前言
支持向量机在应用到二分类和多分类问题上, 很强大,
需要了解支持向量机的基础知识,请先自行学习
数据集介绍
线性数据集
:::success
sklearn.datasets.make_blobs(n_samples=100, n_features=2, centers=3, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None)
n_samples: 待生成的样本的总数
centers: 要生成的样本中心(类别)数,或者是确定的中心点
cluster_std: 每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以 cluster_std设置为[1.0,3.0]
:::
圆形数据集
:::success
sklearn.datasets.samples_generator.make_circles()
略
:::
使用支持向量机完成线性分类
导包
import matplotlib.pyplot as pltfrom sklearn.datasets._samples_generator import make_blobsimport numpy as np# "Support Vector Classifier" 支持向量机分类器from sklearn.svm import SVC
使用sklearn自带的数据集生成数据
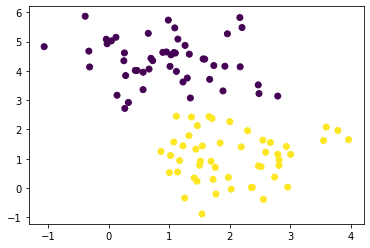
# n_samples=100 是取100个点# centers=2 是将数据分为2类data, target = make_blobs(n_samples=100, centers=2, random_state=3, cluster_std=0.7)# 将图片展示出来plt.scatter(data[:,0],data[:,1], c=target, s=10, cmap='autumn')plt.show()
:::tips
X[:, 0]就是所有的x轴数据
X[:, 1]就是所有的y轴数据
:::

粗略的画出3条决策边界
xfit = np.linspace(-5, 3, 5)# 先画出散点图plt.scatter(data[:,0], data[:,1], c=target, s=10, cmap='autumn')# 画三条线plt.plot(xfit, -xfit, '-k')plt.plot(xfit, -0.5*xfit+0.7, '-k')plt.plot(xfit, 1*xfit+2.9, '-k')plt.show()

训练一个SVC模型
model = SVC(kernel='linear', C=1E10)model.fit(data, target)
SVC(C=10000000000.0, kernel=’linear’)
画出该SVC模型的图形
def plot_svc_decision_function(model, data, target, ax=None, plot_support=True):# """Plot the decision function for a 2D SVC"""if ax is None:ax = plt.gca()xlim = (data[:,0].min(), data[:,0].max())ylim = (data[:,1].min(), data[:,1].max())x = np.linspace(xlim[0], xlim[1], 100)y = np.linspace(ylim[0], ylim[1], 100)Y1, X1 = np.meshgrid(y, x)xy = np.vstack([X1.ravel(), Y1.ravel()]).TP = model.decision_function(xy).reshape(X1.shape)ax.contour(X1, Y1, P, colors='k',levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--'])if plot_support:ax.scatter(model.support_vectors_[:, 0],model.support_vectors_[:, 1],s=10, linewidth=1, facecolors='none');ax.set_xlim(xlim)ax.set_ylim(ylim)plt.scatter(data[:, 0], data[:, 1], c=target, s=10, cmap='autumn')
plot_svc_decision_function(model, data, target);

:::tips 这个画图的代码比复杂, 我稍微解释一下
- 第5行是获取整个X数据的x轴最小值和最大值
- 第6行是获取整个X数据的y轴最小值和最大值
- 第9行是根据xlim和ylim获取坐标轴
- 第11~14行, 我也看不懂, 也懒得看, 反正能跑出来
第17行是画散点图的 ::: :::info 其实在边界上的两个红点和一个黄点在决策边界上,是支持向量,其
 值不为0。这三个点的坐标可以由
值不为0。这三个点的坐标可以由model.support_vectors_得出。
这个分类器的成功的关键在于:为了拟合,只有支持向量的位置是重要的;远离任何边距的点,都不会影响拟合。边界之外的点无论有多少都不会对其造成影响,下面来对比一下数据为60和120时的区别。 :::对比60和120个样本点的差距
def plot_svm(N=10, ax=None):data, target = make_blobs(n_samples=200, centers=2, random_state=0, cluster_std=0.60)data = data[:N]target = target[:N]model = SVC(kernel='linear', C=1E10)model.fit(data, target)if ax is None:ax = plt.gca()ax.scatter(data[:, 0], data[:, 1], c=target, s=50, cmap='autumn')plot_svc_decision_function(model, data, target, ax)
fig, ax = plt.subplots(2, 3, figsize=(16, 6))fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)for axi, N in zip(ax.flatten(), [30, 60, 90, 120, 150, 180]):#左侧的数据60个样本点,右侧的数据为120样本点。plot_svm(N, axi)axi.set_title('N = {0}'.format(N))plt.show()
 :::tips
:::tips
plt.subplots(2, 3, figsize=(16, 6))这行代码返回的是fig和一个numpy.ndarray类型的变量,如果是建立的2行3列的大图,最后在使用zip变量进行遍历的时候,要记得将shape=(2, 3)的axes拉伸成shape=(1, 6)的数组才可以 ::: :::info 由上图可以看到,相邻密度构成的决策边界是大致一样的。这就意味着样本的多少对决策边界是影响不大的(是有影响的),这主要是因为没有引入足够的新的支持向量,意思就是说只要边界上的点不变就不会对决策边界造成影响。 :::线性分类的总代码
import matplotlib.pyplot as pltfrom sklearn.datasets._samples_generator import make_blobsimport numpy as np# "Support Vector Classifier" 支持向量机分类器from sklearn.svm import SVC# n_samples=100 是取100个点# centers=2 是将数据分为2类X ,y = make_blobs(n_samples=100, centers=2, random_state=3, cluster_std=0.7)# 将图片展示出来plt.scatter(X[:,0],X[:,1], c=y, s=10, cmap='autumn')plt.show()xfit = np.linspace(-5, 3, 5)# 先画出散点图plt.scatter(X[:,0], X[:,1], c=y, s=10, cmap='autumn')# 画三条线plt.plot(xfit, -xfit, '-k')plt.plot(xfit, -0.5*xfit+0.7, '-k')plt.plot(xfit, 1*xfit+2.9, '-k')plt.show()model = SVC(kernel='linear', C=1E10)model.fit(X, y)def plot_svc_decision_function(model, data, target, ax=None, plot_support=True):# """Plot the decision function for a 2D SVC"""if ax is None:ax = plt.gca()xlim = (data[:,0].min(), data[:,0].max())ylim = (data[:,1].min(), data[:,1].max())x = np.linspace(xlim[0], xlim[1], 100)y = np.linspace(ylim[0], ylim[1], 100)Y1, X1 = np.meshgrid(y, x)xy = np.vstack([X1.ravel(), Y1.ravel()]).TP = model.decision_function(xy).reshape(X1.shape)ax.contour(X1, Y1, P, colors='k',levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--'])if plot_support:ax.scatter(model.support_vectors_[:, 0],model.support_vectors_[:, 1],s=10, linewidth=1, facecolors='none');ax.set_xlim(xlim)ax.set_ylim(ylim)plt.scatter(data[:, 0], data[:, 1], c=target, s=10, cmap='autumn')plot_svc_decision_function(model, data, target);def plot_svm(N=10, ax=None):data, target = make_blobs(n_samples=200, centers=2, random_state=0, cluster_std=0.60)data = data[:N]target = target[:N]model = SVC(kernel='linear', C=1E10)model.fit(data, target)if ax is None:ax = plt.gca()ax.scatter(data[:, 0], data[:, 1], c=target, s=50, cmap='autumn')plot_svc_decision_function(model, data, target, ax)fig, ax = plt.subplots(2, 3, figsize=(16, 6))fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)for axi, N in zip(ax.flatten(), [30, 60, 90, 120, 150, 180]):#左侧的数据60个样本点,右侧的数据为120样本点。plot_svm(N, axi)axi.set_title('N = {0}'.format(N))plt.show()
使用支持向量机完成核函数分类
接下来引入核函数, 来看看核函数的威力, 真的感觉好厉害~!
下面是具体的讲解流程导包
import matplotlib.pyplot as pltfrom sklearn.datasets._samples_generator import make_circlesimport numpy as np# "Support Vector Classifier" 支持向量机分类器from sklearn.svm import SVC
引入一个线性不可分的数据集
:::success
sklearn.datasets.make_circles(n_samples=100, *, shuffle=True, noise=None, random_state=None, factor=0.8)
n_samples:生成样本的数量,默认为10
shuffle: 是否乱序生成, 默认为True
noise: 添加到数据中的高斯噪声的标准偏差
random_state: int, RandomState instance or None, default=None
fctor: Scale factor between inner and outer circle in the range(0, 1)::: :::successmatplotlib.pyplot.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=None)
left = 0.125 # 子图(subplot)距画板(figure)左边的距离
right = 0.9 # 右边
bottom = 0.1 # 底部
top = 0.9 # 顶部
wspace = 0.2 # 子图水平间距
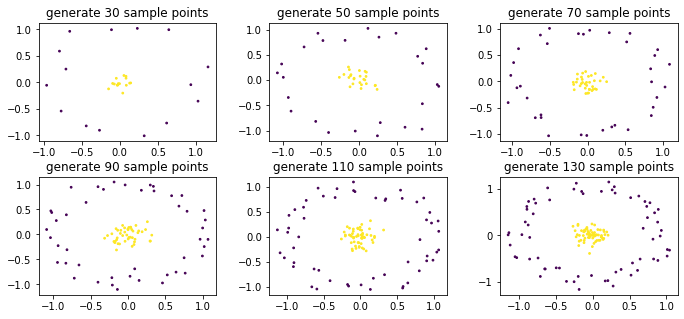
hspace = 0.2 # 子图垂直间距 :::fig, axs = plt.subplots(2, 3, figsize=(10, 5))fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.3, hspace=0.3)for axi, n_samples in zip(axs.flatten(), [30, 50, 70, 90, 110, 130]):data, target = make_circles(n_samples, factor=.1, noise=.1)axi.scatter(data[:,0], data[:,1], c=target, s=3)axi.set_title('generate {} sample points'.format(n_samples))plt.show()
使用线性分类对圆形数据集进行分类
def plot_svc_decision_function(model, data, target, ax=None, plot_support=True):# """Plot the decision function for a 2D SVC"""if ax is None:ax = plt.gca()xlim = (data[:,0].min(), data[:,0].max())ylim = (data[:,1].min(), data[:,1].max())x = np.linspace(xlim[0], xlim[1], 100)y = np.linspace(ylim[0], ylim[1], 100)Y1, X1 = np.meshgrid(y, x)xy = np.vstack([X1.ravel(), Y1.ravel()]).TP = model.decision_function(xy).reshape(X1.shape)ax.contour(X1, Y1, P, colors='k',levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--'])if plot_support:ax.scatter(model.support_vectors_[:, 0],model.support_vectors_[:, 1],s=10, linewidth=1, facecolors='none');ax.set_xlim(xlim)ax.set_ylim(ylim)plt.scatter(data[:, 0], data[:, 1], c=target, s=10, cmap='autumn')
:::tips 注意:上面的
plot_svc_decision_function()函数是上节已经定义过的函数 :::data, target = make_circles(n_samples, factor=.1, noise=.1)model = SVC(kernel='linear').fit(data, target)plot_svc_decision_function(model, data, target)
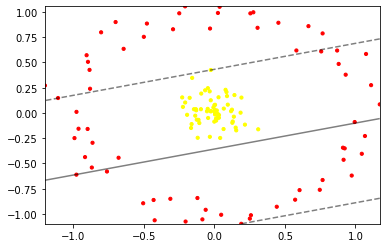 :::info
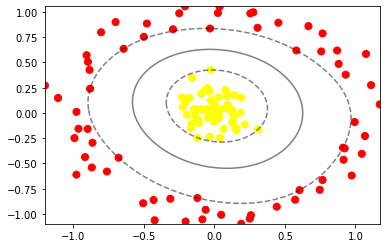
我们生成了一个圆形数据集,并且使用了线性分类进行分类, 可以看到线性分类并不能将圆形数据集进行正确的分类, 因此我们考虑使用核函数对圆形数据集进行分类
:::
:::info
我们生成了一个圆形数据集,并且使用了线性分类进行分类, 可以看到线性分类并不能将圆形数据集进行正确的分类, 因此我们考虑使用核函数对圆形数据集进行分类
:::
先看看数据在高纬空间下的映射
from mpl_toolkits import mplot3dr=np.exp(-(data**2).sum(1))def plot_3D(elev=30, azim=30, X=data, y=target):ax = plt.subplot(projection='3d')ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap='autumn')ax.view_init(elev=elev, azim=azim)ax.set_xlabel('x')ax.set_ylabel('y')ax.set_zlabel('z')plot_3D(elev=45,azim=45,X=data,y=target)plt.show()
引入径向基函数,进行核变换
见证核函数变换的威力的时刻到了~!
clf = SVC(kernel='rbf', C=1E6) #引入径向基 函数clf.fit(data, target)plt.scatter(data[:, 0], data[:, 1], c=target, s=50, cmap='autumn')plot_svc_decision_function(clf, data, target)plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=300, lw=1, facecolors='none');plt.show()
核函数分类的总代码
import matplotlib.pyplot as pltfrom sklearn.datasets._samples_generator import make_circlesimport numpy as np# "Support Vector Classifier" 支持向量机分类器from sklearn.svm import SVCfig, axs = plt.subplots(2, 3, figsize=(10, 5))fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.3, hspace=0.3)for axi, n_samples in zip(axs.flatten(), [30, 50, 70, 90, 110, 130]):data, target = make_circles(n_samples, factor=.1, noise=.1)axi.scatter(data[:,0], data[:,1], c=target, s=3)axi.set_title('generate {} sample points'.format(n_samples))plt.show()def plot_svc_decision_function(model, data, target, ax=None, plot_support=True):# """Plot the decision function for a 2D SVC"""if ax is None:ax = plt.gca()xlim = (data[:,0].min(), data[:,0].max())ylim = (data[:,1].min(), data[:,1].max())x = np.linspace(xlim[0], xlim[1], 100)y = np.linspace(ylim[0], ylim[1], 100)Y1, X1 = np.meshgrid(y, x)xy = np.vstack([X1.ravel(), Y1.ravel()]).TP = model.decision_function(xy).reshape(X1.shape)ax.contour(X1, Y1, P, colors='k',levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--'])if plot_support:ax.scatter(model.support_vectors_[:, 0],model.support_vectors_[:, 1],s=10, linewidth=1, facecolors='none');ax.set_xlim(xlim)ax.set_ylim(ylim)plt.scatter(data[:, 0], data[:, 1], c=target, s=10, cmap='autumn')data, target = make_circles(n_samples, factor=.1, noise=.1)model = SVC(kernel='linear').fit(data, target)plot_svc_decision_function(model, data, target)from mpl_toolkits import mplot3dr=np.exp(-(data**2).sum(1))def plot_3D(elev=30, azim=30, X=data, y=target):ax = plt.subplot(projection='3d')ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap='autumn')ax.view_init(elev=elev, azim=azim)ax.set_xlabel('x')ax.set_ylabel('y')ax.set_zlabel('z')plot_3D(elev=45,azim=45,X=data,y=target)plt.show()clf = SVC(kernel='rbf', C=1E6) #引入径向基 函数clf.fit(data, target)plt.scatter(data[:, 0], data[:, 1], c=target, s=50, cmap='autumn')plot_svc_decision_function(clf, data, target)plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=300, lw=1, facecolors='none');plt.show()
调节参数-软间隔问题
:::info SVM模型有两个非常重要的参数C与gamma。
其中 C是惩罚系数,即对误差的宽容度。
c越高,说明越不能容忍出现误差,容易过拟合。
C越小,容易欠拟合。C过大或过小,泛化能力变差
gamma是选择RBF函数作为kernel后,该函数自带的一个参数。
隐含地决定了数据映射到新的特征空间后的分布,
gamma越大,支持向量越少,
gamma值越小,支持向量越多。 ::: 分别调节C和gamma来看一下对结果的影响:引入一个离散度很大的数据集
# 将离散度cluster_std改为0.8data, target = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=0.8)plt.scatter(data[:,0], data[:,1], c=target)plt.show()
调节参数C
:::tips C趋近于无穷大时,意味着分类严格不能有错误。
C趋于很小时,意味着可以有更大的容忍。 :::data, target = make_blobs(n_samples=100, centers=2,random_state=0, cluster_std=0.8)fig, ax = plt.subplots(1, 2, figsize=(16, 6))fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)for axi, C in zip(ax, [20, 0.2]): #将C分别设定为20和0.2,看其对结果的影响。model = SVC(kernel='linear', C=C).fit(X, y)axi.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')plot_svc_decision_function(model, data, target, axi)axi.scatter(model.support_vectors_[:, 0],model.support_vectors_[:, 1],s=300, lw=1, facecolors='none');axi.set_title('C = {0:.1f}'.format(C), size=14)plt.show()
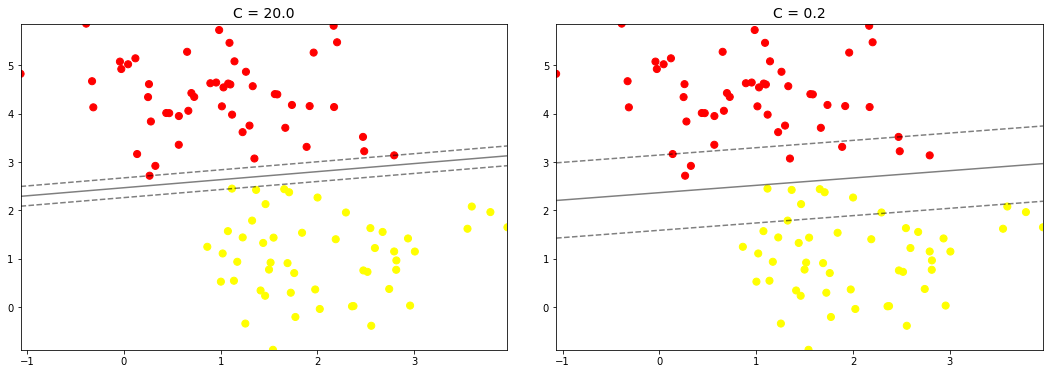 :::info
可以看出:
:::info
可以看出:
当C=20较大时,对分类错误的容忍是很低的
当C=0.2较小时,对分类错误的容忍是较高的
——————————————————————————————————————————————————————————-
左边这幅图C值比较大,要求比较严格,不能分错东西,隔离带中没有进入任何一个点,但是隔离带的距离比较小,泛化能力比较差。右边这幅图C值比较小,要求相对来说比较松一些,隔离带较大,但是隔离带中进入了很多的黄点和红点。那么C大一点好还是小一点好呢?这需要考虑实际问题,可以进行K折交叉验证来得出最合适的C值。 :::调节参数gamma
data, target = make_blobs(n_samples=100, centers=2,random_state=0, cluster_std=1.1)fig, ax = plt.subplots(1, 2, figsize=(16, 6))fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)for axi, gamma in zip(ax, [20, 0.1]): #比较了一下gamma为20和0.1对结果的影响model = SVC(kernel='rbf', gamma=gamma).fit(X, y)axi.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')plot_svc_decision_function(model, data, target, axi)axi.scatter(model.support_vectors_[:, 0],model.support_vectors_[:, 1],s=300, lw=1, facecolors='none');axi.set_title('gamma = {0:.1f}'.format(gamma), size=14)plt.show()
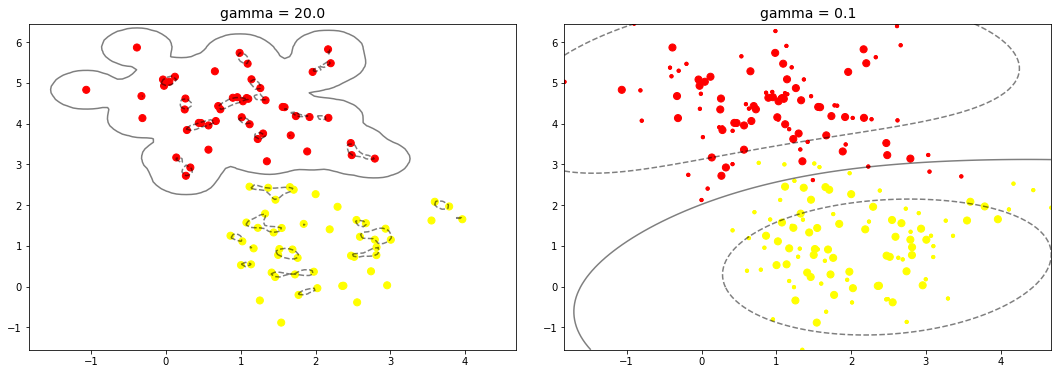 :::info
左边的图边界比较复杂,这也意味着泛化能力更弱,右边的图比较精简,泛化能力较强。一般会选择泛化能力较强的。
:::
:::info
左边的图边界比较复杂,这也意味着泛化能力更弱,右边的图比较精简,泛化能力较强。一般会选择泛化能力较强的。
:::
参考链接
https://blog.csdn.net/weixin_44010678/article/details/87016753
- https://blog.csdn.net/v_july_v/article/details/7624837


若有收获,就点个赞吧
0 人点赞
