HashMap
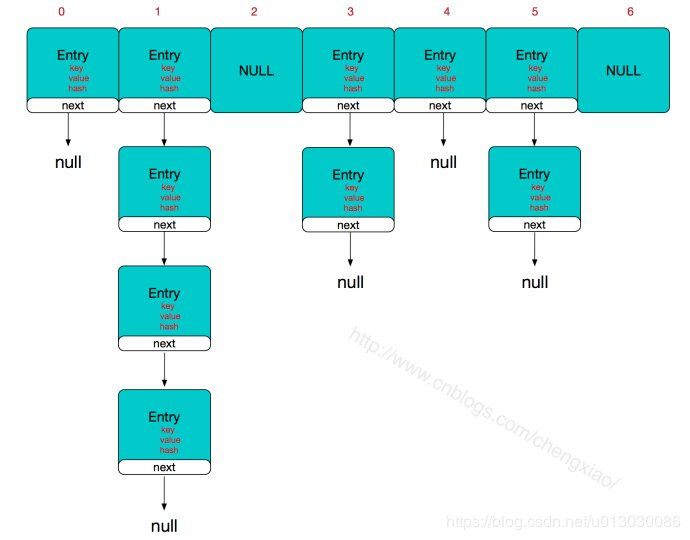
LinkedHashMap
LinkedHashMap多维护了一个双链表来记录元素的存储顺序,弥补了hashmap相较于treemap无顺序的缺点。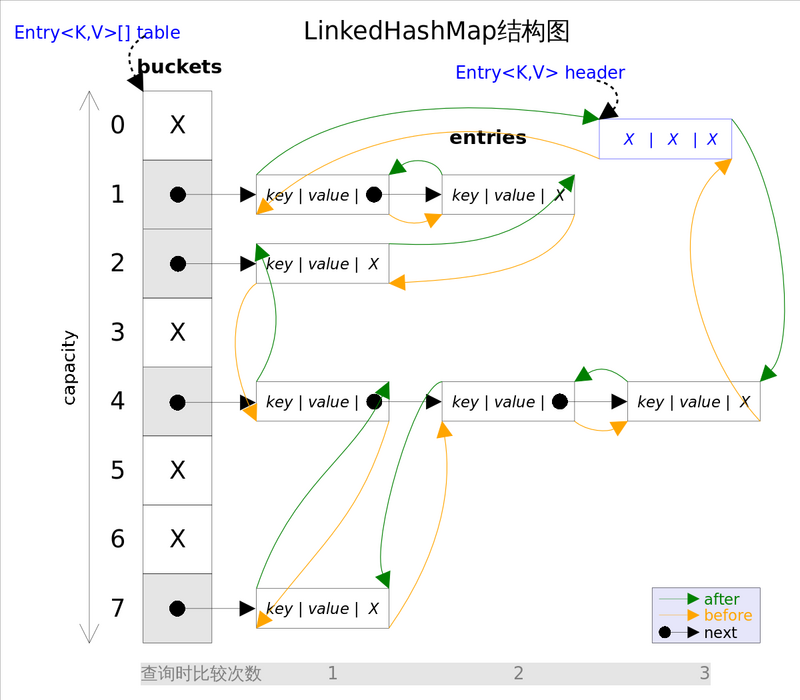
HashSet
HashSet底层使用HashMap(linkedHashSet和linkedHashMap应该也是这关系)
:::warning
但他们之间不是基础关系
linkedHashSet继承了HashSet继承了Set
linkedHashMap继承了HashMap继承了Map
:::
// 底层使用HashMap来保存HashSet的元素private transient HashMap<E,Object> map;// Dummy value to associate with an Object in the backing Map// 由于Set只使用到了HashMap的key,所以此处定义一个静态的常量Object类,来充当HashMap的valueprivate static final Object PRESENT = new Object();
HashSet是用HashMap来保存数据,而主要使用到的就是HashMap的key。
看到private static final Object PRESENT = new Object();不知道你有没有一点疑问呢。
这里使用一个静态的常量Object类来充当HashMap的value,既然这里map的value是没有意义的,为什么不直接使用null值来充当value呢?
比如写成这样子private final Object PRESENT = null;我们都知道的是,Java首先将变量PRESENT分配在栈空间,而将new出来的Object分配到堆空间,这里的new Object()是占用堆内存的(一个空的Object对象占用8byte),而null值我们知道,是不会在堆空间分配内存的。
那么想一想这里为什么不使用null值。想到什么吗,看一个异常类java.lang.NullPointerException
噢买尬,这绝对是Java程序员的一个噩梦,这是所有Java程序猿都会遇到的一个异常,你看到这个异常你以为很好解决,但是有些时候也不是那么容易解决,Java号称没有指针,但是处处碰到NullPointerException。
所以啊,为了从根源上避免NullPointerException的出现,浪费8个byte又怎么样,在下面的代码中我再也不会写这样的代码啦if (xxx == null) { … } else {….},好爽。
JDK1.8后的改变
1.HashSet中的链表从以前的头插法改为尾插法,
为什么要从头插法改成尾插法?
A.因为头插法会造成死链,参考链接
B.JDK7用头插是考虑到了一个所谓的热点数据的点(新插入的数据可能会更早用到),但这其实是个伪命题,因为JDK7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置(就是因为头插) 所以最后的结果 还是打乱了插入的顺序 所以总的来看支撑JDK7使用头插的这点原因也不足以支撑下去了 所以就干脆换成尾插 一举多得
2.Hash采用数组+链表+红黑树实现。
在Jdk1.8中Hash的实现方式做了一些改变,但是基本思想还是没有变得,只是在一些地方做了优化,下面来看一下这些改变的地方,数据结构的存储由数组+链表的方式,变化为数组+链表+红黑树的存储方式,当链表长度超过阈值(8)时,将链表转换为红黑树。在性能上进一步得到提升。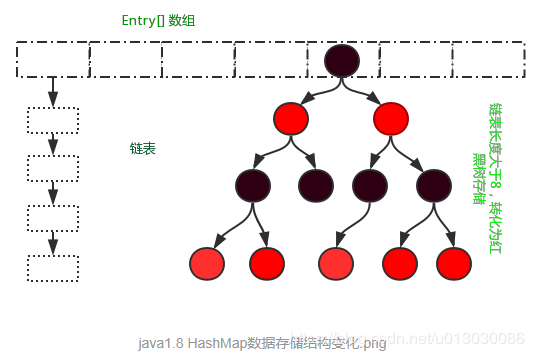

若有收获,就点个赞吧
0 人点赞
