资源规划
| 组件 | LTSR003 | LTSR005 | LTSR006 | LTSR007 | LTSR008 |
|---|---|---|---|---|---|
| OS | centos7.6 | centos7.6 | centos7.6 | centos7.6 | centos7.6 |
| JDK | jvm | jvm | jvm | jvm | jvm |
| HDFS | DataNode/HTTPFS | DataNode/HTTPFS | DataNode/HTTPFS | DataNode/HTTPFS | NameNode/DataNode/HTTPFS |
| YARN | NodeManager | NodeManager | NodeManager | NodeManager | ResourceManager/NodeManager/mr-jobhistory |
| Spark | Slave | Master History Server |
N.A | Slave | N.A |
安装介质
版本:spark-2.2.0-bin-hadoop2.7.tgz
下载:https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
注意:安装Spark要下载与Hadoop对应的版本(这里Hadoop使用2.7版本)。
环境准备
安装JDK
参考:《 CentOS7.6-安装JDK-1.8.221 》
安装Hadoop
安装Zookeeper
安装Spark
可以直接在客户端下载安装包,上传至服务器。此时可以省略下面第一步。
(1) .下载安装包
cd ~/software/wget https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
(2) .解压
tar -zxvf ~/software/spark-2.2.0-bin-hadoop2.7.tgz -C ~/modules/
(3) .配置
- 修改配置文件
spark-env.sh以指定运行参数
进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
cd ~/modules/spark-2.2.0-bin-hadoop2.7/conf/ cp spark-env.sh.template spark-env.sh vi spark-env.sh将以下内容复制进配置文件末尾 ```
指定 Java Home
export JAVA_HOME=/home/bigdata/modules/jdk1.8.0_221
指定 Spark Master 地址
export SPARK_MASTER_HOST=LTSR005 export SPARK_MASTER_PORT=7077
2. 修改配置文件 `slaves`, 以指定从节点为止, 从在使用 `sbin/start-all.sh` 启动集群的时候, 可以一键启动整个集群所有的 Worker
- 进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
```bash
cd ~/modules/spark-2.2.0-bin-hadoop2.7/conf/
cp slaves.template slaves
vi slaves
- 配置所有从节点的地址
LTSR003 LTSR007
- 配置
HistoryServer
- 默认情况下, Spark 程序运行完毕后, 就无法再查看运行记录的 Web UI 了, 通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程
复制
spark-defaults.conf, 以供修改cd ~/modules/spark-2.2.0-bin-hadoop2.7/conf/ cp spark-defaults.conf.template spark-defaults.conf vi spark-defaults.conf将以下内容复制到
spark-defaults.conf末尾处, 通过这段配置, 可以指定 Spark 将日志输入到 HDFS 中spark.eventLog.enabled true spark.eventLog.dir hdfs://LTSR008:9000/spark_log spark.eventLog.compress true将以下内容复制到
spark-env.sh的末尾, 配置 HistoryServer 启动参数, 使得 HistoryServer 在启动的时候读取 HDFS 中写入的 Spark 日志vi spark-env.sh # 指定 Spark History 运行参数 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://LTSR008:9000/spark_log"为 Spark 创建 HDFS 中的日志目录
hdfs dfs -mkdir -p /spark_log(4) .分发
cd ~/modules/ scp -r spark-2.2.0-bin-hadoop2.7/ bigdata@LTSR003:$PWD scp -r spark-2.2.0-bin-hadoop2.7/ bigdata@LTSR007:$PWD启动Spark集群
启动 Spark Master 和 Slaves, 以及 HistoryServer
cd ~/modules/spark-2.2.0-bin-hadoop2.7/ sbin/start-all.sh sbin/start-history-server.sh访问入口:http://LTSR005:8080/
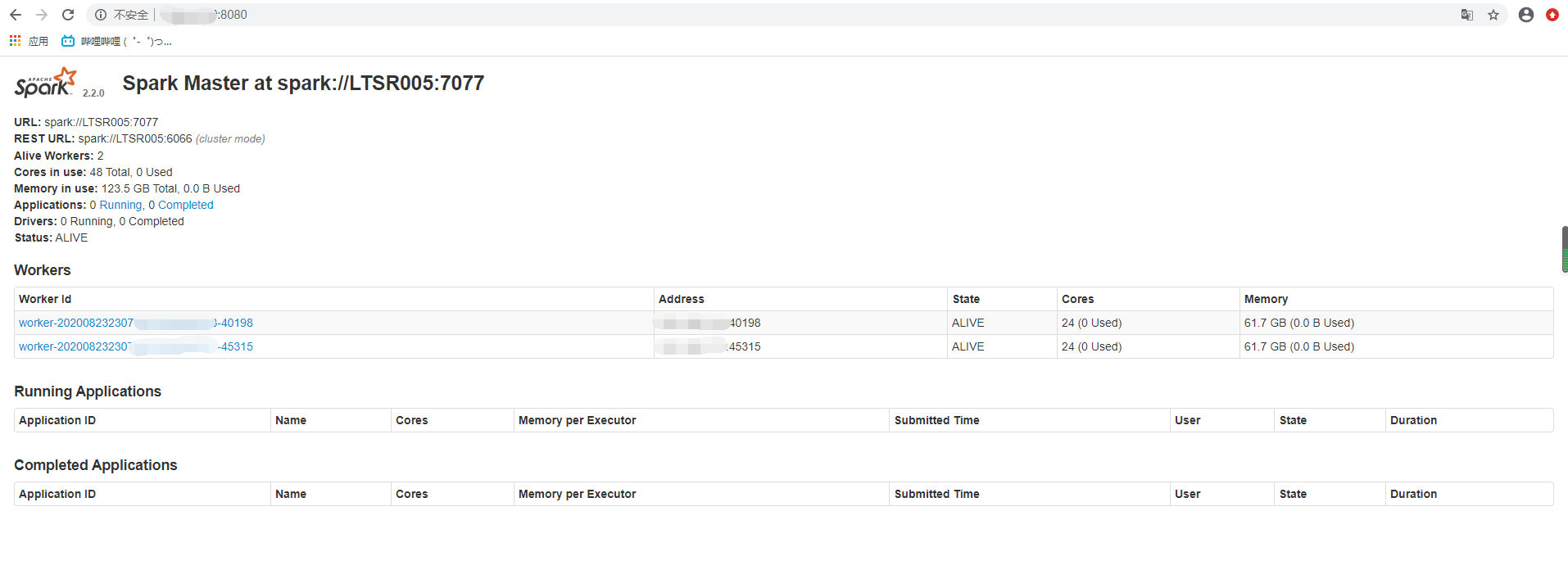
- 各服务端口 | Master WebUI | LTSR005:8080 | | —- | —- | | Worker WebUI | LTSR003:8081 | | History Server | LTSR005:4000 |
配置高可用
对于 Spark Standalone 集群来说, 当 Worker 调度出现问题的时候, 会自动的弹性容错, 将出错的 Task 调度到其它 Worker 执行。但是对于 Master 来说, 是会出现单点失败的, 为了避免可能出现的单点失败问题, Spark 提供了两种方式满足高可用:
- 使用 Zookeeper 实现 Masters 的主备切换
- 使用文件系统做主备切换
而使用文件系统做主备切换的场景实在太小,不作考虑 。
步骤:
停止集群:
cd ~/modules/spark-2.2.0-bin-hadoop2.7/ sbin/stop-all.sh修改配置文件, 增加 Spark 运行时参数, 从而指定 Zookeeper 的位置
进入
spark-env.sh所在目录, 打开 vi 编辑cd ~/modules/spark-2.2.0-bin-hadoop2.7/conf/ vi spark-env.sh编辑
spark-env.sh, 添加 Spark 启动参数, 并去掉 SPARK_MASTER_HOST 地址

# 指定 Spark 运行时参数
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=LTSR005:2181,LTSR006:2181,LTSR007:2181 -Dspark.deploy.zookeeper.dir=/spark"
分发配置文件到集群
scp -r spark-env.sh LTSR003:$PWD scp -r spark-env.sh LTSR007:$PWD启动
在LTSR005上启动整个集群
cd ~/modules/spark-2.2.0-bin-hadoop2.7/ sbin/start-all.sh sbin/start-history-server.sh在LTSR003上单独启动一个Master
sbin/start-master.sh分别查看WebUI
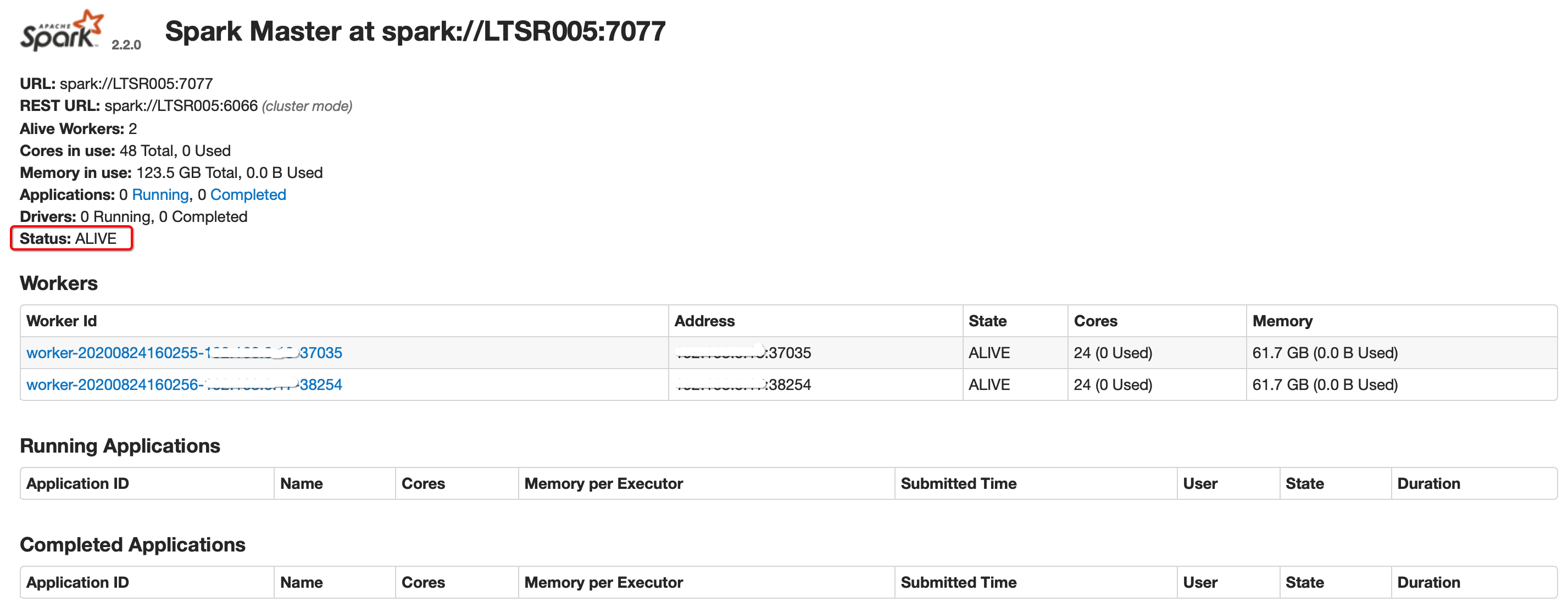
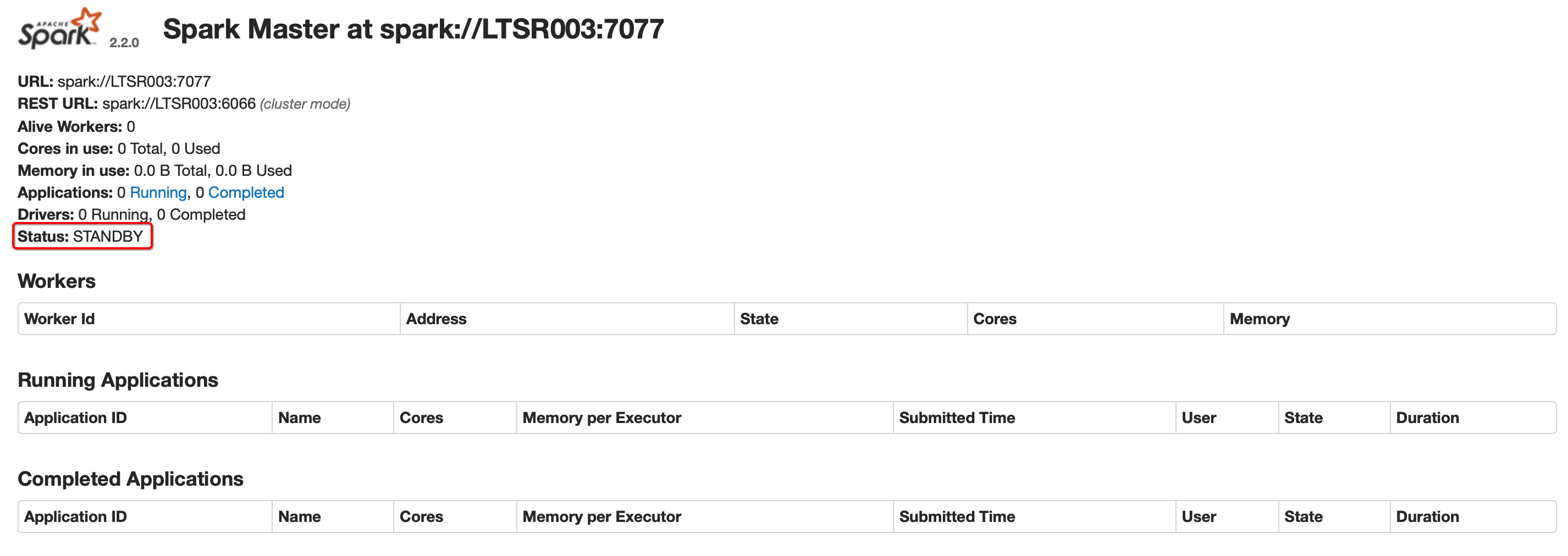
关闭LTSR005的master
cd ~/modules/spark-2.2.0-bin-hadoop2.7/ sbin/stop-master.sh
刷新LTSR003 WebUI(约1-2分钟)
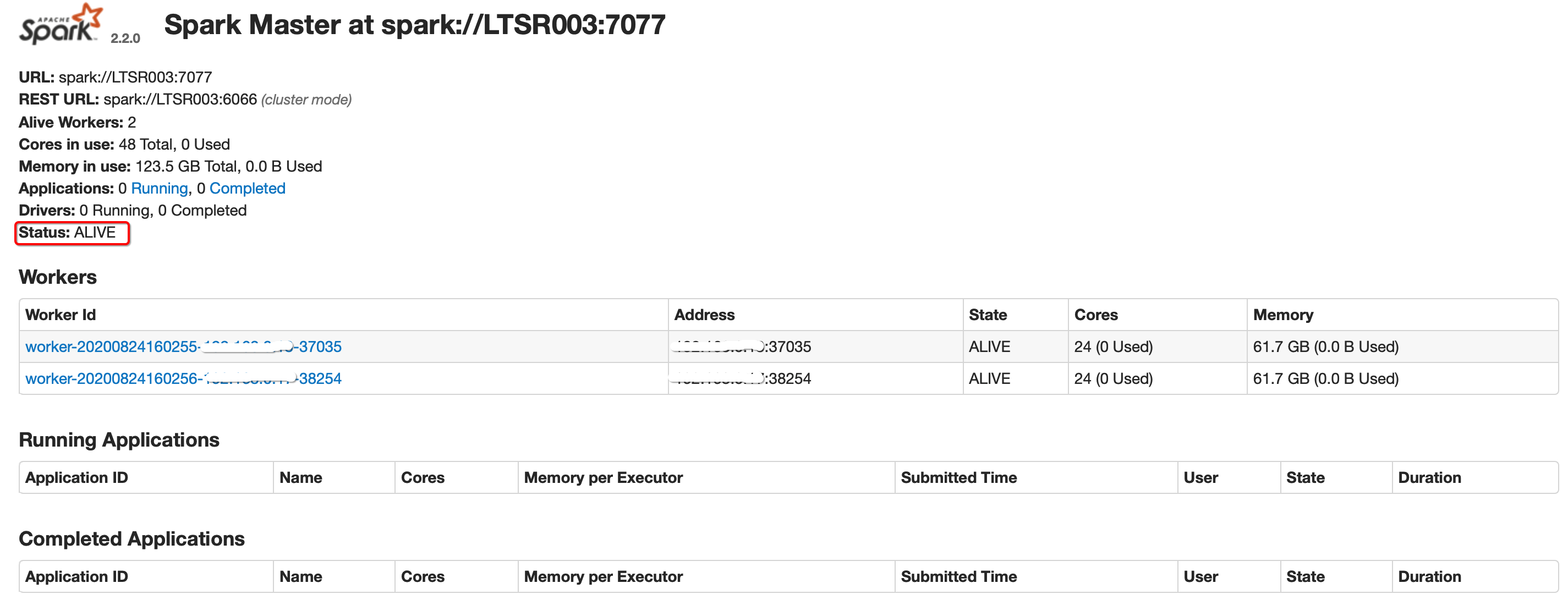
第一个应用程序
cd ~/modules/spark-2.2.0-bin-hadoop2.7/
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://LTSR005:7077,LTSR003:7077,LTSR007:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/home/bigdata/modules/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar \
100
结果
[bigdata@ltsr005 spark-2.2.0-bin-hadoop2.7]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master spark://LTSR005:7077,LTSR003:7077,LTSR007:7077 \
> --executor-memory 1G \
> --total-executor-cores 2 \
> /home/bigdata/modules/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar \
> 100
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/08/23 23:45:01 INFO SparkContext: Running Spark version 2.2.0
20/08/23 23:45:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/08/23 23:45:02 INFO SparkContext: Submitted application: Spark Pi
20/08/23 23:45:02 INFO SecurityManager: Changing view acls to: bigdata
20/08/23 23:45:02 INFO SecurityManager: Changing modify acls to: bigdata
20/08/23 23:45:02 INFO SecurityManager: Changing view acls groups to:
20/08/23 23:45:02 INFO SecurityManager: Changing modify acls groups to:
...
20/08/23 23:45:07 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
20/08/23 23:45:07 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 1.662 s
20/08/23 23:45:07 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.920289 s
Pi is roughly 3.1414895141489514
20/08/23 23:45:07 INFO SparkUI: Stopped Spark web UI at http://****:4040
20/08/23 23:45:08 INFO StandaloneSchedulerBackend: Shutting down all executors
20/08/23 23:45:08 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down
20/08/23 23:45:08 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/08/23 23:45:08 INFO MemoryStore: MemoryStore cleared
20/08/23 23:45:08 INFO BlockManager: BlockManager stopped
20/08/23 23:45:08 INFO BlockManagerMaster: BlockManagerMaster stopped
20/08/23 23:45:08 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/08/23 23:45:08 INFO SparkContext: Successfully stopped SparkContext
20/08/23 23:45:08 INFO ShutdownHookManager: Shutdown hook called
20/08/23 23:45:08 INFO ShutdownHookManager: Deleting directory /tmp/spark-8937c5ae-8011-46b5-9ac9-8a22668052a6
[bigdata@ltsr005 spark-2.2.0-bin-hadoop2.7]$

若有收获,就点个赞吧
0 人点赞
