应用层
HTTP
HTTP请求结构?
HTTP头部本质上是一个传递额外重要信息的键值对。主要分为
- 通用头部
- 请求头部 | 响应头部
- 实体头部
get和post的区别?
Get 方法的含义是请求从服务器获取资源,这个资源可以是静态的文本、⻚面、图片视频等。
而 POST 方法则是相反操作,它向 URI 指定的资源提交数据,数据就放在报文的 body 里。
GET 和 POST 方法都是安全和幂等的吗?
先说明下安全和幂等的概念:
- 在 HTTP 协议里,所谓的「安全」是指请求方法不会「破坏」服务器上的资源。
- 所谓的「幂等」,意思是多次执行相同的操作,结果都是「相同」的。
那么很明显 GET 方法就是安全且幂等的,因为它是「只读」操作,无论操作多少次,服务器上的数据都是安全 的,且每次的结果都是相同的。
POST 因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多 个资源,所以不是幂等的。
HTTP的缓存机制
HTTP底层基于什么协议?
HTTP底层除了TCP和UDP还能用什么协议?
HTTP2.0的服务器推送具体怎么实现?
HTTP1.0、1.1、2.0和3.0的区别。
1.1和1.0的区别
- 缓存处理
- 节约带宽:1.1请求头中引入了range头域,它允许只请求部分资源。
- 错误通知的管理:新增了24个错误状态响应码。
- Host请求头:
- 长连接
2.0和1.X的区别
- 相比于1.X的文本(字符串)传送,2.0采用二进制传送,同时有优先级。
- 多路复用
- 头部压缩
- 服务器推送
HTTPS
HTTP 与 HTTPS 有哪些区别?
- HTTP 是超文本传输协议,信息是明文传输,存在安全⻛险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
- HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之 后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- HTTP 的端口号是 80,HTTPS 的端口号是 443。
HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
HTTPS 解决了 HTTP 的哪些问题?
HTTP 由于是明文传输,所以安全上存在以下三个⻛险:
窃听⻛险,比如通信链路上可以获取通信内容,用户号容易没。
- 篡改⻛险,比如强制植入垃圾广告,视觉污染,用户眼容易瞎。
- 冒充⻛险,比如冒充淘宝网站,用户钱容易没。
HTTPS 在 HTTP 与 TCP 层之间加入了 SSL/TLS 协议,可以很好的解决了上述的⻛险:
- 信息加密:交互信息无法被窃取,但你的号会因为「自身忘记」账号而没。
- 校验机制:无法篡改通信内容,篡改了就不能正常显示,但百度「竞价排名」依然可以搜索垃圾广告。
身份证书:证明淘宝是真的淘宝网,但你的钱还是会因为「剁手」而没。
HTTPS 是如何解决上面的三个⻛险的?
混合加密的方式实现信息的机密性,解决了窃听的⻛险。 摘要算法的方式来实现完整性,它能够为数据生成独一无二的「指纹」,指纹用于校验数据的完整性,解决
了篡改的⻛险。 将服务器公钥放入到数字证书中,解决了冒充的⻛险。
非对称加密
公钥和私匙
先有私钥,再用函数生成公钥。公钥包含了私钥的信息,但也掺杂了其他随机变量,因此不能反推。
私匙不要泄露,公钥要告诉和你通信的对方。
公钥加密,只有对应私钥能解开(保密);
私钥加密,只有对应公钥能解开(不可抵赖)。
具体有两种情形:
(1)对方用你的公钥加密信息,你收到后用私钥解开。
只有你有私钥,所以只有你能解开,换句话说,有私钥才能看到信息,很安全。
(2)你拿私钥加密信息,对方收到后用你的公钥解开。
公钥是公开的,所以其他人也可以看到你的信息,不保密。
私钥加密,只有对应公钥能解开。既然用你的公钥能解开,说明加密一定是你的私钥。私钥只有你有,所以一定是你发送的,你不可抵赖。
对称加密
加密和解密都用一个密钥。
HTTPS的握手(加密)过程?
两个过程:
- TCP三次握手
- TLS握手
- 和http一样,首先要建立tcp的三次握手,具体细节参考TCP三次握手和四次挥手
- 当客户端请求服务端时,首先服务端会返回一个证书给客户端,客户端拿到证书后,去验证证书的有效性,无效的话会弹出一个警告框,如果有效,则生成一个随机值R1(对称密钥的值),然后利用证书上的公钥加密随机值发给服务端,服务端收到请求后用私钥进行解密,注意这一步是采用非对称加密,此时服务端获取到了客户端的对称密钥的值,然后用对称加密加密信息发送给客户端,客户端收到后,用一开始对称密钥R1解密信息。
为什么TLS握手过程中使用两种加密方式?
因为使用非对称加密客户端和服务端是非常耗时耗资源的,这样一来性能就会很差,通过非对称加密交换对称加密的密钥,后续的传输过程也是安全可靠的。
HTTPS一般使用的加密与HASH算法如下:
非对称加密算法:RSA,DSA/DSS
对称加密算法:AES,RC4,3DES
HASH算法:MD5,SHA1,SHA256
DNS
传输层
三次握手和四次挥手?
CLOSE_WAIT和TIME_WAIT的状态和意义?
TIME_WAIT的作用?为什么要有it?
你可能会问,为什么不直接进入 CLOSED 状态,而要停留在 TIME_WAIT 这个状态?
- 让旧的TCP 报文得以自然消失,
- 同时为了让被动关闭方能够正常关闭;
首先,这样做是为了确保最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭。
第二个理由和连接“化身”和报文迷走有关系,为了让旧连接的重复分节在网络中自然消失。
TIME_WAIT为什么是2MSL?
为的是确认服务器能否接收到客户端发出的ACK确认报文。
MSL
最长分节生命期 MSL(maximum segment lifetime),指一段TCP报文在传输过程中的最大声明周期
和大多数 BSD 派生的系统一样,Linux 系统里有一个硬编码的字段,名称为TCP_TIMEWAIT_LEN,其值为 60 秒。也就是说,Linux 系统停留在 TIME_WAIT 的时间为固定的 60 秒。
TIME_WAIT的危害?
- 内存资源的占用,这个目前看来不是太严重,基本可以忽略。
- 端口资源的占用,一个 TCP 连接至少消耗一个本地端口。要知道,端口资源也是有限的,一般可以开启的端口为 32768~61000 ,也可以通过net.ipv4.ip_local_port_range指定,如果 TIME_WAIT 状态过多,会导致无法创建新连接。这个也是我们在一开始讲到的那个例子。
TCP是如何保证可靠性的?
校验
序号:
确认应答
重传机制
流量控制和拥塞控制。
TCP 是通过序列号、确认应答、发控制、连接管理以及窗口控制等机制实现可靠性传输的。
- 序列号、确认应答和超时重传
- 窗口控制和重复确认应答
- 拥塞控制
数据到达接收方后,接收方需要发出一个确认应答,表示已经收到该数据段。并且确认序号会说明它下一次需要接收的数据序列号。如果发送发迟迟为收到确认应答,那么可能是发送的数据丢失,也可能是确认应答丢失,这时候发送发在等待一定时间后会进行超时重传。这个时间一般是2*RTT(报文往返时间)+一个偏差值。
TCP会利用窗口控制来提高传输速度,意思是在一个窗口大小内,不一定要等到应答才能发送下一段数据,窗口大小就是无需等待确认而可以继续发送数据的最大值。(累计确认吧这是)
什么是拥塞控制?
如果把窗口定的很大,发送端连续发送大量的数据,可能会造成网络的拥堵,所以TCP为了防止这种情况而进行了拥塞控制。
- 慢启动:定义拥塞窗口,窗口大小初值为1,之后每收到一个确认应答(经过一个RTT),便将拥塞窗口大小*2.
- 拥塞避免:设置满启动阈值,一般开始都设为65536(2^16).拥塞避免是指当拥塞窗口大小达到这个阈值时,拥塞窗口大小不再指数上升,而是加法增加(每个确认应答,拥塞窗口大小+1),以此来避免拥塞。
- 快重传和快恢复:是对满开始和拥塞避免算法的改进。
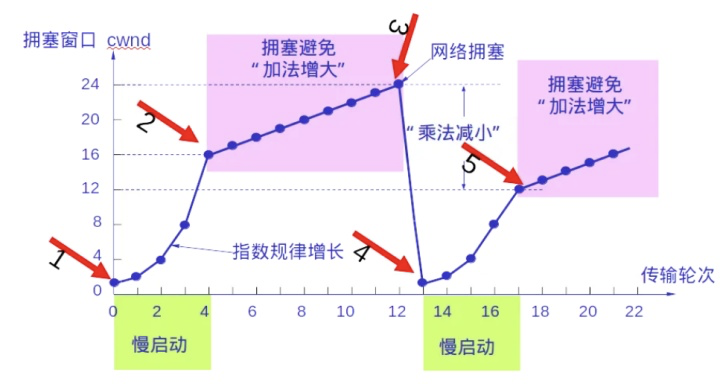
快重传
在上一节介绍的 TCP 可靠传输机制中,快重传技术使用了冗余 ACK 来检测丟包的发生。同样,用冗余ACK 也用于网络拥塞的检测(丢了包当然意味着网络可能出现了拥塞)。快重传并非取消重传计时器,而是在某些情况下可更早地重传丢失的报文段。
当发送方连续收到三个重复的 ACK 报文时,直接重传对方尚未收到的报文段,而不必等待
那个报文段设置的重传计时器超时。
快恢复
快恢复算法的原理如下:当发送方连续收到三个冗余 ACK(即重复确认)时,执行 “乘法减小”算法,把慢开始门限 ssthresh 设置为此时发送方 cwnd 的一半。这是为了预防网络发生拥塞。但发送方现在认为网络很可能没有发生(严重)拥塞,否则就不会有几个报文段连续到达接收方,也不会连续收到重复确认。因此与慢开始不同之处是它把 owad 值设置为慢开始门限 ssthresh 改变后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口绥慢地线性增大。由于跳过了拥塞窗口cwnd 从1起始的馒开始过程,所以被称为快恢复。快恢复算法的实现过程如图 5.12 所示,作为对比,虛线为慢开始的处理过程。
拥塞控制与流量控制的区别?
拥塞控制是让网络能够承受现有的网络负荷,是一个全局性的过程,涉及所有的主机、所有的路由器,以及与降低网络传输性能有关的所有因素。
相反,流量控制往往是指点对点的通信量的控制,是个端到端的问题(接收端控制发送端),它所要做的是
抑制发送端发送数据的速率,以便使接收端来得及接收。
当然,拥塞控制和流量控制也有相似的地方,即它们都通过控制发送方发送数据的速率来达到控制效果。
网络层
IP
HTTP协议:
HTTP 协议的基本知识,
- 报文结构
- 请求头
- 响应头
- 内部的请求方法、
- URI
- 状态码
标准请求方法(HTTP/1.1 规定了八种方法)
- GET:获取资源,可以理解为读取或者下载数据;
- HEAD:获取资源的元信息;
- POST:向资源提交数据,相当于写入或上传数据;
- PUT:类似 POST;(update)
- DELETE:删除资源;
- CONNECT:建立特殊的连接隧道;
- OPTIONS:列出可对资源实行的方法;
- TRACE:追踪请求 - 响应的传输路径。

若有收获,就点个赞吧
0 人点赞
