- var、val、def三个关键字之间的区别;伴生类与伴生对象;
- case class是什么,与case object的区别是什么?
- Spark为什么快,Spark Sql一定比Hive快吗?
- 描述一下你对Rdd的理解
- 描述以下算子的区别和联系:
- 简述Spark中的缓存机制与checkpoint机制,说明两者的区别与联系
- RDD、DataFrame、DataSet三者的区别与联系
- 介绍Spark核心组件及功能
- 什么是迭代计算,迭代与循环的区别是什么?
- MapReduce和Spark都是并行计算,它们之间的区别是什么?
- 简述Spark中共享变量(广播变量和累加器)的基本原理和用途
- Spark提交作业的参数
- Spark的宽窄依赖,以及Spark如何划分stage,如何确定每个stage中task个数
- 如何理解Spark中的lineage
- Scala类型系统中Null、Nothing、Nil、None、Unit的区别
- 说说你对spark分区器的理解
- Spark Streaming 中有哪些消费Kafka数据的方式,它们之间的区别是什么
- 说明yarn-cluster模式作业提交流程,yarn-cluster与yarn-client的区别
- 介绍一下Spark SQL解析过程
- Spark的动态资源分配
- 简要介绍Spark的内存管理
- 介绍一下你对Spark Shuffle的理解
- 谈谈Spark中的容错机制
- 项目中遇到数据倾斜没有,如何解决的。
- 做过哪些Spark的优化
- 是否阅读过Spark的源码,读过哪些?
var、val、def三个关键字之间的区别;伴生类与伴生对象;
var用来声明变量;val用来声明常量;def用来创建方法。
伴生类和伴生对象同名且存在同一个文件中,二者互为伴生,可以相互访问私有成员。
case class是什么,与case object的区别是什么?
样例类是scala中特殊的类,具有以下特点:
1.构造器中的参数默认是val修饰的常量,除非被显示为var
2.提供apply方法,不用new关键字就可以构造出相应的对象
3.提供unapply方法,使得样例类可以使用模式匹配
4.生成tostring,equals,hashcode和copy方法。
5.继承了Product和Serializable,即已实现了序列化方法和可以应用Product的方法。
区别:类中有参数的时候用case class,无对象用case object
Spark为什么快,Spark Sql一定比Hive快吗?
Spark和MR相比,更加积极的使用内存,计算时减少数据落地到磁盘。
- MapReduce会将计算的中间结果落地到磁盘中,获取中间结果又会读取磁盘,会有大量的磁盘IO。
MapReduce采用的是多进程模型,而Spark采用的是多线程模型。MR中的map和reduce都是单独的进程,每次启动都要重新申请资源,消耗时间,而Spark则是维护着一个线程池,复用线程,因此减少了启动和关闭task的开销。
MR在没有中间结果落地的情况下就不一定慢于Spark Sql。Spark快是在基于内存的可迭代计算。
描述一下你对Rdd的理解
Rdd是spark提供的最重要的抽象概念,是一种有容错机制的特殊数据集合,可以分布在集群的节点上,以函数式操作集合的方式进行各种并行操作。
Rdd是只读,不可变的,具有如下的性质:只读的:只能通过转换操作生成新的Rdd
- 分布式:可以分布式在多台节点上并行处理
- 弹性: 计算过程中内存不足,它会和磁盘进行数据交换
基于内存:可以全部或者部分缓存在内存中进行重复使用,避免重复的计算
描述以下算子的区别和联系:
groupByKey、reduceByKey、aggreageByKey
相同:作用在key-value Rdd上,对相同key的数据进行聚合,都会有shuffle
不同:- groupByKey:没有map段的预聚合combiner,所以会有大数据量的shuffle过程,效率低,不建议使用; - reduceByKey、aggreageByKey:有map端的combiner,shuffle过程中数据量小效率高。 - reduceByKey:不能定义初值,初值类型和Rdd元素类型必须一致;分区内和分区间聚合使用完全相同的算法。 - aggreageByKey:最灵活也最复杂,可以定义初值,初值类型可以是任何类型,分区间和分区内的算法可以不相同。cache、persist
相同:都是操作算子,都是实现RDD的持久化
不同:cache是通过persist实现的,默认的缓存级别是MEMORY_ONLY,而persist有多种缓存级别repartition、coalesce
相同:都是对RDD进行分区操作。
不同:repartition可以减少和增加分区,coalesce只能减少分区,coalesce由repartition实现。map、flatMap
相同:都是对每个元素进行操作
不同:flatMap相当于map+flatten操作的结合,遍历每个元素,并将元素压平简述Spark中的缓存机制与checkpoint机制,说明两者的区别与联系
spark中的缓存机制目的是缓存中间结果在内存或者磁盘,避免中间结果的重复计算,节省时间和资源。但是缓存机制会保存RDD之间的依赖链(血缘关系),如果cache丢失,可以根据依赖链重新计算得到。
checkpoint机制的目的是容错。直接将RDD存在HDFS上,斩断了血缘关系。RDD、DataFrame、DataSet三者的区别与联系
相同:
三者都是分布式弹性数据集
- 三者有许多共同的函数,都有partition的概念;都支持持久化
- 三者都有惰性机制,在创建和转换时都不会立即执行,只有遇到Action时才会触发计算。
不同:
- DataFrame相比RDD,更向是传统数据库的二维表格,除了数据外,还记录数据的结构信息,即schema;且Dataframe具有更加友好的API,使用门槛更低。
DataSet相对DataFrame来说是一个新的拓展,具有类型安全检查,也具有Dataframe查询优化的特性;支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
介绍Spark核心组件及功能
Master:集群中的管理节点,管理集群中的资源,通知worker启动Driver或者Executor
Worker:集群中的工作节点,负责管理当前节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver或者Executor。
Driver:执行spark应用中的main方法,负责实际代码的执行工作。主要任务:- 负责向集群申请资源,向master注册信息。
- Executor启动后向Driver反向注册
- 负责作业的解析,生成stage并调度Task到Executor上
- 监控Task的执行情况,执行完毕后释放资源
- 通知Master注销应用程序
Executor:是一个JVM进程,负责执行具体的Task。Executor伴随着spark任务启动而启动,其生命周期伴随着整个spark的应用;如果Executor发生了故障或者崩溃,会将出错节点上的任务调度到其他Executor节点继续运行。
- 负责运行spark应用的task,并将结果返回到Driver进程。
- 通过自身的block manage为应用程序缓存RDD
什么是迭代计算,迭代与循环的区别是什么?
迭代一定是循环,但是循环不一定是迭代;
迭代计算的基本思想是将输出作为输入,再次进行计算处理。比如说KMeans中对中心点的计算就是迭代;
循环就是一段代码的重复执行;
MapReduce和Spark都是并行计算,它们之间的区别是什么?
MapReduce不支持迭代计算,其中mapTask和ReduceTask都是独立的进程,启动需要重新拉取资源。
Spark支持迭代计算,其中spark的Application会存在多个Job,每个job都会有多种算子,形成不同的Stage,其中最小的执行单元是Task,Task在Executor上,Executor是和Application相同的生命周期,即只会读取一次数据,分配一次资源,可重复使用。
Spark基于内存计算,可将计算中间结果存放在内存中,且算子种类多,表达能力强;
Spark的算子可以分哪两类,这两类算子的区别是什么,分别列举6个这两类算子,列举6个会产生Shuffle的算子
可以分为两类:操作算子(Transformation)、行动算子(Action)
区别:
操作算子是懒执行的,行动算子触发执行;
操作算子是生成中间结果,是转换动作;行动算子可以是返回程序结果或者存储数据;
分别列举6个:
操作算子:map、mapValue、mapPartitions、flatMap、filter、Join、uoin、reduceByKey
行动算子:count、collect、first、reduce、saveAsTextFile、aggregate
列举6个会产生shuffle的算子:
- 一堆的xxxByKey(sortBykey、reduceBykey、groupByKey、aggreagebykey)
- join相关:join、leftOuterJoin、rightOuterJoin、fullOuterJoin
- distinct、intersection、repartition、partitionBy、subtract
简述Spark中共享变量(广播变量和累加器)的基本原理和用途
基本原理:
广播变量:将大的变量RDD副本由Driver发送到Executor上,给其中的Task共用,避免每个Task都去拉取数据;
累加器:Driver发送到Executor的共享变量,其上的Task共同累加;
用途:
广播变量可以用来优化spark程序,累加器可用在SparkStream上对数进行累加;
Spark提交作业的参数
- executor-cores:建议2~5个
- executor-memory:和executor-cores的比例建议是2:1到4:1之间;单个Executor内存大小一般在20G左右(经验值),单个JVM内存太高易导致GC代价过高,或者浪费资源
- num-executors:executors的数量,这和Task的并行度有直接关系;一般executos-cores*num-executos表示的是能够并行执行Task的数量,不宜太小或者太大,理想情况下一般给每个core分配2-3个Task,知道想分配的Task总数量可反推出executors的数量;
- driver-memory:不需要做任何计算和存储,只是下发任务,一般设置1-2g
Spark的宽窄依赖,以及Spark如何划分stage,如何确定每个stage中task个数
Spark的RDD之间的依赖关系分为宽依赖和窄依赖;
窄依赖:父RDD和子RDD是多对一或者一对一的关系;
宽依赖:父RDD会被多个子RDD所依赖,存在Shuffle;
Stage:根据RDD之间的依赖关系将Job划分为不同的Stage,遇到一个宽依赖则划分一个Stage
如何确定Stage中的Task个数:Stage本身就是一个TaskSet,将Stage根据分区数划分为一个个的Task;
如何理解Spark中的lineage
每个RDD中都会记录其lineage,这是Spark中的容错机制,任意一个Rdd的分区出错或者不可用,都是利用原始输入数据通过转换操作而重新算出的;
对于窄依赖,只要把丢失的父分区重新算即可,不依赖其他分区;
对于宽依赖,父类RDD的所有分区都需要重算,代价昂贵;
Scala类型系统中Null、Nothing、Nil、None、Unit的区别
- Null是一个trait,是引用类型AnyRef的一个子类型,null是其唯一的实例;
- Nothing也是一个trait,是类型any(包括值类型和引用类型)的子类型,它没有子类型,也没有实例。
- Nil代表一个List的空类型,等同List[Nothing]
- None是Option的空标识
- Unit代表没有任何意义的值类型,类似于void,是AnyVal的子类型
说说你对spark分区器的理解
前提是只有key-value类型的Rdd才可能存在分区器,因为是以key进行分区的;
spark分区器是直接决定了RDD中分区的个数、RDD的每条数据经过shuffle过程,分到分区;
spark中存在两种分区器:
- HashPartition(默认分区器):Hash分区器,将key的hashcode对分区个数求余,得到目标分区;
优点就是简单、常用;缺点就是容易造成数据倾斜;
- RangePartitioner:将一定范围的数映射到某一个分区内,会尽量保证每个分区内的数据量均匀,而且一个分区中任何一个key一定比另一个分区中的任意一个key大或者小;
采用的是水塘抽样法,进行抽样,sortByKey()会使用改分区方法,其中会使用collect(),会触发一次执行;
要求:key类型必须是可以排序的
还可以自定义分区器:继承Partitioner类
Spark Streaming 中有哪些消费Kafka数据的方式,它们之间的区别是什么
有两种方式:
方式一:基于Receiver的方式
kafka0.8.2版本开始的方式,使用的是Kafka高阶消费者API实现的;Receiver将Kafka消费得到的数据存放在Spark Executor的内存中(如果突然数据暴增,大量batch堆积,很容易出现内存溢出的问题),然后Spark Streaming定期启动job处理这些数据。
默认配置下,底层处理数据失败会丢失数据;可以启用高可靠机制,保证数据的零丢失,但是必须开启WAL。
方式二:基于Direct的方式
在Spark1.3引入,兼容kafak0.10.0,用来替代Receiver方式。使用Kafka低阶消费者API实现;这种方式会周期性地获取topic+partition的最新offset范围,从而定义每个batch的offset范围。
优点如下:
简化并行读取:如果读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,然后并行从kafka中读取数据;即两边的partition是一一对应的。
高性能:基于Receiver需要开启WAL才可以保证数据的零丢失,这种效率很低,因为数据实际上存在多份,kafka中数据存在有多份,复制到HDFS上的数据有多份,Executor中的数据还有一份。
而基于Direct方式,不依赖Receiver,不需要开启WAL,只要复制kafka中的数据进行处理。
支持用户管理offset,支持消息的EOS传递。
两种方式对比:
基于Receiver:使用kafka高阶API实现,在Zookeeper中保存消费过的offset,这是消费kafka数据的传统方式。这种方式配合WAL机制可以保证数据零丢失,但是无法保证数据消费精确一次。
基于Direct的方式,使用kafka低阶API实现,Spark Streaming自己负责追踪消费的offset,并保存在checkpoint中,可以保证数据时消费一次且仅消费一次。
说明yarn-cluster模式作业提交流程,yarn-cluster与yarn-client的区别
yarn-cluster模式作业提交流程: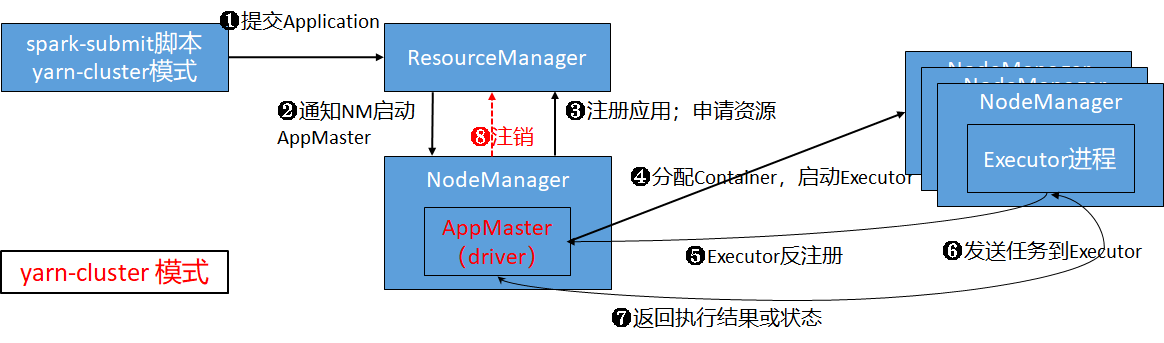
- client向Resourcemanager提交请求,并上传jar到HDFS上。
- RM通知NodeManager启动ApplicationMaster,AppMaster在其中实例化SparkContext,也就是Driver。
- AppMaster向RM注册应用,申请资源。RM监控App的运行状态直到结束。
- AppMaster申请到资源后,与NM通信,在Container启动Executor进程。
- Executor向AppMaster反向注册,申请任务。
- Driver监控着Executor执行Task的情况。
- 应用执行完毕,AppMaster通知RM注销应用,回收资源。
client和cluster的区别
client模式:
- Driver运行在客户端
- 适用于调试,能直接看见各种日志
- 连接断了,任务就挂了
cluster模式:
- Driver运行在AppMaster中(运行在集群中)
- 适合于生产,日志需要登录到某个节点才能看到
- 客户端连接断了,任务不受影响
介绍一下Spark SQL解析过程
正常的SQL执行会先经过SQL Parser解析SQL,然后经过Catalyst优化器处理,最后到Spark执行。
Catalyst优化的过程又分为很多个过程,其中包括:
- Analysis:主要利用Catalog信息将Unresolved Logical Plan 解析成Analyzed logical plan
- Logical Optimizer:利用一些Rule规则将Analyzed logical plan 解析 Optimized Logical plan
- Physical Planning:前面的logical plan不能被spark执行,而是该过程将 logical plan转换为多个物理执行计划
- Physical Optimizer:在多个执行计划中选择最佳的physical plan
- Code Generation:这个过程会吧Sql查询生成java字节码
Spark的动态资源分配
- 默认情况下,Spark采用资源预分配的方式。即为每个Spark应用设定一个最大可用资源总量,该应用在整个生命周期都会持有这些资源。
- Spark提供了一种机制,即应用的某些资源不使用的时候,回先返还给集群,并在有用的时候再次请求资源。
- 动态资源分配是Executor级。
简要介绍Spark的内存管理
Spark内存的管理主要是在Executor中,Driver是主控进程,负责创建spark上下文,负责任务的调度。
Executor内运行的并发任务共享JVM堆内存,按照用途分为:
- Storage(存储内存):缓存RDD数据和广播变量数据
- Execution(执行内存):执行Shuffle时占用的内存
- Other(剩余空间):存储Spark内部的对象实例,和用户定义的Spark应用程序中的对象实例
Spark引入了堆外内存,直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。堆外内存空间的占用可以被精确计算,相比堆内内存来说降低了管理难度。
Spark2.0之前的内存管理是采用静态内存管理机制:
- Storage:60%
- Execution:20%
- Other:20%
堆外内存没有Other,默认Storage:Execution =1:1
由于堆内内存的管理计算是不准确的,Storage和Execution内存都会有预留空间,防止OOM。
Spark2.0之后的内存管理是采用的动态内存管理机制:
- Storage:60% * 50%
- Execution:60% * 50%
- Other:40%
其中Storage和Execution是动态占用的,其中一方空闲会给忙碌的一方使用内存,但是有一点很重要:
Storage占用Execution时,Execution如果需要,Storage会马上将占用的内存返还给Execution,将数据落在磁盘上。但是如果Execution占用Storage,不会马上还,而是等自然释放。
介绍一下你对Spark Shuffle的理解
Spark1.1之前,Spark使用的是Hash Shuffle,Hash Shuffle减少了排序,但会产生海量的中间磁盘文件,大量的磁盘IO操作影响了性能;针对这个问题,Spark后续做了优化,引入了文件合并机制,但Reducer端的并行任务或者数据分片过多的话,仍然会产生大量的小文件。
Spark1.2以后,逐步是引入了Sort Shuffle。在Spark2.0之后,Hash base Shuffle逐渐是退出了历史舞台;
在Spark2.0之后,有三种Shuffle Writer:BypassMeregeSortShuffleWriter、SortShuffleWriter、UnsafeShuffleWriter;使用哪种取决以下条件判断,生产中使用的最多的是SortShuffleWriter。
谈谈Spark中的容错机制
Spark中很多地方有容错
Master容错:
只有在Standlone模式下,才需要进行Master容错配置。如果是on Yarn模式,资源由RM管理,具体的容错由Yarn管理。
StandLone模式下,会启动多个Master,只有一个是处于Action状态,其他都是处于Stand By状态。当前Master异常时,会按照一定的规则从中选取一个接替原Master的工作。
Work容错:
Worker也是Standlone才会有的,在on Yarn模式下,对应的是NodeManager,Yarn自身带有NodeManager的容错机制。
在StandLone模式下,Master回监控Worker的心跳,当Worker出现超时未响应的情况,会根据Worker运行的是Executor还是Driver分别进行处理:
Executor:Master会给对应的Driver发送消息,告知Executor已经丢失,同时把这些Executor从其应用程序运行列表删除。
Driver:会判断是否设置了需要重新启动,需要分配合适的节点重启,否则删除应用程序。
Executor容错:
Executor出现异常后,Worker会接收到通知,并把该Executor的状态发给Master,Master发现Executor出现异常退出后,会尝试在可用的Worker节点重新启动Executor,会尝试一定的次数,如果失败,整个应用程序退出;这是防止应用程序一直占用资源。
Stage容错:
Stage失败会重试,默认重试4次,可参数控制,spark.stage.maxConsecutiveAttempts控制
task容错:
task级别的重试,同一个task失败4次才会被影响。
RDD容错:
RDD本身会记录其数据来源,也就是依赖链信息,在计算结果出现丢失的时候可以根据Lineage重新恢复计算,如果lineage过长,还可以使用checkPoint机制,斩断依赖链。
项目中遇到数据倾斜没有,如何解决的。
数据倾斜的原因有很多种,首先就是业务数据本身的原因,这时候就要对数据进行预处理。
通常程序执行过程中Shuffle经常会导致数据的倾斜,有如下办法:
- 消除shuffle:能不shuffle,尽量不使用shuffle。
- 改变shuffle过程中的并行度:理论上可行,最简单,但通常没有效果。
- 加盐:给key添加随机数,将原来不能打散的数据,强行打散,通用的办法。
- 两阶段聚合:通过给key加盐,然后进行一次聚合(局部聚合),再去掉前缀或者后缀进行全局聚合
- 过滤造成数据倾斜的key,其他没有数据倾斜正常处理即可。对有数据倾斜的key加盐,强行将其打散;然后将结果合并。
- 如果以上方法都不行,采用本方法。对一张表的数据加盐强行打散,对另一张表数据扩容。
做过哪些Spark的优化
第一部分:代码优化
- 减少对数据源的扫描
- RDD复用,尽量少创建重复的RDD,同一份数据应该只有一个RDD
- RDD缓存。选择合理的缓存级别对RDD进行缓存,对经过复杂计算、计算链路长的RDD做checkpoint。
- 巧用Filter,并且尽可能早的执行filter操作,过滤无用的数据;过滤后使用coalesce对数据重新分区。
- 使用高性能的算子:尽量不要使用groupByKey,根据场景选择使用高性能的聚合算子。
- 设置合理的并行度,让并行度与资源相匹配。executor的数量executor的核心数(2~4)
- 合理使用广播变量,减少网络数据的传输
- Kryo序列化
- 多使用SparkSql:编码简单,其优化器对Sql语句做了大量的优化。
- 使用高性能的集合框架:fastUtil
第二部分 参数优化
- shuffle参数调优
- 内存参数调优
- 资源调优
- 启用动态资源分配
- 调节本地等待时长
是否阅读过Spark的源码,读过哪些?
Master & Worker启动流程描述:
- Master worker都有main方法,都是RpcEndPoint(消息通信体),通过receive、receiveAndReply、能够收、发、处理各种消息
- RpcEndPoint的生命周期是:constructor -> onStart -> receive* -> onStop,其中:
- onstart在接收任务消息前调用,主要用来执行初始化
- receive和receiveAndReply分别用来接收RpcEndPoint send 或者 ask 过来的消息
- send发送的消息不需要立即处理,ask发送的信息需要立即处理
- 在Master.onStart方法中,最重要的事情是执行恢复。Master HA的实现方式有:ZOOKEEPER、FILESYSTEM、CUSTOM
- 在Worker.onStart方法中,最重要的事情是:Worker向Master注册
- Worker启动后,启动线程同时向所有的Master发送RegisterWorker消息,进行注册
- Active Master接收到RegisterWorker后,判断worker是否重复注册,不是则记录worker的资源信息,并向worker返回一个RegisterWorker消息
- Worker接收到Master返回的RegistedWorker消息后,启动一个定时线程定期向Master发送心跳信息(Hearbeat)

若有收获,就点个赞吧
0 人点赞
