lambda表达式介绍
Java 8的一个大亮点是引入Lambda表达式,使用它设计的代码会更加简洁。通过Lambda表达式,可以替代我们以前经常写的匿名内部类来实现接口。Lambda表达式本质是一个匿名函数
体验Lambda表达式
lambda表达式用得最多的场合就是替代匿名内部类,而实现Runnable接口是匿名内部类的经典例子
// Java7new Thread(new Runnable(){@Overridepublic void run() {for (int i = 0; i < 100; i++) {System.out.println(i);}}}).start();// Java8new Thread(() -> {for (int i = 0; i < 100; i++) {System.out.println(i);}}).start();
使用lambda表达式对集合进行迭代
public class TestCollection{public static void main(String[] args) {List<String> languages = Arrays.asList("java", "scala", "python");//before java8for (String each : languages) {System.out.println(each);}//after java8languages.forEach(x -> System.out.println(x));languages.forEach(System.out::println);}}
自定义接口
public interface ICalculate{int calculate(int x, int y);}public class TestCalculate{public static void main(String[] args) {//jdk7ICalculate iCalculate = new ICalculate(){@Overridepublic int calculate(int x, int y) {return x + y;}};System.out.println(iCalculate.calculate(1, 3));//jdk8iCalculate = (x, y) -> x - y;System.out.println(iCalculate.calculate(5, 6));}}
Lambda表达式语法
一般的函数类有返回值,方法名,参数列表,方法体
Lambda表达式函数的话,只有参数列表,和方法体;(函数类型不需要申明,可以由接口的方法签名自动推导出来)
( 参数列表 ) -> { 方法体 }
说明:
( ) :用来描述参数列表;
{ } : 用来描述方法体;
-> :Lambda运算符,可以叫做箭头符号,或者goes to
Lambda表达式精简语法
精简语法注意点:
- 参数类型可以省略
- 假如只有一个参数,()括号可以省略
- 如果方法体只有一条语句,{}大括号可以省略
- 如果方法体中唯一的语句是return返回语句,那省略大括号的同事return也要省略
方法引用
有时候多个lambda表达式实现函数是一样的话,我们可以封装成通用方法,以便于维护;
这时候可以用方法引用实现:
语法是:对象::方法
假如是static方法,可以直接 类名::方法
public class TestMethod{public static void main(String[] args) {TestMethod testMethod = new TestMethod();ICalculate iCalculate = testMethod::calculate;ICalculate iCalculate1 = testMethod::calculate1;System.out.println(iCalculate.calculate(5, 7));System.out.println(iCalculate1.calculate(5, 7));}public int calculate(int x, int y) {return x + y;}public int calculate1(int x, int y) {return x - y;}}
构造方法引用
如果函数式接口的实现恰好可以通过调用一个类的构造方法来实现,
那么就可以使用构造方法引用;
语法:类名::new
public Dog() {System.out.println("无参构造方法");}public Dog(String name, int age) {System.out.println("有参构造方法");this.name = name;this.age = age;}public class TestDog{public static void main(String[] args) {// 普通方式DogService dogService = () -> {return new Dog();};dogService.getDog();// 简化方式DogService dogService2 = () -> new Dog();dogService2.getDog();// 构造方法引用DogService dogService3 = Dog::new;dogService3.getDog();// 构造方法引用 有参DogService2 dogService21 = Dog::new;dogService21.getDog("小米", 11);}}interface DogService{Dog getDog();}interface DogService2{Dog getDog(String name, int age);}
@FunctionalInterface注解
这个注解是函数式接口注解,所谓的函数式接口,当然首先是一个接口,然后就是在这个接口里面只能有一个抽象方法。
这种类型的接口也称为SAM接口,即Single Abstract Method interfaces
- 接口有且仅有一个抽象方法
- 允许定义静态方法
- 允许定义默认方法
- 允许java.lang.Object中的public方法
该注解不是必须的,如果一个接口符合”函数式接口”定义,那么加不加该注解都没有影响。加上该注解能够更好地让编译器进行检查。如果编写的不是函数式接口,但是加上了@FunctionInterface,那么编译器会报错
// 正确的函数式接口@FunctionalInterfacepublic interface TestInterface {// 抽象方法public void sub();// java.lang.Object中的public方法public boolean equals(Object var1);// 默认方法public default void defaultMethod(){}// 静态方法public static void staticMethod(){}}// 错误的函数式接口(有多个抽象方法)@FunctionalInterfacepublic interface TestInterface2 {void add();void sub();}
Java8内置接口
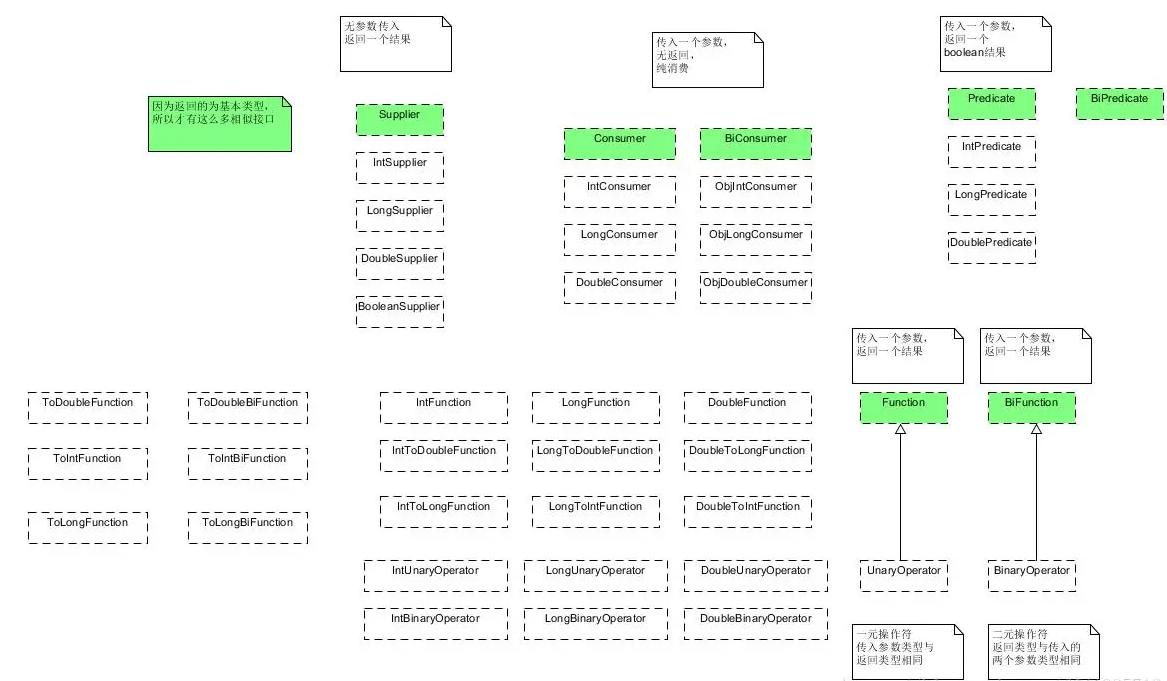
Consumer(消费型)
接受一个输入参数并且无返回的操作;因为没有出参,常⽤于打印、发送短信等消费动作
@FunctionalInterfacepublic interface Consumer<T> {void accept(T t);/*** 执行完再走一个消费型函数accept方法*/default Consumer<T> andThen(Consumer<? super T> after) {Objects.requireNonNull(after);return (T t) -> { accept(t); after.accept(t); };}}
其他Consumer扩展接口:
- BiConsumer:void accept(T t, U u);接受两个参数
- DoubleConsumer:void accept(double value);接受一个double参数
- IntConsumer:void accept(int value);接受一个int参数
- LongConsumer:void accept(long value);接受一个long参数
- ObjDoubleConsumer:void accept(T t, double value);接受一个泛型参数一个double参数
- ObjIntConsumer:void accept(T t, int value);接受一个泛型参数一个int参数
- ObjLongConsumer:void accept(T t, long value);接受一个泛型参数一个long参数
测试demo
public class TestConsumer{public static void main(String[] args) {// Consumer 接收一个参数,不返回Consumer<String> c = System.out::println;c.accept("函数式接口:Consumer");//做完本次后再继续执行一个Consumer<String> count = x -> System.out.println((Integer.parseInt(x) + 1) + "");count.andThen(c).accept("5");//定义一个方法使用consumer作为参数sendmessage("iphone13", x -> System.out.println(x + "发送短信"));}public static void sendmessage(String phone, Consumer<String> consumer) {consumer.accept(phone);}}
Supplier(供给型)
无入参 有返回值 泛型⼀定和⽅法的返回值类型是⼀种类型,如果需要获得⼀个数据,并且不需要传⼊参数,可以使⽤Supplier接⼝,例如 ⽆参的⼯⼚⽅法,即⼯⼚设计模式创建对象,简单来说就是 提供者
@FunctionalInterfacepublic interface Supplier<T> {/*** Gets a result.** @return a result*/T get();}
其他Supplier扩展接口:
- BooleanSupplier:boolean getAsBoolean();返回boolean
- DoubleSupplier:double getAsDouble();返回double
- IntSupplier:int getAsInt();返回int
- LongSupplier:long getAsLong();返回long
测试demo
public class TestSupplier{public static void main(String[] args) {//自定义Supplier<Integer> supplier = () -> new Random().nextInt();System.out.println(supplier.get());System.out.println("********************");//方法引用Supplier<Double> supplier2 = Math::random;System.out.println(supplier2.get());//类似工厂创建一个对象Supplier<String> supplier3 = () -> "5";System.out.println(supplier3.get());}}
Predicate(断言型)
断⾔型接⼝:有⼊参,有返回值,返回值类型确定是boolean,接收⼀个参数,⽤于判断是否满⾜⼀定的条件,过滤数据
@FunctionalInterfacepublic interface Predicate<T> {/*** Evaluates this predicate on the given argument.(断言)*/boolean test(T t);/*** 当前断言 与other断言进行 && 判断*/default Predicate<T> and(Predicate<? super T> other) {Objects.requireNonNull(other);return (t) -> test(t) && other.test(t);}/*** 当前断言取非*/default Predicate<T> negate() {return (t) -> !test(t);}/*** 当前断言取或*/default Predicate<T> or(Predicate<? super T> other) {Objects.requireNonNull(other);return (t) -> test(t) || other.test(t);}/*** targetRef为空的情况 会降级成校验T是否为空,不为空的情况下判断是否相等*/static <T> Predicate<T> isEqual(Object targetRef) {return (null == targetRef)? Objects::isNull: object -> targetRef.equals(object);}}
其他Predicate扩展接口:
- BiPredicate:boolean test(T t, U u);接受两个参数的,判断返回bool
- DoublePredicate:boolean test(double value);入参为double的谓词函数
- IntPredicate:boolean test(int value);入参为int的谓词函数
- LongPredicate:boolean test(long value);入参为long的谓词函数
测试demo
public class TestPredicate{public static void main(String[] args) {Predicate<Integer> predicate = (t) -> t > 5;System.out.println(predicate.test(1));//判断是否为空Objects 1.8新工具用来判空,判相等 等操作Predicate<String> p = Objects::isNull;System.out.println(p.test(""));TestPredicate testPredicate = new TestPredicate();//1.判断传入的字符串的长度是否大于5System.out.println(testPredicate.judgeConditionByFunction(12345, value -> String.valueOf(value).length() > 5));//2.判断传入的参数是否是奇数System.out.println(testPredicate.judgeConditionByFunction(4, value -> value % 2 == 0));//3.判断数字是否大于10System.out.println(testPredicate.judgeConditionByFunction(-1, value -> value > 10));//4.且断言System.out.println(testPredicate.testAndMethod("zhangsan", stringOne -> stringOne.equals("zhangsan"),stringTwo -> stringTwo.length() > 5));//5.测试isEqualsSystem.out.println(testPredicate.testMethodIsEquals("zhangsan", "zhangsan"));System.out.println("~~~ ~~~ ~~~ ~~~");System.out.println(testPredicate.testMethodIsEquals("zhangsan", "lisi"));System.out.println("~~~ ~~~ ~~~ ~~~");System.out.println(testPredicate.testMethodIsEquals(null, "zhangsan"));}public boolean judgeConditionByFunction(int value, Predicate<Integer> predicate) {return predicate.test(value);}/**** @param stringOne 待判断的字符串* @param predicateOne 断定表达式1* @param predicateTwo 断定表达式2* @return 是否满足两个条件*/public boolean testAndMethod(String stringOne, Predicate<String> predicateOne, Predicate<String> predicateTwo) {return predicateOne.and(predicateTwo).test(stringOne);}public boolean testMethodIsEquals(String strValue, String strValue2) {return Predicate.isEqual(strValue).test(strValue2);}}
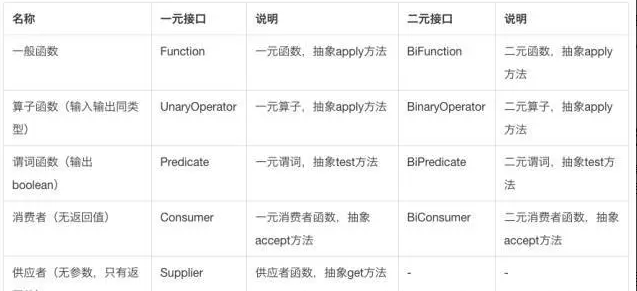
Function(功能型)
Function 接口是一个功能型接口,它的一个作用就是转换作用,将输入数据转换成另一种形式的输出数据。
/*** 代表这一个方法,能够接受参数,并且返回一个结果* @since 1.8*/@FunctionalInterfacepublic interface Function<T, R> {/*** 将参数赋予给相应方法** @param t* @return*/R apply(T t);/*** 先执行参数(即也是一个Function)的,再执行调用者(同样是一个Function)*/default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {Objects.requireNonNull(before);return (V v) -> apply(before.apply(v));}/*** 先执行调用者,再执行参数,和compose相反。*/default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {Objects.requireNonNull(after);return (T t) -> after.apply(apply(t));}/*** 返回当前正在执行的方法(输出自己,等于什么都不做,主要封装t -> t这种写法,部分场景并不能直接使用identity)*/static <T> Function<T, T> identity() {return t -> t;}}
Function相关扩展接口:
- BiFunction :R apply(T t, U u);接受两个参数,返回一个值,代表一个二元函数;
- DoubleFunction :R apply(double value);只处理double类型的一元函数;
- ToDoubleFunction:double applyAsDouble(T value);返回double的一元函数;
- ToDoubleBiFunction:double applyAsDouble(T t, U u);返回double的二元函数;
- IntToLongFunction:long applyAsLong(int value);接受int返回long的一元函数;
测试demo
public class TestFunction{public static void main(String[] args) {Function<Integer, Integer> times2 = i -> i * 2;Function<Integer, Integer> squared = i -> i * i;System.out.println(times2.apply(4));System.out.println(squared.apply(4));//32 先4×4然后16×2,先执行apply(4),在times2的apply(16),先执行参数,再执行调用者。System.out.println(times2.compose(squared).apply(4));//64 先4×2,然后8×8,先执行times2的函数,在执行squared的函数。System.out.println(times2.andThen(squared).apply(4));//16System.out.println(Function.identity().compose(squared).apply(4));}}
UnaryOperator(一元算子)
@FunctionalInterfacepublic interface UnaryOperator<T> extends Function<T, T> {/*** 同function*/static <T> UnaryOperator<T> identity() {return t -> t;}}
BinaryOperator(二元算子)
@FunctionalInterfacepublic interface BinaryOperator<T> extends BiFunction<T,T,T> {/*** 传入比较器,主要不要传反*/public static <T> BinaryOperator<T> minBy(Comparator<? super T> comparator) {Objects.requireNonNull(comparator);return (a, b) -> comparator.compare(a, b) <= 0 ? a : b;}/*** 传入比较器,主要不要传反*/public static <T> BinaryOperator<T> maxBy(Comparator<? super T> comparator) {Objects.requireNonNull(comparator);return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;}}
其他的Operator接口:
- LongUnaryOperator:long applyAsLong(long operand);
- LongBinaryOperator:long applyAsLong(long left, long right);
- …
测试demo
public class TestOperator{public static void main(String[] args) {UnaryOperator<Integer> unaryOperator = x -> x + 10;BinaryOperator<Integer> binaryOperator = (x, y) -> x + y;//20System.out.println(unaryOperator.apply(10));//15System.out.println(binaryOperator.apply(5, 10));//继续看看BinaryOperator提供的两个静态方法 也挺好用的BinaryOperator<Integer> min = BinaryOperator.minBy(Integer::compare);BinaryOperator<Integer> max = BinaryOperator.maxBy(Integer::compareTo);//10System.out.println(min.apply(10, 20));//20System.out.println(max.apply(10, 20));}}
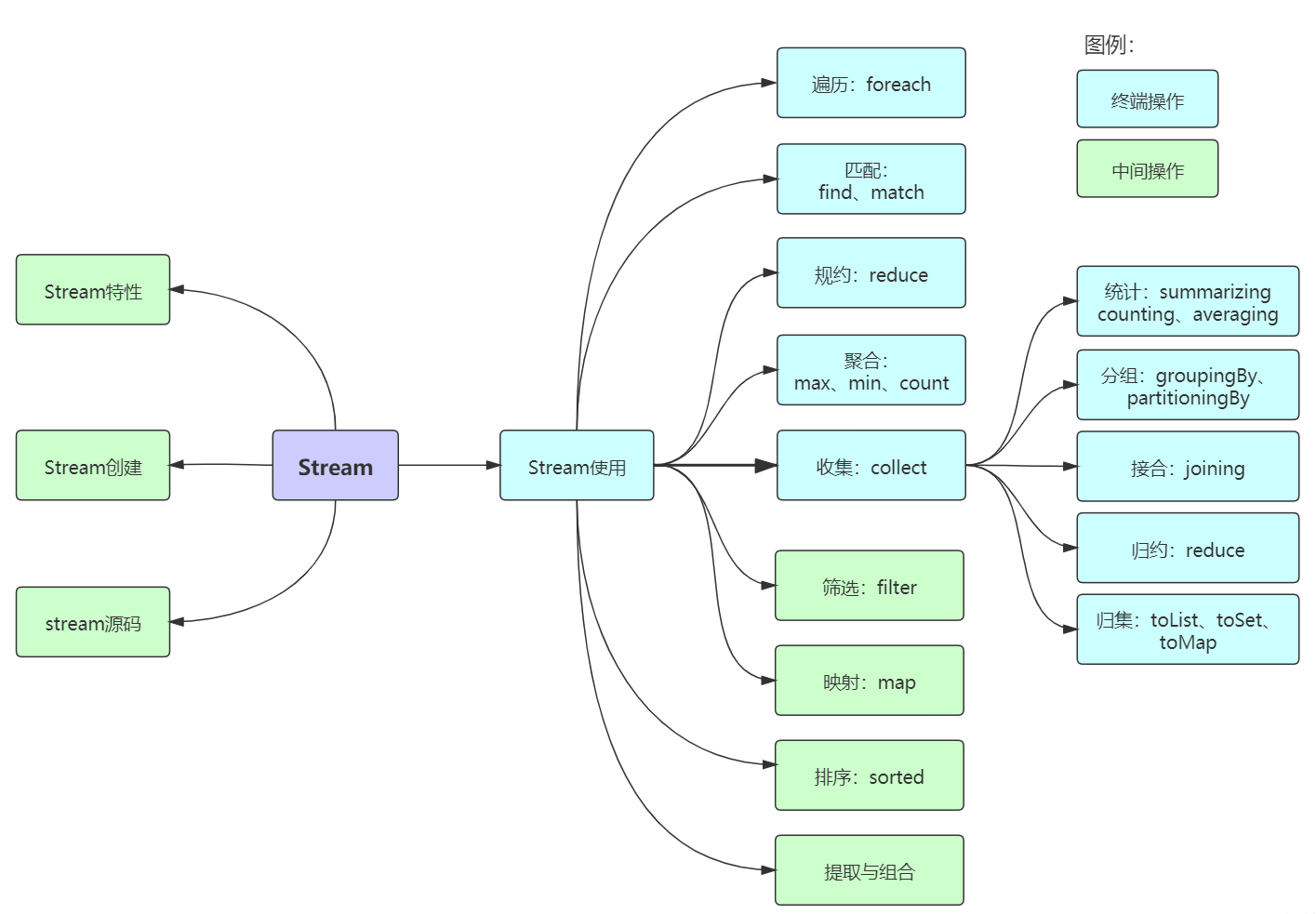
Stream
Java8中的Stream是对容器对象功能的增强,它专注于对容器对象进行各种非常便利、高效的 聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API借助于同样新出现的Lambda表达式,极大的提高编程效率和程序可读性。同时,它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用fork/join并行方式来拆分任务和加速处理过程
stream流的构成
当我们使用一个流的时候,通常包括三个基本步骤:获取一个数据源(source)→ 数据转换 → 执行操作获取想要的结果。每次转换原有Stream对象不改变,返回一个新的Stream对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道
Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等
Stream可以由数组或集合创建,对流的操作分为两种:
- 中间操作,每次返回一个新的流,可以有多个。
- 终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值。
另外,Stream有几个特性:
- stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
- stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
- stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
stream流的创建
直接看代码
public class TestCreate{public static void main(String[] args) {String[] dd = {"a", "b", "c" };//1.使用java.util.Arrays.stream(T[] array)方法用数组创建流Arrays.stream(dd).forEach(System.out::print);System.out.println();//2.通过Stream的of静态方法,传入一个泛型数组,或者多个参数,创建一个流Stream.of(dd).forEach(System.out::print);System.out.println();//3.通过 java.util.Collection.stream() 方法用集合创建流// 使用这个方法,包括继承Collection的接口,如:Set,List,Map,SortedSet 等等,详细的,可以看Collection接口上的定义注释Arrays.asList(dd).stream().forEach(System.out::print);// 创建一个并行流Arrays.asList(dd).parallelStream().forEach(System.out::print);System.out.println();//4.使用Stream的静态方法:iterate()、generate(),生成的是无限流,需要配合limit使用Stream.iterate(0, x -> x + 1).limit(10).forEach(System.out::print);System.out.println();Stream.generate(() -> "x").limit(10).forEach(System.out::print);System.out.println();//5.从BufferedReader获得BufferedReader bufferedReader = new BufferedReader(new StringReader("123456"));System.out.println(bufferedReader.lines().count());//6.静态工厂 IntStream.range, Files.walkIntStream.range(6, 10).forEach(System.out::print);System.out.println();try (Stream<Path> walk = Files.walk(Paths.get("E:\\vscode"))) {List<String> result = walk.filter(Files::isRegularFile).map(Path::toString).collect(Collectors.toList());result.forEach(System.out::println);}catch (IOException e) {e.printStackTrace();}System.out.println();//7.Spliterator,接口,示例比较复杂,可专门研究//8.其他random.ints()、BitSet.stream()、Pattern.splitAsStream、JarFile.stream()new Random().ints(0, 100).limit(10).forEach(System.out::println);}}
stream流的操作类型
- Intermediate:一个流可以后面跟随零个或多个intermediate操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
- Terminal:一个流只能有一个terminal操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以,这必定是流的最后一个操作。Terminal操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个side effect
转换操作都是lazy的,多个转换操作只会在Terminal操作的时候融合起来,一次循环完成。我们可以这样简单的理解,Stream里有个操作函数的集合,每次转换操作就是把转换函数放入这个集合中,在Terminal 操作的时候循环Stream对应的集合,然后对每个元素执行所有的函数。此操作被称为short-circuiting
stream流的使用
- Intermediate 操作map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
- Terminal 操作forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
- Short-circuiting 操作anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
遍历/匹配(foreach/find/match)
Stream也是支持类似集合的遍历和匹配元素的,只是Stream中的元素是以Optional类型存在的。Stream的遍历、匹配非常简单。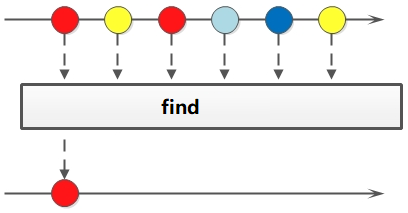
//以下所有PersonList均复用此public static List<Person> personList;static {personList = new ArrayList<Person>();personList.add(new Person("Tom", 8900, 19, "male", "New York"));personList.add(new Person("Jack", 7000, 23, "male", "Washington"));personList.add(new Person("Lily", 7800, 45, "female", "Washington"));personList.add(new Person("Anni", 8200, 32, "female", "New York"));personList.add(new Person("Owen", 9500, 11, "male", "New York"));personList.add(new Person("Alisa", 7900, 8, "female", "New York"));}public static void main(String[] args) {List<Integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);// 遍历输出符合条件的元素list.stream().filter(x -> x > 6).forEach(System.out::println);// 匹配第一个Optional<Integer> findFirst = list.stream().filter(x -> x > 6).findFirst();// 匹配任意(适用于并行流)Optional<Integer> findAny = list.parallelStream().filter(x -> x > 6).findAny();// 是否包含符合特定条件的元素boolean anyMatch = list.stream().anyMatch(x -> x > 6);System.out.println("匹配第一个值:" + findFirst.get());System.out.println("匹配任意一个值:" + findAny.get());System.out.println("是否存在大于6的值:" + anyMatch);}
match方法
Stream有三个match方法,从语义上说:
(1).allMatch:Stream 中全部元素符合传入的 predicate,返回 true;
(2).anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true;
(3).noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true.
它们都不是要遍历全部元素才能返回结果。例如allMatch只要一个元素不满足条件,就skip剩下的所有元素,返回false。对清单13中的Person类稍做修改,加入一个age属性和getAge方法
// 使用 MatchList<Person> persons = new ArrayList();persons.add(new Person(1, "name" + 1, 10));persons.add(new Person(2, "name" + 2, 21));persons.add(new Person(3, "name" + 3, 34));persons.add(new Person(4, "name" + 4, 6));persons.add(new Person(5, "name" + 5, 55));boolean isAllAdult = persons.stream().allMatch(p -> p.getAge() > 18);System.out.println("All are adult? " + isAllAdult);boolean isThereAnyChild = persons.stream().anyMatch(p -> p.getAge() < 12);System.out.println("Any child? " + isThereAnyChild);输出结果:All are adult? falseAny child? true
筛选(filter)
筛选,是按照一定的规则校验流中的元素,将符合条件的元素提取到新的流中的操作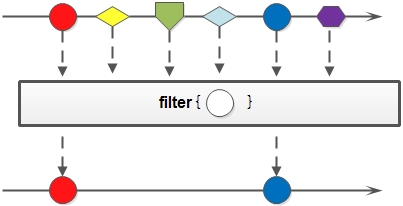
//筛选出Integer集合中大于7的元素,并打印出来list.stream().filter(x -> x > 7).forEach(System.out::println);//筛选员工中工资高于8000的人,并形成新的集合List<String> fiterList = personList.stream().filter(x -> x.getSalary() > 8000).map(Person::getName).collect(Collectors.toList());System.out.print("高于8000的员工姓名:" + fiterList);
聚合(max/min/count)
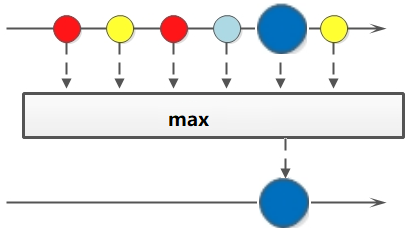
//获取String集合中最长的元素List<String> strList = Arrays.asList("adnm", "admmt", "pot", "xbangd", "weoujgsd");Optional<String> strMax = strList.stream().max(Comparator.comparing(String::length));System.out.println("最长的字符串:" + strMax.get());//获取Integer集合中的最大值// 自然排序Optional<Integer> max = list.stream().max(Integer::compareTo);// 自定义排序Optional<Integer> max2 = list.stream().max(new Comparator<Integer>(){@Overridepublic int compare(Integer o1, Integer o2) {return o1.compareTo(o2);}});System.out.println("自然排序的最大值:" + max.get());System.out.println("自定义排序的最大值:" + max2.get());//获取员工工资最高的人Optional<Person> maxSalary = personList.stream().max(Comparator.comparingInt(Person::getSalary));System.out.println("员工工资最大值:" + maxSalary.get().getSalary());//计算Integer集合中大于6的元素的个数long count = list.stream().filter(x -> x > 6).count();System.out.println("list中大于6的元素个数:" + count);
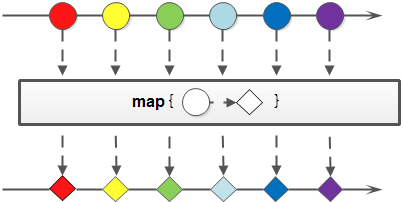
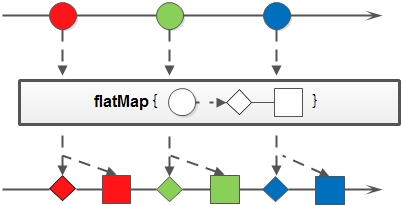
映射(map/flatMap)
映射,可以将一个流的元素按照一定的映射规则映射到另一个流中。分为map和flatMap:
- map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
- flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
//将员工的薪资全部增加10000// 不改变原来员工集合的方式(map内部新对象进行处理,旧的不受影响了)List<Person> personListNew = personList.stream().map(person -> {Person personNew = new Person(person.getName(), 0, 0, null, null);personNew.setSalary(person.getSalary() + 10000);return personNew;}).collect(Collectors.toList());System.out.println("一次改动前:" + personList.get(0).getName() + "-->" + personList.get(0).getSalary());System.out.println("一次改动后:" + personListNew.get(0).getName() + "-->" + personListNew.get(0).getSalary());// 改变原来员工集合的方式List<Person> personListNew2 = personList.stream().map(person -> {person.setSalary(person.getSalary() + 10000);return person;}).collect(Collectors.toList());System.out.println("二次改动前:" + personList.get(0).getName() + "-->" + personListNew.get(0).getSalary());System.out.println("二次改动后:" + personListNew2.get(0).getName() + "-->" + personListNew.get(0).getSalary());
将两个字符数组合并成一个新的字符数组
public class StreamTest {public static void main(String[] args) {List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7");List<String> listNew = list.stream().flatMap(s -> {// 将每个元素转换成一个streamString[] split = s.split(",");Stream<String> s2 = Arrays.stream(split);return s2;}).collect(Collectors.toList());System.out.println("处理前的集合:" + list);System.out.println("处理后的集合:" + listNew);}}
flatMap()的作用就是将多个集合(List)合并成一个大集合处理
String[] strs = { "aaa", "bbb", "ccc" };Arrays.stream(strs).map(str -> str.split("")).forEach(System.out::println);// Ljava.lang.String;@53d8d10aArrays.stream(strs).map(str -> str.split("")).flatMap(Arrays::stream).forEach(System.out::println);// aaabbbcccArrays.stream(strs).map(str -> str.split("")).flatMap(str -> Arrays.stream(str)).forEach(System.out::println);// aaabbbccc
peek(debug用途)
peek和map的区别
Stream<T> peek(Consumer<? super T> action)<R> Stream<R> map(Function<? super T, ? extends R> mapper);
peek接收一个Consumer,而map接收一个Function。
Consumer是没有返回值的,它只是对Stream中的元素进行某些操作,但是操作之后的数据并不返回到Stream中,所以Stream中的元素还是原来的元素。
而Function是有返回值的,这意味着对于Stream的元素的所有操作都会作为新的结果返回到Stream中。
这就是为什么peek String不会发生变化而peek Object会发送变化的原因
// 改变原来员工集合的方式(改写为Peek方式)List<Person> personListNew2 = personList.stream().peek(person -> person.setSalary(person.getSalary() + 10000)).collect(Collectors.toList());System.out.println("二次改动前:" + personList.get(0).getName() + "-->" + personListNew.get(0).getSalary());System.out.println("二次改动后:" + personListNew2.get(0).getName() + "-->" + personListNew.get(0).getSalary());
归约(reduce)
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作

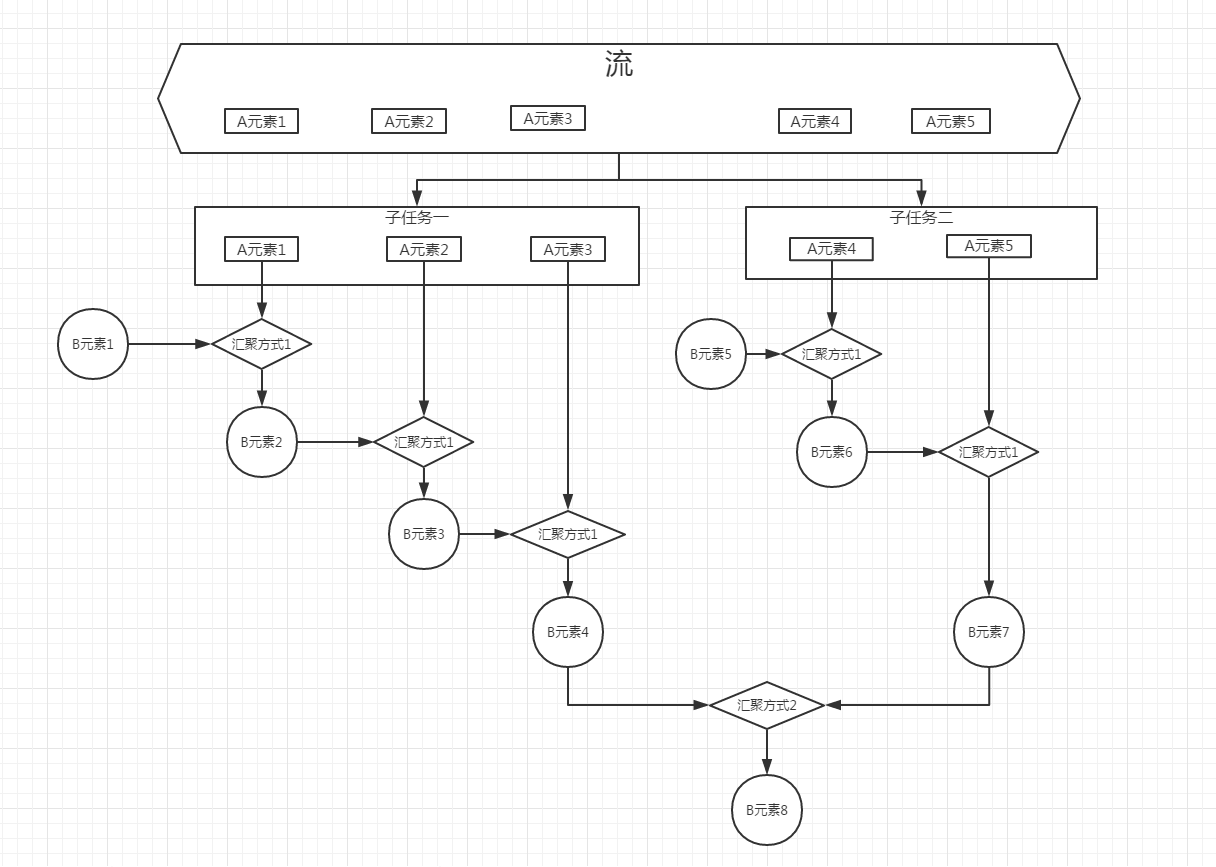
结合草图,要实现stream.reduce()方法,必须要告诉JDK
- 你有什么需求数据要汇聚?(Stream已经提供了数据源,对应上面草图的A元素)
- 最后要汇聚成怎样的一个数据类型(对应reduce方法的参数一,对应上面草图的B元素)
- 如何将需求数据处理或转化成一个汇聚数据(对应reduce方法的参数二,对应上面草图的汇聚方式1)
- 如何将多个汇聚数据进行合并(对应reduce方法的参数三,对应上面草图的汇聚方式2)
再结合你给的map方法,其实是要把I类数据的流,最后转化为一个O类数据的List,因此按照上面的步骤可以进行对照
- 你有什么需求数据要汇聚?(I类数据流)
- 最后要汇聚成怎样的一个数据类型(一个集合,new ArrayList())
- 如何将需求数据处理或转化成一个汇聚数据(根据mapper把I转化为O,再用List.add方法)
- 如何将多个汇聚数据进行合并(两个集合合并,用List.addAll())
public static void main(String[] args) {List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4);// 求和方式1Optional<Integer> sum = list.stream().reduce((x, y) -> x + y);// 求和方式2Optional<Integer> sum2 = list.stream().reduce(Integer::sum);// 求和方式3Integer sum3 = list.stream().reduce(0, Integer::sum);// 求乘积Optional<Integer> product = list.stream().reduce((x, y) -> x * y);// 求最大值方式1Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y);// 求最大值写法2Integer max2 = list.stream().reduce(1, Integer::max);System.out.println("list求和:" + sum.get() + "," + sum2.get() + "," + sum3);System.out.println("list求积:" + product.get());System.out.println("list求和:" + max.get() + "," + max2);// 求工资之和方式1:Optional<Integer> sumSalary = personList.stream().map(Person::getSalary).reduce(Integer::sum);// 求工资之和方式2:Integer sumSalary2 = personList.stream().reduce(0, (sumSal, p) -> sumSal += p.getSalary(),(sumSal1, sumSal2) -> sumSal1 + sumSal2);// 求工资之和方式3:Integer sumSalary3 = personList.stream().reduce(0, (sumSal, p) -> sumSal += p.getSalary(), Integer::sum);// 求最高工资方式1:Integer maxSalary = personList.stream().reduce(0,(maxSal, p) -> maxSal > p.getSalary() ? maxSal : p.getSalary(), Integer::max);// 求最高工资方式2:Integer maxSalary2 = personList.stream().reduce(0,(maxSal, p) -> maxSal > p.getSalary() ? maxSal : p.getSalary(),(maxSal1, maxSal2) -> maxSal1 > maxSal2 ? maxSal1 : maxSal2);System.out.println("工资之和:" + sumSalary.get() + "," + sumSalary2 + "," + sumSalary3);System.out.println("最高工资:" + maxSalary + "," + maxSalary2);}
reduce方法有三个重载的方法
Optional<T> reduce(BinaryOperator<T> accumulator);T reduce(T identity, BinaryOperator<T> accumulator);<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
第三种签名的用法相较前两种稍显复杂,由于前两种实现有一个缺陷,它们的计算结果必须和stream中的元素类型相同。
分析下它的三个参数:
identity: 一个初始化的值;这个初始化的值其类型是泛型U,与Reduce方法返回的类型一致;注意此时Stream中元素的类型是T,与U可以不一样也可以一样,这样的话操作空间就大了;不管Stream中存储的元素是什么类型,U都可以是任何类型,如U可以是一些基本数据类型的包装类型Integer、Long等;或者是String,又或者是一些集合类型ArrayList等;后面会说到这些用法。
accumulator: 其类型是BiFunction,输入是U与T两个类型的数据,而返回的是U类型;也就是说返回的类型与输入的第一个参数类型是一样的,而输入的第二个参数类型与Stream中元素类型是一样的。
combiner: 其类型是BinaryOperator,支持的是对U类型的对象进行操作;
第三个参数combiner主要是使用在并行计算的场景下;如果Stream是非并行时,第三个参数实际上是不生效的。
因此针对这个方法的分析需要分并行与非并行两个场景。
比如我们要对一个一系列int值求和,但是求和的结果用一个int类型已经放不下,必须升级为long类型,此实第三签名就能发挥价值了,它不将执行结果与stream中元素的类型绑死。
List<Integer> numList = Arrays.asList(Integer.MAX_VALUE,Integer.MAX_VALUE);long result = numList.stream().reduce(0L,(a,b) -> a + b, (a,b)-> 0L );System.out.println(result);
再比如将一个int类型的ArrayList转换成一个String类型的ArrayList
List<Integer> numList = Arrays.asList(1, 2, 3, 4, 5, 6);ArrayList<String> result = numList.stream().reduce(new ArrayList<String>(), (a, b) -> {a.add("element-" + Integer.toString(b));return a;}, (a, b) -> null);System.out.println(result);
收集(collect)
collect,收集,可以说是内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。
collect主要依赖java.util.stream.Collectors类内置的静态方法。
collector部分方法与stream重合了,优先使用stream中的
Collector是专门用来作为Stream的collect方法的参数的
public interface Stream<T> extends BaseStream<T, Stream<T>> {<R, A> R collect(Collector<? super T, A, R> collector);}
Collector主要包含五个参数,它的行为也是由这五个参数来定义的,如下所示
public interface Collector<T, A, R> {// supplier参数用于生成结果容器,容器类型为ASupplier<A> supplier();// accumulator用于消费元素,也就是归纳元素,这里的T就是元素,它会将流中的元素一个一个与结果容器A发生操作BiConsumer<A, T> accumulator();// combiner用于两个两个合并并行执行的线程的执行结果,将其合并为一个最终结果ABinaryOperator<A> combiner();// finisher用于将之前整合完的结果R转换成为AFunction<A, R> finisher();// characteristics表示当前Collector的特征值,这是个不可变SetSet<Characteristics> characteristics();}
Collector拥有两个of方法用于生成Collector实例,其中一个拥有上面所有五个参数,另一个四个参数,不包括finisher。
public interface Collector<T, A, R> {// 四参方法,用于生成一个Collector,T代表流中的一个一个元素,R代表最终的结果public static<T, R> Collector<T, R, R> of(Supplier<R> supplier,BiConsumer<R, T> accumulator,BinaryOperator<R> combiner,Characteristics... characteristics) {/*...*/}// 五参方法,用于生成一个Collector,T代表流中的一个一个元素,A代表中间结果,R代表最终结果,finisher用于将A转换为Rpublic static<T, A, R> Collector<T, A, R> of(Supplier<A> supplier,BiConsumer<A, T> accumulator,BinaryOperator<A> combiner,Function<A, R> finisher,Characteristics... characteristics) {/*...*/}}
Characteristics:这个特征值是一个枚举,拥有三个值:CONCURRENT(多线程并行),UNORDERED(无序),IDENTITY_FINISH(无需转换结果)。其中四参of方法中没有finisher参数,所以必有IDENTITY_FINISH特征值。
归集(toList/toSet/toMap)
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法
public static void main(String[] args) {List<Integer> list = Arrays.asList(1, 6, 3, 4, 6, 7, 9, 6, 20);//toList默认为ArrayListList<Integer> listNew = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toList());//toSet默认为HashSetSet<Integer> set = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toSet());Map<?, Person> map = personList.stream().filter(p -> p.getSalary() > 8000).collect(Collectors.toMap(Person::getName, p -> p));System.out.println("toList:" + listNew);System.out.println("toSet:" + set);System.out.println("toMap:" + map);LinkedList<Integer> linkedList = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toCollection(LinkedList::new));System.out.println("tolinkedList:" + linkedList);Map<?, Person> currentMap = personList.stream().filter(p -> p.getSalary() > 8000).collect(Collectors.toConcurrentMap(Person::getName, p -> p));System.out.println("tocurrentMap:" + currentMap);}
toMap 重载
toMap方法是根据给定的键生成器和值生成器生成的键和值保存到一个map中返回,键和值的生成都依赖于元素,可以指定出现重复键时的处理方案和保存结果的map
public final class Collectors {// 指定键和值的生成方式keyMapper和valueMapperpublic static <T, K, U>Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,Function<? super T, ? extends U> valueMapper) {/*...*/}// 在上面方法的基础上增加了对键发生重复时处理方式的mergeFunction,比如上面的默认的处理方法就是抛出异常public static <T, K, U>Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,Function<? super T, ? extends U> valueMapper,BinaryOperator<U> mergeFunction) {/*...*/}// 在第二个方法的基础上再添加了结果Map的生成方法。public static <T, K, U, M extends Map<K, U>>Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,Function<? super T, ? extends U> valueMapper,BinaryOperator<U> mergeFunction,Supplier<M> mapSupplier) {/*...*/}}
toMap实例
public class CollectorsTest {public static void toMapTest(List<String> list){Map<String,String> map = list.stream().limit(3).collect(Collectors.toMap(e -> e.substring(0,1),e -> e));Map<String,String> map1 = list.stream().collect(Collectors.toMap(e -> e.substring(0,1),e->e,(a,b)-> b));Map<String,String> map2 = list.stream().collect(Collectors.toMap(e -> e.substring(0,1),e->e,(a,b)-> b,HashMap::new));System.out.println(map.toString() + "\n" + map1.toString() + "\n" + map2.toString());}public static void main(String[] args) {List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");toMapTest(list);}}
统计(count/averaging)
Collectors提供了一系列用于数据统计的静态方法:
计数:count
平均值:averagingInt、averagingLong、averagingDouble
最值:maxBy、minBy
求和:summingInt、summingLong、summingDouble
统计以上所有:summarizingInt、summarizingLong、summarizingDouble
public static void main(String[] args) {// 求总数(但没有这样的用法,直接personList.size)Long count1 = personList.stream().collect(Collectors.counting());Long count2 = personList.stream().count();// 求平均工资Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));// 求最高工资Optional<Integer> max1 = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));Optional<Integer> max2 = personList.stream().map(Person::getSalary).max(Integer::compare);// 求工资之和//summing**生成一个用于求元素和的Collector,首先通过给定的mapper将元素转换类型,然后再求和Integer sum1 = personList.stream().collect(Collectors.summingInt(Person::getSalary));Integer sum2 = personList.stream().mapToInt(Person::getSalary).sum();// 一次性统计所有信息DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));System.out.println("员工总数:" + count1 + "," + count2);System.out.println("员工平均工资:" + average);System.out.println("员工最高工资:" + max1.get() + "," + max2.get());System.out.println("员工工资总和:" + sum1 + "," + sum2);System.out.println("员工工资所有统计:" + collect);}
分组(partitioningBy/groupingBy)
- 分区:将stream按条件分为两个Map,比如员工按薪资是否高于8000分为两部分。
- 分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。
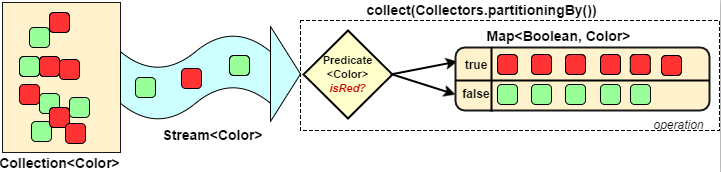
public static void main(String[] args) {// 将员工按薪资是否高于8000分组Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));// 将员工按性别分组Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));// 将员工先按性别分组,再按地区分组Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));System.out.println("员工按薪资是否大于8000分组情况:" + part);System.out.println("员工按性别分组情况:" + group);System.out.println("员工按性别、地区:" + group2);}
partitioningBy 重载
该方法将流中的元素按照给定的校验规则的结果分为两个部分,放到一个map中返回,map的键是Boolean类型,值为元素的列表List
public final class Collectors {// 只需一个校验参数predicatepublic static <T>Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {/*...*/}// 在上面方法的基础上增加了对流中元素的处理方式的Collector,比如上面的默认的处理方法就是Collectors.toList()public static <T, D, A>Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate,Collector<? super T, A, D> downstream) {/*...*/}}
partitioningBy实例
public class CollectorsTest {public static void partitioningByTest(List<String> list){Map<Boolean,List<String>> map = list.stream().collect(Collectors.partitioningBy(e -> e.length()>5));Map<Boolean,Set<String>> map2 = list.stream().collect(Collectors.partitioningBy(e -> e.length()>6,Collectors.toSet()));System.out.println(map.toString() + "\n" + map2.toString());}public static void main(String[] args) {List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");partitioningByTest(list);}}
groupingby重载
public final class Collectors {// 只需一个分组参数classifier,内部自动将结果保存到一个map中,每个map的键为?类型(即classifier的结果类型),值为一个list,这个list中保存在属于这个组的元素。public static <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function<? super T, ? extends K> classifier) {/*...*/}// 在上面方法的基础上增加了对流中元素的处理方式的Collector,比如上面的默认的处理方法就是Collectors.toList()public static <T, K, A, D>Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,Collector<? super T, A, D> downstream) {/*...*/}// 在第二个方法的基础上再添加了结果Map的生成方法。public static <T, K, D, A, M extends Map<K, D>>Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,Supplier<M> mapFactory,Collector<? super T, A, D> downstream) {/*...*/}}
groupingby实例
public class CollectorsTest {public static void groupingByTest(List<String> list){Map<Integer,List<String>> s = list.stream().collect(Collectors.groupingBy(String::length));Map<Integer,List<String>> ss = list.stream().collect(Collectors.groupingBy(String::length, Collectors.toList()));Map<Integer,Set<String>> sss = list.stream().collect(Collectors.groupingBy(String::length,HashMap::new,Collectors.toSet()));System.out.println(s.toString() + "\n" + ss.toString() + "\n" + sss.toString());}public static void main(String[] args) {List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");groupingByTest(list);}}
接合(joining)
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
public static void main(String[] args) {String names = personList.stream().map(Person::getName).collect(Collectors.joining(","));System.out.println("所有员工的姓名:" + names);List<String> list = Arrays.asList("A", "B", "C");String string = list.stream().collect(Collectors.joining("-"));//可替换为 String string1 = String.join("-", list);System.out.println("拼接后的字符串:" + string);}
归约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
public final class Collectors {// 无初始值的情况,返回一个可以生成Optional结果的Collectorpublic static <T> Collector<T, ?, Optional<T>> reducing(BinaryOperator<T> op) {/*...*/}// 有初始值的情况,返回一个可以直接产生结果的Collectorpublic static <T> Collector<T, ?, T> reducing(T identity, BinaryOperator<T> op) {/*...*/}// 有初始值,还有针对元素的处理方案mapper,生成一个可以直接产生结果的Collector,元素在执行结果操作op之前需要先执行mapper进行元素转换操作public static <T, U> Collector<T, ?, U> reducing(U identity,Function<? super T, ? extends U> mapper,BinaryOperator<U> op) {/*...*/}}
public class CollectorsTest {public static void reducingTest(List<String> list){System.out.println(list.stream().limit(4).map(String::length).collect(Collectors.reducing(Integer::sum)));System.out.println(list.stream().limit(3).map(String::length).collect(Collectors.reducing(0, Integer::sum)));System.out.println(list.stream().limit(4).collect(Collectors.reducing(0,String::length,Integer::sum)));}public static void main(String[] args) {List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");reducingTest(list);}}
public static void main(String[] args) {// 每个员工减去起征点后的薪资之和(这个例子并不严谨,但一时没想到好的例子)Integer sum1 = personList.stream().collect(Collectors.reducing(0, Person::getSalary, (i, j) -> (i + j - 5000)));Integer sum2 = personList.stream().map(Person::getSalary).reduce(0, (i, j) -> (i + j - 5000));System.out.println("员工扣税薪资总和:" + sum1 + "," + sum2);// stream的reduceOptional<Integer> sum3 = personList.stream().map(Person::getSalary).reduce(Integer::sum);System.out.println("员工薪资总和:" + sum3.get());}
排序(sorted)
sorted,中间操作。有两种排序:
- sorted():自然排序,流中元素需实现Comparable接口
- sorted(Comparator com):Comparator排序器自定义排序
public static void main(String[] args) {// 按工资升序排序(自然排序)List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName).collect(Collectors.toList());// 按工资倒序排序List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed()).map(Person::getName).collect(Collectors.toList());// 先按工资再按年龄升序排序List<String> newList3 = personList.stream().sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName).collect(Collectors.toList());// 先按工资再按年龄自定义排序(降序)List<String> newList4 = personList.stream().sorted((p1, p2) -> {if (p1.getSalary() == p2.getSalary()) {return p2.getAge() - p1.getAge();}else {return p2.getSalary() - p1.getSalary();}}).map(Person::getName).collect(Collectors.toList());System.out.println("按工资升序排序:" + newList);System.out.println("按工资降序排序:" + newList2);System.out.println("先按工资再按年龄升序排序:" + newList3);System.out.println("先按工资再按年龄自定义降序排序:" + newList4);}
提取/组合
流也可以进行合并、去重、限制、跳过等操作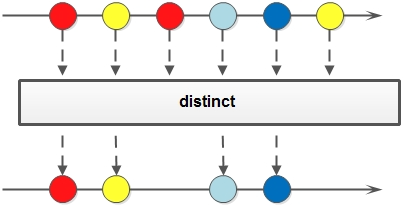
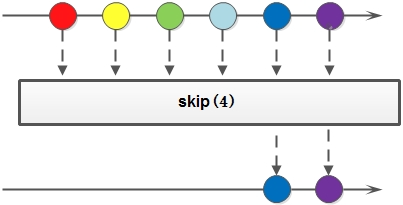
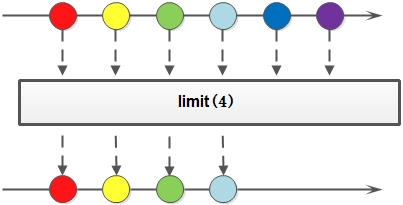
public static void main(String[] args) {String[] arr1 = {"a", "b", "c", "d" };String[] arr2 = {"d", "e", "f", "g" };Stream<String> stream1 = Stream.of(arr1);Stream<String> stream2 = Stream.of(arr2);// concat:合并两个流 distinct:去重List<String> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());// limit:限制从流中获得前n个数据List<Integer> collect = Stream.iterate(1, x -> x + 2).limit(10).collect(Collectors.toList());// skip:跳过前n个数据List<Integer> collect2 = Stream.iterate(1, x -> x + 2).skip(1).limit(5).collect(Collectors.toList());System.out.println("流合并:" + newList);System.out.println("limit:" + collect);System.out.println("skip:" + collect2);}
映射(mapping)
这个映射是首先对流中的每个元素进行映射,即类型转换,然后再将新元素以给定的Collector进行归纳
public class CollectorsTest {public static void mapingTest(List<String> list){List<Integer> ll = list.stream().limit(5).collect(Collectors.mapping(Integer::valueOf,Collectors.toList()));}public static void main(String[] args) {List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");mapingTest(list);}}
实例中截取字符串列表的前5个元素,将其分别转换为Integer类型,然后放到一个List中返回
collect后处理(collectingAndThen)
该方法是在归纳动作结束之后,对归纳的结果进行再处理
public class CollectorsTest {public static void collectingAndThenTest(List<String> list){int length = list.stream().collect(Collectors.collectingAndThen(Collectors.toList(),e -> e.size()));System.out.println(length);}public static void main(String[] args) {List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");collectingAndThenTest(list);}}

若有收获,就点个赞吧
0 人点赞
