原则
更小的通常更好
- 更小的数据类型,占据更小的磁盘,内存和CPU缓存,并且处理时需要的CPU周期也更少
- 需要确定没有低估需要存储的值得范围
简单就好
- 简单数据类型的操作需要更少的CPU周期
- 整型比字符串操作低
- 尽量避免null
- 为null 的列使得索引,索引统计和值比较都更复杂
- 可为null的列会使用更多的存储空间,在mysql里需要额外处理
- 当可以为null的列被索引时,每个索引记录需要一个额外的值
- 甚至会导致,固定大小的索引,变成可变大小的索引
- Innodb 有单独的位bit 来存储null 所以一般这种调优 提升比较小 其实
选择调优的数据类型
整数类型
有这几种整数类型,
- tinyint 8位存储空间
- smllint 16位
- mediumint 24位
- int 32位
- bigint 64位
他们的值可以从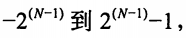 N 为位数
N 为位数
整数类型 有 正数和负数 unsigned 属性 表示不允许为负数, 如果不为负数,那么取值范围 上限提高一倍, 如果原来是 -10 - 10 如果不为负数 那么就可以为 0 - 20
int(1) 和 int(20) 对于存储和计算来说 是一样的
实数类型
实数就是带有小数的数字
- float 和 double 类型支持使用标准的浮点运算进行近似计算
- decimal 可以存储比bigint 还要大的数字 用于存储精确地小数 只有需要精确计算的时候才使用
- 数量比较大时,可以使用bigint代替,例如可以将小数字 乘以100万 然后存储起来
字符串类型
varchar 和 char 类型
varchar
- 用于存储可变长度的字符串,比定长更节省空间
- 由于时变长的,所以在update时候更耗费时间
- 适合的场景
- 字符串列的最大长度比平均长度大很多
- 列的更新很少,所以碎片不是问题
- 使用了像UTF-8这样复杂的字符集,每个都是用不同的字节数进行存储
- 大于等于5.0的版本 存储和检索的时候 会保留末尾空格
char
- 存储char值时,会删除结尾空格
- 适合的场景
- 存储密码的MD5值,因为MD5时定长的
最好的策略就是 只分配真正需要的空间
binary 和 varbinary类型
他们存储的是二进制字符串,存储的是字节码 而不是字符
blob 和 text 类型
都是为了存储很大的数据而设计的字符串数据类型
- blob 采用二进制存储
- text 采用字符存储
text
字符串类型分别为
- tinytext
- smalltext
- text
- mediumtext
- longtext
blob
二进制类型分别为
- tinyblob
- smallblob
- blob
- mediumblob
- longblob
当blob 和 text 过大的时候,存储引擎会使用 专门的 外部的存储区域来存储
此时在行内存储的是 1~ 4字节大小的指针 类似于 堆内存 在栈内存中存储的一个指针
使用枚举代替 字符串类型
对于一些固定值列,可以使用枚举
日期 和 时间类型
mysql 能存储的最小时间粒度为秒
大部分时间类型都没有替代品,因此没有最佳选择
datetime 和 timestamp
datetime
- 存储 1001 - 9999 年 范围之间的值, 精确度为秒 封装到 YYYY-MM-DD HH-MM-SS 的格式中, 与时区无关
- 使用8个字节存储
- 保留文本表示的日期和时间
timestamp
除了特殊情况,我们就尽量使用timestamp,因为效率高
- 保存了 从190.1.1 开始 的秒数
- 只是用4个字节的存储空间
- 范围比datetime小 只能 到2038年
- FROM_UNIXTIME 方法可以吧时间戳转为 日期
- UNIX_TIMESTAMP 方法把日期 转为时间戳
- 与时区有关,时间会与时区的变化而变化
- 默认为not null
- 插入值时,如果没有指定列的值,那么就会将列设置为当前时间 自动设置的 所以一般记录此行数据的插入时间
位数据类型
少数的几种类型用位存储数据
不管存储方式和处理方式,从技术上来说,位数据类型 其实都属于字符串类型
bit
谨慎使用
- 在一列中存储一个或者多个 true/false 值
- 最大长度为64位
- InnoDB 使用一个足够存储的最小类型来存放,所以不能节省空间
选择标识符
特殊类型数据
例如 ipv4 地址 其实是一个32位 无符号整数 不是字符串
所以应该使用无符号整数来存储ip地址,
mysql提供了 inet_aton() 和 inet_ntoa() 方法来在这两种数据之间转换
MySQL schema 设计中的缺陷
- 太多的列
- 存储引擎API 在工作的时候需要在服务器层和存储引擎层之间通过行缓冲格式,拷贝数据,然后再服务层将缓冲内容解码成各个列,从行缓冲中将编码 过得列转为行数据结构是非常耗性能的,所以一般要求列的数量不要太多了
- 太多的关联
- EVA 实体 属性 值 模式 单个查询关联的表最好少于12个表
- 全能的枚举
- 防止过度使用枚举
- 变相的枚举
- 非此发明的null
范式和反范式
范式
第一范式
表中的每一列,都是最小的数据单元,确保不可再分,则满足第一范式
例如:user用户表,包含字段id,username,password
第二范式
在第一范式的基础上,保证每一列的数据都和主键有关
例如:一个用户只有一种角色,而一个角色对应多个用户。则可以按如下方式建立数据表关系,使其满足第二范式。
user用户表,字段id,username,password,role_id
role角色表,字段id,name
第三范式
在第二范式的基础上,更近一步,表的每一列与主键都强相关,所以需要将关系列单独拆分出去成一个表
例如:一个用户可以对应多个角色,一个角色也可以对应多个用户。则可以按如下方式建立数据表关系,使其满足第三范式。
user用户表,字段id,username,password
role角色表,字段id,name
user_role用户-角色中间表,id,user_id,role_id
像这样,通过第三张表(中间表)来建立用户表和角色表之间的关系,同时又符合范式化的原则,就可以称为第三范式。
反范式

若有收获,就点个赞吧
0 人点赞
