实现OCR,关键的并不是在于Python,而是在于后端实现部分,在这个过程中Python只是作为一种串通不同模块的一个工具,你同样也可以使用JS、php、Java等语言把一款ocr工具流程打通。
既然题目提到了使用Python,那么这里就介绍使用Python实现ocr的方式,介绍3种方式,
- 调用API
- 调用后端服务
- 直接使用算法模型
-
调用API
OCR作为当下非常热门且在现实生活中较为常用的一个领域,在OCR方面的研究自然是非常多的。目前提供OCR API调用的网站有很多,但是绝大多数都是收费的,这个也能理解,别人提供调用,需要很大的服务资源支撑,毕竟都要吃饭嘛。
但是,也的确会有一些非常良心的平台,直接提供免费的API调用,下面就介绍2个较为不错的提供免费OCR API调用的平台,
1. ocr.space
ocr.space免费版每个月限制25000次请求,每天限制500次,如果个人或者团队内小范围使用,这个数量是可以满足的。但是,如果希望搭建一个平台供大众使用,这显然是远远不够的。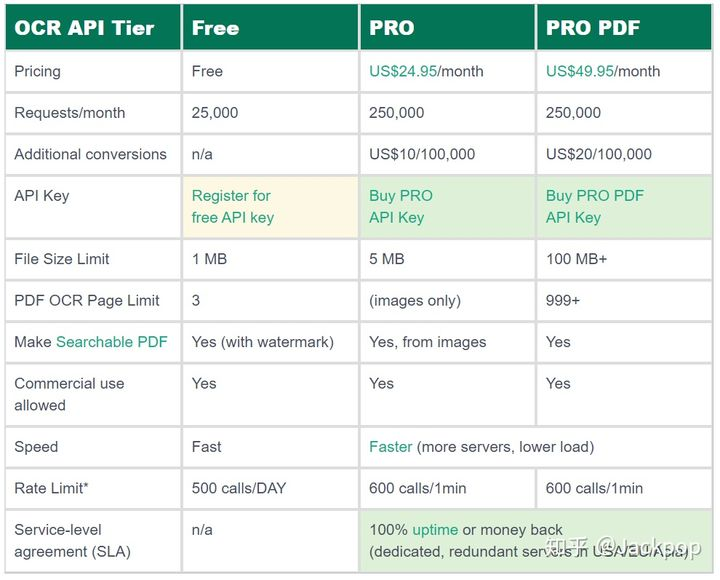
2. 百度OCR
百度智能云提供的OCR API覆盖范围更加全面,且免费额度也更高一下,它主要覆盖如下场景, 通用文字识别
- 卡证文字识别
- 票据文字识别
- 汽车场景文字识别
- 教育场景文字识别
以通用文字识别为例,它每天提供高达50000次免费调用额度。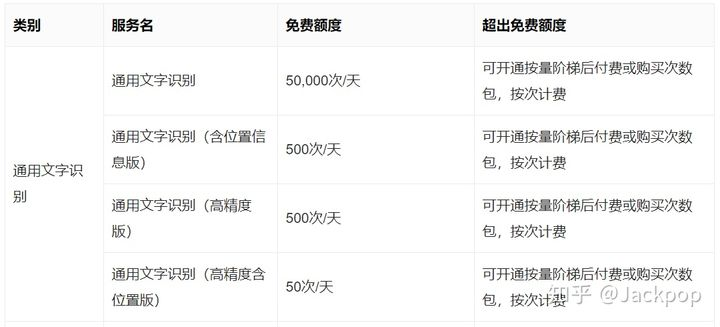
详细的情况可以点击下方链接查看,
https://cloud.baidu.com/doc/OCR/s/fk3h7xu7hcloud.baidu.com/doc/OCR/s/fk3h7xu7h
Python如何实现API的调用呢?
在API调用方面,上述两个平台提供的调用方式都是以post方式进行调用,也就是说以rest接口与平台进行交互,对编程语言不敏感,你可以使用Java、php、js任何语言,只要能够发送post请求获取结果就好,下面就以Python调用ocr.space接口为例进行介绍一下。
由于ocr.space对接口以及进行了封装,所以调用非常简单,只需要下面几步,
- 注册API Key
- 使用requests post请求
注册API Key
可以通过下面链接注册API Key,
https://us11.list-manage.com/subscribe?u=ce17e59f5b68a2fd3542801fd&id=252aee70a1us11.list-manage.com/subscribe?u=ce17e59f5b68a2fd3542801fd&id=252aee70a1
发送请求
我们把api_key、语言等 一些必要参数写到一个字典里,然后使用requests这个库发送post请求即可获取ocr识别结果。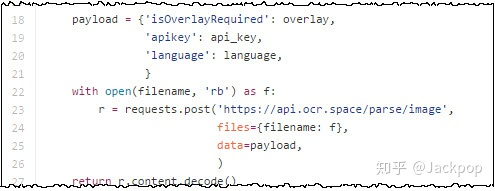
调用后端服务
调用API是最为简单的一种方式,我们不需要去关注后端及中间数据传输的过程,只需要填写一下api_key即可,简短的几行代码就可以实现。这里我再来介绍一款进阶的方式,需要如果需要使用,需要自己做进一步的封装和完善。
这里要介绍的就是tessearct,它是基于Apache许可证开源的OCR识别引擎,在2006年由Google赞助开发,被认为是当下最为优秀的OCR引擎之一,由C++实现,目前在Github已经高达33.5k个Star。
它具有支持语言丰富、识别速度快、准确率高等优点,官方提供的调用方式是使用命令行进行调用,
tesseract imagename outputbase [-l lang] [—oem ocrenginemode] [—psm pagesegmode] [configfiles…]
也就是说,tesseract作为一个核心的算法实现模块,但是没有外壳进行包装,我们想要使用的话不如很多平台或者工具那样那么方便。
它缺少的就是一个UI或者web。
因此,我们可以把tesseract作为一个后端服务,利用Python实现服务层的开发和交互层的开发。
首先在服务器启动tesseract服务,然后,使用Python tkinter实现一个UI,然后基于flask、requests等第三方库实现数据传输和发送rest请求,调用后端的tesseract服务,执行上述命令,然后返回结果到前端即可。
直接使用算法模型
OCR (Optical Character Recognition,光学字符识别),它主要依托的核心技术就是图像识别、自然语言模型。因此,我们也可以不去调用ocr.space的API接口或者tesseract的后端服务,可以直接使用最为底层的计算机视觉、自然语言模型进行OCR文字识别。
这里,我推荐一个github开源项目darknet-ocr,它基于darknet(https://github.com/pjreddie/darknet.git)框架实现CTPN版本自然场景文字检测 与CNN+CTCOCR进行文字识别,目前在github有480+个star。
这是一种最为简洁明了、对Python最为依赖的一种方式,也是端到端实现OCR系统较为完善的一种方式。
但是,darknet-ocr是在darknet源码的基础上 进行编译实现的,它整体上和前面介绍的tesseract没有什么差别,只是更加完整的实现了一个ocr系统。
如果想对ocr识别的过程中更加清晰的认识,可以看一下darknet-ocr这个项目的前身chineseocr,它是于yolo3 与crnn 实现中文自然场景文字检测及识别,在这个项目中,你可以看到模型的导入,语言模型和CV模型的应用过程。当然,如果感兴趣可以对模型进行重新训练或者进一步优化,这对比于前两种方式的好处就是定制化、扩展能力方面都较为灵活。
darknet-ocr和chineseocr都是在训练好的模型基础上已经搭建成了完整的ocr系统,如果觉得这些还不足够锻炼自己,那么可以从数据准备到模型训练全流程手动完成一个ocr系统,这样就需要如下几个阶段,
- 准备数据
- 选取CNN+RNN模型
- 模型训练及调优
- 结果输出
调用第三方库
我想这应该是选择使用Python开发一个ocr工具的同学最喜闻乐见的方式。
Python比较吸引人的一点就是有丰富的第三方库,图像、数据、机器学习、优化算法、图、UI…….你能想到的,Python可能都会找到第三方库,ocr也不例外。
这里要推荐的库就是pytesseract,你可以像调用numpy、matplotlib、tensorflow那样直接在Python代码中调用pytesseract,实现图像文字的识别。
安装
pip install pytesseract
示例
from PIL import Image import pytesseract pytesseract.pytesseract.tesseractcmd = r’
依赖
pytesseract支持Python 2.7或者3.5+,需要用到PIL或者pillow。这里比较重要的是,还需要安装tesseract后端引擎。
其实,虽然使用了pytesseract库,但是它和前面介绍的调用后端服务大同小异,只不过在上面封装了一层对Python的支持。由于tesseract是最为成功的ocr识别程序之一,所以它对php、Python等语言都有支持的模块,但是无论是哪种语言,真正起作用的还是后端的识别引擎,依然脱离不了tesseract。
因此,在使用pytesseract之前,需要在windows、Linux或者mac上安装tesseract。

若有收获,就点个赞吧
0 人点赞
