参考
知识点
为什么L1正则化具有稀疏性?
- 定量解释:一维情况下
 ,其中
,其中  是目标函数,
是目标函数,  是原始目标函数,
是原始目标函数,  是L1正则项。要使0点成为可能的最值点,虽然在0点不可导,但是我们只需要让0点左右的导数异号,即
是L1正则项。要使0点成为可能的最值点,虽然在0点不可导,但是我们只需要让0点左右的导数异号,即  即可。也就是
即可。也就是  的情况下,0点都是可能的最值点。
的情况下,0点都是可能的最值点。 - 概率解释:L1正则化等价于参数服从拉普拉斯分布,该分布在0点的概率很大。
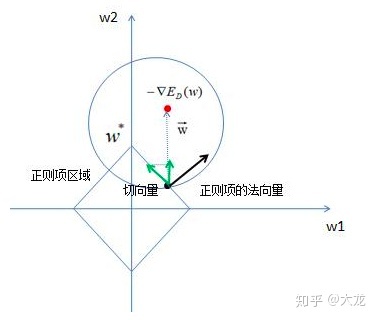
- 几何解释:如下图所示,这里只考虑负梯度方向在w2上的投影为正的情况,负的情况分析方法是相同的。w点靠着负梯度的力量,沿着边界斜线运动时,能时损失函数减小,运动到顶点w时,不能再继续运动了,因此w就是最小值点。可见在L1正则项约束下,w2=0或w1=0很容易成为最小值点,因此说L1正则化具有稀疏性。
为什么L2正则化可以减小参数值?
- 概率解释:L2正则化等价于参数服从高斯分布,数值集中在[-σ,σ]之间。
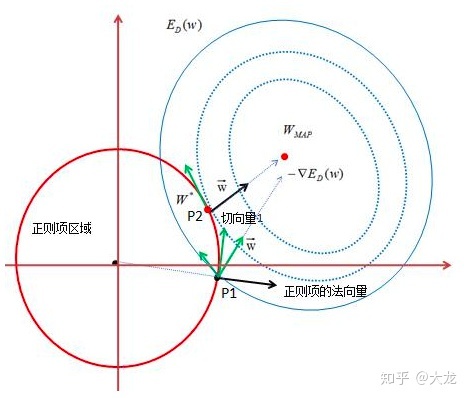
- 几何解释:如下图所示,P1点靠着负梯度的力量,沿着正则项边界滑动,能使损失函数不断减小,并在负梯度垂直于正则项边界的P2点,达到最小值。P2点相比于等高点上的其它点,参数值的平方和更小,因此说L2正则化能减小参数值。
为什么正则化可以降低过拟合?

若有收获,就点个赞吧
0 人点赞
