[注:本文学自Java业务开发常见错误100例**](https://time.geekbang.org/column/intro/100047701?utm_campaign=guanwang&utm_source=baidu-ad&utm_medium=ppzq-pc&utm_content=title&utm_term=baidu-ad-ppzq-title)
代码加锁:不要让“锁”事成为烦心事
加锁要考虑锁的粒度和场景问题
在方法上加 synchronized 关键字实现加锁确实简单,也因此我曾看到一些业务代码中几乎所有方法都加了 synchronized,但这种滥用 synchronized 的做法:
- 没必要。通常情况下 60% 的业务代码是三层架构,数据经过无状态的 Controller、Service、Repository 流转到数据库,没必要使用 synchronized 来保护什么数据。
可能会极大地降低性能。使用 Spring 框架时,默认情况下 Controller、Service、Repository 是单例的,加上 synchronized 会导致整个程序几乎就只能支持单线程,造成极大的性能问题。
线程池:业务代码最常用也最容易犯错的组件
不建议使用 Executors 提供的两种快捷的线程池
原因如下:
我们需要根据自己的场景、并发情况来评估线程池的几个核心参数,包括核心线程数、最大线程数、线程回收策略、工作队列的类型,以及拒绝策略,确保线程池的工作行为符合需求,一般都需要设置有界的工作队列和可控的线程数。任何时候,都应该为自定义线程池指定有意义的名称,以方便排查问题。当出现线程数量暴增、线程死锁、线程占用大量 CPU、线程执行出现异常等问题时,我们往往会抓取线程栈。此时,有意义的线程名称,就可以方便我们定位问题。
除了建议手动声明线程池以外,我还建议用一些监控手段来观察线程池的状态。线程池这个组件往往会表现得任劳任怨、默默无闻,除非是出现了拒绝策略,否则压力再大都不会抛出一个异常。如果我们能提前观察到线程池队列的积压,或者线程数量的快速膨胀,往往可以提早发现并解决问题
需要仔细斟酌线程池的混用策略,线程池的意义在于复用
那这是不是意味着程序应该始终使用一个线程池呢?当然不是。通过第一小节的学习我们知道,要根据任务的“轻重缓急”来指定线程池的核心参数,包括线程数、回收策略和任务队列:对于执行比较慢、数量不大的 IO 任务,或许要考虑更多的线程数,而不需要太大的队列。而对于吞吐量较大的计算型任务,线程数量不宜过多,可以是 CPU 核数或核数 2(理由是,线程一定调度到某个 CPU 进行执行,如果任务本身是 CPU 绑定的任务,那么过多的线程只会增加线程切换的开销,并不能提升吞吐量),但可能需要较长的队列来做缓冲。
- 就线程池混用问题,再补充一个坑:Java 8 的 parallel stream 功能,可以让我们很方便地并行处理集合中的元素,其背后是共享同一个 ForkJoinPool,默认并行度是 CPU 核数 -1。对于 CPU 绑定的任务来说,使用这样的配置比较合适,但如果集合操作涉及同步 IO 操作的话(比如数据库操作、外部服务调用等),建议自定义一个 ForkJoinPool(或普通线程池)。
- 连接池:别让连接池帮了倒忙
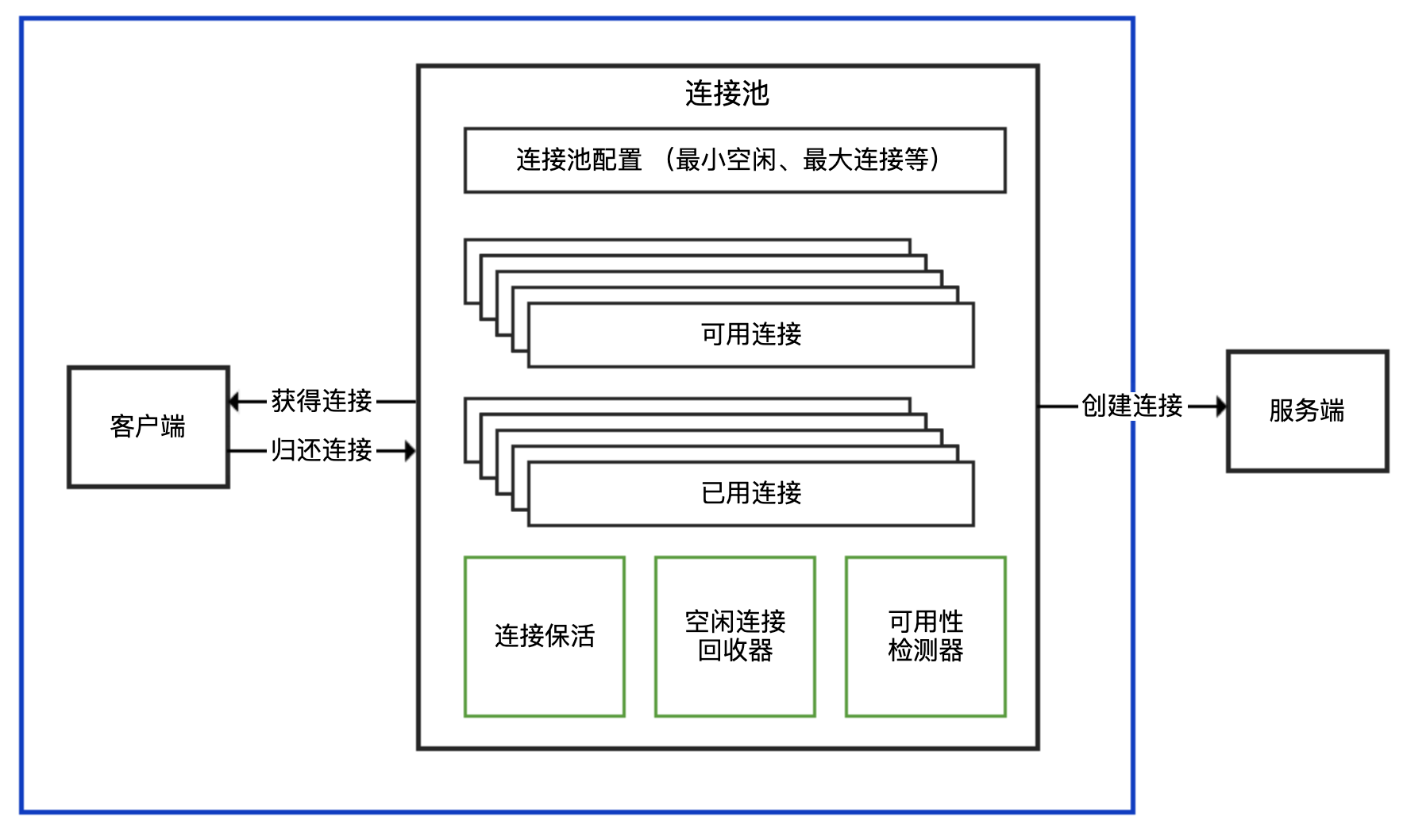
面对各种三方客户端的时候,只有先识别出其属于哪一种,才能理清楚使用方式。
- 连接池和连接分离的 API:有一个 XXXPool 类负责连接池实现,先从其获得连接 XXXConnection,然后用获得的连接进行服务端请求,完成后使用者需要归还连接。通常,XXXPool 是线程安全的,可以并发获取和归还连接,而 XXXConnection 是非线程安全的。对应到连接池的结构示意图中,XXXPool 就是右边连接池那个框,左边的客户端是我们自己的代码。
- 内部带有连接池的 API:对外提供一个 XXXClient 类,通过这个类可以直接进行服务端请求;这个类内部维护了连接池,SDK 使用者无需考虑连接的获取和归还问题。一般而言,XXXClient 是线程安全的。对应到连接池的结构示意图中,整个 API 就是蓝色框包裹的部分。
- 非连接池的 API:一般命名为 XXXConnection,以区分其是基于连接池还是单连接的,而不建议命名为 XXXClient 或直接是 XXX。直接连接方式的 API 基于单一连接,每次使用都需要创建和断开连接,性能一般,且通常不是线程安全的。对应到连接池的结构示意图中,这种形式相当于没有右边连接池那个框,客户端直接连接服务端创建连接。
明确了 SDK 连接池的实现方式后,我们就大概知道了使用 SDK 的最佳实践:
- 如果是分离方式,那么连接池本身一般是线程安全的,可以复用。每次使用需要从连接池获取连接,使用后归还,归还的工作由使用者负责。
- 如果是内置连接池,SDK 会负责连接的获取和归还,使用的时候直接复用客户端。
- 如果 SDK 没有实现连接池(大多数中间件、数据库的客户端 SDK 都会支持连接池),那通常不是线程安全的,而且短连接的方式性能不会很高,使用的时候需要考虑是否自己封装一个连接池。
连接池的配置不是一成不变的
- 为方便根据容量规划设置连接处的属性,连接池提供了许多参数,包括最小(闲置)连接、最大连接、闲置连接生存时间、连接生存时间等。其中,最重要的参数是最大连接数,它决定了连接池能使用的连接数量上限,达到上限后,新来的请求需要等待其他请求释放连接。
- 但,最大连接数不是设置得越大越好。如果设置得太大,不仅仅是客户端需要耗费过多的资源维护连接,更重要的是由于服务端对应的是多个客户端,每一个客户端都保持大量的连接,会给服务端带来更大的压力。这个压力又不仅仅是内存压力,可以想一下如果服务端的网络模型是一个 TCP 连接一个线程,那么几千个连接意味着几千个线程,如此多的线程会造成大量的线程切换开销。
当然,连接池最大连接数设置得太小,很可能会因为获取连接的等待时间太长,导致吞吐量低下,甚至超时无法获取连接。
HTTP调用:你考虑到超时、重试、并发了吗?
几乎所有的网络框架都会提供这么两个超时参数:
连接超时参数 ConnectTimeout,让用户配置建连阶段的最长等待时间;
读取超时参数 ReadTimeout,用来控制从 Socket 上读取数据的最长等待时间。
这两个参数看似是网络层偏底层的配置参数,不足以引起开发同学的重视。但,正确理解和配置这两个参数,对业务应用特别重要,毕竟超时不是单方面的事情,需要客户端和服务端对超时有一致的估计,协同配合方能平衡吞吐量和错误率。因为 TCP 是先建立连接后传输数据,对于网络情况不是特别糟糕的服务调用,通常可以认为出现连接超时是网络问题或服务不在线,而出现读取超时是服务处理超时。确切地说,读取超时指的是,向 Socket 写入数据后,我们等到 Socket 返回数据的超时时间,其中包含的时间或者说绝大部分的时间,是服务端处理业务逻辑的时间。默认情况下 Feign 的读取超时是 1 秒,如此短的读取超时算是坑点一。
- 如果要配置 Feign 的读取超时,就必须同时配置连接超时,才能生效。除了可以配置 Feign,也可以配置 Ribbon 组件的参数来修改两个超时时间。
- 这里的坑点三是,参数首字母要大写,和 Feign 的配置不同。
ribbon.ReadTimeout=4000 ribbon.ConnectTimeout=4000,同时配置 Feign 和 Ribbon 的参数,最终谁会生效?答案是feign。
翻看 Ribbon 的源码可以发现,MaxAutoRetriesNextServer 参数默认为 1,也就是 Get 请求在某个服务端节点出现问题(比如读取超时)时,Ribbon 会自动重试一次:
判等问题:程序里如何确定你就是你
比较值的内容,除了基本类型只能使用 == 外,其他类型都需要使用 equals。
对于自定义的类型,如果要实现 Comparable,请记得 equals、hashCode、compareTo 三者逻辑一致。
数值计算:注意精度、舍入和溢出问题
- 浮点数运算避坑第一原则:使用 BigDecimal 表示和计算浮点数,且务必使用字符串的构造方法来初始化 BigDecimal:BigDecimal 有 scale 和 precision 的概念,scale 表示小数点右边的位数,而 precision 表示精度,也就是有效数字的长度。对于 BigDecimal 乘法操作,返回值的 scale 是两个数的 scale 相加
- 浮点数避坑第二原则:浮点数的字符串格式化也要通过 BigDecimal 进行。比如下面这段代码,使用 BigDecimal 来格式化数字 3.35,分别使用向下舍入和四舍五入方式取 1 位小数进行格式化:
这次得到的结果是 3.3 和 3.4,符合预期。如果我们希望只比较 BigDecimal 的 value,可以使用 compareTo 方法 , equals 比较的是 BigDecimal 的 value 和 scale。比如如下返回false:BigDecimal num1 = new BigDecimal("3.35");BigDecimal num2 = num1.setScale(1, BigDecimal.ROUND_DOWN);System.out.println(num2);BigDecimal num3 = num1.setScale(1, BigDecimal.ROUND_HALF_UP);System.out.println(num3);
BigDecimal 的 equals 和 hashCode 方法会同时考虑 value 和 scale,如果结合 HashSet 或 HashMap 使用的话就可能会出现麻烦。比如,我们把值为 1.0 的 BigDecimal 加入 HashSet,然后判断其是否存在值为 1 的 BigDecimal,得到的结果是 false:System.out.println(new BigDecimal("1.0").equals(new BigDecimal("1")))
解决这个问题的办法有两个:第一个方法是,使用 TreeSet 替换 HashSet。TreeSet 不使用 hashCode 方法,也不使用 equals 比较元素,而是使用 compareTo 方法,所以不会有问题。Set<BigDecimal> hashSet1 = new HashSet<>();hashSet1.add(new BigDecimal("1.0"));System.out.println(hashSet1.contains(new BigDecimal("1")));//返回false
第二个方法是,把 BigDecimal 存入 HashSet 或 HashMap 前,先使用 stripTrailingZeros 方法去掉尾部的零,比较的时候也去掉尾部的 0,确保 value 相同的 BigDecimal,scale 也是一致的:Set<BigDecimal> treeSet = new TreeSet<>();treeSet.add(new BigDecimal("1.0"));System.out.println(treeSet.contains(new BigDecimal("1")));//返回true
Set<BigDecimal> hashSet2 = new HashSet<>();hashSet2.add(new BigDecimal("1.0").stripTrailingZeros());System.out.println(hashSet2.contains(new BigDecimal("1.000").stripTrailingZeros()));//返回true
小心数值溢出问题
数值计算还有一个要小心的点是溢出,不管是 int 还是 long,所有的基本数值类型都有超出表达范围的可能性。比如,对 Long 的最大值进行 +1 操作:
输出结果是一个负数,因为 Long 的最大值 +1 变为了 Long 的最小值long l = Long.MAX_VALUE;System.out.println(l + 1);System.out.println(l + 1 == Long.MIN_VALUE);
显然这是发生了溢出,而且是默默的溢出,并没有任何异常。这类问题非常容易被忽略,改进方式有下面 2 种。-9223372036854775808true
方法一:考虑使用 Math 类的 addExact、subtractExact 等 xxExact 方法进行数值运算,这些方法可以在数值溢出时主动抛出异常。我们来测试一下,使用 Math.addExact 对 Long 最大值做 +1 操作:
执行后,可以得到 ArithmeticException,这是一个 RuntimeException:try {long l = Long.MAX_VALUE;System.out.println(Math.addExact(l, 1));} catch (Exception ex) {ex.printStackTrace();}
方法二:使用大数类 BigInteger。BigDecimal 是处理浮点数的专家,而 BigInteger 则是对大数进行科学计算的专家。如下代码,使用 BigInteger 对 Long 最大值进行 +1 操作;如果希望把计算结果转换一个 Long 变量的话,可以使用 BigInteger 的 longValueExact 方法,在转换出现溢出时,同样会抛出 ArithmeticException:
输出结果如下:BigInteger i = new BigInteger(String.valueOf(Long.MAX_VALUE));System.out.println(i.add(BigInteger.ONE).toString());try {long l = i.add(BigInteger.ONE).longValueExact();} catch (Exception ex) {ex.printStackTrace();}
可以看到,通过 BigInteger 对 Long 的最大值加 1 一点问题都没有,当尝试把结果转换为 Long 类型时,则会提示 BigInteger out of long range。BigDecimal提供了 8 种舍入模式,你能通过一些例子说说它们的区别吗?9223372036854775808java.lang.ArithmeticException: BigInteger out of long rangeat java.math.BigInteger.longValueExact(BigInteger.java:4632)at org.geekbang.time.commonmistakes.numeralcalculations.demo3.CommonMistakesApplication.right1(CommonMistakesApplication.java:37)at org.geekbang.time.commonmistakes.numeralcalculations.demo3.CommonMistakesApplication.main(CommonMistakesApplication.java:11)
1、 ROUND_UP
舍入远离零的舍入模式。在丢弃非零部分之前始终增加数字(始终对非零舍弃部分前面的数字加1)。注意,此舍入模式始终不会减少计算值的大小。
2、ROUND_DOWN
接近零的舍入模式。在丢弃某部分之前始终不增加数字(从不对舍弃部分前面的数字加1,即截短)。注意,此舍入模式始终不会增加计算值的大小。
3、ROUND_CEILING
接近正无穷大的舍入模式。如果 BigDecimal 为正,则舍入行为与 ROUND_UP 相同;如果为负,则舍入行为与 ROUND_DOWN 相同。注意,此舍入模式始终不会减少计算值。
4、ROUND_FLOOR
接近负无穷大的舍入模式。如果 BigDecimal 为正,则舍入行为与 ROUND_DOWN 相同;如果为负,则舍入行为与 ROUND_UP 相同。注意,此舍入模式始终不会增加计算值。
5、ROUND_HALF_UP
向“最接近的”数字舍入,如果与两个相邻数字的距离相等,则为向上舍入的舍入模式。如果舍弃部分 >= 0.5,则舍入行为与 ROUND_UP 相同;否则舍入行为与 ROUND_DOWN 相同。注意,这是我们大多数人在小学时就学过的舍入模式(四舍五入)。
6、ROUND_HALF_DOWN
向“最接近的”数字舍入,如果与两个相邻数字的距离相等,则为上舍入的舍入模式。如果舍弃部分 > 0.5,则舍入行为与 ROUND_UP 相同;否则舍入行为与 ROUND_DOWN 相同(五舍六入)。
7、ROUND_HALF_EVEN
向“最接近的”数字舍入,如果与两个相邻数字的距离相等,则向相邻的偶数舍入。如果舍弃部分左边的数字为奇数,则舍入行为与 ROUND_HALF_UP 相同;如果为偶数,则舍入行为与 ROUND_HALF_DOWN 相同。注意,在重复进行一系列计算时,此舍入模式可以将累加错误减到最小。此舍入模式也称为**“银行家舍入法”**,主要在美国使用。四舍六入,五分两种情况。如果前一位为奇数,则入位,否则舍去。以下例子为保留小数点1位,那么这种舍入方式下的结果。1.15>1.2 1.25>1.2
8、ROUND_UNNECESSARY
断言请求的操作具有精确的结果,因此不需要舍入。如果对获得精确结果的操作指定此舍入模式,则抛出ArithmeticException。
集合类:坑满地的List列表操作
使用 Arrays.asList 把数据转换为 List 的三个坑
第一个坑:我们初始化三个数字的 int[]数组,然后使用 Arrays.asList 把数组转换为 List:
int[] arr = {1, 2, 3};List list = Arrays.asList(arr);log.info("list:{} size:{} class:{}", list, list.size(), list.get(0).getClass());
但,这样初始化的 List 并不是我们期望的包含 3 个数字的 List。通过日志可以发现,这个 List 包含的其实是一个 int 数组,整个 List 的元素个数是 1,元素类型是整数数组。其原因是,只能是把 int 装箱为 Integer,不可能把 int 数组装箱为 Integer 数组。我们知道,Arrays.asList 方法传入的是一个泛型 T 类型可变参数,最终 int 数组整体作为了一个对象成为了泛型类型 T:
public static <T> List<T> asList(T... a) {return new ArrayList<>(a);}
直接遍历这样的 List 必然会出现 Bug,修复方式有两种,如果使用 Java8 以上版本可以使用 Arrays.stream 方法来转换,否则可以把 int 数组声明为包装类型 Integer 数组:
int[] arr1 = {1, 2, 3};List list1 = Arrays.stream(arr1).boxed().collect(Collectors.toList());log.info("list:{} size:{} class:{}", list1, list1.size(), list1.get(0).getClass());Integer[] arr2 = {1, 2, 3};List list2 = Arrays.asList(arr2);log.info("list:{} size:{} class:{}", list2, list2.size(), list2.get(0).getClass());
第二个坑:Arrays.asList 返回的 List 不支持增删操作。Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList
第三个坑:对原始数组的修改会影响到我们获得的那个 List。
看一下 ArrayList 的实现,可以发现 ArrayList 其实是直接使用了原始的数组。所以,我们要特别小心,把通过 Arrays.asList 获得的 List 交给其他方法处理,很容易因为共享了数组,相互修改产生 Bug。
修复方式比较简单,重新 new 一个 ArrayList 初始化 Arrays.asList 返回的 List 即可:
String[] arr = {"1", "2", "3"};List list = new ArrayList(Arrays.asList(arr));arr[1] = "4";try {list.add("5");} catch (Exception ex) {ex.printStackTrace();}log.info("arr:{} list:{}", Arrays.toString(arr), list);
使用 List.subList 进行切片操作居然会导致 OOM?
业务开发时常常要对 List 做切片处理,即取出其中部分元素构成一个新的 List,我们通常会想到使用 List.subList 方法。但,和 Arrays.asList 的问题类似,List.subList 返回的子 List 不是一个普通的 ArrayList。这个子 List 可以认为是原始 List 的视图,会和原始 List 相互影响。如果不注意,很可能会因此产生 OOM 问题。
SubList 相当于原始 List 的视图,那么避免相互影响的修复方式有两种:一种是,不直接使用 subList 方法返回的 SubList,而是重新使用 new ArrayList,在构造方法传入 SubList,来构建一个独立的 ArrayList;另一种是,对于 Java 8 使用 Stream 的 skip 和 limit API 来跳过流中的元素,以及限制流中元素的个数,同样可以达到 SubList 切片的目的。
//方式一:List<Integer> subList = new ArrayList<>(list.subList(1, 4));//方式二:List<Integer> subList = list.stream().skip(1).limit(3).collect(Collectors.toList());
如果要对大 ArrayList 进行去重操作,也不建议使用 contains 方法,而是可以考虑使用 HashSet 进行去重
空值处理:分不清楚的null和恼人的空指针
NullPointerException 是 Java 代码中最常见的异常,最可能出现的场景归为以下 5 种:
- 参数值是 Integer 等包装类型,使用时因为自动拆箱出现了空指针异常;
- 字符串比较出现空指针异常;
- 诸如 ConcurrentHashMap 这样的容器不支持 Key 和 Value 为 null,强行 put null 的 Key 或 Value 会出现空指针异常;
- A 对象包含了 B,在通过 A 对象的字段获得 B 之后,没有对字段判空就级联调用 B 的方法出现空指针异常;
- 方法或远程服务返回的 List 不是空而是 null,没有进行判空就直接调用 List 的方法出现空指针异常。
纯粹的空指针判空这种修复方式。如果要先判空后处理,大多数人会想到使用 if-else 代码块。但,这种方式既增加代码量又会降低易读性,我们可以尝试利用 Java 8 的 Optional 类来消除这样的 if-else 逻辑,使用一行代码进行判空和处理。修复思路如下:
- 对于 Integer 的判空,可以使用 Optional.ofNullable 来构造一个 Optional,然后使用 orElse(0) 把 null 替换为默认值再进行 +1 操作。
- 对于 String 和字面量的比较,可以把字面量放在前面,比如”OK”.equals(s),这样即使 s 是 null 也不会出现空指针异常;而对于两个可能为 null 的字符串变量的 equals 比较,可以使用 Objects.equals,它会做判空处理。
- 对于 ConcurrentHashMap,既然其 Key 和 Value 都不支持 null,修复方式就是不要把 null 存进去。HashMap 的 Key 和 Value 可以存入 null,而 ConcurrentHashMap 看似是 HashMap 的线程安全版本,却不支持 null 值的 Key 和 Value,这是容易产生误区的一个地方。
- 对于类似 fooService.getBarService().bar().equals(“OK”) 的级联调用,需要判空的地方有很多,包括 fooService、getBarService() 方法的返回值,以及 bar 方法返回的字符串。如果使用 if-else 来判空的话可能需要好几行代码,但使用 Optional 的话一行代码就够了。
对于 rightMethod 返回的 List,由于不能确认其是否为 null,所以在调用 size 方法获得列表大小之前,同样可以使用 Optional.ofNullable 包装一下返回值,然后通过.orElse(Collections.emptyList()) 实现在 List 为 null 的时候获得一个空的 List,最后再调用 size 方法。
private List<String> rightMethod(FooService fooService, Integer i, String s, String t) {log.info("result {} {} {} {}", Optional.ofNullable(i).orElse(0) + 1, "OK".equals(s), Objects.equals(s, t), new HashMap<String, String>().put(null, null));Optional.ofNullable(fooService).map(FooService::getBarService).filter(barService -> "OK".equals(barService.bar())).ifPresent(result -> log.info("OK"));return new ArrayList<>();}@GetMapping("right")public int right(@RequestParam(value = "test", defaultValue = "1111") String test) {return Optional.ofNullable(rightMethod(test.charAt(0) == '1' ? null : new FooService(),test.charAt(1) == '1' ? null : 1,test.charAt(2) == '1' ? null : "OK",test.charAt(3) == '1' ? null : "OK")).orElse(Collections.emptyList()).size();}
使用判空方式或 Optional 方式来避免出现空指针异常,不一定是解决问题的最好方式,空指针没出现可能隐藏了更深的 Bug 因此,解决空指针异常,还是要真正 case by case 地定位分析案例,然后再去做判空处理,而处理时也并不只是判断非空然后进行正常业务流程这么简单,同样需要考虑为空的时候是应该出异常、设默认值还是记录日志等。
捕获和处理异常容易犯的错
第一个错:“统一异常处理”方式,不在业务代码层面考虑异常处理,仅在框架层面粗犷捕获和处理异常。不建议在框架层面进行异常的自动、统一处理,尤其不要随意捕获异常。但,框架可以做兜底工作。如果异常上升到最上层逻辑还是无法处理的话,可以以统一的方式进行异常转换,“未处理”异常:
对于自定义的业务异常,以 Warn 级别的日志记录异常以及当前 URL、执行方法等信息后,提取异常中的错误码和消息等信息,转换为合适的 API 包装体返回给 API 调用方;
- 对于无法处理的系统异常,以 Error 级别的日志记录异常和上下文信息(比如 URL、参数、用户 ID)后,转换为普适的“服务器忙,请稍后再试”异常信息,同样以 API 包装体返回给调用方。
第二个错:捕获了异常后直接生吞。在任何时候,我们捕获了异常都不应该生吞,也就是直接丢弃异常不记录、不抛出。这样的处理方式还不如不捕获异常,因为被生吞掉的异常一旦导致 Bug,就很难在程序中找到蛛丝马迹,使得 Bug 排查工作难上加难。
第三个错:丢弃异常的原始信息。我们来看两个不太合适的异常处理方式,虽然没有完全生吞异常,但也丢失了宝贵的异常信息。像这样调用 readFile 方法,捕获异常后,完全不记录原始异常,直接抛出一个转换后异常,导致出了问题不知道 IOException 具体是哪里引起的:
@GetMapping("wrong1")public void wrong1(){try {readFile();} catch (IOException e) {//原始异常信息丢失throw new RuntimeException("系统忙请稍后再试");}}
或者是这样,只记录了异常消息,却丢失了异常的类型、栈等重要信息:
catch (IOException e) {//只保留了异常消息,栈没有记录log.error("文件读取错误, {}", e.getMessage());throw new RuntimeException("系统忙请稍后再试");}
留下的日志是这样的,看完一脸茫然,只知道文件读取错误的文件名,至于为什么读取错误、是不存在还是没权限,完全不知道。
[12:57:19.746] [http-nio-45678-exec-1] [ERROR] [.g.t.c.e.d.HandleExceptionController:35 ] - 文件读取错误, a_file
这两种处理方式都不太合理,可以改为如下方式:
catch (IOException e) {log.error("文件读取错误", e);throw new RuntimeException("系统忙请稍后再试");}
或者,把原始异常作为转换后新异常的 cause,原始异常信息同样不会丢:
catch (IOException e) {throw new RuntimeException("系统忙请稍后再试", e);}
第四个错:抛出异常时不指定任何消息。我见过一些代码中的偷懒做法,直接抛出没有 message 的异常:
throw new RuntimeException();
如果你捕获了异常打算处理的话,除了通过日志正确记录异常原始信息外,通常还有三种处理模式
- 转换,即转换新的异常抛出。对于新抛出的异常,最好具有特定的分类和明确的异常消息,而不是随便抛一个无关或没有任何信息的异常,并最好通过 cause 关联老异常。
- 重试,即重试之前的操作。比如远程调用服务端过载超时的情况,盲目重试会让问题更严重,需要考虑当前情况是否适合重试。
-
小心 finally 中的异常
有些时候,我们希望不管是否遇到异常,逻辑完成后都要释放资源,这时可以使用 finally 代码块而跳过使用 catch 代码块。但要千万小心 finally 代码块中的异常,因为资源释放处理等收尾操作同样也可能出现异常。比如下面这段代码,我们在 finally 中抛出一个异常:
@GetMapping("wrong")public void wrong() {try {log.info("try");//异常丢失throw new RuntimeException("try");} finally {log.info("finally");throw new RuntimeException("finally");}}
最后在日志中只能看到 finally 中的异常,虽然 try 中的逻辑出现了异常,但却被 finally 中的异常覆盖了。这是非常危险的,特别是 finally 中出现的异常是偶发的,就会在部分时候覆盖 try 中的异常,让问题更不明显:
至于异常为什么被覆盖,原因也很简单,因为一个方法无法出现两个异常。修复方式是,finally 代码块自己负责异常捕获和处理:@GetMapping("right")public void right() {try {log.info("try");throw new RuntimeException("try");} finally {log.info("finally");try {throw new RuntimeException("finally");} catch (Exception ex) {log.error("finally", ex);}}}
或者可以把 try 中的异常作为主异常抛出,使用 addSuppressed 方法把 finally 中的异常附加到主异常上
@GetMapping("right2")public void right2() throws Exception {Exception e = null;try {log.info("try");throw new RuntimeException("try");} catch (Exception ex) {e = ex;} finally {log.info("finally");try {throw new RuntimeException("finally");} catch (Exception ex) {if (e!= null) {e.addSuppressed(ex);} else {e = ex;}}}throw e;}
运行方法可以得到如下异常信息,其中同时包含了主异常和被屏蔽的异常:
java.lang.RuntimeException: tryat org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.right2(FinallyIssueController.java:69)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)...Suppressed: java.lang.RuntimeException: finallyat org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.right2(FinallyIssueController.java:75)... 54 common frames omitted
其实这正是 try-with-resources 语句的做法,对于实现了 AutoCloseable 接口的资源,建议使用 try-with-resources 来释放资源,否则也可能会产生刚才提到的,释放资源时出现的异常覆盖主异常的问题。
千万别把异常定义为静态变量
提交线程池的任务出了异常会怎么样? 提交线程池的任务出了异常会怎么样?
修复方式有 2 步:
以 execute 方法提交到线程池的异步任务,最好在任务内部做好异常处理;设置自定义的异常处理程序作为保底,比如在声明线程池时自定义线程池的未捕获异常处理程序:通过线程池 ExecutorService 的 execute 方法提交任务到线程池处理,如果出现异常会导致线程退出,控制台输出中可以看到异常信息。那么,把 execute 方法改为 submit,线程还会退出吗,异常还能被处理程序捕获到吗?
线程没退出 ,异常也没记录被生吞了查看 FutureTask 源码可以发现,在执行任务出现异常之后,异常存到了一个 outcome 字段中,只有在调用 get 方法获取 FutureTask 结果的时候,才会以 ExecutionException 的形式重新抛出异常:思考与讨论:
关于在 finally 代码块中抛出异常的坑,如果在 finally 代码块中返回值,你觉得程序会以 try 或 catch 中返回值为准,还是以 finally 中的返回值为准呢?对于手动抛出的异常,不建议直接使用 Exception 或 RuntimeException,通常建议复用 JDK 中的一些标准异常,比如IllegalArgumentException、IllegalStateException、UnsupportedOperationException,你能说说它们的适用场景,并列出更多常用异常吗?
第一个问题:肯定是以finally语句块为准。 原因:首先需要明白的是在编译生成的字节码中,每个方法都附带一个异常表。异常表中的每一个条目代表一个异常处理器,并且由 from 指针、to 指针、target 指针以及所捕获的异常类型构成。这些指针的值是字节码索引(bytecode index,bci),用以定位字节码。其中,from 指针和 to 指针标示了该异常处理器所监控的范围,例如 try 代码块所覆盖的范围。target 指针则指向异常处理器的起始位置,例如 catch 代码块的起始位置; 当程序触发异常时,Java 虚拟机会从上至下遍历异常表中的所有条目。当触发异常的字节码的索引值在某个异常表条目的监控范围内,Java 虚拟机会判断所抛出的异常和该条目想要捕获的异常是否匹配。如果匹配,Java 虚拟机会将控制流转移至该条目 target 指针指向的字节码。如果遍历完所有异常表条目,Java 虚拟机仍未匹配到异常处理器,那么它会弹出当前方法对应的 Java 栈帧,并且在调用者(caller)中重复上述操作。在最坏情况下,Java 虚拟机需要遍历当前线程 Java 栈上所有方法的异常表。所以异常操作是一个非常耗费性能的操作; finally 代码块的原理是复制 finally 代码块的内容,分别放在 try-catch 代码块所有正常执行路径以及异常执行路径的出口中。所以不管是是正常还是异常执行,finally都是最后执行的,所以肯定是finally语句块中为准。 第二个问题:IllegalArgumentException:不合法的参数异常,比如说限制不能为空或者有指定的发小范围,调用方没有按照规定传递参数,就可以抛出这个异常;IllegalStateException:如果有状态流转的概念在里面(比如状态机),状态只能从A->B->C,若状态直接从A->C,就可以抛出该异常; UnsupportedOperationException:不支持该操作异常,比如非抽象父类中有个方法,子类必须实现,父类中的方法就可以抛出次异常。老师在集合坑中提到的Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList。ArrayList 内部类继承自 AbstractList 类,并没有覆写父类的 add 方法,而父类中 add 方法的实现,就是抛出 UnsupportedOperationException。
文件IO:实现高效正确的文件读写并非易事
有一个项目需要读取三方的对账文件定时对账,原先一直是单机处理的,没什么问题。后来为了提升性能,使用双节点同时处理对账,每一个节点处理部分对账数据,但新增的节点在处理文件中中文的时候总是读取到乱码。程序代码都是一致的,为什么老节点就不会有问题呢?我们知道,这很可能是写代码时没有注意编码问题导致的
当时出现问题的文件读取代码是这样的:
char[] chars = new char[10];String content = "";try (FileReader fileReader = new FileReader("hello.txt")) {int count;while ((count = fileReader.read(chars)) != -1) {content += new String(chars, 0, count);}}log.info("result:{}", content);
显然,这里并没有指定以什么字符集来读取文件中的字符。查看JDK 文档可以发现,FileReader 是以当前机器的默认字符集来读取文件的,如果希望指定字符集的话,需要直接使用 InputStreamReader 和 FileInputStream。到这里我们就明白了,FileReader 虽然方便但因为使用了默认字符集对环境产生了依赖,这就是为什么老的机器上程序可以正常运作,在新节点上读取中文时却产生了乱码。
思考与讨论
Files.lines 方法进行流式处理,需要使用 try-with-resources 进行资源释放。那么,使用 Files 类中其他返回 Stream 包装对象的方法进行流式处理,比如 newDirectoryStream 方法返回 DirectoryStream,list、walk 和 find 方法返回 Stream,也同样有资源释放问题吗?
Java 的 File 类和 Files 类提供的文件复制、重命名、删除等操作,是原子性的吗?
先说下FileChannel 的 transfreTo 方法,这个方法出现在眼前很多次,因为之前看Kafka为什么吞吐量达的原因的时候,提到了2点:批处理思想和零拷贝;批处理思想:就是对于Kafka内部很多地方来说,不是消息来了就发送,而是有攒一波发送一次,这样对于吞吐量有极大的提升,对于需要实时处理的情况,Kafka就不是很适合的原因;零拷贝:Kafka快的另外一个原因是零拷贝,避免了内存态到内核态以及网络的拷贝,直接读取文件,发送到网络出去,零拷贝的含义不是没有拷贝,而是没有用户态到核心态的拷贝。而在提到零拷贝的实现时,Java中说的就是FileChannel 的 transfreTo 方法。 然后回答下问题: 第一个问题:Files的相关方法文档描述: When not using the try-with-resources construct, then directory stream’s close method should be invoked after iteration is completed so as to free any resources held for the open directory。所以是需要手动关闭的。 第二个问题:没有原子操作,因此是线程不安全的。个人理解,其实即使加上了原子操作,也是鸡肋,不实用的很,原因是:File 类和 Files的相关操作,其实都是调用操作系统的文件系统操作,这个文件除了JVM操作外,可能别的也在操作,因此还不如不保证,完全基于操作系统的文件系统去保证相关操作的正确性。
序列化:一来一回你还是原来的你吗
序列化和反序列化需要确保算法一致
业务代码中涉及序列化时,很重要的一点是要确保序列化和反序列化的算法一致性。有一次我要排查缓存命中率问题,需要运维同学帮忙拉取 Redis 中的 Key,结果他反馈 Redis 中存的都是乱码,怀疑 Redis 被攻击了。其实呢,这个问题就是序列化算法导致的Spring 提供的 4 种 RedisSerializer(Redis 序列化器):
- 默认情况下,RedisTemplate 使用 JdkSerializationRedisSerializer,也就是 JDK 序列化,容易产生 Redis 中保存了乱码的错觉。
- 通常考虑到易读性,可以设置 Key 的序列化器为 StringRedisSerializer。但直接使用 RedisSerializer.string(),相当于使用了 UTF_8 编码的 StringRedisSerializer,需要注意字符集问题。如果希望 Value 也是使用 JSON 序列化的话,可以把 Value 序列化器设置为 Jackson2JsonRedisSerializer。默认情况下,不会把类型信息保存在 Value 中,即使我们定义 RedisTemplate 的 Value 泛型为实际类型,查询出的 Value 也只能是 LinkedHashMap 类型。
- 如果希望直接获取真实的数据类型,你可以启用 Jackson ObjectMapper 的 activateDefaultTyping 方法,把类型信息一起序列化保存在 Value 中。
如果希望 Value 以 JSON 保存并带上类型信息,更简单的方式是,直接使用 RedisSerializer.json() 快捷方法来获取序列化器。
用好Java 8的日期时间类,少踩一些“老三样”的坑
在 Java 8 之前,我们处理日期时间需求时,使用 Date、Calender 和 SimpleDateFormat,来声明时间戳、使用日历处理日期和格式化解析日期时间。但是,这些类的 API 的缺点比较明显,比如可读性差、易用性差、使用起来冗余繁琐,还有线程安全问题。
关于 Date 类,我们要有两点认识:一是,Date 并无时区问题,世界上任何一台计算机使用 new Date() 初始化得到的时间都一样。因为,Date 中保存的是 UTC 时间,UTC 是以原子钟为基础的统一时间,不以太阳参照计时,并无时区划分。
- 二是,Date 中保存的是一个时间戳,代表的是从 1970 年 1 月 1 日 0 点(Epoch 时间)到现在的毫秒数。尝试输出 Date(0):
对于国际化(世界各国的人都在使用)的项目,处理好时间和时区问题首先就是要正确保存日期时间。这里有两种保存方式:
- 方式一,以 UTC 保存,保存的时间没有时区属性,是不涉及时区时间差问题的世界统一时间。我们通常说的时间戳,或 Java 中的 Date 类就是用的这种方式,这也是推荐的方式。
- 方式二,以字面量保存,比如年 / 月 / 日 时: 分: 秒,一定要同时保存时区信息。只有有了时区信息,我们才能知道这个字面量时间真正的时间点,否则它只是一个给人看的时间表示,只在当前时区有意义。Calendar 是有时区概念的,所以我们通过不同的时区初始化 Calendar,得到了不同的时间。
要正确处理国际化时间问题,我推荐使用 Java 8 的日期时间类,即使用 ZonedDateTime 保存时间,然后使用设置了 ZoneId 的 DateTimeFormatter 配合 ZonedDateTime 进行时间格式化得到本地时间表示。这样的划分十分清晰、细化,也不容易出错。
使用遗留的 SimpleDateFormat,会遇到哪些问题:
- 日期时间格式化和解析
每到年底,就有很多开发同学踩时间格式化的坑,比如“这明明是一个 2019 年的日期,怎么使用 SimpleDateFormat 格式化后就提前跨年了” , 出现这个问题的原因在于,这位同学混淆了 SimpleDateFormat 的各种格式化模式。JDK 的文档中有说明:小写 y 是年,而大写 Y 是 week year,也就是所在的周属于哪一年。
除了格式化表达式容易踩坑外,SimpleDateFormat 还有两个著名的坑。
第一个坑:定义的 static 的 SimpleDateFormat 可能会出现线程安全问题。
SimpleDateFormat 的作用是定义解析和格式化日期时间的模式。这,看起来这是一次性的工作,应该复用,但它的解析和格式化操作是非线程安全的。我们来分析一下相关源码:SimpleDateFormat 继承了 DateFormat,DateFormat 有一个字段 Calendar;SimpleDateFormat 的 parse 方法调用 CalendarBuilder 的 establish 方法,来构建 Calendar;establish 方法内部先清空 Calendar 再构建 Calendar,整个操作没有加锁。显然,如果多线程池调用 parse 方法,也就意味着多线程在并发操作一个 Calendar,可能会产生一个线程还没来得及处理 Calendar 就被另一个线程清空了的情况:
public abstract class DateFormat extends Format {protected Calendar calendar;}public class SimpleDateFormat extends DateFormat {@Overridepublic Date parse(String text, ParsePosition pos){CalendarBuilder calb = new CalendarBuilder();parsedDate = calb.establish(calendar).getTime();return parsedDate;}}class CalendarBuilder {Calendar establish(Calendar cal) {...cal.clear();//清空for (int stamp = MINIMUM_USER_STAMP; stamp < nextStamp; stamp++) {for (int index = 0; index <= maxFieldIndex; index++) {if (field[index] == stamp) {cal.set(index, field[MAX_FIELD + index]);//构建break;}}}return cal;}}
第二个坑:当需要解析的字符串和格式不匹配的时候,SimpleDateFormat 表现得很宽容,还是能得到结果。比如,我们期望使用 yyyyMM 来解析 20160901 字符串:
String dateString = "20160901";SimpleDateFormat dateFormat = new SimpleDateFormat("yyyyMM");System.out.println("result:" + dateFormat.parse(dateString));
居然输出了 2091 年 1 月 1 日,原因是把 0901 当成了月份,相当于 75 年:
result:Mon Jan 01 00:00:00 CST 2091
对于 SimpleDateFormat 的这三个坑,我们使用 Java 8 中的 DateTimeFormatter 就可以避过去。首先,使用 DateTimeFormatterBuilder 来定义格式化字符串,不用去记忆使用大写的 Y 还是小写的 Y,大写的 M 还是小写的 m:
private static DateTimeFormatter dateTimeFormatter = new DateTimeFormatterBuilder().appendValue(ChronoField.YEAR) //年.appendLiteral("/").appendValue(ChronoField.MONTH_OF_YEAR) //月.appendLiteral("/").appendValue(ChronoField.DAY_OF_MONTH) //日.appendLiteral(" ").appendValue(ChronoField.HOUR_OF_DAY) //时.appendLiteral(":").appendValue(ChronoField.MINUTE_OF_HOUR) //分.appendLiteral(":").appendValue(ChronoField.SECOND_OF_MINUTE) //秒.appendLiteral(".").appendValue(ChronoField.MILLI_OF_SECOND) //毫秒.toFormatter();
其次,DateTimeFormatter 是线程安全的,可以定义为 static 使用;最后,DateTimeFormatter 的解析比较严格,需要解析的字符串和格式不匹配时,会直接报错,而不会把 0901 解析为月份。
对日期时间做计算操作,Java 8 日期时间 API 会比 Calendar 功能强大很多。
第一,可以使用各种 minus 和 plus 方法直接对日期进行加减操作,比如如下代码实现了减一天和加一天,以及减一个月和加一个月:
第二,还可以通过 with 方法进行快捷时间调节,比如:
- 使用 TemporalAdjusters.firstDayOfMonth 得到当前月的第一天;
- 使用 TemporalAdjusters.firstDayOfYear() 得到当前年的第一天;
- 使用 TemporalAdjusters.previous(DayOfWeek.SATURDAY) 得到上一个周六;
- 使用 TemporalAdjusters.lastInMonth(DayOfWeek.FRIDAY) 得到本月最后一个周五。
第三,可以直接使用 lambda 表达式进行自定义的时间调整。
使用 Java 8 操作和计算日期时间虽然方便,但计算两个日期差时可能会踩坑:Java 8 中有一个专门的类 Period 定义了日期间隔,通过 Period.between 得到了两个 LocalDate 的差,返回的是两个日期差几年零几月零几天。如果希望得知两个日期之间差几天,直接调用 Period 的 getDays() 方法得到的只是最后的“零几天”,而不是算总的间隔天数。
可以使用 ChronoUnit.DAYS.between 解决这个问题:
如果有条件的话,我还是建议全面改为使用 Java 8 的日期时间类型。我把 Java 8 前后的日期时间类型,汇总到了一张思维导图上,图中箭头代表的是新老类型在概念上等价的类型: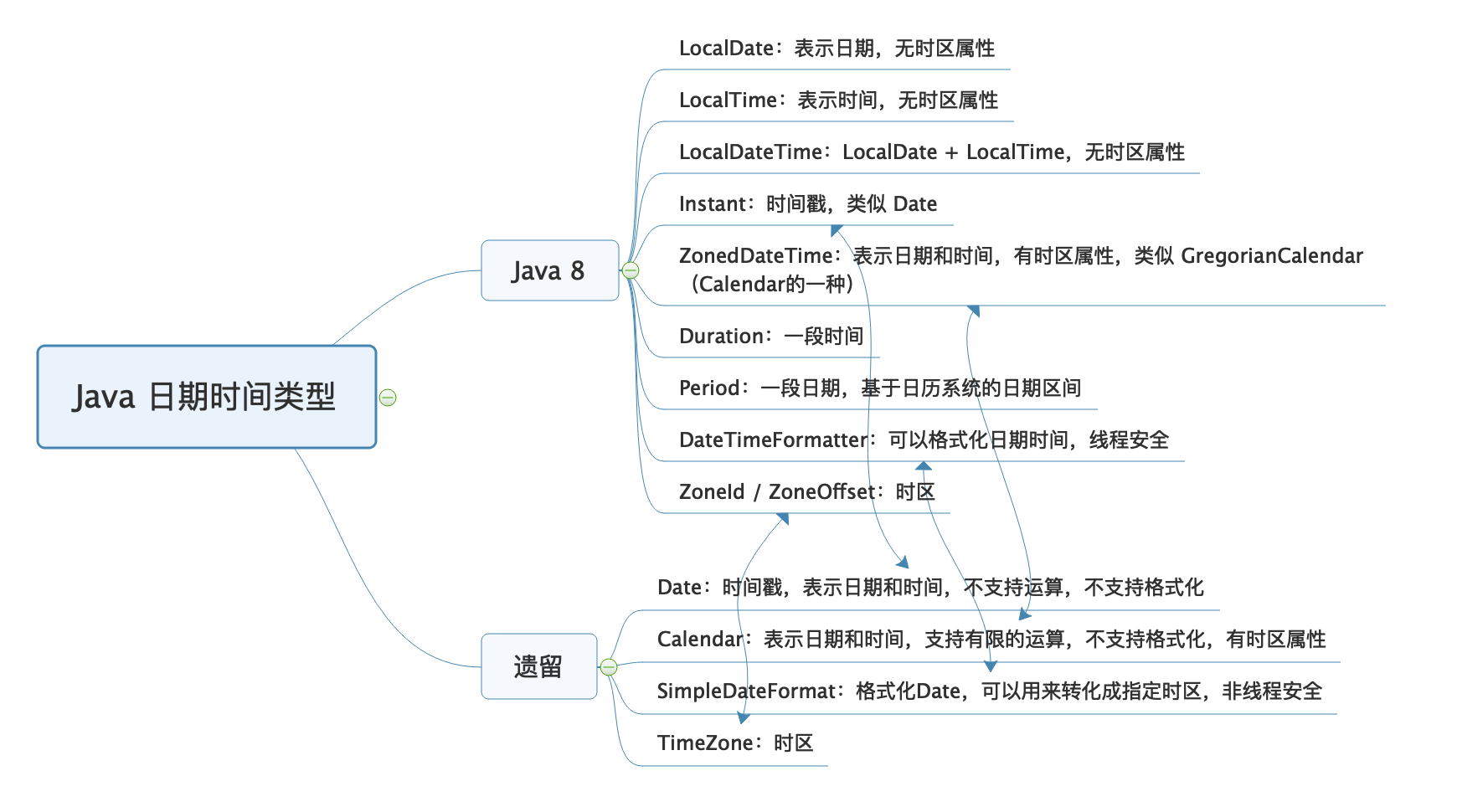
思考与讨论:
我今天多次强调 Date 是一个时间戳,是 UTC 时间、没有时区概念,为什么调用其 toString 方法会输出类似 CST 之类的时区字样呢?
日期时间数据始终要保存到数据库中,MySQL 中有两种数据类型 datetime 和 timestamp 可以用来保存日期时间。你能说说它们的区别吗,它们是否包含时区信息呢?
第一个:Date的toString()方法处理的,同String中有BaseCalendar.Date date = normalize(); 而normalize中进行这样处理cdate = (BaseCalendar.Date)cal.getCalendarDate(fastTime,TimeZone.getDefaultRef();因此其实是获取当前的默认时区的。
第二个:从下面几个维度进行区分: 占用空间:datetime:8字节。timestamp 4字节 表示范围:datetime ‘1000-01-01 00:00:00.000000’ to ‘9999-12-31 23:59:59.999999’ timestamp ‘1970-01-01 00:00:01.000000’ to ‘2038-01-19 03:14:07.999999’ 时区:timestamp 只占 4 个字节,而且是以utc的格式储存, 它会自动检索当前时区并进行转换。datetime以 8 个字节储存,不会进行时区的检索.也就是说,对于timestamp来说,如果储存时的时区和检索时的时区不一样,那么拿出来的数据也不一样。对于datetime来说,存什么拿到的就是什么。更新:timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;这个特性是自动初始化和自动更新(Automatic Initialization and Updating)。自动更新指的是如果修改了其它字段,则该字段的值将自动更新为当前系统时间。它与“explicit_defaults_for_timestamp”参数有关。 By default, the first TIMESTAMP column has both DEFAULT CURRENT_TIMESTAMP and ON UPDATE CURRENT_TIMESTAMP if neither is specified explicitly。 很多时候,这并不是我们想要的,如何禁用呢?
1. 将“explicit_defaults_for_timestamp”的值设置为ON。2. “explicit_defaults_for_timestamp”的值依旧是OFF,也有两种方法可以禁用1> 用DEFAULT子句该该列指定一个默认值2> 为该列指定NULL属性。
反射相关
使用反射查询类方法清单时,我们要注意两点:getMethods 和 getDeclaredMethods 是有区别的,前者可以查询到父类方法,后者只能查询到当前类。反射进行方法调用要注意过滤桥接方法。
使用 Java 反射、注解和泛型高级特性配合 OOP 时,可能会遇到的一些坑。
- 第一,反射调用方法并不是通过调用时的传参确定方法重载,而是在获取方法的时候通过方法名和参数类型来确定的。遇到方法有包装类型和基本类型重载的时候,你需要特别注意这一点。
- 第二,反射获取类成员,需要注意 getXXX 和 getDeclaredXXX 方法的区别,其中 XXX 包括 Methods、Fields、Constructors、Annotations。这两类方法,针对不同的成员类型 XXX 和对象,在实现上都有一些细节差异,详情请查看官方文档。今天提到的 getDeclaredMethods 方法无法获得父类定义的方法,而 getMethods 方法可以,只是差异之一,不能适用于所有的 XXX。
- 第三,泛型因为类型擦除会导致泛型方法 T 占位符被替换为 Object,子类如果使用具体类型覆盖父类实现,编译器会生成桥接方法。这样既满足子类方法重写父类方法的定义,又满足子类实现的方法有具体的类型。使用反射来获取方法清单时,你需要特别注意这一点。
- 第四,自定义注解可以通过标记元注解 @Inherited 实现注解的继承,不过这只适用于类。如果要继承定义在接口或方法上的注解,可以使用 Spring 的工具类 AnnotatedElementUtils,并注意各种 getXXX 方法和 findXXX 方法的区别,详情查看Spring 的文档AnnotatedElementUtils。最后,我要说的是。编译后的代码和原始代码并不完全一致,编译器可能会做一些优化,加上还有诸如 AspectJ 等编译时增强框架,使用反射动态获取类型的元数据可能会和我们编写的源码有差异,这点需要特别注意。你可以在反射中多写断言,遇到非预期的情况直接抛异常,避免通过反射实现的业务逻辑不符合预期。

若有收获,就点个赞吧
0 人点赞
