- vue3的diff算法的一些源码分析。总结一波关键点进行回溯记忆">前提: 最近又看了看vue3的diff算法的一些源码分析。总结一波关键点进行回溯记忆
- 一、没有key的节点,不需要diff核心算法
- 二、对于有key的节点,会用到diff算法:patchKeyedChildren
前提: 最近又看了看vue3的diff算法的一些源码分析。总结一波关键点进行回溯记忆
一、没有key的节点,不需要diff核心算法
patchUnkeyedChildren方法简要代码const patchChildren: PatchChildrenFn = (n1, n2,...) => {const { patchFlag, shapeFlag } = n2if (patchFlag & PatchFlags.KEYED_FRAGMENT) {patchKeyedChildren(){}} else if (patchFlag & PatchFlags.UNKEYED_FRAGMENT) {1. 遍历新旧中最短的节点,依次patch,如果不是相同节点,直接卸载const commonLength = Math.min(c1.length, c2.length)for (let i = 0; i < commonLength; i++) {patch(c1[i],c2[i])}2. 变长了就新增,变短了就删除节点将commonLength作为 start开始循环 卸载或者,新增节点c1.length > c2.length? unmountChildren(c1,...,commonLength) : mountChildren(c2,...,commonLength)}}
二、对于有key的节点,会用到diff算法:patchKeyedChildren
以下内容都是 patchKeyedChildren方法简要代码
1. 前后对比记住三个变量 i , e1 , e2
let i = 0;let e1 = c1.length - 1let e2 = c2.length - 1从前往后遍历,i增加. 遇到不一样的节点暂停。i 的值就很重要了。while (i <= e1 && i <= e2) {const n1 = c1[i]const n2 = c2[i]if (isSameVNodeType(n1, n2)) {patch(...)} else {break}i++}再从后往前遍历,原元素递减,遇到相同的也暂停。while (i <= e1 && i <= e2) {const n1 = c1[e1]const n2 = c2[e2]if (isSameVNodeType(n1, n2)) {patch(...)} else {break}e1--e2--}
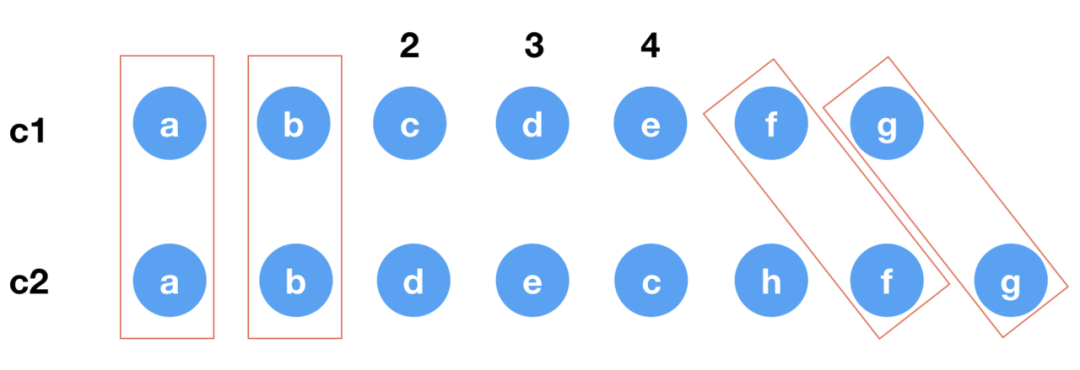
上面前后循环对比得到结论: i = 2, e1 = 4 , e2 = 4
从结论来思考如果是单纯的增加元素,或者减少元素呢
单纯在末尾新增一个元素ce1 :a be2 :a b c得到: i = 2, e1 = 1, e2 = 2单纯在头部新增元素c, d, ke1 :a be2 :c d k a b得到: i = 0, e1 = -1, e2 = 2//单纯在末尾减少一个元素ce1 :a b ce2 :a b得到: i = 2, e1 = 2, e2 = 1单纯在头部减少一个元素ce1 :a b ce2 :b c得到: i = 0, e1 = 0, e2 = -1中间新增或减少e1 :a b ce2 :a c得到: i = 1, e1 = 1, e2 = 0
从上面可以看出规律: 单纯的新增元素时: i > e1, 单纯的减少元素时: i > e2. 如果 i 比e1 e2 小,那就不是单纯新增或减少了.
代码为证:
if (i > e1) {if (i <= e2) {while (i <= e2) {创建新的节点patch(null,...)i++}} else if (i > e2) {单纯的减少元素 直接去掉元素while (i <= e1) {unmount(c1[i], parentComponent, parentSuspense, true)i++}} else {//}
单纯新增减少元素不会涉及到diff算法的核心算法。其他情况else才需要用到
1. 核心算法记住几个变量
以下代码都是else里面的
1. 第一步遍历到的index,存起const s1 = iconst s2 = i2. 前后对比循环后,,通过map 记录 c2 没有比较过的节点的位置角标const keyToNewIndexMap: Map<string | number, number> = new Map()/* */for (i = s2; i <= e2; i++) {const nextChild = c2[i]if (nextChild.key != null) {keyToNewIndexMap.set(nextChild.key, i)}}3. c2 中待处理的节点数目const toBePatched = e2 - s2 + 14. 证明是否移动let moved = false5.记录节点在 c2 中的最大索引,假如节点在 c2 中的索引位置小于这个最大索引,代表有元素需要移动let maxNewIndexSoFar = 06.针对未比较的C2 节点建立一个数组,每个子元素都是0 [ 0, 0, 0, 0, 0, 0]初始情况,0 代表新增const newIndexToOldIndexMap = new Array(toBePatched)for (i = 0; i < toBePatched; i++) {newIndexToOldIndexMap[i] = 0}
通过开篇的图,结合以上代码,我们可以得出这些值
c2 中待处理的节点有:d,e,c,h。对应索引是2,3,4,5keyToNewIndexMap: [ 2 , 3 ,4 ,5 ]toBePatched = 4newIndexToOldIndexMap: [0,0,0,0]
2. 记住上面的变量后,下面就是最重要的环节了
已处理的节点let patched = 0let jfor (i = s1; i <= e1; i++) {// 如果已处理的数量大于待处理节点数,直接删剩余的// if (patched >= toBePatched) {// unmount(prevChild, parentComponent, parentSuspense, //true)// continue// }const prevChild = c1[i]let newIndex1. 通过key匹配新旧节点,newIndex就是标识节点在c2中的位置此时上面得到的keyToNewIndexMap开始发挥作用if (prevChild.key != null) {newIndex = keyToNewIndexMap.get(prevChild.key)} else {3. 如果,老节点的key不存在,遍历剩下的所有新节点。什么情况下老节点的key会不存在呢??for (j = s2; j <= e2; j++) {// newIndexToOldIndexMap里面本身初始化的都是0// 这里=== 0 代表 新节点没有被patchif ( newIndexToOldIndexMap[j - s2] === 0 &&isSameVNodeType(prevChild, c2[j] as VNode)) {3.1 找到与当前老节点对应的新节点,记录newIndexnewIndex = jbreak}}}2.1 newIndex 无值,代表没有找到与老节点对应的新节点,删除节点//拓展:void 0是undefined备选方案。字节更少// void 后面随便跟上一个表达式,返回的都是 undefinedif (newIndex === void 0) {unmount()} else {2.2 注意:i + 1,0 有特殊用途。把老节点的索引,记录在存放新节点的数组中newIndexToOldIndexMap[newIndex - s2] = i + 12.3 看这里:记录maxNewIndexSoFar如果某节点的索引大于之前节点的索引代表有元素移动了moved = trueif (newIndex >= maxNewIndexSoFar) {maxNewIndexSoFar = newIndex} else {moved = true}2.4 找到新的节点进行patch节点 ,建立对应关系,执行patch将旧dom上的el(真实dom的引用)和其他给到新节点patch(prevChild)patched++}}
以上代码实现:
- 遍历c1待处理的节点, 在c2中有没有相同key的节点
没有就直接删掉unmount,有就记录改节点的索引
在找的过程中发现旧节点没有key??那就嵌套遍历新节点c2找到对应关系
- 把旧节点在c1的位置(非索引,因为0要代表新增节点),存放在newIndexToOldIndexMap
我们可以得到以下的结论
3 4 5c d ed e c heg: 节点c 在原位置是3,索引是2。这里存在它在新节点中的位置,(h为新增,原位置没有)newIndexToOldIndexMap:[4, 5, 3, 0]
通过newIndexToOldIndexMap求得最小递增子序列
这是一个优化点
求解一个稳定递增的序列,即不需要移动的序列,其他未在稳定序列的节点,进行移动。实现最小化移动元素
newIndexToOldIndexMap [4, 5, 3, 0] --> 最长递增子序列是 [4, 5]对应的索引是 [0, 1]increasingNewIndexSequence = [0, 1]
3. 最后一步遍历c2,该移动的移动该新增的新增
const increasingNewIndexSequence = moved? getSequence(newIndexToOldIndexMap): EMPTY_ARRj = increasingNewIndexSequence.length - 1注意:这里是从后往前遍历i = 3 s2 = 2nextIndex = 5anchor 是找到h节点的后一个,也就是f节点插入。小于新节点长度实际上就是移动到最后for (i = toBePatched - 1; i >= 0; i--) {const nextIndex = s2 + iconst nextChild = c2[nextIndex]const anchor =nextIndex + 1 < c2.length ? (c2[nextIndex + 1] as VNode).el : parentAnchor1. 这里 === 0 表示 c2 中的节点在 c1 中没有对应的节点,就新增它if (newIndexToOldIndexMap[i] === 0) {patch(null)} else if (moved) {2. 移动, 怎么最小化移动呢?最长递增子序列对应的元素不需要移动// j < 0 --> 最长递增子序列为 []if (j < 0 || i !== increasingNewIndexSequence[j]) {move(nextChild, container, anchor)} else {j--}}}
具体怎么移动呢?
上面代码有一个anchor,反向遍历,找到新节点的需要移动的节点的同级下个兄弟节点,执行dom的insetBefore操作:源码move方法
源码部分引入insert后,改为了hostInsertinsert: hostInsert,const move: MoveFn = (vnode, container, anchor,) => {hostInsert(vnode.anchor!, container, anchor)}
所有dom的操作在这里runtime-dom
这里为什么要提这个move呢。主要是因为强调一下vnode上的el属性的重要性,在第二步的时候将真实dom的引用给到新节点el,才能通过节点执行dom的方法
总结
在前后对比时,会判断是否是相同节点isSameVNodeType.判断条件是相同的type和相同的key
export function isSameVNodeType(n1: VNode, n2: VNode): boolean {return n1.type === n2.type && n1.key === n2.key}
想一想,如果在v-for里面用index作为key(或者用index拼接其他值作为key),第一步的前后对比都失去了意义
新增一个c,都是以index为key0 1a b0 1 2c a b从后往前遍历时是会发现新旧节点b的key不同。无法复用
所以老老实实用数据唯一id作为key吧
vue2 的时间复杂度是O(n) , vue3 用到了最长递增子序列,时间复杂度是O(nlogn),但是因为找出了最长递增子序列,减少了dom移动的开销,能够提高性能
tip: vue双端比较由嵌套循环变为一个循环,用空间换时间- Virtual DOM 带来了 分层设计,它对渲染过程的抽象,使得框架可以渲染到 web(浏览器) 以外的平台,以及能够实现 SSR 等。
至于 Virtual DOM 相比原生 DOM 操作的性能,这并非 Virtual DOM 的目标,确切地说,如果要比较二者的性能是要“控制变量”的,例如:页面的大小、数据变化量等 看完文章可以发现,上面代码对节点的操作都用到了patch函数,patch做了什么呢??
patch概念:如果旧的 VNode 存在,则会使用新的 VNode 与旧的 VNode 进行对比,试图以最小的资源开销完成 DOM 的更新,这个过程就叫 patchconst patch: PatchFn = (n1, n2) => {1. 旧元素存在,但是不是同类型直接卸载if (n1 && !isSameVNodeType(n1, n2)) {unmount(n1)n1 = null}2. 根据新元素的类型,创建不同的节点,比如processElementconst { type, ref, shapeFlag } = n2switch (type) {case Text:processText(n1, n2, container, anchor)breakcase Fragment:processFragment(n1,n2, ...)breakdefault:if (shapeFlag & ShapeFlags.ELEMENT) {processElement(n1,n2,...)}}// 每次patch都要重新设置ref,这也就是为什么在编译阶段不对含有ref的节点进行提升的原因// 因为ref是当作动态属性来看待的if (ref != null && parentComponent) {setRef(ref, n1 && n1.ref, parentSuspense, n2 || n1, !n2)}}
再看processElement,上一步节点不一致,就将n1置为null,所以在下面判断新增新节点
const processElement = ( n1: VNode | null,n2: VNode) => {if (n1 == null) {mountElement(n2,...)} else {patchElement(n1,n2,...)}}patchElement方法会将VNode上的真实dom引用el属性给到新节点,el很重要,有了它才能执行dom操作如果n2下面有children子节点,会再次进入 patchChildren,回到文章开头const patchElement = (n1, n2,...) => {const el = (n2.el = n1.el!)...省略代码patchChildren(n1,n2)}
引用
最长递增子序列怎么算出来的?
Vue3.0 Diff核心算法详解
渲染器
这里说明一下,渲染器这篇文章非常细致地讲解了渲染器的设计过程,并不代表vue完全就是这样
- 文中提到的子节点是数组(不管是不是v-for生成)会自动生成key,一度让我迷惑:以为没有key会自动生成key,然后进行diff核心比较。看源码后发现没有key就是null,就会走patchUnkeyedChildren,如果不移动节点,key都是null也会通过isSameVNodeType判断进行复用
文中提到旧的节点为多个,只有新节点也为多个才进行核心diff,这一点在vue3代码我没看到,从代码上看:只关心有key无key。
2021-6-18新增:这一点是在react代码里有:单节点diff,源码部分reconcileChildFibers单个节点就是isObject ,执行reconcileSingleElement判断是否可以复用function reconcileChildFibers(returnFiber: Fiber,currentFirstChild: Fiber | null,newChild: any){const isObject = typeof newChild === 'object' && newChild !== null;if (isObject) {case REACT_ELEMENT_TYPE:return placeSingleChild(reconcileSingleElement(),);}}
vue函数式组件和有状态的组件(类组件)更新有什么区别 ?
(1)类组件在实例上挂在更新方法,可以在外部执行更新。函数式组件只能由props数据驱动更新,判断是否更新的条件是:是否有preNode
(2)VNode 的 children 属性本应该用来存储子节点,但是对于组件类型的 VNode 来说,它的子节点都应该作为插槽存在,并且我们选择将插槽内容存储在单独的 slots 属性中,而非储在 children 属性中函数式组件的 使用 children 属性存储产出的 VNode ,slots属性存储插槽数据有状态组件类型使用其 children 属性存储组件实例,用 slots 属性存储插槽数据
4.关于vue2的diff在文中 双端比较这一节非常清晰
可以对比查看vue2的源码updateChildren

若有收获,就点个赞吧
0 人点赞
