缓存中。在缓存中,对共享对象进行修改。只要 CPU 缓存还没有被刷新回主内存,共享对象的更改版本对运行在其它 CPU 上的线程就是不可见的。通过这种方式,每个线程最终可能会有它自己的共享对象的副本,每份副本都位于不同的 CPU 缓存中。
下图说明了大致情况。运行在左边 CPU 上的线程把共享对象复制到它的 CPU 缓存,并把它的 count 变量修改为 2。这种修改对运行在右边 CPU 上的其它线程是不可见的,因为对 count 的更新还没有刷新回主内存。
要解决这个问题,我们可以使用 Java 的 volatile 关键字。volatile 关键字可以确保指定变量直接从主内存中读取,并且在更新时被写回到主内存。
竞态条件
如果两到多个线程共享一个对象,并且多个线程都在更新该共享对象中的变量,竞态条件就可能会发生。
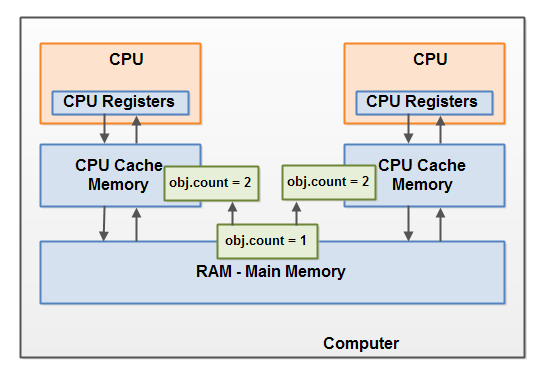
假设线程 A 把一个共享对象的 count 变量读入到它的 CPU 缓存中。线程 B 也做同样的事情,但是是读入到不同的 CPU 缓存中。现在线程 A 给 count 加一,线程 B 也做一样的事情。现在 count 已经递增两次了,每个 CPU 缓存中递增一次。
如果递增是按顺序执行的,那么变量 count 就会递增两次,并把原始值加上 2 写回给主内存。
不过,这两次递增是在没有正确同步的情况下并发执行的。不管线程 A 和 B 中的哪一个把它的更新版本的 count 写回主内存,尽管有两次递增,更新后的值会只比原始值高 1。
下图说明上述竞态条件问题的发生:
要解决这个问题,可以用 Java 同步块。同步块保证在任何指定时间,只有一个线程可以进入到指定的代码临界区。同步块还可以保证同步块内的所有变量访问会是从主内存中读取的,并且当线程退出同步块时,所有被更新的变量都会被再次刷新回主内存,而不管变量是否声明为 volatile。

若有收获,就点个赞吧
0 人点赞
