前言
自ChatGPT发布以来,全球的注意力都开始聚焦在人工智能领域,各家世界顶级的科技公司近几周纷纷开始入局,为什么一款 AI 聊天工具能在全球带起如此广泛的浪潮?
今天,我将从GPT模型开始来给大家介绍下ChatGPT的的原理,以及为何它在整个人类社会中占领如此重要的地位。
GPT模型的由来
GPT的全称是 Generative Pre-Training Transformer,即生成式预训练模型。早在2017年的时候,谷歌的研究人员Ashish Vaswani等人发布的文章《Attention is all you need》中提到了一个重要的模型:Transformer。该模型可以在词语编码时同步分析文档的信息,此外该模型的矩阵运算可以实现训练并行,可以大大缩短模型训练的时间。而GPT的运作方式正是建立在Transformer模型的基础上被提出来的。
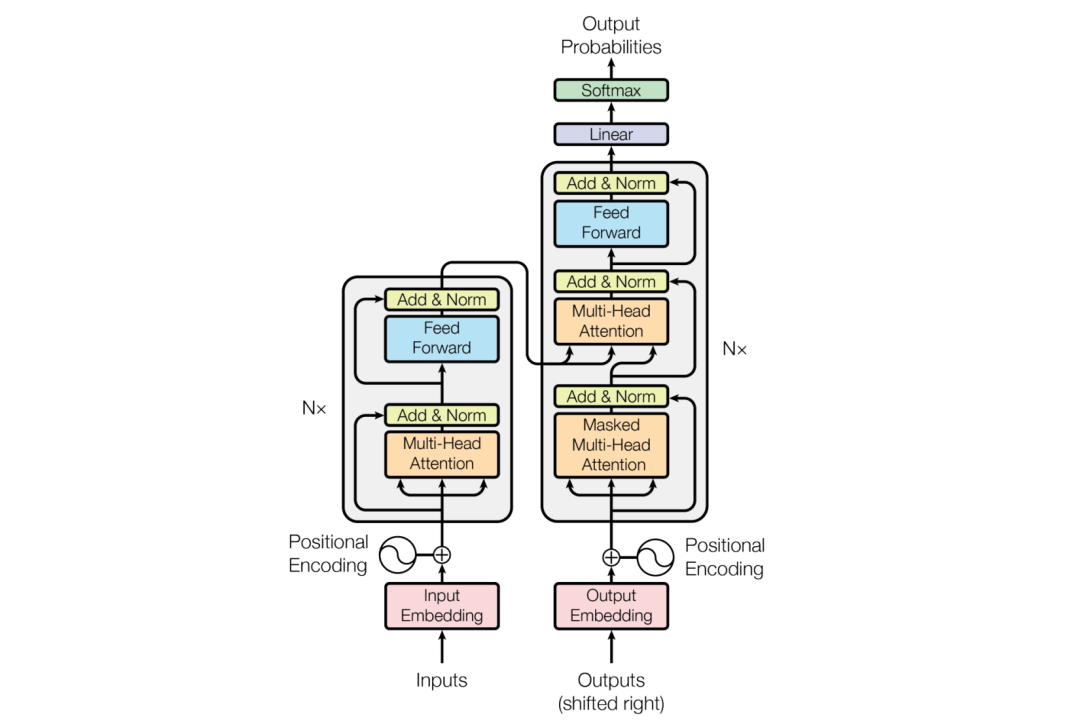
图片来源:文章《Attention is all you need》
GPT听起来是很复杂的算法模型,但其实它的运作原理很简单,就是续写和补齐,我们可以将其理解成【单词接龙】。比如当我们输入“今天”,它能回复“天气很好”;输入“好好学习”,它能回复“天天向上”。而这是单词序列层面的生成方式,那对于大篇幅的长文内容如何处理呢?GPT采用的方式是循环往复的自回归生成:将自己生成的内容和前文结合成“新的上文”,并由此再生成“新的下文”,通过这样的方式就可以接连生成大量的内容。
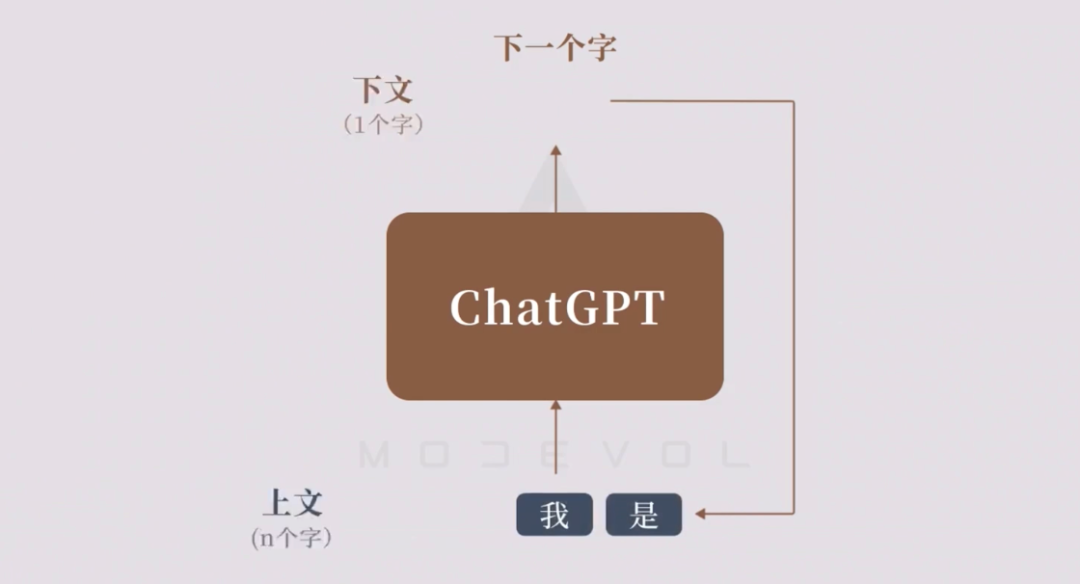
图片来源:《万字科普ChatGPT-4为何会颠覆人类社会》
同一段话,可以通过【单词接龙】续写的内容有很多。如何让GPT可以按照我们想要的结果来生成内容?那就是把提问和最终答案组合成一个完整的“答题范本”提供给 GPT,通过分析提问的内容来匹配生成答案下文。
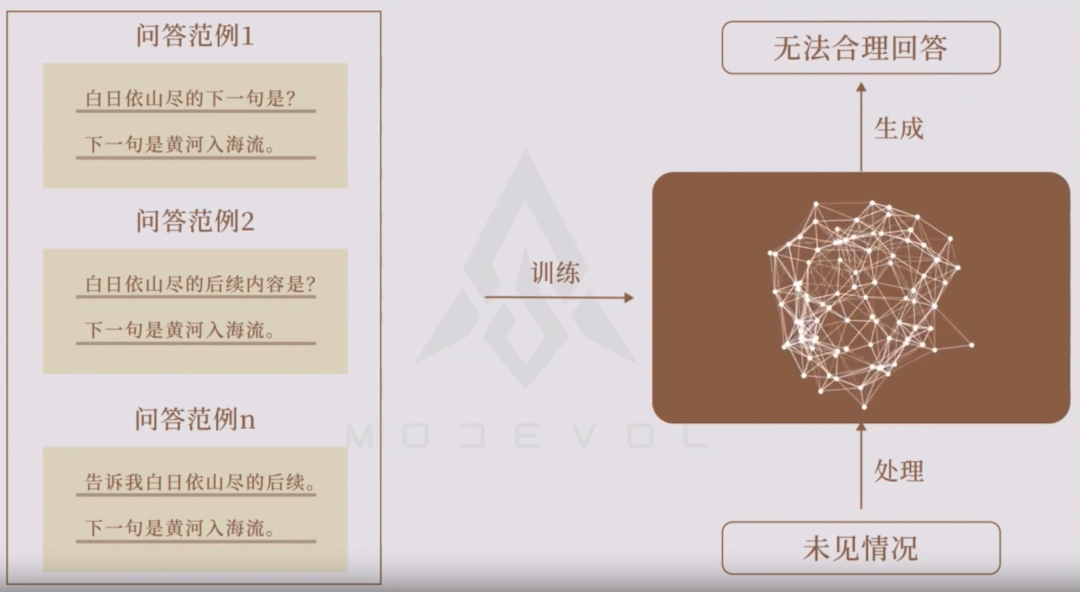
图片来源:《万字科普ChatGPT-4为何会颠覆人类社会》
在我们日常沟通中,同一个意思可以有无数种表达的方式,同一种表达在不同语境下又有不同含义。如果把所有可能的问题和回答都穷举一遍未免太消耗资源,且总会出现被遗漏的情况。为了解决让机器可以正确理解语法语境的问题,开发人员采用了预训练(Pre-Training)的方式来调教 GPT 模型:即提供大量的学习资料来训练 GPT,让模型在大量的数据案例中自行摸索语言规律。
在训练阶段中,最重要是学习数据的参数量。我们可以将参数量理解成大脑中的神经元数量,当经过反复训练后,人脑中会建立更稳定的神经突触连接,对复杂内容也会更容易理解和做出判断。同理,参数量也是模型能力的体现,为模型提供的参数越多,它的学习和记忆能力也就会越强,对内容规律的理解也越深刻。

图片来源自网络
为了方便大家理解GPT的版本差距,我们可以用 OpenAI 近几年在 GPT 模型训练时所使用的参数量做个对比:
- 2018 年 6 月,初代GPT发布,当时的训练量只有 5GB ,参数量是 1.17 亿。
- 2019 年 2 月,GPT-2 的训练量升级为 40GB,模型参数量升级为 15 亿,是第一代的13倍。在当时,模型的效果已经有了很大的提升,但是并没有在国际上引起巨大反响。
- 直到2020 年 6 月,GPT-3 使用了 45TB 的训练数据,资料库包括维基百科、网络新闻、博客、代码、书籍等各种资料,模型参数达到了惊人的 1750 亿,是第二代的 116 倍。由于量级远超前两代,因此该类模型也被称为超大语言模型(Large Language Model,LLM)。也是在这个时候,GPT-3开始显露出3个重要能力:语言生成、上下文学习和广泛的知识量。
语言生成,即依照提示词来补全整个句子,这正是前文中提到的【单词接龙】能力。
案例学习,通过分析给定任务的具体案例,来为新的情景提供解决方案。
广泛知识量,包括各类事实性真理和各种生活常识。
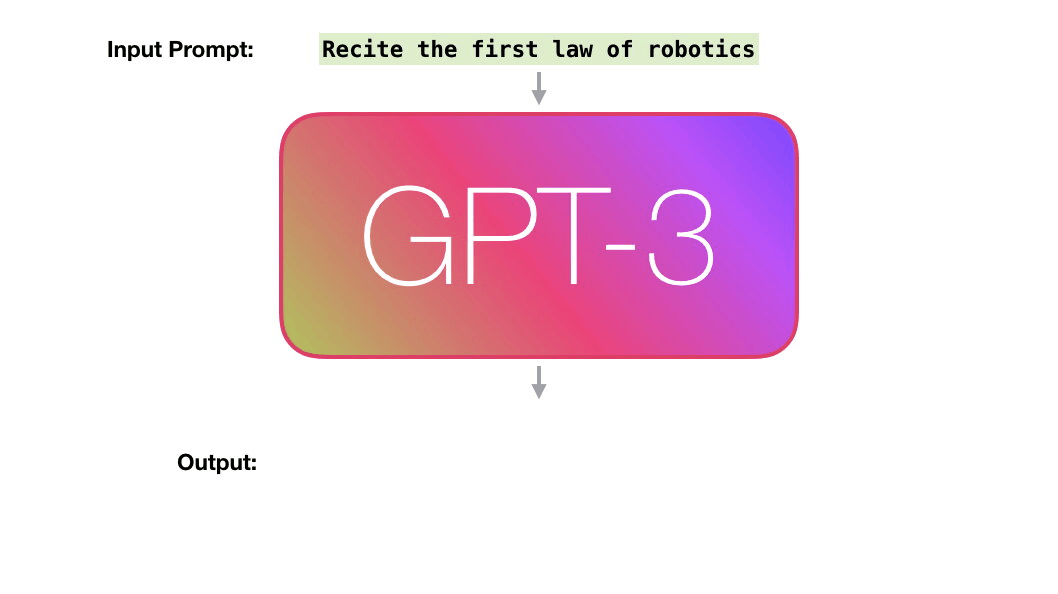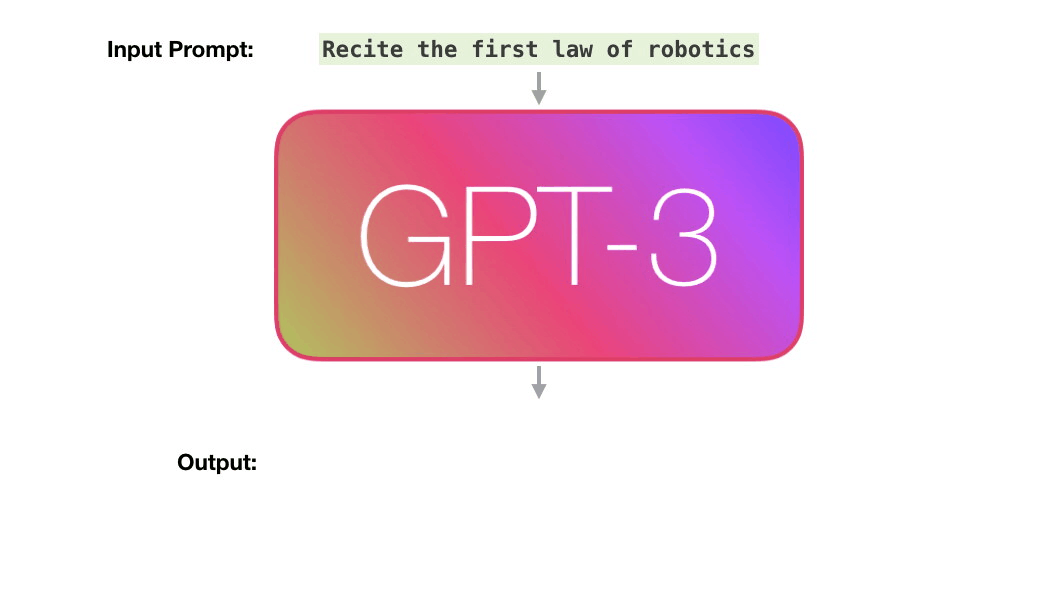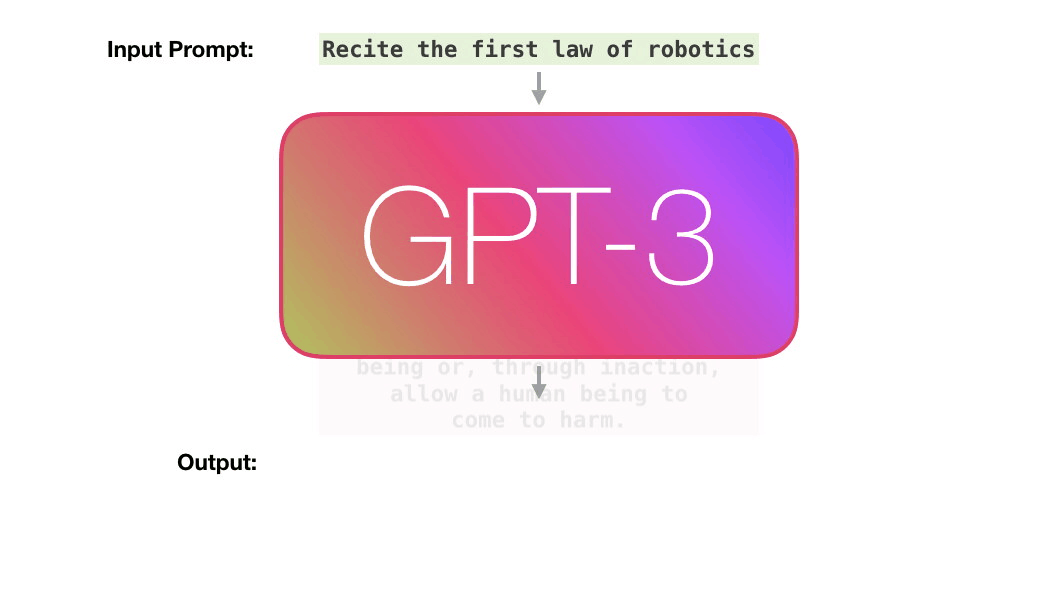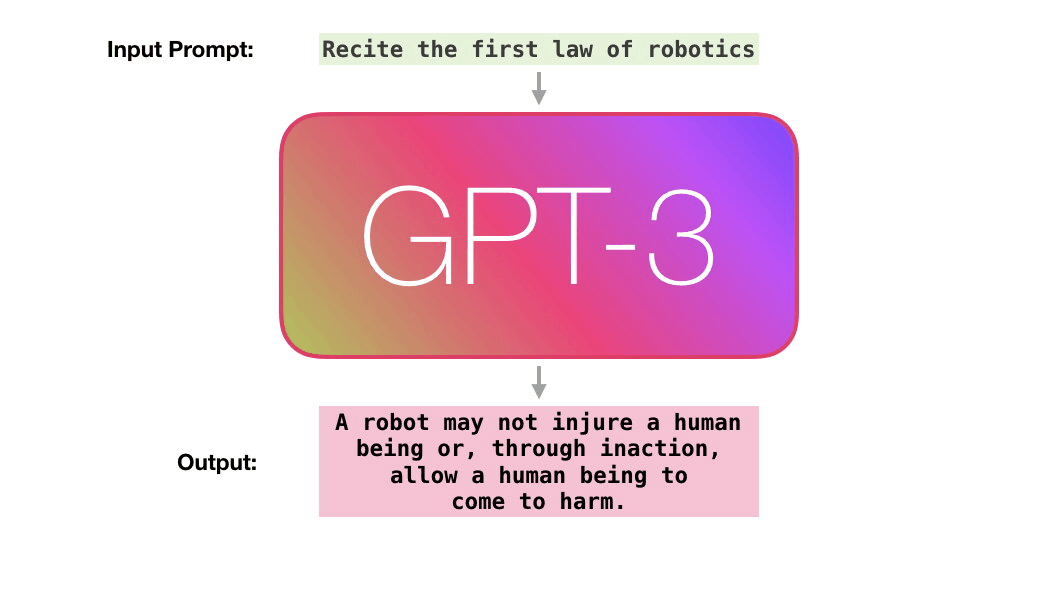
图片来源:机器之心报道
在这个时候,大语言模型的价值已经初露成效,但是在当时并没有被广泛传播。一方面是因为2019 年谷歌团队发布的Bert模型是当时 GPT 模型的有力竞争者,不仅同等参数规模下算力成本更低,而且相对而言业内知名度更高,许多出版文献和资料都是基于Bert模型的研究。
再加上在专业技术领域,很多突破性的技术进展如果没有相应载体的传播,很难被大众所熟知,大部分情况下都是通过发表论文来展现下技术实力,且面向内测团队开放的 API 通常也有较多的限制。
ChatGPT的训练过程
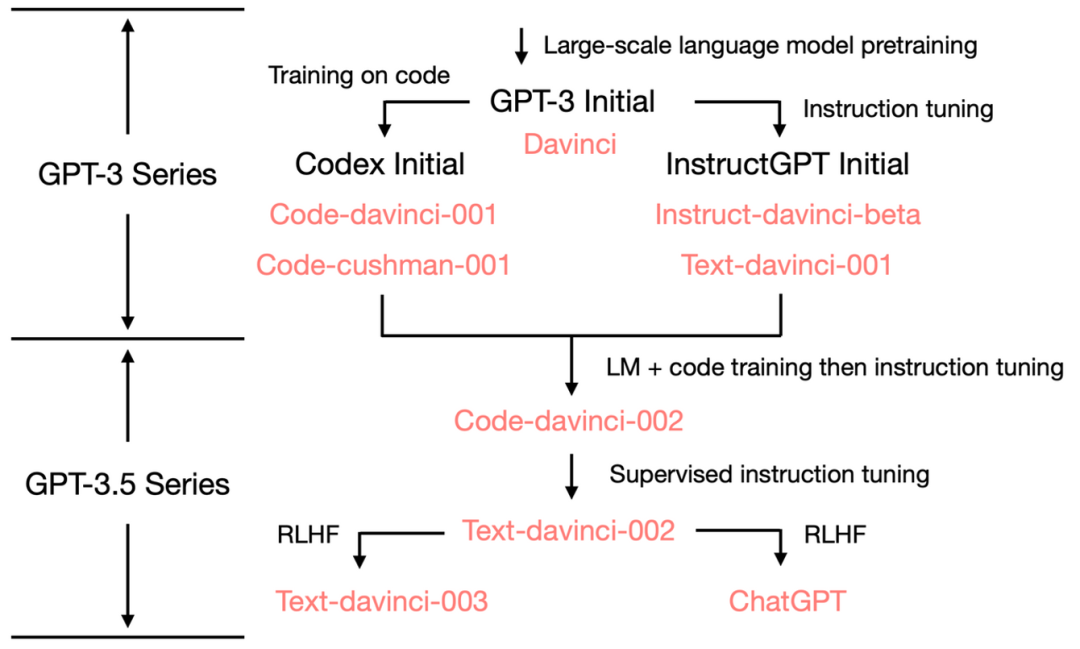
图片来源:《拆解追溯 GPT-3.5 各项能力的起源》
而从GPT-3到火爆全球chatGPT的3.5版本,GPT模型还经历了三个阶段的训练:监督微调、奖励训练、强化学习。
第一阶段:监督微调
为了让GPT-3.5准确理解人类指令的提示内容并输出高质量的回答。OpenAI的团队从众多问题中选择一部分进行人工标注并写出高质量的参考答案,通过不断给GPT模型提供这些规范问答来提升其理解因果关系的能力。
第二阶段:奖励训练
在这一阶段,研究人员不再提供规范好的答案,而是使用监督微调后的模型对随机抽查的问题进行多次回答,然后通过人工标注答案的质量排名。通过这样的方式,GPT模型对于理解高质量问题有了更准确的判断。
第三阶段:强化学习
研究人员将第二阶段的奖励训练封装成自主运行的奖励模型,让此前的人工标注排名可以实现自主重复运行,这个过程中通过强化学习的方式不断优化模型生成内容的能力。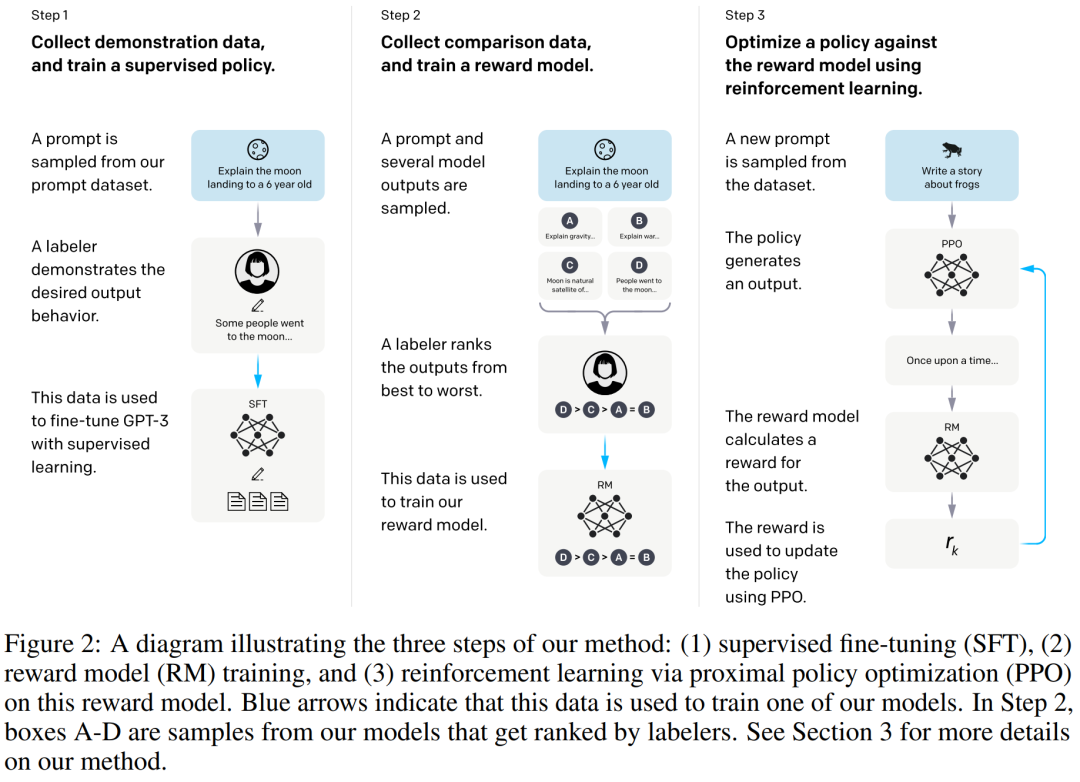
图片来源:ChatGPT的前身 InstructGPT 框架
在以上三个阶段的训练中,GPT运用了多种技术架构,比如RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习),通过人工反馈来强化模型的理解能力,以及判断问题真实性,是虚假信息还是误导性信息?又或者问题的合理性,是否违反社会伦理或造成伤害?TAMER(Training an Agent Manually via Evaluative Reinforcement,评估式强化人工训练代理):通过奖励模型来加快模型的训练速度等。
通过不断重复以上训练迭代模型,2022年11月30日,搭载了 GPT3.5 的 chatGPT 正式开放了聊天接口给用户参与,至此,一款颠覆人类想象的AI聊天工具正式进入大众的视野,在其可怕知识储备和生成式算法的影响下,越来越多的人开始自发在社交媒体上传播。此外, 由于OpenAI 团队对模型在种族主义等类似敏感话题上的严格管控,避免了因为用户恶意训练导致模型黑化,也从侧面减少了许多政治、宗教的禁令风险,最终使chatGPT让在几个月火遍全球。
GPT的意义
可能很多人都没有注意到,在过去的短短三十年内,人类已经经历了三次技术的迭代,每一次都是以不起眼的形式出现,并迅速颠覆了我们的日常生活方式:第一次出现的互联网跨越了现实空间,将全世界的网友链接在一起,第二次是智能手机,便携的移动端解放了我们的业余时间,让我们可以随时随地进行网络互动,而随着ChatGPT的发布,第三次技术革命已经开始,而且速度比我们想象中快的多。
2023年3月14日,OpenAI发布GPT-4
距离上一次GPT3.5发布才刚刚过去4个月,全新的GPT-4就已经发布,而第五代也早已在研发中,甚至第六代、第七代也可能在今年上线。此外,最近几周,包括谷歌发布的Bard、百度的文心一言、微软全家桶植入GPT-4、Adobe发布Firefly等,全世界知名的互联网企业全都开始涌入AI市场,资本的涌入和技术的迭代势必会让AI的发展急剧加速。而这一切,正是由于OpenAI的成功让世界都看到了大语言模型的可能性,当前ChatGPT还只是应用在聊天领域的日常办公,未来很可能人工智会辐射至各行各业,从搜索引擎到办公软件、从社交媒体到游戏开发,AI的发展很快就会以病毒传播式的速度普及到我们的日常生活中。
Adobe发布Firefly
除了生活方式的迭代,GPT模型更重要意义在于知识的传承。人类和其他动物的最大区别,便是在于前人的知识可以通过语言和文字传承下来,这才让几千年里人类的文明知识就能迅速发展到如今的地步。但是似乎最近这些年里,我们已经很难听到像万有引力、相对论这些跨时代的科学进步再出现,这是限于人类物种的生理极限,在短短的百年岁月里光是学习前人的知识便耗费了很多人大半的时间,在剩下的几十年里每一步的前进都愈加困难。
然而,AI技术的出现给人类科学发展也带来了新的转折点,除了知识覆盖面广、处理速度快、生产效率高等优点外,人工智能深度学习和理解分析的能力在每个领域的探索都是绝佳的助力。从长远来看,很可能未来人类只能作为乘客,看着AI带着我们往科学的下一步发展,甚至可能AI本身也会自行迭代研发出更加智能的AI技术,这些作为目前的我们都不得而知了。
但同时,我们也要意识到AI技术的局限性,前面我们提到GPT模型非常依赖于学习材料的输入,而一旦有人恶意提供大量违反社会伦理和恶意导向的资源来训练模型,其后果将难以想象。此外,生成模型另一个的可怕之处在于其不可控性,要知道,就连OpenAI的创始人奥特曼本人及其团队如今对AI生成的结果都是无法溯源其原理的,如今唯一能做的就是不断提供优质内容进行正向引导,这也是为什么奥特曼曾多次发文强调愿意积极配合政府,严格监管和抑制ChatGPT的使用。包括马斯克也多次公开表示,人类应该限制AI的发展速度,因为其极度的不可控性。
马斯克带头签署千人联名信,紧急呼吁 AI 实验室立即暂停研究
最后的话
在最后的结尾,我想再聊几句我对AI技术的思考。
6年前在中国乌镇围棋峰会上,当我们第一次看到 AlphaGo 以3比0战胜排名世界第一的世界围棋冠军柯洁时,所有人还没意识到这是人类历史上少数几次人类还有机会能与AI博弈的机会,当时我还无法理解为什么柯洁会在中途离席落泪。如今看来,作为人类在某一领域最顶尖代表的他在那个时候就已经意识到,从那一刻开始,从今以后人类将再也不可能在棋盘上战胜AI。
很可能再过几十年,我们再回想起2022年11月30日大洋彼岸出现的那款叫做chatGPT的AI工具时,才意识到从那个时刻开始,人类时代的倒计时已经响起了。
参考资料
https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer#Transformer%E4%B8%BA%E4%BD%95%E4%BC%98%E4%BA%8ERNN
https://mp.weixin.qq.com/s/WzNlxgX4PpGQ_5cdJh0xKA
https://mp.weixin.qq.com/s/Fkp_lFA1ycdH9tZ4saxdQw
https://mp.weixin.qq.com/s/nXDosBgDvREsn1paGyRfdg
https://mp.weixin.qq.com/s/wtup0ZhBA2dPZaYiVcjNFg
https://mp.weixin.qq.com/s/VaQsX8icwJDqeXYKYtfrHA
https://mp.weixin.qq.com/s/EohQySoEAyGtzxRcqAolwQ
https://mp.weixin.qq.com/s/XZCaKTnQ-xJ_9vaLuJswbQ
https://www.gatesnotes.com/The-Age-of-AI-Has-Begun
https://mp.weixin.qq.com/s/TA8wr80ldvYBmb1esSFXWQ
https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756

若有收获,就点个赞吧
0 人点赞
