聚合函数
将整张表当成一组数据,对这组数据进行的操作即为聚合函数。
# 1. 求所有手机价格的总和SELECT SUM(price) as totalPrice FROM `products`;# 2. 求所有华为手机价格的总和SELECT SUM(price) huaTotalPrice FROM `products` WHERE brand = '华为';# 3. 求所有华为手机的平均价格SELECT AVG(price) FROM `products` WHERE brand = '华为';# 4. 求所有华为手机的最高、最低价格SELECT MAX(price) FROM `products` WHERE brand = '华为';SELECT MIN(price) FROM `products` WHERE brand = '华为';# 5. 求所有华为手机的个数SELECT COUNT(*) FROM `products` WHERE brand = 'OPPO'; -- 21SELECT COUNT(url) FROM `products` WHERE brand = 'OPPO'; -- 17 ,5个url为NULLSELECT COUNT(price) FROM `products`; -- 108SELECT COUNT(DISTINCT(price)) FROM `products`; -- 79,去掉了价格重复的
Group By
聚合函数是把整个表当成一组数据,Group By可以将数据分组。
# 根据brand不同分成多组,然后各组内进行聚合计算
SELECT AVG(price), COUNT(*), AVG(score) FROM `products` GROUP BY brand;
# SELECT加入brand,结果更清晰,但brand不能乱加,需要和GROUP BY后字段匹配
SELECT brand, AVG(price), COUNT(*), AVG(score) FROM `products` GROUP BY brand;

HAVING
1. HAVING是对分组之后的结果进行二次筛选
获取分组后平均价格大于2000的数据
# 错误写法1
SELECT brand, AVG(price), COUNT(*), AVG(score) FROM `products` GROUP BY brand WHERE price > 2000;
# 错误写法2
SELECT
brand,
AVG(price) avgPrice,
COUNT(*),
AVG(score)
FROM `products`
GROUP BY brand
WHERE avgPrice > 2000;
# 正确写法
SELECT
brand,
AVG(price) avgPrice,
COUNT(*),
AVG(score)
FROM `products`
GROUP BY brand
HAVING avgPrice > 2000; -- 在21行之前(包括21行)统计完后,再执行22行
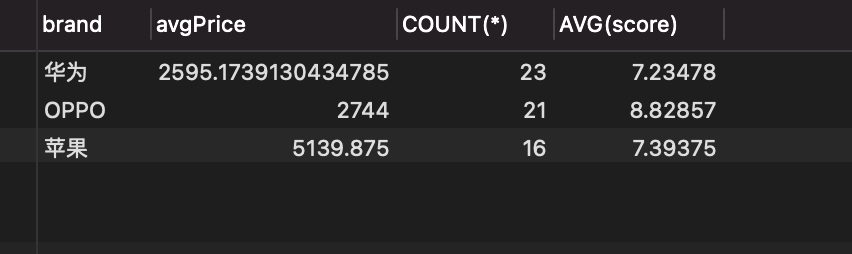
2. 数据

要求:
求评分大于9.0的手机,按照品牌分类后的平均价格
# 先where筛选,再分组,在此基础再算平均价格,平均分
SELECT
brand,
AVG(price)
FROM `products`
WHERE score > 9.0
GROUP BY brand;
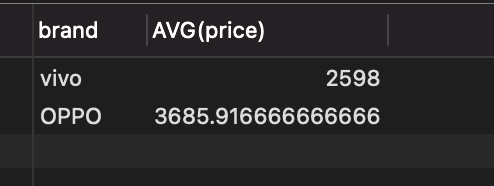
3. 当然也可以在此基础上继续用HAVING
SELECT
brand,
AVG(price) avgPrice
FROM `products`
WHERE score > 9.0
GROUP BY brand
HAVING avgPrice > 3000; -- 把7行和7行之前的看成分开执行就行了
结果:

若有收获,就点个赞吧
0 人点赞
