- 1面
- volatile的底层原理是怎么做的?
- Reentrantlock公平锁和非公平锁有什么区别, 讲讲源码上的差别?
- Reentrantlock和countDownLatch的区别,模式有什么不同?
- AQS是怎么加到队列的?
- 给我写一个单利模式, 写了之后讲讲不加volatile会有什么问题. new对象非原子性的问题?
- mysql的binlog,redolog 都是做什么的?
- redolog和binglog的两阶段提交你知道吗?
- redolog是怎么刷盘到磁盘的
- undolog 是啥?有什么作用?undolog除了原子性涉及到,还有什么方面涉及用到?
- mysql的索引一页有多大
- 怎么解决缓存雪崩问题?
- 分库分表你们怎么拆的
- JVM自己做了什么优化吗, 你了解不
- 2面
- 自我介绍一下自己, 上一家公司有没有做过什么高性能的接口开发, 有没有做过比较有成就的需求,讲解一下怎么做的
- 看过哪些JDK源码吗,我讲的是AQS,给他聊聊源码+一些个人看法,主要是并发编程的优化力度问题
- Redis的分布式锁是怎么用的,ZK 和redis的实现讲了一下,
- redis 分布式锁和 zk 分布式锁的对比
- redission 看门狗怎么实现的
- 主从之后的redis锁丢失问题
- 红锁怎么做的
- Redis删除大key是怎么删的,redis删除大key是异步 , 让你来做你怎么做,给讲讲你的实现思路
- Redis哨兵选举流程?
- mysql索引的叶子节点的顺序指针 ,存的是什么玩意?
- 回表是怎么回事, 怎么避免回表?
- 索引下推是什么?
- 给你一个Sting变量, 它的元素存在文件里面,怎么设计能让他快速的去这个文件里面获取找个元素值,
- explain执行计划讲讲.怎么用,mysql的优化器用的索引不是最优的,怎么办, 索引的一些组合索引的引用,维护之类的
- order By 一个组合索引, 会排序几次?
- 看到你项目中有做过一个动态数据源是怎么做的?
- RocketMQ底层原理结构怎么样的?
- 怎么解决消息堆积?
- 怎么解决RocketMQ 重复消费?
- 怎么解决 RocketMQ 消息乱序问题?
- 怎么解决消息丢失问题?
- 做过接口优化吗, 怎么做的,怎么对一个接口做幂等性校验问题,数据库的唯一索引做幂等性校验有什么问题
- 3面:
1面
volatile的底层原理是怎么做的?
http://passjava.cn/#/10.并发多线程/01.反制面试官-14张原理图-再也不怕被问volatile!
Reentrantlock公平锁和非公平锁有什么区别, 讲讲源码上的差别?
ReentrantLock内部有一个静态类Sync继承于AQS,实现需要的功能, 为了实现公平锁和非公平锁,Sync扩展了两个子类FairSync和UnFairSync。找了下1.8的ReentranLock源码:
protected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (!hasQueuedPredecessors() &&compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
final boolean nonfairTryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
区别在于公平锁在抢占时,如果队列中已经有元素,就不再用自旋抢占;而非公平锁,新线程只要执行tryAcquire 就会尝试抢占,允许新的线程插队,明显性能好一些,所以一般没有公平要求的时候可以优先使用非公平锁性能会比较好哦。
Reentrantlock和countDownLatch的区别,模式有什么不同?
上面一道题说了ReentranLock,我们看看CountDownLatch的源代码:
private static final class Sync extends AbstractQueuedSynchronizer {private static final long serialVersionUID = 4982264981922014374L;Sync(int count) {setState(count);}int getCount() {return getState();}protected int tryAcquireShared(int acquires) {return (getState() == 0) ? 1 : -1;}protected boolean tryReleaseShared(int releases) {// Decrement count; signal when transition to zerofor (;;) {int c = getState();if (c == 0)return false;int nextc = c-1;if (compareAndSetState(c, nextc))return nextc == 0;}}}
内部也是有个类Sync继承于AQS,然后它将AQS的state用来构建Sync的参数,加锁释放锁对应的方法是tryAcquireShared和tryReleaseShared,走的模式是分享模式(ReentranLock走的是独占模式),当tryAcquireShared 返回>0的值时,代表需要上锁,tryReleaseShared 每次执行就把状态减少1,当状态=0时相当于锁住。
AQS是怎么加到队列的?
给我写一个单利模式, 写了之后讲讲不加volatile会有什么问题. new对象非原子性的问题?
package com.jackson0714.passjava.threads;class VolatileSingleton {private static VolatileSingleton instance = null;private VolatileSingleton() {System.out.println(Thread.currentThread().getName() + "\t 我是构造方法SingletonDemo");}public static VolatileSingleton getInstance() {// 第一重检测if(instance == null) {// 锁定代码块synchronized (VolatileSingleton.class) {// 第二重检测if(instance == null) {// 实例化对象instance = new VolatileSingleton();}}}return instance;}}
代码看起来没有问题,但是 instance = new VolatileSingleton();其实可以看作三条伪代码:
memory = allocate(); // 1、分配对象内存空间instance(memory); // 2、初始化对象instance = memory; // 3、设置instance指向刚刚分配的内存地址,此时 instance != nullCop
y to clipboardErrorCopied
步骤2 和 步骤3之间不存在 数据依赖关系,而且无论重排前 还是重排后,程序的执行结果在单线程中并没有改变,因此这种重排优化是允许的。
memory = allocate(); // 1、分配对象内存空间instance = memory; // 3、设置instance指向刚刚分配的内存地址,此时instance != null,但是对象还没有初始化完成instance(memory); // 2、初始化对象Cop
y to clipboardErrorCopied
如果另外一个线程执行:if(instance == null) 时,则返回刚刚分配的内存地址,但是对象还没有初始化完成,拿到的instance是个假的。如下图所示: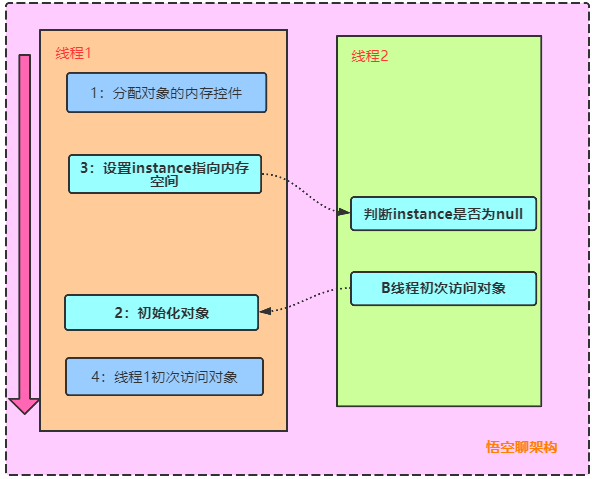
解决方案:定义instance为volatile变量
private static volatile VolatileSingleton instance = null;
mysql的binlog,redolog 都是做什么的?
binlog
binlog用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。binlog是mysql的逻辑日志,并且由Server层进行记录,使用任何存储引擎的mysql数据库都会记录binlog日志。
- 逻辑日志:可以简单理解为记录的就是sql语句。
- 物理日志:因为mysql数据最终是保存在数据页中的,物理日志记录的就是数据页变更。
binlog是通过追加的方式进行写入的,可以通过max_binlog_size参数设置每个binlog文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。
binlog使用场景
在实际应用中,binlog的主要使用场景有两个,分别是主从复制和数据恢复。
- 主从复制:在Master端开启binlog,然后将binlog发送到各个Slave端,Slave端重放binlog从而达到主从数据一致。
-
binlog刷盘时机
对于InnoDB存储引擎而言,只有在事务提交时才会记录biglog,此时记录还在内存中,那么biglog是什么时候刷到磁盘中的呢?mysql通过sync_binlog参数控制biglog的刷盘时机,取值范围是0-N:
0:不去强制要求,由系统自行判断何时写入磁盘;
- 1:每次commit的时候都要将binlog写入磁盘;
- N:每N个事务,才会将binlog写入磁盘。
redo log
redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。
redo log适用于崩溃恢复(crash-safe)
redo log的大小是固定的。redolog和binglog的两阶段提交你知道吗?
通常我们说 MySQL 的“双 1”配置,指的就是 sync_binlog 和 innodb_flush_log_at_trx_commit 都设置成 1。也就是说,一个事务完整提交前,需要等待两次刷盘,一次是 redo log(prepare 阶段),一次是 binlog。redolog是怎么刷盘到磁盘的
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。undolog 是啥?有什么作用?undolog除了原子性涉及到,还有什么方面涉及用到?
mysql的索引一页有多大
怎么解决缓存雪崩问题?
事前:Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃。
事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
事后:Redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。分库分表你们怎么拆的
JVM自己做了什么优化吗, 你了解不
我给他聊了逃逸分析 栈上分配 标量替换 锁消除, 内联, 栈帧优化2面
自我介绍一下自己, 上一家公司有没有做过什么高性能的接口开发, 有没有做过比较有成就的需求,讲解一下怎么做的
我讲的是一个千万级数据量同步的需求开发, 从并发MQ消费聊到代码优化, 聊到服务集群效果, 聊到sql的自增锁,唯一索引,插入缓存优化,还聊到了JVM内存不够触发的full gc怎么调整看过哪些JDK源码吗,我讲的是AQS,给他聊聊源码+一些个人看法,主要是并发编程的优化力度问题
Redis的分布式锁是怎么用的,ZK 和redis的实现讲了一下,
Redis 分布式锁
Zookeeper 分布式锁
举个栗子。对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机
器先执行完另外一个机器再执行。那么此时就可以使用 zookeeper 分布式锁,一个机器接收到
了请求之后先获取 zookeeper 上的一把分布式锁,就是可以去创建一个 znode,接着执行操
作;然后另外一个机器也尝试去创建那个 znode,结果发现自己创建不了,因为被别人创建
了,那只能等着,等第一个机器执行完了自己再执行。
zk 分布式锁,其实可以做的比较简单,某个节点尝试创建临时 znode,此时创建成功了就获取了这个锁;这个时候别的客户端来创建锁会失败,只能注册个监听器监听这个锁。释放锁就是删除这个 znode,一旦释放掉就会通知客户端,然后有一个等待着的客户端就可以再次重
新加锁。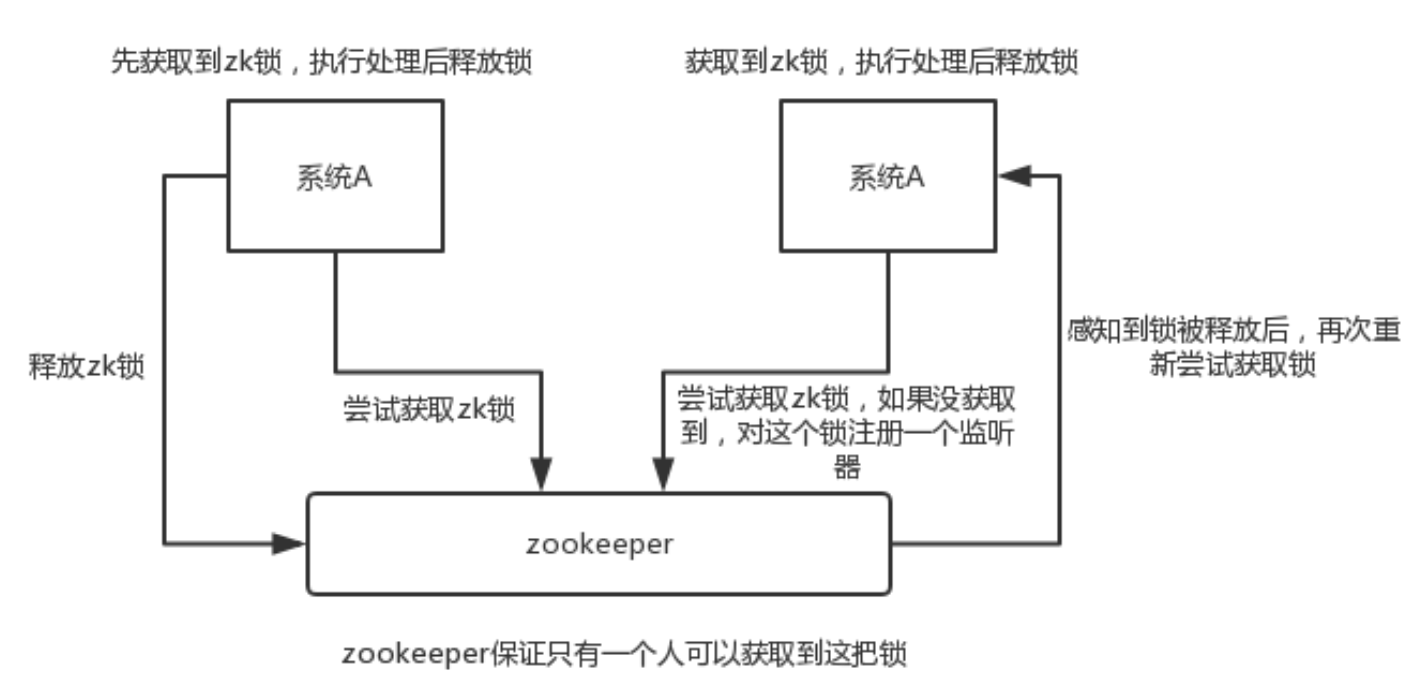
redis 分布式锁和 zk 分布式锁的对比
redis 分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
zk 分布式锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较
小。
另外一点就是,如果是 Redis 获取锁的那个客户端 出现 bug 挂了,那么只能等待超时时间之后
才能释放锁;而 zk 的话,因为创建的是临时 znode,只要客户端挂了,znode 就没了,此时就
自动释放锁。
Redis 分布式锁大家没发现好麻烦吗?遍历上锁,计算时间等等……zk 的分布式锁语义清晰实现
简单。
所以先不分析太多的东西,就说这两点,我个人实践认为 zk 的分布式锁比 Redis 的分布式锁牢
靠、而且模型简单易用。
redission 看门狗怎么实现的
- watchDog 只有在未显示指定加锁时间(leaseTime)时才会生效。(这点很重要)
如果负责储存这个分布式锁的 Redisson 节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。
默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
如果我们未制定 lock 的超时时间,就使用 30 秒作为看门狗的默认时间。只要占锁成功,就会启动一个定时任务:每隔 10 秒重新给锁设置过期的时间,过期时间为 30 秒。
如下图所示: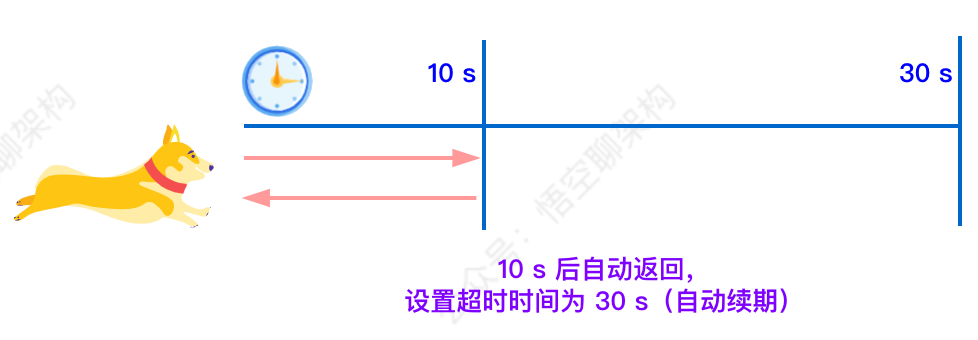
当服务器宕机后,因为锁的有效期是 30 秒,所以会在 30 秒内自动解锁。(30秒等于宕机之前的锁占用时间+后续锁占用的时间)。
如下图所示:
主从之后的redis锁丢失问题
红锁怎么做的
假设有5个redis节点,这些节点之间既没有主从,也没有集群关系。客户端用相同的key和随机值在5个节点上请求锁,请求锁的超时时间应小于锁自动释放时间。当在3个(超过半数)redis上请求到锁的时候,才算是真正获取到了锁。如果没有获取到锁,则把部分已锁的redis释放掉。
Redis删除大key是怎么删的,redis删除大key是异步 , 让你来做你怎么做,给讲讲你的实现思路
Redis哨兵选举流程?
哨兵至少需要 3 个实例,来保证自己的健壮性。
哨兵 + Redis 主从的部署架构,是不保证数据零丢失的,只能保证 Redis 集群的高可用性。
对于哨兵 + Redis 主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测
试和演练。
哨兵集群必须部署 2 个以上节点,如果哨兵集群仅仅部署了 2 个哨兵实例,quorum = 1。 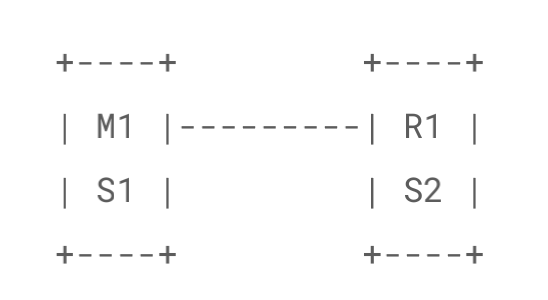
配置 quorum=1 ,如果 master 宕机, s1 和 s2 中只要有 1 个哨兵认为 master 宕机了,就可以
进行切换,同时 s1 和 s2 会选举出一个哨兵来执行故障转移。但是同时这个时候,需要
majority,也就是大多数哨兵都是运行的。
如果此时仅仅是 M1 进程宕机了,哨兵 s1 正常运行,那么故障转移是 OK 的。但是如果是整个
M1 和 S1 运行的机器宕机了,那么哨兵只有 1 个,此时就没有 majority 来允许执行故障转移,
虽然另外一台机器上还有一个 R1,但是故障转移不会执行。
经典的 3 节点哨兵集群是这样的: 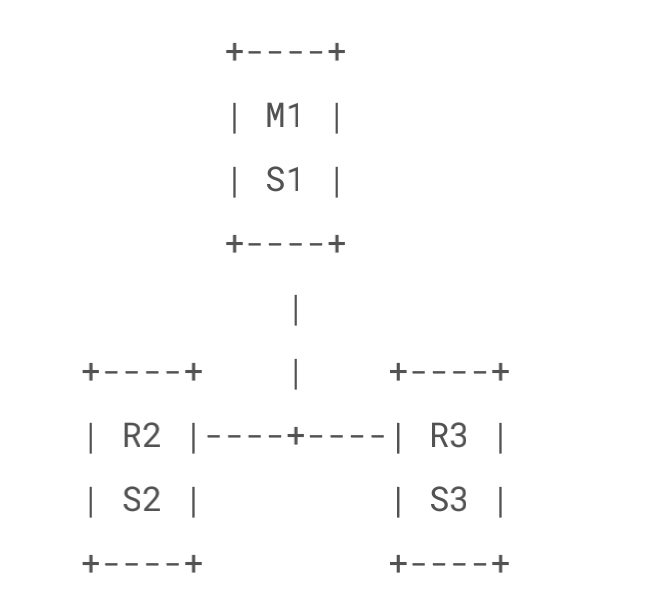
配置 quorum=2 ,如果 M1 所在机器宕机了,那么三个哨兵还剩下 2 个,S2 和 S3 可以一致认
为 master 宕机了,然后选举出一个来执行故障转移,同时 3 个哨兵的 majority 是 2,所以还剩
下的 2 个哨兵运行着,就可以允许执行故障转移。
mysql索引的叶子节点的顺序指针 ,存的是什么玩意?
就是在叶子节点增加一个指向隔壁节点的指针(解释是什么玩意儿),
来提高区间数据的查询效率的(顺序指针的作用),
比如你要查8-50的数据 ,当查到你那个8时就可以按照顺序查下去了(顺带举个栗子)
回表是怎么回事, 怎么避免回表?
答:首先索引分为聚簇索引和普通索引
聚簇索引是直接根据主键id查询直接返回完整的数据行(所以用不上回表)
普通索引是先根据条件判断获取到主键id,然后在根据主键id去聚簇索引上查询完整的数据行,再返回数据(称之为回表)
避免回表,就采用了覆盖索引
覆盖索引:在查询列表里只包含索引列
二师兄提问:索引字段是name,我用id做查询条件返回id和name字段需要回表吗?
不需要,用id做查询条件,直接用到了聚簇索引,直接返回就行。
二师兄追问:要是按name查,返回name id俩字段呢?
也不需要,使用name索引利用到了覆盖索引避免了回表
索引下推是什么?
给你一个Sting变量, 它的元素存在文件里面,怎么设计能让他快速的去这个文件里面获取找个元素值,
explain执行计划讲讲.怎么用,mysql的优化器用的索引不是最优的,怎么办, 索引的一些组合索引的引用,维护之类的
order By 一个组合索引, 会排序几次?
看到你项目中有做过一个动态数据源是怎么做的?
RocketMQ底层原理结构怎么样的?
怎么解决消息堆积?
方案一:申请多台机器,部署多个消费者系统的示例,同时消费。
方案二:临时修改消费者系统的代码,获取到消息后不做业务逻辑操作,直接把消息写入新的 Topic,速度是很快的。
怎么解决RocketMQ 重复消费?
怎么解决 RocketMQ 消息乱序问题?
生产者:同一个 id 的数据进同一个 MessageQueue。
消费者:
我们使用的是MessageListenerOrderly这个东西,他里面有Orderly这个名称
也就是说,Consumer会对每一个ConsumeQueue,都仅仅用一个线程来处理其中的消息。
如果遇到消息处理失败的场景,就必须返回SUSPEND_CURRENT_QUEUE_A_MOMENT这个状态,意
思是先等一会儿,一会儿再继续处理这批消息,而不能把这批消息放入重试队列去,然后直接处理下一批消息。
消费者代码: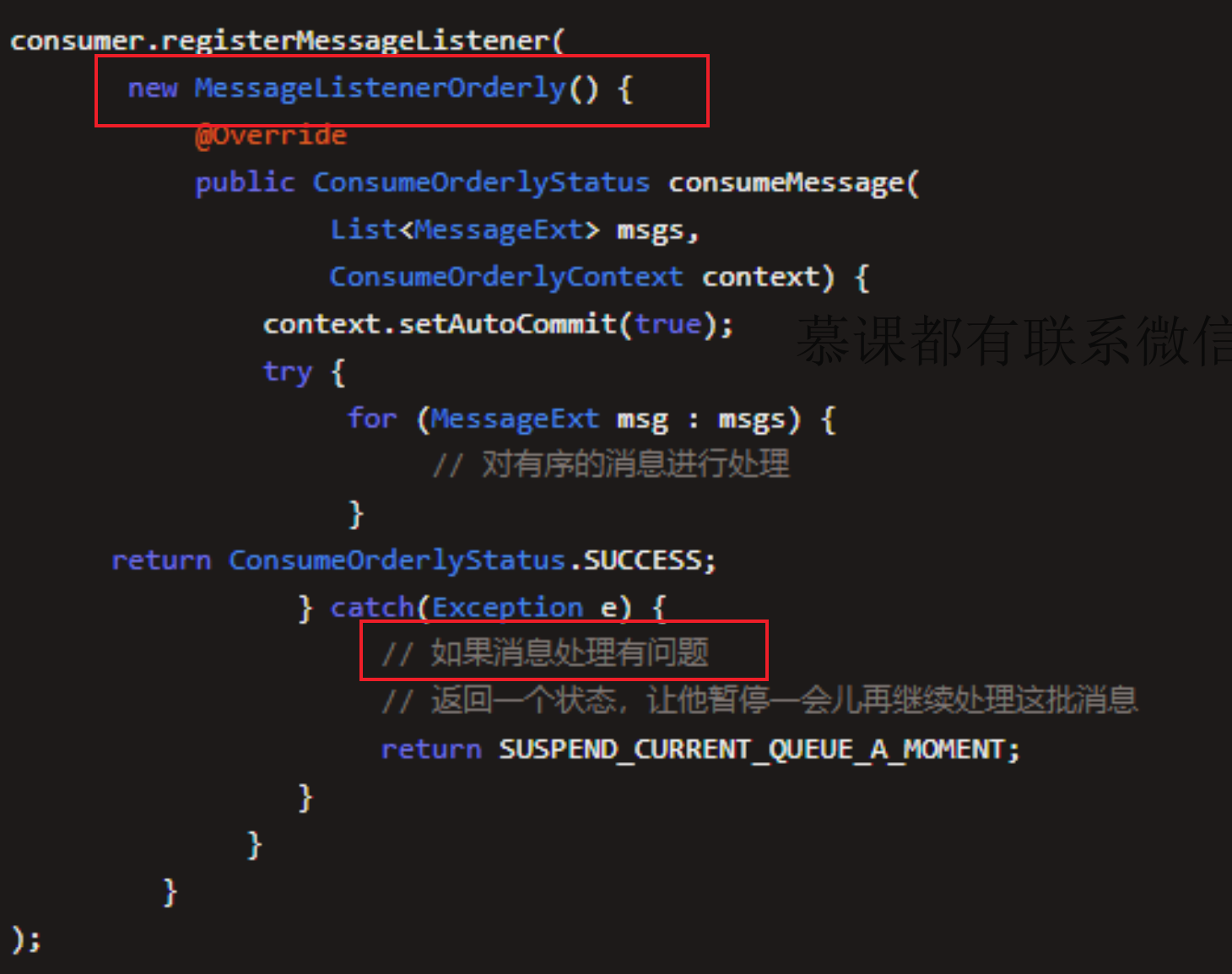
怎么解决消息丢失问题?
- 生产者系统推送支付消息时,因为网络故障,推送失败。
方案一(同步发送消息 + 反复多次重试)
方案二(事务消息机制),两者都有保证消息发送零丢失的效果,但是经过分析,事务消息方案整体会更好一些
- 消息队列自己丢失消息,消息进入了 os cache,还没写入磁盘,broker 机器故障。
开启同步刷盘策略
- 消息队列自己丢失消息,磁盘坏了,数据丢失。
开启同步刷盘策略 + 主从架构同步机制,只要让一个Broker收到消息之后同步写入磁盘,同时同步复制
给其他Broker,然后再返回响应给生产者说写入成功,此时就可以保证MQ自己不会弄丢消息。
消费者系统故障,丢失消息。消费者拿到了消息,提交了 offset,Broker 标记为已处理,但是消费者系统自己还没有处理,这个时候消费者系统故障了。
做过接口优化吗, 怎么做的,怎么对一个接口做幂等性校验问题,数据库的唯一索引做幂等性校验有什么问题
3面:
mysql中如果查询太多怎么办, 主从/多数据源
分库分表怎么做,怎么拆的,多大的时候适合拆,拆完之后的数据热点问题怎么处理?
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一
样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意
义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储
容量来进行扩容。
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个
库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字
段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库
是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个
一般在表层面做的较多一些。
这个其实挺常见的,不一定我说,大家很多同学可能自己都做过,把一个大表拆开,订单表、
订单支付表、订单商品表。还有表层面的拆分,就是分表,将一个表变成 N 个表,就是让每个表的数据量控制在一定范
围内,保证 SQL 的性能。否则单表数据量越大,SQL 性能就越差。一般是 200 万行左右,不要
太多,但是也得看具体你怎么操作,也可能是 500 万,或者是 100 万。你的SQL越复杂,就最
好让单表行数越少。
好了,无论分库还是分表,上面说的那些数据库中间件都是可以支持的。就是基本上那些中间
件可以做到你分库分表之后,中间件可以根据你指定的某个字段值,比如说 userid,自动路
由到对应的库上去,然后再自动路由到对应的表里去。
你就得考虑一下,你的项目里该如何分库分表?一般来说,垂直拆分,你可以在表层面来做,
对一些字段特别多的表做一下拆分;水平拆分,你可以说是并发承载不了,或者是数据量太
大,容量承载不了,你给拆了,按什么字段来拆,你自己想好;分表,你考虑一下,你如果哪
怕是拆到每个库里去,并发和容量都 ok 了,但是每个库的表还是太大了,那么你就分表,将
这个表分开,保证每个表的数据量并不是很大。
而且这儿还有两种分库分表的方式:
一种是按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,
但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了。
或者是按照某个字段 hash 一下均匀分散,这个较为常用。
range 来分,好处在于说,扩容的时候很简单,因为你只要预备好,给每个月都准备一个库就
可以了,到了一个新的月份的时候,自然而然,就会写新的库了;缺点,但是大部分的请求,
都是访问最新的数据。实际生产用 range,要看场景。
hash 分发,好处在于说,可以平均分配每个库的数据量和请求压力;坏处在于说扩容起来比较
麻烦,会有一个数据迁移的过程,之前的数据需要重新计算 hash 值重新分配到不同的库或表。
redis热点key问题怎么解决的?
缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个
key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了
一个洞。
不同场景下的解决方式可如下:
若缓存的数据是基本不会发生更新的,则可尝试将该热点数据设置为永不过期。
若缓存的数据更新不频繁,且缓存刷新的整个流程耗时较少的情况下,则可以采用基于
Redis、zookeeper 等分布式中间件的分布式互斥锁,或者本地互斥锁以保证仅少量的请求能
请求数据库并重新构建缓存,其余线程则在锁释放后能访问到新缓存。
若缓存的数据更新频繁或者在缓存刷新的流程耗时较长的情况下,可以利用定时线程在缓
存过期前主动地重新构建缓存或者延后缓存的过期时间,以保证所有的请求能一直访问到
对应的缓存。
redis集群的节点本身的热点数据怎么解决?
工作中有带过团队经验吗,有没有大团队互相合作的经验,遇到了什么问题,怎么解决的. 你怎么思考这些引发的问题.
为什么要离职,对未来的展望是怎么样的

若有收获,就点个赞吧
0 人点赞
