一、selenium介绍
- selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
from selenium import webdriver#webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器browser=webdriver.Chrome()browser=webdriver.Firefox()browser=webdriver.PhantomJS()browser=webdriver.Safari()browser=webdriver.Edge()
- Selenium是一个自动化测试工具,支持各种浏览器,包括Chrome、Safari、Firefox等主流界面式浏览器,也包括PhantomJS等无界面浏览器,通俗来说Selenium支持浏览器驱动,可以对浏览器进行控制。而且Selenium支持多种语言开发,比如Java、C、Ruby,还有Python,因此Python+Selenium+PhantomJS的组合就诞生了。PhantomJS负责渲染解析JavaScript, Selenium负责驱动浏览器和与Python对接,Python负责做后期处理,三者构成了一个完整的爬虫结构。
二、环境搭建
1、有界面浏览器
-
(1)安装selenium
-
(2)获取浏览器的驱动程序
不获得浏览器的驱动程序则无法操作浏览器。以谷歌浏览器为例:谷歌浏览器驱动下载地址
下载的驱动程序必须和浏览器的版本统一,具体查看selenium之chromedriver与chrome版本映射表
(3)获取浏览器的驱动程序
① 查看浏览器版本
Chrome -> 关于Google Chrome
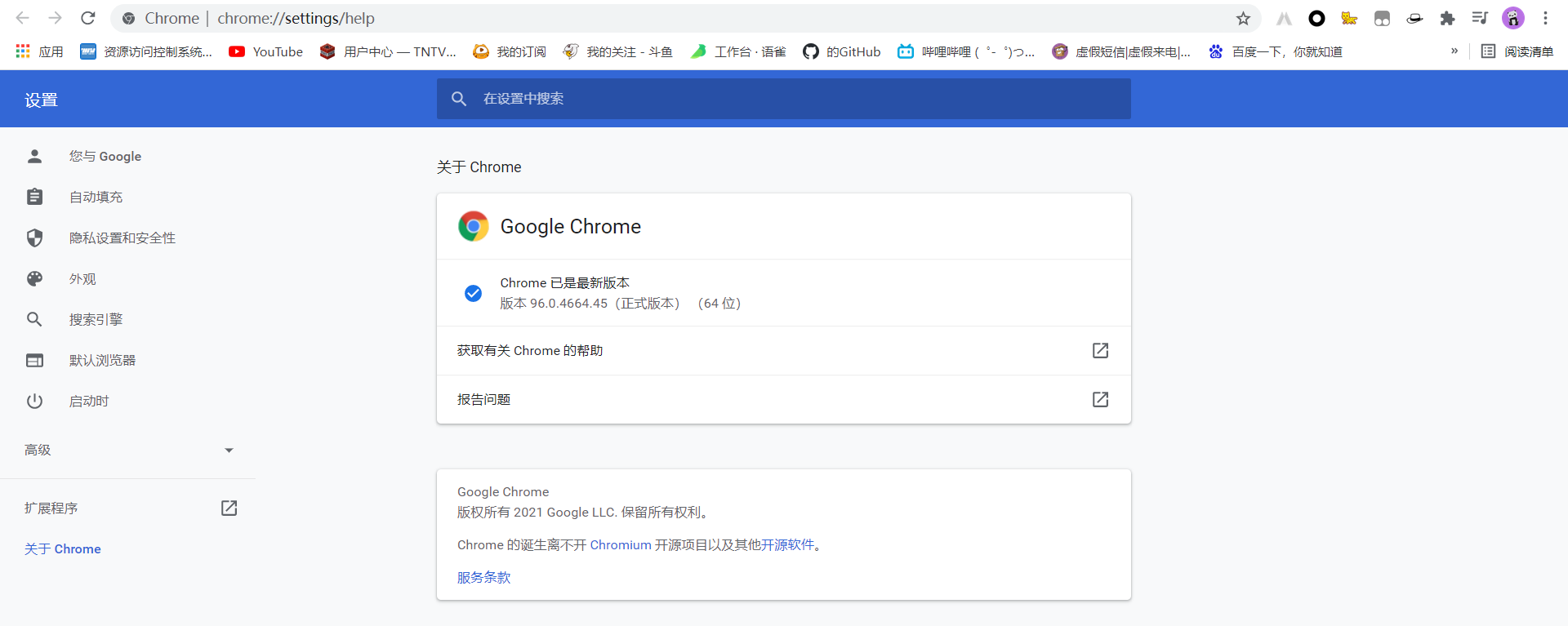
② 下载浏览器对应的驱动程序
- 查看chrome和chromedriver的对应关系,我们应该下载 96.0.4664.45 版本对应的chromedriver驱动
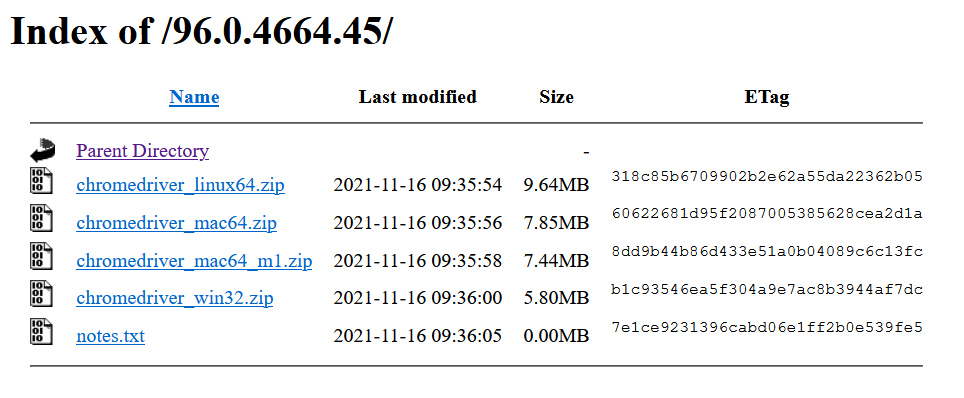
- 我选择Windows版本的驱动下载,解压后,将文件chromedriver拷贝python安装路径的scripts目录中即可
(4)验证安装
```python from selenium import webdriver
driver=webdriver.Chrome() #弹出浏览器 driver.get(‘https://www.baidu.com‘) driver.page_source #selenium的page_source方法可以直接返回页面源码
<a name="KMYGz"></a>### (5)注意- selenium3默认支持的webdriver是Firfox,而Firefox需要安装geckodriver 下载链接:[https://github.com/mozilla/geckodriver/releases](https://github.com/mozilla/geckodriver/releases)<a name="IBxnY"></a>## 2、无界面浏览器- selenium+phantomjs- PhantomJS不再更新<a name="tj38v"></a>### (1)安装selenium- `**pip3 install selenium**`<a name="nUtgx"></a>### (2)下载phantomJS- 下载phantomjs,解压后把phantomjs.exe所在的bin目录放到环境变量- 下载链接:[http://phantomjs.org/download.html](http://phantomjs.org/download.html)<a name="YV1IR"></a>### (3)验证安装```powershell#验证安装C:\Users\Administrator>phantomjsphantomjs> console.log('egon gaga')egon gagaundefinedphantomjs> ^CC:\Users\Administrator>python3Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)] on win32Type "help", "copyright", "credits" or "license" for more information.>>> from selenium import webdriver>>> driver=webdriver.PhantomJS() #无界面浏览器>>> driver.get('https://www.baidu.com')>>> driver.page_source
(3)selenium+谷歌浏览器headless模式
- 在 PhantomJS 年久失修, 后继无人的节骨眼 ,Chrome 出来救场, 再次成为了反爬虫 Team 的噩梦
- 自Google 发布 chrome 59 / 60 正式版 开始便支持
Headless mode,这意味着在无 GUI 环境下, PhantomJS 不再是唯一选择 ```python from selenium import webdriver from selenium.webdriver.chrome.options import Options
chrome_options = Options() # 实例化一个启动参数对象 chrome_options.add_argument(‘window-size=1920x3000’) # 指定浏览器分辨率 chrome_options.add_argument(‘—disable-gpu’) # 谷歌文档提到需要加上这个属性来规避bug chrome_options.add_argument(‘—hide-scrollbars’) # 隐藏滚动条, 应对一些特殊页面 chrome_options.add_argument(‘blink-settings=imagesEnabled=false’) # 不加载图片, 提升速度 chrome_options.add_argument(‘—headless’) # 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败 chrome_options.binary_location = r”C:\Program Files (x86)\Google\Chrome\Application\chrome.exe” # 手动指定使用的浏览器位置
driver = webdriver.Chrome(options=chrome_options) driver.get(‘https://www.baidu.com‘)
print(‘hao123’ in driver.page_source)
driver.close() # 切记关闭浏览器,回收资源
<a name="uvRNe"></a># 三、基本使用<a name="AdhSS"></a>## 1、声明浏览器对象- 注意点一,Python文件名或者包名不要命名为selenium,会导致无法导入```pythonfrom selenium import webdriver#webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器,这里以Chrome为例browser = webdriver.Chrome()
2、访问页面并获取网页html
from selenium import webdriverbrowser = webdriver.Chrome()browser.get('https://www.taobao.com')print(browser.page_source) # browser.page_source是获取网页网页的全部htmlbrowser.close()
3、输入内容到搜索框并查找
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysimport timedriver = webdriver.Chrome() # 获取chrome浏览器的驱动driver.get("http://www.baidu.com") # 调用get方法,打开百度首页assert u"百度" in driver.title # 判断标题中是否包含百度字样elem = driver.find_element(By.NAME, "wd") # 通过元素名称wd获取输入框elem.clear()elem.send_keys(u"网络爬虫") # 通过send_keys方法将网络爬虫填写其中elem.send_keys(Keys.RETURN) # 回车time.sleep(3) # 延时3秒assert u"网络爬虫. " not in driver.page_source # 判断搜索页面是否有网络爬虫字样driver.close() # 最后关闭driver
四、元素选取
- 要想对页面进行操作,首先要做的是选中页面元素
除了上面具有确定功能的方法,还有两个通用方法
**find_element**和**find_elements**,可以通过传入参数来指定功能。示例如下from selenium.webdriver.common.by import Bydriver.find_element(By.XPATH, '//button[text()="Some text"]')
这一个例子是通过xpath表达式来查找,方法中第一个参数是指定选取元素的方式,第二个参数是选取元素需要传入的值或表达式。第一个参数还可以传入By类中的以下值:
By.IDBy.XPATHBy.LINK_TEXTBy.PARTIAL_LINK_TEXTBy.NAMEBy.TAG_NAMEBy.CLASS_NAMEBy.CSS_SELECTOR
下面通过一个HTML文档来讲解一下如何使用以上方法提取内容,HTML文档如下:
<html><body><h1>Welcome</h1><p class="content">用户登录</p><form id="loginForm"><input name="username" type="text" /><input name="password" type="password" /><input name="continue" type="submit" value="Login" /><input name="continue" type="button" value="Clear" /></form><a href="register.html">Register</a></body></html>
定位方法的使用如表所示

五、页面操作
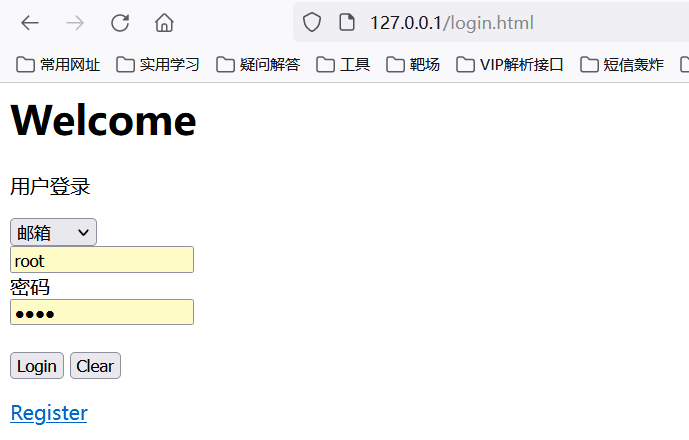
以如下HTML文档为例介绍页面操作,login.html代码如下:
<html><head><meta http-equiv="content-type" content="text/html; charset=gbk"></head><body><h1>Welcome</h1><p class="content">用户登录</p><form id="loginForm"><select name="loginways"><option value="email">邮箱</option><option value="mobile">手机号</option><option value="name">用户名</option></select><br/><input name="username" type="text" /><br/>密码<br/><input name="password" type="password" /><br/><br/><input name="continue" type="submit" value="Login" /><input name="continue" type="button" value="Clear" /></form><a href="register.html">Register</a></body></html>
效果如图所示
1、页面交互与填充表单
第一步:初始化Chrome驱动,打开html文件,由于是本地文件,可以使用下面方式打开。
driver = webdriver.chrome()driver.get("file:// /D:/phpstudy_pro/WWW/login.html")
第二步:获取用户名和密码的输入框,和登录按钮。
username = driver.find_element(By.NAME, 'username')password = driver.find_element(By.XPATH, ".//*[@id='loginForm']/input[2]")login_button = driver.find_element(By.XPATH, "//input[@type='submit']")
第三步:使用send_keys方法输入用户名和密码,使用click方法模拟点击登录。
username.send_keys("qiye")password.send_keys("qiye_pass")login.button.click()
如果想清除username和password输入框的内容,可以使用clear方法
username.clear()password.clear()
上面还有一个问题没解决,如何操作下拉选项卡选择登录方式呢?第一种方法代码如下:
select = driver.find_element(By.XPATH, "//form/select")all_options = select.find_elements(By.TAG_NAME, "option")for option in all_options:print("Value is: %s" % option.get_attribute("value"))option.click()
在代码中首先获取select元素,也就是下拉选项卡。然后轮流设置了select选项卡中的每一个option选项。这并不是一个非常好的办法。官方提供了更好的实现方式,在WebDriver中提供了一个叫Select方法,也就是第二种操作方式。代码如下:
from selenium.webdriver.support.ui import Selectselect = Select(driver.find_element(By.XPATH, '//form/select'))select.select_by_index(index)select.select_by_visible_text("text")select.select_by_value(value)
它可以根据索引、文字、value值来选择选项卡中的某一项。如果select标记中multiple=”multiple”,也就是说这个select标记支持多选,Select对象提供了支持此功能的方法和属性。示例如下:
取消所有的选项:select.deselect_all()获取所有的选项:select.options获取已选中的选项:select. all_selected_options
2、元素拖拽
元素的拖拽即将一个元素拖到另一个元素的位置,类似于拼图。首先要找到源元素和目的元素,然后使用ActionChains类可以实现。代码如下: ```python element = driver.find_element(By.NAME, “source”) target = driver.find_element(By.NAME, “target”)
from selenium.webdriver import ActionChains action_chains = ActionChains(driver) action_chains.drag_and_drop(element, target).platform()
<a name="QT4Yj"></a>## 3、窗口和页面frame的切换- 一个浏览器一般都会开多个窗口,我们可以switch_to_window方法实现指定窗口的切换。示例如下:```pythondriver.switch_to_window("windowName")
也可以通过window handle来获取每个窗口的操作对象。示例如下:
for handle in driver.window_handles:driver.switch_to_window(handle)
如需切换页面frame,可以使用switch_to_frame方法,示例如下:
iframe = browser.find_element(By.ID, "loginIframe")browser.switch_to.frame(iframe)
4、弹窗处理
如果你在处理页面的过程中,触发了某个事件,跳出弹框。可以使用switch_to_alert获取弹框对象,从而进行关闭弹框、获取弹框信息等操作。示例如下:
alert = driver.switch_to_alert()alert.dismiss()
5、历史记录
操作页面的前进和后退功能,示例如下
driver.forward()driver.back()
6、Cookie处理
可以使用get_cookies方法获取cookie,也可以使用add_cookie方法添加cookie信息。示例如下: ```python from selenium import webdriver
driver = webdriver.Chrome() driver.get(“http://www.baidu.com“) cookie = {‘name’: ‘foo’, ‘value’: ‘bar’} driver.add_cookie(cookie) driver.get_cookies()
<a name="iS6C0"></a>## 7、设置phantomJS请求头中User-Agent- 这个功能在爬虫中非常有用,一般针对phantomJS的反爬虫措施都会检测这个字段,默认的User-Agent中含有phantomJS内容,可以通过代码进行修改。代码如下:```pythonfrom selenium import webdriverdcap = dict(DesiredCapabilities.PHANTOMJS)dcap["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/48.0.2564.23 Mobile Safari/537.36 ")driver = webdriver.PhantomJS() # desired_capabilities=dcap)driver.get("http://www.google.com")driver.quit()
六、等待
由于现在很多网站采用Ajax技术,不确定网页元素什么时候能被完全加载,所以网页元素的选取会比较困难,这时候就需要等待。Selenium有两种等待方式,一种是显式等待,一种是隐式等待。
1、显式等待
显式等待是一种条件触发式的等待方式,指定某一条件直到这个条件成立时才会继续执行,可以设置超时时间,如果超过这个时间元素依然没被加载,就会抛出异常。示例如下: ```python from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome() driver.get(“https://somedoamin/url_that_delays_loading“) try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, “myDynamicElement”)) ) finally: driver.quit()
- 以上代码加载[http://somedomain/url_that_delays_loading](http://somedomain/url_that_delays_loading)页面,并定位id为myDynamic Element的元素,设置超时时间为10s。WebDriverWait默认会500ms检测一下元素是否存在。- Selenium提供了一些内置的用于显式等待的方法,位于expected_conditions类中,方法名称如表所示: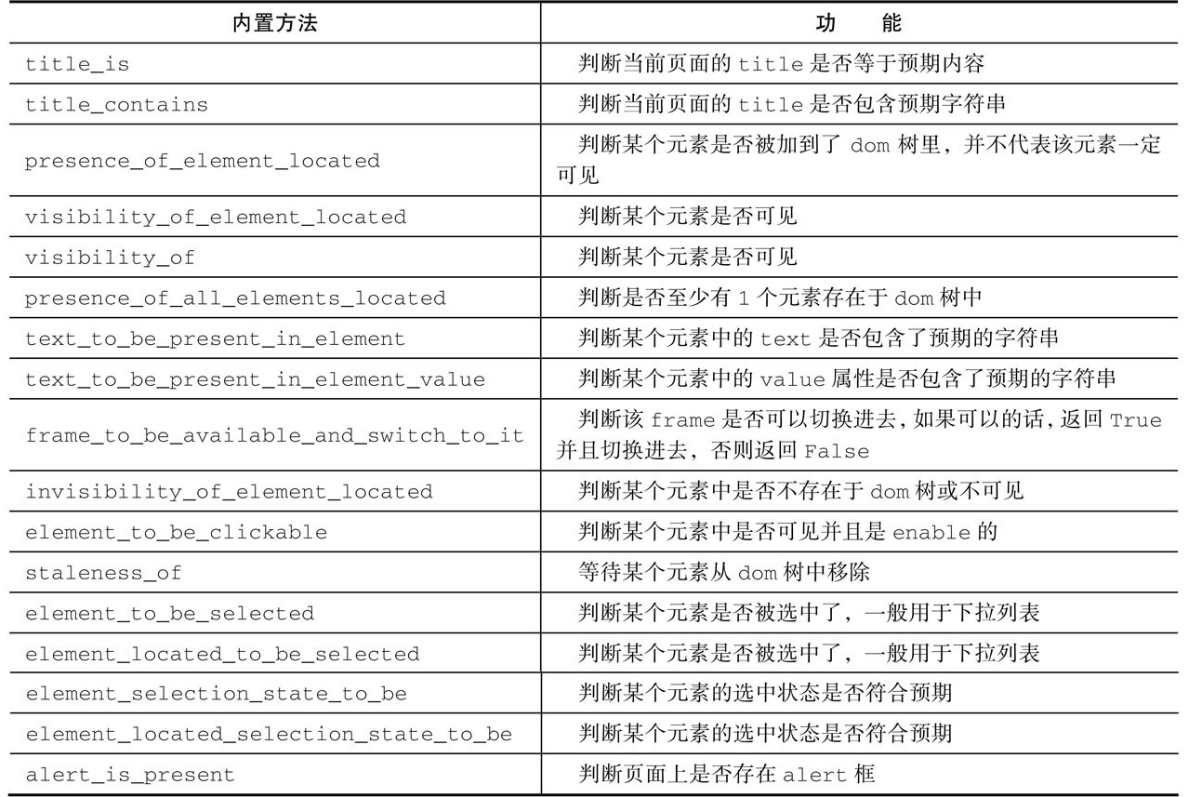<a name="NnFZW"></a>## 2、隐式等待- 隐式等待是在尝试发现某个元素的时候,如果没能立刻发现,就等待固定长度的时间,类似于socket超时,默认设置是0秒。一旦设置了隐式等待时间,它的作用范围是Webdriver对象实例的整个生命周期,也就是说Webdriver执行每条命令的超时时间都是如此。如果大家感觉设置的时间过长,可以进行不断地修改。使用方法示例如下:```pythonfrom selenium import webdriverdriver = webdriver.Chrome()driver.implicitly_wait(10) # secondsdriver.get("http://somedomain/url_that_delays_loading")myDynamicElement = driver.find_element(By.ID, "myDynamicElement")
3、线程休眠
time.sleep(time),这是使用线程休眠延时的办法,也是比较常用的。
七、动态爬虫:爬取去哪儿网
讲解完了Selenium,接下来编写一个爬取去哪网酒店信息的简单动态爬虫。目标是爬取上海今天的酒店信息,并将这些信息存成文本文件。下面将整个目标进行功能分解:
1)搜索功能,在搜索框输出地点和入住时间,点击搜索按钮
2)获取一页完整的数据。由于去哪网一个页面数据分为两次加载,第一次加载15条数据,这时候需要将页面拉到底部,完成第二次数据加载。
3)获取一页完整且渲染过的HTML文档后,使用BeautifulSoup将其中的酒店信息提取出来进行存储。
4)解析完成,点击下一页,继续抽取数据。
- 第一步:找到酒店信息的搜索页面,如图所示。
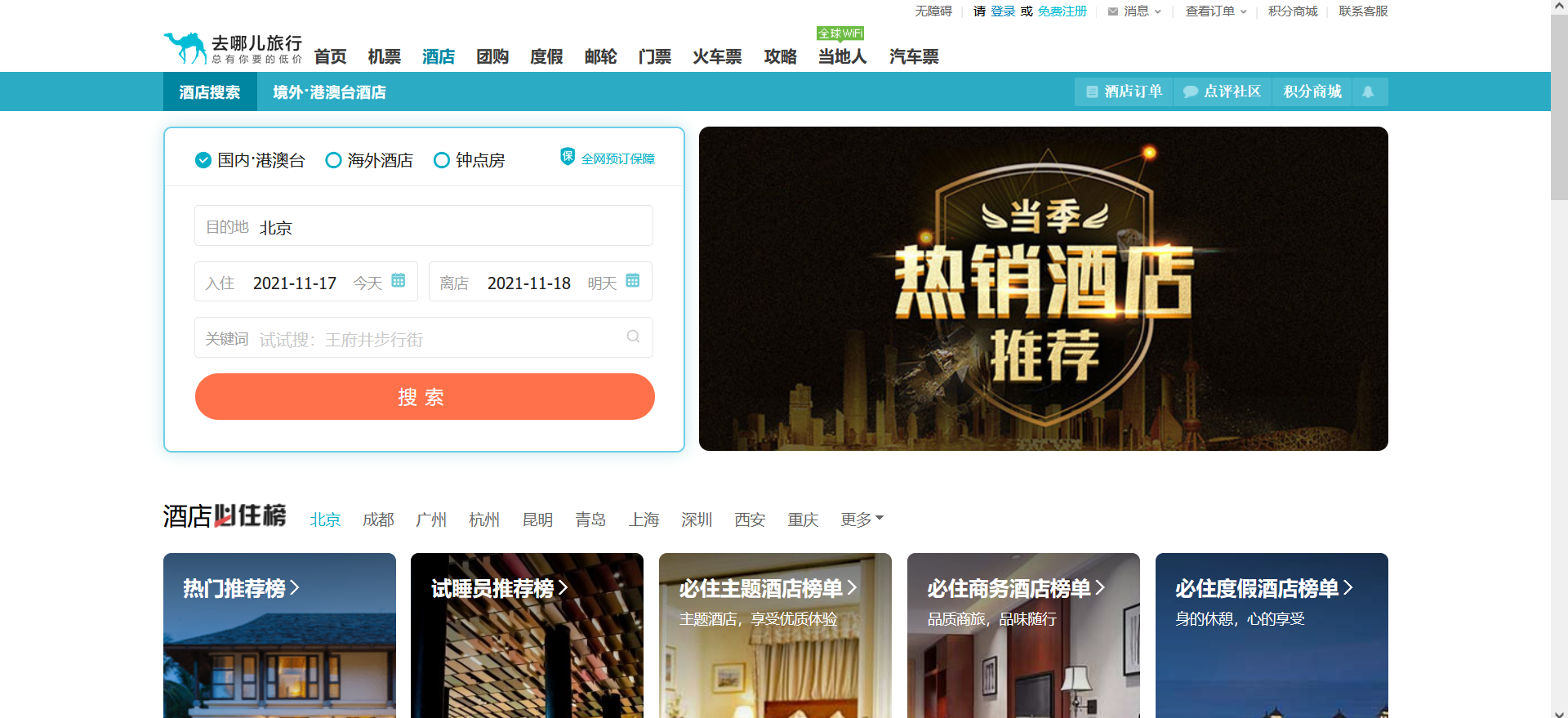
使用Firebug查看Html结果,可以通过selenium获取目的地框、入住日期、离店日期和搜索按钮的元素位置,输入内容,并点击搜索按钮。
ele_toCity = driver.find_element(By.NAME, 'toCity')ele_fromDate = driver.find_element(By.ID, 'fromDate')ele_toDate = driver.find_element(By.ID, 'toDate')ele_search = driver.find_element(By.CLASS_NAME, 'search-btn')ele_toCity.clear()ele_toCity.send_keys(to_city)ele_toCity.click()ele_fromDate.clear()ele_toCity.send_keys(fromdate)ele_toDate.clear()ele_toDate.send_keys(todate)ele_search.click()
第二步:分两次获取一页完整的数据,第二次让driver执行js脚本,把网页拉到底部。 ```python try: WebDriverWait(driver, 10).until(
EC.title_contains(unicode(to_city))
) except Expection, e: print(e) break time.sleep(5)
js = “window.scrollTo(0, document.body.scrollHeight);” driver.execute_script(js) time.sleep(5) htm_const = driver.page_source
- **第三步:**使用BeautifulSoup解析酒店信息,并将数据进行清洗和存储。```pythonsoup = BeautifulSoup(htm_const, 'html.parser', from_encoding='utf-8')infos = soup.find_all(class="item_hotel_info")f = codecs.open(unicode(to_city)+unicode(fromdate)+u'.html', 'a', 'utf-8')for info in infos:f.write(str(page_num)+'--'*50)content = info.get_text().replace(" ", "").replace("\t", "").strip()for line in [ln for ln in content.splitlines() if ln.strip()]:f.write(line)f.write('\r\n')f.close()
第四步:点击下一页,继续重复这一个过程。
next_page = WebDriverWait(driver, 10).until(EC.visibility_of(driver.find_element(By.CSS_SELECTOR, ".item.text")))next_page.click()
这个小例子只是简单实现了功能,完整代码如下: ```python class QunaSpider(object): def get_hotel(self, driver, to_city, fromdate, todate):
ele_toCity = driver.find_element(By.NAME, 'toCity')ele_fromDate = driver.find_element(By.ID, 'fromDate')ele_toDate = driver.find_element(By.ID, 'toDate')ele_search = driver.find_element(By.CLASS_NAME, 'search-btn')ele_toCity.clear()ele_toCity.send_keys(to_city)ele_toCity.click()ele_fromDate.clear()ele_toCity.send_keys(fromdate)ele_toDate.clear()ele_toDate.send_keys(todate)ele_search.click()page_num = 0while True:try:WebDriverWait(driver, 10).until(EC.title_contains(unicode(to_city)))except Exception as e:print(e)breaktime.sleep(5)js = "window.scrollTo(0, document.body.scrollHeight);"driver.execute_script(js)time.sleep(5)htm_const = driver.page_sourcesoup = BeautifulSoup(htm_const, 'html.parser', from_encoding='utf-8')infos = soup.find_all(class_="item_hotel_info")f = codecs.open(unicode(to_city) + unicode(fromdate) + u'.html', 'a', 'utf-8')for info in infos:f.write(str(page_num) + '--' * 50)content = info.get_text().replace(" ", "").replace("\t", "").strip()for line in [ln for ln in content.splitlines() if ln.strip()]:f.write(line)f.write('\r\n')f.close()try:next_page = WebDriverWait(driver, 10).until(EC.visibility_of(driver.find_element(By.CSS_SELECTOR, ".item.text")))next_page.click()page_num += 1time.sleep(10)except Exception as e:print(e)break
def crawl(self, root_url, to_city):
today = datatime.date.today().strftime('%Y-%m-%d')tomorrow = datetime.date.today() + datetime.timedelta(days=1)tomorrow = tomorrow.strftime('%Y-%m-%d')driver = webdriver.Chrome(executable_path='D:\geckodriver_win32\gecko-driver.exe')driver.set_page_load_ti meout(50)driver.get(root_url)driver.maximize_window() # 将浏览器最大化显示driver.implicitly_wait(10) # 控制间隔时间,等待浏览器反映self.get_hotel(driver, to_city, today, tomorrow)
if name == “main“: spider = QunaSpider() spider.crawl(‘http://hotel.qunar.com/‘, u”上海”) ```
八、小结
- 本章讲解了两种动态网站抓取的方法,两种方法有利有弊。直接从JavaScript中提取数据远比使用Selenium+PhantomJS速度快,占用系统内存小,但是碰到参数加密的情况,分析起来就较为复杂,而Selenium+PhantomJS恰恰避免了这个问题,反爬虫能力很强,基本上可以躲过大部分的检测。两种方法都要掌握,针对不同的网站使用不同的策略。

若有收获,就点个赞吧
0 人点赞
