Golang安装包国内镜像网站:https://golang.google.cn/dl/
中文网站:https://studygolang.com/dl
go的优势:
- 极简单的部署方式:
- 可直接编译机器码
- 不依赖其他库
- 直接运行即可部署
- 静态类型语言
- 编译时候即可检查出来大多数问题
- 语言层面上的并发
- 天生支持并发
- 切换成本低
- 能够充分利用多核Cpu利用率
- 强大的标准库:
- runtime系统调度机制
- 高效的GC垃圾回收
- 丰富的标准库
- 简单易学
- 关键字少,仅25个
- 有面向对象特征(封装,继承,多态)
- 跨平台语言
Golang基础
1.1 变量的声明
变量声明的四种方式:
var a int //a默认初始值为0var b =10var c int=20d:=30 (常用)
其中:=声明方式只能用在函数体内部,所以第四种不能用在全局声明
1.2 常量与iota
被const修饰的量称为常量
- 定义常量时必须赋初值
const a =10const b int //报错
- 常量不允许被修改
const a =10a=20 //报错 cannot assign to a 不能修改a的数值
const定义枚举类型:
iota只能与const一起使用
//const与iota一起定义枚举类型时,每行iota都会加1,第一行默认值为0const(BeiJing=iota // BeiJing=0HuBei // HuBei=1FuJian // FuJian=2)
//使用表达式跟前者一样const(a,b=iota+1,iota+2 //此时iota=0 所以a=1,b=2c,d //此时iota=1 所以c=2,d=3e,f //此时iota=2 所以e=3,f=4g,h=iota*2,iota*3 //此时iota=3 所以g=6,h=9j,k //此时iota=4 所以j=8,k=12)
1.3 init函数与import导包
`main`函数在导包时,首先会执行`init`函数,即是`init`函数会优先于`main`函数先被执行。因此可以在`init`函数执行一些初始化操作,比如加载配置文件,环境变量初始化等。
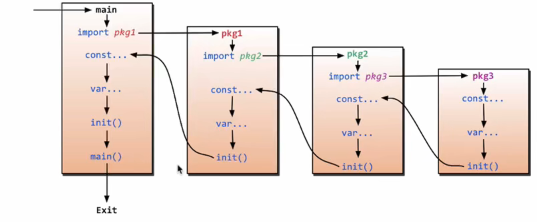
testinit├─lib1└─lib1.go├─lib2└─lib2.go└─main.go
main.go代码:
import ("awustjq/go-codingtrave/testinit/lib1""awustjq/go-codingtrave/testinit/lib2")func main() {lib1.Lib1Test()lib2.Lib2Test()}
lib1.go代码:
func Lib1Test(){fmt.Println("lib1Test is working.....")}func init() {fmt.Println("lib1 init.....")}
lib2.go代码:
func Lib2Test(){fmt.Println("lib2Test is working.....")}func init() {fmt.Println("lib2 init.....")}
执行结果:可以看出main.go执行前会先去执行导包中init函数
lib1 init.....lib2 init.....lib1Test is working.....lib2Test is working.....
import导包
import _ "aa" //给aa包起一个匿名,无法使用当前包里的方法,但是还是会执行此包的init函数;import bb "fmt" //给fmt包起一个别名,可以使用bb.Println()进行打印;
import aa "fmt"func main() {aa.Println("hello world")fmt.Println("hello world") //报错}
1.4 defer语句
类似于C++中的析构函数,程序声明周期结束前执行的命令;当有个多个defer语句,**defer**语句采用的是**压栈**顺序执行,即先进后出执行顺序;
//打印顺序 3 4 2 1 说明defer是压栈执行 且程序结束前执行func main() {defer fmt.Println("1 is working....")defer fmt.Println("2 is working....")fmt.Println("3 is working....")fmt.Println("4 is working....")}
当**return**和**defer**在同一个函数,**return**先被执行。
//"return func called..."先被打印 "defer func called..."后被打印 说明return先于defer执行func deferfunc()int{fmt.Println("defer func called...")return 0}func returnfunc()int{fmt.Println("return func called...")return 0}func testdeferAndreturn()int{defer deferfunc()return returnfunc()}
1.5 slice切片
数组定义方式:
var Array1 [10]int //默认全是0Array2:=[10]int{1,2,3,4,5} //不够的补0Array3:=[...]int{1,2,3,4} //不写数组具体数字,自动推导数字个数
切片的本质:切片变量名是指向底层数组首地址的指针,维护了指向底层数组的指针,长度和容量。
切片定义方式:
//方式1 没有分配空间时通过索引访问就会报错var slice1 []int{}//此时仅声明slice1是切片,并没分配空间,两种插入元素会报错。slice1[0]=0 / slice1=append(slice1,0) //越界报错//方式2://slice2的长度和容量均为3slice2:=[]int{1,2,3}//方式3://slice3=[]int{0,0,0} len(slice3)=3,cap(slice3)=3 长度和容量都为3,所以切片数用0填充slice3:=make([]int,3) 等价于 slice3:=make([]int,3,3)//slice4=[]int{} len(slice3)=0,cap(slice3)=3 长度为0,容量为3slice4:=make([]int,0,3)
两种声明方式比较
dic1:=make([]int,3)dic2:=make([]int,0,3)fmt.Println("len(dic1)=",len(dic1),"cap(dic1)=",cap(dic1),"dic1= ",dic1)fmt.Println("len(dic2)=",len(dic2),"cap(dic2)=",cap(dic2),"dic2= ",dic2)dic1=append(dic1,0)dic2=append(dic2,0)fmt.Println("len(dic1)=",len(dic1),"cap(dic1)=",cap(dic1),"dic1= ",dic1)fmt.Println("len(dic2)=",len(dic2),"cap(dic2)=",cap(dic2),"dic2= ",dic2)//输出:len(dic1)= 3 cap(dic1)= 3 dic1= [0 0 0]len(dic2)= 0 cap(dic2)= 3 dic2= []len(dic1)= 4 cap(dic1)= 6 dic1= [0 0 0 0]len(dic2)= 1 cap(dic2)= 3 dic2= [0]
切片的长度表示左指针和右指针之间的距离;
切片的容量表示左指针到底层数组末尾的距离;
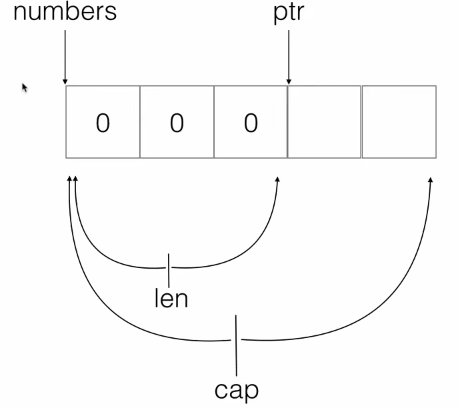
切片和数组比较:
- 数组长度是固定的,不便于修改。
- 数组作为参数传参的时候,数组长度和传参数组长度必须一致。
- 数组采用值传递,切片采用引用传递。
- 数组需要遍历求解数组的长度,而切片底层包含len字段,可以直接计算切片长度。
切片中扩容的原理:
- 如果旧切片的容量小于1024,则扩容后的容量是原来的两倍;
- 如果旧切片的容量大于1024,则扩容后的容量在原基础上增加1/4;
- 如果指定容量超过旧切片容量的两倍,则扩容至指定容量;
深浅拷贝问题:
切片本质是指向底层数组的指针,s2与s1底层公用一个数组,所以一方修改了底层数组数值,另一方数值也会被修改,即是浅拷贝;
而s3借助copy函数实现深拷贝,也即是**copy**找了一块新内存将底层数组也进行拷贝,所以对原底层数组修改,对s3底层并无影响。
func main() {s1:=[]int{1,2,3}s2:=s1[:]//s3的容量要与s1一致s3:=make([]int,len(s1))copy(s3,s1)s2[0]=999fmt.Println("s1=",s1,"s2=",s2,"s3=",s3)fmt.Println("&s1[0]=",&s1[0],"&s2[0]=",&s2[0],"&s3[0]=",&s3[0])}//s1= [999 2 3] s2= [999 2 3] s3= [1 2 3]//&s1[0]= 0xc0000ae090 &s2[0]= 0xc0000ae090 &s3[0]= 0xc0000ae0a8
1.6 map
`map`中并没有`cap`容量的概念,如果插入数据超过`map`容量,`map`不会像切片一样存在容量倍数增长,而是你插入多少容量就增长多少。
定义形式:
//map并没有容量这概念var m1 map[string]string //并没有分配内存空间,赋值报错m2:=make(map[int]int,5)m3:=map[string]string{ //声明时直接赋初值"one":"php","two":"go",}
map底层是通过哈希表实现的,有一个buckets指针和oldbuckets指针,当不进行扩容时候,使用的是buckets,而oldbuckets为空,当进行扩容的时候,oldbuckets不为空,buckets大小变为oldbuckets两倍。 而buckets储存是将key放在一起,value放在一起,而没有将keyvalue放一起,这样可以避免字节对齐的问题,避免浪费多余储存空间。
delete(citymap,"China") //只能以key值进行删除
func ChangeValueslice(s1 []int){s1=append(s1,6)fmt.Println("func里面s地址为:",&s1[0])}func ChangeValuemap(m1 map[string]string){m1["three"]="c++"}func main() {m1:=make(map[string]string)m1["one"]="php"m1["two"]="Go"s1:=[]int{1,2,3,4,5}fmt.Println("main里面s地址为:",&s1[0])fmt.Println("第一次打印:","m1=",m1,"s1=",s1)ChangeValueslice(s1)ChangeValuemap(m1)fmt.Println("第二次打印:","m1=",m1,"s1=",s1)}//main里面s地址为: 0xc000010480//第一次打印: m1= map[one:php two:Go] s1= [1 2 3 4 5]//func里面s地址为: 0xc00000e2d0//第二次打印: m1= map[one:php three:c++ two:Go] s1= [1 2 3 4 5]//main里面s地址为: 0xc000010480
比较main函数和func函数中切片地址(地址不同,说明传参是拷贝了一个副本)和数值(数值没有被修改,说明底层数组不同),实际上切片给函数传参本质还是值传递。
1.7 结构体struct
如果说类的属性首字母大写,表示该属性是对外可以访问的,否则的话只能再类的内部访问 ,**用大小写表示类中属性或者方法是否对其他包开放(类名,属性,方法等都是这样)**。在本类中大小写都可以访问 但是必须大写才能被外包和模块访问。
给一个类型起别名
type myint int //相当于给int类型起一个别名myintfunc main() {var a myint=10fmt.Println("a=",a)fmt.Printf("type of a=%T\n",a)}
封装 :
实现方式:
给结构体绑定一个方法,带由接受者的函数称为方法;
type Book struct{Name stringAuth string}//此即为封装,给结构体Book绑定一个GetName的方法func (b *Book)GetName()string{ //(b *Book)一般传指针 可以用来进行写操作}
继承:
实现方式:
- 通过匿名字段实现继承
定义父类结构体Human和对应方法
type Human struct{Name stringAge int}func (h *Human)Eat(){fmt.Println("human eat....")}func (h *Human)Walk(){fmt.Println("human walk....")}
结构体SuperMan通过匿名字段继承结构体Human
type SuperMan struct{Human //通过父类匿名字段实现继承Id int}//重写父类的walk方法func (sm *SuperMan)Walk(){fmt.Println("SuperMan walk....")}//定义子类独有的方法func (sm *SuperMan)Fly(){fmt.Println("SuperMan fly....")}
定义子类对象,实现继承
func main() {sm:=&SuperMan{Id: 1,Human:Human{"姜庆",12},}// var s SuperMan 定义子类对象//s.Id=... s.Name=... s.Age=...sm.Eat() //human eat.... 子类没有的方法 从父类继承sm.Walk() //SuperMan walk.... 子类独有的方法,实现子类自己的方法sm.Fly() //SuperMan fly.... 子类重写的方法,实现子类自己的方法}
- 子类将父类所有方法全部重写
子类将父类所有方法全部重写,就可认为是实现继承;
多态:
实现方式:
- 父类是一个
interface接口类型; - 子类必须全部重写父类的接口方法;
- 父类指向子类的指针对象;
定义一个父类的抽象类并定义两种方法
type AnimalIF interface{ //interface本质是指针Eat()Sleep()}
定义具体的类,并分别实现这两种方法
//此时即实现前述所说的继承,子类全部重写父类的方法,只不过此父类是一个抽象类type Cat struct {}func (c *Cat)Eat(){fmt.Println("Cat is eatting")}func (c *Cat)Sleep(){fmt.Println("Cat is Sleepping")}type Dog struct {}func (d *Dog)Eat(){fmt.Println("Dog is eating")}func (d *Dog)Sleep(){fmt.Println("Dog is Sleepping")}
定义不同对象实现多态 传指针因为AnimalIF是指针类型
func main(){var animal AnimalIF //定义父类对象animal=&Cat{} //父类指向子类的指针对象animal.Eat() //Cat is eattinganimal.Sleep() //Cat is Sleeppinganimal=&Dog{}animal.Eat() //Dog is eattinganimal.Sleep() //Dog is Sleepping}
或者定义一个多态的方法,再实现
func ShowAnimal(animal AnimalIF){animal.Sleep()animal.Eat()}func main() {var dog DogShowAnimal(&dog) //父类指向子类的指针对象var cat CatShowAnimal(&cat) //父类指向子类的指针对象}
1.8 万能类型interface{}
interface{}是万能类型
func TestInter(arg interface{}){fmt.Printf("type of arg is %T, arg=%v\n",arg,arg)}func main() {a,str,b:=1,"abc",3.14TestInter(a) //type of arg is int, arg=1TestInter(str) //type of arg is string, arg=abcTestInter(b) //type of arg is float64, arg=3.14}
给interface{}提供的类型断言机制,只有空接口类型才有
func TestInter(arg interface{}){//fmt.Printf("type of arg is %T, arg=%v\n",arg,arg)//如果是断言类型,value就位对应数值,ok为true 否则value为nil,ok为falsevalue,ok:= arg.(string)if !ok{fmt.Println("arg is not string type")}else{fmt.Println("arg is string type, value=",value)}}func main() {a,str,b:=1,"abc",3.14TestInter(a) //arg is not string typeTestInter(str) //arg is string type, value= abcTestInter(b) //arg is not string type}
断言机制成功原因:
变量的类型与变量值实现一个`pair`对,赋值时,始终会保持这个`pair`对
func main() {var a interface{}//pair<type:string value:"JiangQing">str:="JiangQing"//赋值后,保证pair对不会被改变,pair<type:string value:"JiangQing">a=strfmt.Printf("type of a is %T ,a=%v\n",a,a)}
1.9 反射机制
reflect包里reflect.TypeOf(arg) //求变量类型reflect.ValueOf(arg) //求变量值
结构体转json和json转结构体
定义对应结构体
type Movie struct {Title string `json:"电影名"`Year int `json:"上映年份"`Price int `json:"票价"`Actors []string `json:"主演"`}
编码过程:结构体转json
func main() {movie:=&Movie{Title: "喜剧之王",Year: 1999,Price: 20,Actors: []string{"周星驰","张柏芝"},}//结构体转json 返回值是[]byte{}jsonstr,_:=json.Marshal(movie)fmt.Println(string(jsonstr))}//{"电影名":"喜剧之王","上映年份":1999,"票价":20,"主演":["周星驰","张柏芝"]}{"电影名":"喜剧之王","上映年份":1999,"票价":20,"主演":["周星驰","张柏芝"]}
解码过程:将json转结构体
var m Moviejson.Unmarshal(jsonstr,&m) //这里切记传指针,因为你要修改结构体变量fmt.Printf("m=%#v\n",m)//m=main.Movie{Title:"喜剧之王", Year:1999, Price:20, Actors:[]string{"周星驰", "张柏芝"}}
1.10 GMP模型
1.11 groutine
非匿名
func Print(){i:=0for{time.Sleep(1*time.Second)fmt.Println("子go程:",i)i++}}func main() {go Print()i:=0for{time.Sleep(1*time.Second)fmt.Println("主go程:",i)i++}}
无参go程 匿名
func main() {go func() {defer fmt.Println("A defer")func(){defer fmt.Println("B defer")fmt.Println("B")}()fmt.Println("A")}()time.Sleep(3*time.Second)}// B ; B defer; A ;A defer;
有参go程
func main() {//想要获得子go程返回值要借助channelgo func(a int,b int)bool {fmt.Println("a=",a,"b=",b)return true}(10,20)time.Sleep(3*time.Second)}
1.12 channel
**chan**的结构体有个读**goroutine**队列,写**goroutine**队列,互斥锁**mutex**,环形队列作为缓冲区 实现**groutine**之间通信,可以让**groutine**之间按照顺序执行
无缓冲的channel:两个go程中,任意一个先到达都会阻塞等待对方到达才会执行传输。
eg:如果写go程先到达,他会阻塞等待读go程到达将管道数据读走才会执行写go程的后续操作,读go程也会继续后续操作;反过来 读go程先到达也会阻塞等待写go程写入数据
有缓冲的channel:当写go程写满管道容量,就无法继续写 进而阻塞
当读go程从管道持续读数据 没有数据就会阻塞。关闭channel后,无法向channe发送数据,但可以从中读取数据。
func main() {c:=make(chan int)go func() {defer fmt.Println("子groutine结束....")fmt.Println("子groutine运行....")c<-666}()time.Sleep(1*time.Second)if num,ok:=<-c;ok{fmt.Println("num=",num)}}//先打印"子groutine运行...."//而 "子groutine结束...." 与num数值打印两者之间没有先后顺序,甚至可能主groutine结束,导致 "子groutine结束...." 没有被打印出来
channel与range联合使用 会持续向channel c中读取数据 如果没有数据就会阻塞
for data:=range c{fmt.Println(data)}
channel与select联合使用
for {select {case <-chan1://持续监测chan1 从chan1中读取数据 如果chan1中有数据就会触发case chan1<-1: //持续监测chan2 向chan2中写数据 如果chan2为空就会触发}}
# 版本替换问题go mod edit -replace =zinx@v0.1=znix@v0.2# 当设置了GOPRIVATE后,导包就会先去GOPRIVATE进行导包
通过加锁解决数据竞争问题
package mainimport ("fmt""sync")var (x int64wg sync.WaitGroup // 等待组m sync.Mutex)// add 对全局变量x执行5000次加1操作func add() {for i := 0; i < 5000; i++ {m.Lock()x = x + 1m.Unlock()}wg.Done()}func main() {wg.Add(2)go add()go add()wg.Wait()fmt.Println(x)}
三个协程交替打印
package mainimport ("fmt""sync")func main() {var dogChan, catChan, fishChan = make(chan struct{}), make(chan struct{}), make(chan struct{})wg := sync.WaitGroup{}wg.Add(3)go func(s string) {defer wg.Done()for i := 0; i < 10; i++ {<-dogChanfmt.Println(s)catChan <- struct{}{}}<-dogChan}("dog")go func(s string) {defer wg.Done()for i := 0; i < 10; i++ {<-catChanfmt.Println(s)fishChan <- struct{}{}}}("cat")go func(s string) {defer wg.Done()for i := 0; i < 10; i++ {<-fishChanfmt.Println(s)dogChan <- struct{}{}}}("fish")dogChan <- struct{}{}wg.Wait()}
交替打印奇数和偶数
package mainimport ("fmt""sync")// 两个携程集体打印数func main() {jiChan, ouChan := make(chan struct{}), make(chan struct{})wg := sync.WaitGroup{}a := 0wg.Add(1)go func(a *int) {for i := 0; i < 10; i++ {<-jiChanfmt.Println(*a)*a++ouChan <- struct{}{}}<-jiChandefer wg.Done()}(&a)go func(a *int) {for i := 0; i < 10; i++ {<-ouChanfmt.Println(*a)*a++jiChan <- struct{}{}}}(&a)jiChan <- struct{}{}wg.Wait()}
交替打印奇数偶数
package mainimport ("fmt""sync")// 两个携程集体打印数func main() {jiChan, ouChan := make(chan *int), make(chan *int)wg := sync.WaitGroup{}wg.Add(1)go func() {for i := 0; i < 10; i++ {a, _ := <-jiChanfmt.Println(*a)*a++ouChan <- a}<-jiChandefer wg.Done()}()go func() {for i := 0; i < 10; i++ {a, _ := <-ouChanfmt.Println(*a)*a++jiChan <- a}}()a := 0jiChan <- &awg.Wait()}
三个携程交替打印abc
package mainimport ("fmt""sync")func main() {wg := sync.WaitGroup{}aChan, bChan, cChan := make(chan struct{}), make(chan struct{}), make(chan struct{})wg.Add(1)go func() {for i := 0; i < 10; i++ {<-aChanfmt.Print("A")bChan <- struct{}{}}defer wg.Done()<-aChan}()go func() {for i := 0; i < 10; i++ {<-bChanfmt.Print("B")cChan <- struct{}{}}}()go func() {for i := 0; i < 10; i++ {<-cChanfmt.Print("C")fmt.Println()aChan <- struct{}{}}}()aChan <- struct{}{}wg.Wait()}

若有收获,就点个赞吧
0 人点赞
