一,创建节点
插入
下面的Cypher查询创建一个节点,标签是Person,具有两个属性name和born,通过RETURN子句,返回新建的节点
create (n:Person { name: ‘Tom Hanks’, born: 1956 }) return n;
二,查询节点
1.查询born属性小于1955的节点
match(n) where n.born<1955 return n;
三,创建关系
1.创建没有任何属性的关系
MATCH (a:Person),(b:Movie)
WHERE a.name = ‘Robert Zemeckis’ AND b.title = ‘Forrest Gump’
CREATE (a)-[r:DIRECTED]->(b)
RETURN r;
2.创建关系,并设置关系的属性
MATCH (a:Person),(b:Movie)
WHERE a.name = ‘Tom Hanks’ AND b.title = ‘Forrest Gump’
CREATE (a)-[r:ACTED_IN { roles:[‘Forrest’] }]->(b)
RETURN r;
四,查询关系
1.查询跟指定节点有关系的节点,与电影节点(m)相关的节点n有哪些
2.查询有向关系的节点
MATCH (:Person { name: ‘Tom Hanks’ })—>(movie)
RETURN movie;
返回Tom Hanks演的电影节点
3.为关系命名,通过[r]为关系定义一个变量名,通过函数type获取关系的类型
MATCH (:Person { name: ‘Tom Hanks’ })-[r]->(movie)
RETURN r,type(r);
结果:
返回Tom Hanks 在电影节点中的扮演角色属性等(r:关系的所有属性),及和电影关系的名称(type(r):关系的名称)
4.查询特定的关系类型,通过[Variable:RelationshipType{Key:Value}]指定关系的类型和属性
MATCH (:Person { name: ‘Tom Hanks’ })-[r:ACTED_IN{roles:’Forrest’}]->(movie)
RETURN r,type(r);
和上述查询结果相同
五,更新图形
set子句,用于对更新节点的标签和实体的属性;remove子句用于移除实体的属性和节点的标签;
1、创建一个完整的Path
由于Path是由节点和关系构成的,当路径中的关系或节点不存在时,Neo4j会自动创建;
CREATE p =(vic:Worker:Person{ name:’vic’,title:”Developer” })-[:WORKS_AT]->(neo)<-[:WORKS_AT]-(michael:Worker:Person { name: ‘Michael’,title:”Manager” })
RETURN p
结果:
变量neo代表的节点没有任何属性,但是,其有一个ID值,通过ID值为该节点设置属性和标签
2、为节点增加属性
match (n)
where id(n)=7
set n.name = ‘neo’
return n;
3、为节点增加标签
match (n)
where id(n)=7
set n:Company
return n;
六,跟实体相关的函数
跟实体相关的函数,主要是获取节点或关系的ID,关系类型,标签和属性等函数。
1、通过id函数,返回节点或关系的ID
MATCH (:Person { name: ‘Oliver Stone’ })-[r]->(movie)
RETURN id(r);
2、通过type函数,查询关系的类型
MATCH (:Person { name: ‘Oliver Stone’ })-[r]->(movie)
RETURN type(r);
3、通过lables函数,查询节点的标签
MATCH (:Person { name: ‘Oliver Stone’ })-[r]->(movie)
RETURN lables(movie);
4、通过keys函数,查看节点或关系的属性键
MATCH (a)
WHERE a.name = ‘Alice’
RETURN keys(a)
5、通过properties()函数,查看节点或关系的属性
CREATE (p:Person { name: ‘Stefan’, city: ‘Berlin’ })
RETURN properties(p)
七,模式
模式,用于描述如何搜索数据,模式的格式是:使用()标识节点,使用[]标识关系,为了更有效地使用Cypher查询,必须深入理解模式。
1、节点模式
节点具有标签和属性,Cypher为了引用节点,需要给节点命名:
- (n) :该模式用于描述节点,节点的变量名是n;匿名节点是();
- (n:lable):该模式用于描述节点,节点具有特定的标签lable;也可以指定多个标签;
- (n{name:”Vic”}):该模式用于描述节点,节点具有name属性,并且name属性值是“Vic”;也可以指定多个属性;
(n:lablle{name:”Vic”}):该模式用于描述节点,节点具有特定的标签和name属性,并且name属性值是“Vic”;
2、关系模式
在属性图中,节点之间存在关系,关系通过[]表示,节点之间的关系通过箭头()-[]->()表示,例如:
[r]:该模式用于描述关系,关系的变量名是r;匿名关系是[]
- [r:type]:该模式用于描述关系,关系类型是type;每一个关系必须有且仅有一个类型;
[r:type{name:”Friend”}]:该模式用于描述关系,关系的类型是type,关系具有属性name,并且name属性值是“Friend”;
3、关联节点模式
节点之间通过关系联系在一下,由于关系具有方向性,因此,—>表示存在有向的关系,—表示存在关联,不指定关系的方向,例如:
(a)-[r]->(b) :该模式用于描述节点a和b之间存在有向的关系r,
-
4、变长路径的模式
从一个节点,通过直接关系,连接到另外一个节点,这个过程叫遍历,经过的节点和关系的组合叫做路径(Path),路径是由节点和关系的有序组合。
(a)—>(b):是步长为1的路径,节点a和b之间有关系直接关联;
- (a)—>()—>(b):是步长为2的路径,从节点a,经过两个关系和一个节点,到达节点b;
Cypher语言支持变长路径的模式,变长路径的表示方式是:[*N..M],N和M表示路径长度的最小值和最大值。
- (a)-[*2]->(b):表示路径长度为2,起始节点是a,终止节点是b;
- (a)-[*3..5]->(b):表示路径长度的最小值是3,最大值是5,起始节点是a,终止节点是b;
- (a)-[*..5]->(b):表示路径长度的最大值是5,起始节点是a,终止节点是b;
- (a)-[*3..]->(b):表示路径长度的最小值是3,起始节点是a,终止节点是b;
- (a)-[*]->(b):表示不限制路径长度,起始节点是a,终止节点是b;
5、路径变量
路径可以指定(assign)给一个变量,该变量是路径变量,用于引用查询路径。
p = (a)-[*3..5]->(b)6、示例
以下示例图有6个节点,每个节点都有一个属性name,节点之间存在关系,关系类型是KNOWS,如图: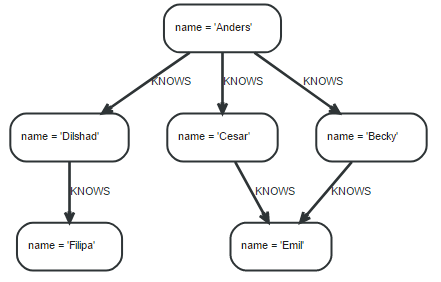
查询模式是:查找跟Filipa有关系的人,路径长度为1或2,查询的结果是:”Dilshad”和”Anders”
MATCH (me)-[:KNOWS*1..2]-(remote_friend)
WHERE me.name = ‘Filipa’
RETURN remote_friend.name
八、索引
1、内置索引
对于标签的的属性添加索引
1.创建索引:
CREATE INDEX ON :Person(name)
组合索引
CREATE INDEX ON :Person(age, country)
2.删除索引:
DROP INDEX ON : Person(name)
2、全文索引:对节点和关系添加索引
创建全文索引:
CALL db.index.fulltext.createNodeIndex(“titlesAndDescriptions”,[“Movie”, “Book”],[“title”, “description”])
对标签为”Movie”, “Book”,属性”title”, “description” 创建名为titlesAndDescriptions 的全文索引
索引使用 属性使用 > 是走索引的,跟 in 也是走索引
在where条件后面,
参考:https://www.cnblogs.com/ljhdo/p/5516793.html
**

若有收获,就点个赞吧
0 人点赞
